
智能工廠中的計(jì)算機(jī)視覺(jué)技術(shù)
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺(jué)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)
(文末有精彩計(jì)算機(jī)視覺(jué)技術(shù)圖譜哦)
在生理學(xué)上,視覺(jué)(Vision)的產(chǎn)生都始于視覺(jué)器官感受細(xì)胞的興奮,并于視覺(jué)神經(jīng)系統(tǒng)對(duì)收集到的信息進(jìn)行加工之后形成。我們?nèi)祟?lèi)通過(guò)視覺(jué)來(lái)直觀地了解眼前事物的形體和狀態(tài),大部分人依靠視覺(jué)來(lái)完成做飯、越過(guò)障礙、讀路牌、看視頻以及無(wú)數(shù)其他任務(wù)。事實(shí)上,絕大多數(shù)人對(duì)外界信息的獲取都是通過(guò)視覺(jué)完成的,而這個(gè)占比高達(dá)80%以上——這個(gè)比例并不是沒(méi)有根據(jù)的,著名實(shí)驗(yàn)心理學(xué)家赤瑞特拉(Treicher)曾通過(guò)大量的實(shí)驗(yàn)證實(shí):人類(lèi)獲取的信息的83%來(lái)自視覺(jué),11%來(lái)自聽(tīng)覺(jué),剩下的6%來(lái)自嗅覺(jué)、觸覺(jué)、味覺(jué)。所以,對(duì)于人類(lèi)來(lái)說(shuō),視覺(jué)無(wú)疑是最重要的一種感覺(jué)。
不僅人類(lèi)是“視覺(jué)動(dòng)物”,對(duì)于大多數(shù)動(dòng)物來(lái)說(shuō),視覺(jué)也都起到十分重要的作用。通過(guò)視覺(jué),人和動(dòng)物感知外界物體的大小、明暗、顏色、動(dòng)靜,獲得對(duì)機(jī)體生存具有重要意義的各種信息,通過(guò)這些信息能夠得知,周?chē)氖澜缡窃鯓拥模约叭绾魏褪澜缃换ァ?br style="outline: 0px;">
而在計(jì)算機(jī)視覺(jué)出現(xiàn)之前,圖像對(duì)于計(jì)算機(jī)來(lái)說(shuō)是黑盒的狀態(tài)。一張圖像對(duì)于計(jì)算機(jī)來(lái)說(shuō)只是一個(gè)文件、一串?dāng)?shù)據(jù)。如果計(jì)算機(jī)、人工智能想要在現(xiàn)實(shí)世界發(fā)揮重要作用,就必須看懂圖片!因此,半個(gè)世紀(jì)以來(lái),計(jì)算機(jī)科學(xué)家一直在想辦法讓計(jì)算機(jī)也擁有視覺(jué),從而產(chǎn)生了“計(jì)算機(jī)視覺(jué)”這個(gè)領(lǐng)域。
網(wǎng)絡(luò)的迅速發(fā)展也令計(jì)算機(jī)視覺(jué)變得尤為重要。下圖是2020年以來(lái)網(wǎng)絡(luò)上新增數(shù)據(jù)量的走勢(shì)圖。灰色圖形是結(jié)構(gòu)化數(shù)據(jù),藍(lán)色圖形是非結(jié)構(gòu)化數(shù)據(jù)(大部分都是圖片和視頻)。可以很明顯地發(fā)現(xiàn),圖片和視頻的數(shù)量正在以指數(shù)級(jí)的速度瘋狂增長(zhǎng)。

