
深度學(xué)習(xí)模型大小與模型推理速度的深度探討
點(diǎn)擊下方“AI算法與圖像處理”,一起進(jìn)步!
重磅干貨,第一時間送達(dá)
本文將對衡量深度學(xué)習(xí)模型大小的一些常用指標(biāo),如計算量、參數(shù)量、訪存量、內(nèi)存占用等進(jìn)行探討,分析這些指標(biāo)對模型部署推理的影響,尤其是計算量與訪存量對模型推理速度的影響,并給出在不同硬件架構(gòu)下設(shè)計網(wǎng)絡(luò)結(jié)構(gòu)的一些建議。
零、前言
當(dāng)年頭一次實(shí)習(xí)做算法的時候,主管給的第一個任務(wù)就是“把一個大的分割模型砍成一個小的”。當(dāng)時并不理解模型“大”、“小”的真正含義,就簡單的選取計算量作為評價指標(biāo),瘋狂砍計算量(backbone換 MobileNet/ShuffleNet、Conv 換成 DepthWise Conv、以及一些奇奇怪怪的融合結(jié)構(gòu)等等),把模型計算量砍了將近 10倍,結(jié)果一部署發(fā)現(xiàn)速度并沒有快多少,反而是把最初的 ResNet 簡單砍掉幾個 block 效果更好。
也是從那時起接觸了訪存量、流水線、RoofLine 模型等概念,對模型推理速度的問題產(chǎn)生了興趣,從此踏上了深度學(xué)習(xí)推理優(yōu)化的不歸路(劃掉)。
如今做推理優(yōu)化和 HPC已經(jīng)有一段時間了,還是偶爾能回想起當(dāng)年不懂推理時設(shè)計的與硬件嚴(yán)重不匹配的模型。此外在工作中跟研究員溝通時,也會發(fā)現(xiàn)部分研究員對模型大小和模型推理速度的關(guān)系不太了解,設(shè)計出一些很難發(fā)揮硬件計算能力的模型結(jié)構(gòu)。因此在這里對一些用于評價模型大小的指標(biāo)——計算量、參數(shù)量、訪存量、內(nèi)存占用等指標(biāo)進(jìn)行詳細(xì)探討,分析這些指標(biāo)會對模型的部署推理產(chǎn)生何種影響,詳細(xì)討論計算量和訪存量對模型推理速度的影響,并給出不同硬件架構(gòu)下設(shè)計高效網(wǎng)絡(luò)結(jié)構(gòu)的一些建議。
本文不僅僅是為了給出網(wǎng)絡(luò)的設(shè)計建議,更是希望能夠有效傳達(dá)性能優(yōu)化的基礎(chǔ)理論知識,以及性能分析的基本思路,幫助各位同學(xué)減少網(wǎng)絡(luò)設(shè)計與部署之間的gap,更高效的完成網(wǎng)絡(luò)設(shè)計與部署工作。非常希望本文能夠?qū)Υ蠹业墓ぷ饔兴鶐椭卜浅g迎大家在評論區(qū)留言探討。
一、常用的模型大小評估指標(biāo)
目前常用于評價模型大小的指標(biāo)有:計算量、參數(shù)量、訪存量、內(nèi)