▼
什么是計(jì)算機(jī)視覺(jué)
計(jì)算機(jī)視覺(jué)是人工智能領(lǐng)域的一個(gè)重要分支,簡(jiǎn)單來(lái)說(shuō),它要解決的問(wèn)題就是:讓計(jì)算機(jī)看懂圖像或者視頻里的內(nèi)容。比如:圖片里的寵物是貓還是狗?圖片里的人是老張還是老王?視頻里的人在做什么事情?更進(jìn)一步地說(shuō),計(jì)算機(jī)視覺(jué)就是指用攝影機(jī)和電腦代替人眼對(duì)目標(biāo)進(jìn)行識(shí)別、跟蹤和測(cè)量等,并進(jìn)一步做圖形處理,得到更適合人眼觀察或傳送給儀器檢測(cè)的圖像。作為一個(gè)科學(xué)學(xué)科,計(jì)算機(jī)視覺(jué)研究相關(guān)的理論和技術(shù),試圖建立能夠從圖像或者多維數(shù)據(jù)中獲取高層次信息的人工智能系統(tǒng)。從工程的角度來(lái)看,它尋求利用自動(dòng)化系統(tǒng)模仿人類(lèi)視覺(jué)系統(tǒng)來(lái)完成任務(wù)。
計(jì)算機(jī)視覺(jué)的最終目標(biāo)是使計(jì)算機(jī)能像人那樣通過(guò)視覺(jué)觀察和理解世界,具有自主適應(yīng)環(huán)境的能力。但能真正實(shí)現(xiàn)計(jì)算機(jī)能夠通過(guò)攝像機(jī)感知這個(gè)世界卻是非常之難,因?yàn)殡m然攝像機(jī)拍攝的圖像和我們平時(shí)所見(jiàn)是一樣的,但對(duì)于計(jì)算機(jī)來(lái)說(shuō),任何圖像都只是像素值的排列組合,是一堆死板的數(shù)字。如何讓計(jì)算機(jī)從這些死板的數(shù)字里面讀取到有意義的視覺(jué)線索,是計(jì)算機(jī)視覺(jué)應(yīng)該解決的問(wèn)題。
不過(guò)隨著技術(shù)的發(fā)展,計(jì)算機(jī)視覺(jué)技術(shù)已經(jīng)可以解決越來(lái)越多的現(xiàn)實(shí)問(wèn)題,而本文也附上了從傳統(tǒng)到深度神經(jīng)網(wǎng)絡(luò)即AI人工智能的計(jì)算機(jī)視覺(jué)技術(shù)圖譜。就是這些技術(shù)幫我們實(shí)現(xiàn)了一系列計(jì)算機(jī)視覺(jué)技術(shù)難題(具體的技術(shù)細(xì)節(jié)會(huì)在以后的章節(jié)和各位讀者分享)。
▼
計(jì)算機(jī)視覺(jué)的典型任務(wù)

圖像分類(lèi)
圖像分類(lèi)是計(jì)算機(jī)視覺(jué)任務(wù)中的一個(gè)重要的概念,目標(biāo)檢測(cè)技術(shù)的發(fā)展之初也主要是通過(guò)圖像分類(lèi)思想來(lái)實(shí)現(xiàn)的。
圖像分類(lèi)
圖像分類(lèi),顧名思義,即是輸入一張圖像,我們通過(guò)算法來(lái)輸出這個(gè)圖像的類(lèi)別,例如判斷出這張圖像是貓或者狗。對(duì)于經(jīng)典的Mnist數(shù)據(jù)集來(lái)說(shuō),這個(gè)數(shù)據(jù)集包括了0到9共10個(gè)數(shù)字的手寫(xiě)體圖片,所以這就是一個(gè)典型的圖像多分類(lèi)問(wèn)題,即將這些圖片分為0到9共10個(gè)類(lèi)別。傳統(tǒng)的圖像分類(lèi)的主要步驟是進(jìn)行特征提取,然后訓(xùn)練分類(lèi)器。
2012年,基于神經(jīng)網(wǎng)絡(luò)的AlexNet網(wǎng)絡(luò)提出,在2012年的ImageNet競(jìng)賽中奪得冠軍。之后,更多的更深的神經(jīng)網(wǎng)絡(luò)被提出,比如優(yōu)秀的vgg、GoogLeNet、ResNet等。
目標(biāo)檢測(cè)
目標(biāo)檢測(cè)是對(duì)圖像中的目標(biāo)進(jìn)行分類(lèi)和定位,如圖所示,即找出圖像中的三個(gè)目標(biāo),將其劃分為“羊”這個(gè)類(lèi)別,然后對(duì)每一只羊的位置進(jìn)行定位,用邊界框的形式將其位置標(biāo)注出來(lái),目標(biāo)檢測(cè)的應(yīng)用非常廣泛。

目標(biāo)檢測(cè)
目前目標(biāo)檢測(cè)領(lǐng)域的深度學(xué)習(xí)方法主要分為兩類(lèi):兩階段的目標(biāo)檢測(cè)算法、單階段目標(biāo)檢測(cè)算法。兩階段目標(biāo)檢測(cè)是指首先由算法生成一系列作為樣本的候選框,再通過(guò)卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行樣本分類(lèi)。常見(jiàn)的兩階段算法有R-CNN、Fast R-CNN、Faster R-CNN等。單階段目標(biāo)檢測(cè)算法不需要產(chǎn)生候選框,直接將目標(biāo)框定位的問(wèn)題轉(zhuǎn)化為回歸問(wèn)題處理。常見(jiàn)的算法有YOLO系列算法、SSD算法等。
語(yǔ)義分割
語(yǔ)義分割是一種像素級(jí)別的分類(lèi),就是把圖像中每個(gè)像素賦予一個(gè)類(lèi)別標(biāo)簽(比如羊、草地等),對(duì)比圖中的語(yǔ)義分割沒(méi)有對(duì)草地和天空進(jìn)行劃分,只是單純的將每一個(gè)像素劃分為:是羊的像素;不是羊的像素。將羊的像素部分用顏色表示出來(lái),我們一般將其稱(chēng)為二進(jìn)制掩碼,即一個(gè)0-1矩陣,其中羊的像素部分取值為1,不是羊的像素部分,取值為0。于是上述的圖片如果使用語(yǔ)義分割算法進(jìn)行圖像分割,得到的二進(jìn)制掩碼如下圖所示:

通過(guò)對(duì)掩碼的解析,我們就可以知道當(dāng)前圖像中是否存在羊,以及羊處于什么位置。但是語(yǔ)義分割有一個(gè)局限性,比如如果一個(gè)像素被標(biāo)記為橙色,那就代表這個(gè)像素所在的位置是一只羊,但是如果有兩個(gè)都是橙色的像素,語(yǔ)義分割無(wú)法判斷它們是屬于同一只羊還是不同的羊。也就是說(shuō)語(yǔ)義分割只能判斷類(lèi)別,無(wú)法區(qū)分個(gè)體。

語(yǔ)義分割
語(yǔ)義分割中的經(jīng)典算法為全卷積網(wǎng)絡(luò)FCN,通常CNN網(wǎng)絡(luò)在卷積層之后會(huì)接上若干個(gè)全連接層,將卷積層產(chǎn)生的特征圖映射成一個(gè)固定長(zhǎng)度的特征向量。以AlexNet為代表的經(jīng)典CNN結(jié)構(gòu)適合于圖像級(jí)的分類(lèi)和回歸任務(wù)。與經(jīng)典的CNN在卷積層之后使用全連接層得到固定長(zhǎng)度的特征向量進(jìn)行分類(lèi)不同,F(xiàn)CN可以接受任意尺寸的輸入圖像,采用反卷積層對(duì)最后一個(gè)卷積層的feature map進(jìn)行上采樣,使它恢復(fù)到輸入圖像相同的尺寸,從而可以對(duì)每個(gè)像素都產(chǎn)生了一個(gè)預(yù)測(cè),同時(shí)保留了原始輸入圖像中的空間信息,最后在上采樣的特征圖上進(jìn)行逐像素分類(lèi)。
語(yǔ)義分割領(lǐng)域中的經(jīng)典算法有Deeplab系列算法、DFANet、BiseNet、ENet等。
實(shí)例分割
實(shí)例分割算法有點(diǎn)類(lèi)似于語(yǔ)義分割和目標(biāo)檢測(cè)的結(jié)合,不過(guò)目標(biāo)檢測(cè)輸出的是邊界框的坐標(biāo),實(shí)例分割除了輸出邊界框的坐標(biāo),還會(huì)輸出二進(jìn)制掩碼。實(shí)例分割和語(yǔ)義分割不同,它不需要對(duì)每個(gè)像素進(jìn)行標(biāo)記,它只需要找到感興趣物體的邊緣輪廓就行,實(shí)例分割是在像素級(jí)識(shí)別對(duì)象輪廓的任務(wù)。比如上圖中的羊就是感興趣的物體。我們可以看到每只羊都是不同的顏色的輪廓,因此我們可以區(qū)分出單個(gè)個(gè)體。

實(shí)例分割
經(jīng)典的實(shí)例分割算法有Mask-RCNN算法、SOLO算法,以及提升速度的YOLACT算法、BlendMask算法等。
全景分割
全景分割最先由FAIR與德國(guó)海德堡大學(xué)聯(lián)合提出,其任務(wù)是為圖像中每個(gè)像素點(diǎn)賦予類(lèi)別Label和實(shí)例ID,生成全局的、統(tǒng)一的分割圖像。全景分割任務(wù)要求圖像中的每個(gè)像素點(diǎn)都必須被分配給一個(gè)語(yǔ)義標(biāo)簽和一個(gè)實(shí)例ID。其中,語(yǔ)義標(biāo)簽指的是物體的類(lèi)別,而實(shí)例ID則對(duì)應(yīng)同類(lèi)物體的不同編號(hào)。全景分割的一個(gè)重要的特征在于其對(duì)背景也進(jìn)行了檢測(cè)和分割。全景分割可以認(rèn)為是語(yǔ)義分割和實(shí)例分割的結(jié)合。

全景分割
常見(jiàn)的全景分割算法有UPSNet、OANet、EfficientPS等。
計(jì)算機(jī)視覺(jué)任務(wù)目前的主要應(yīng)用場(chǎng)景主要有:人臉識(shí)別、自動(dòng)駕駛、人群計(jì)數(shù)、視頻監(jiān)控、文字識(shí)別、醫(yī)學(xué)圖像分割等。其應(yīng)用領(lǐng)域涉及諸多行業(yè)。通過(guò)將圖像的分類(lèi)、識(shí)別、分割、跟蹤等技術(shù)進(jìn)行結(jié)合,可以在更多的行業(yè)場(chǎng)景中發(fā)揮作用。
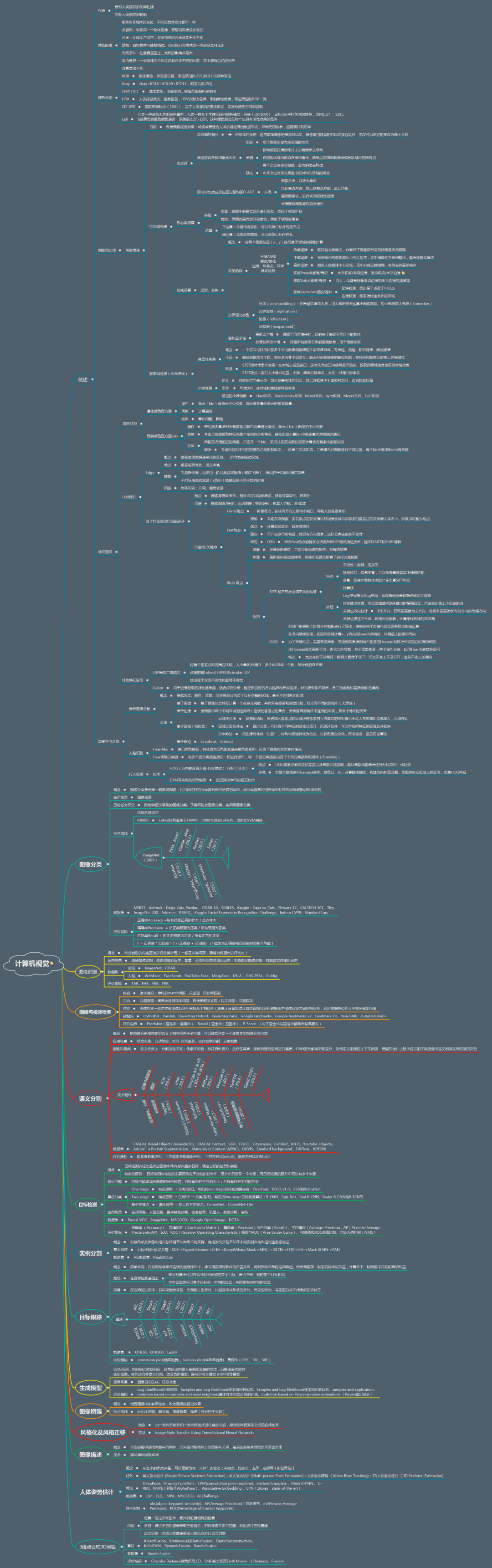
詳細(xì)至極的計(jì)算機(jī)視覺(jué)技術(shù)圖譜!
本文僅做學(xué)術(shù)分享,如有侵權(quán),請(qǐng)聯(lián)系刪文。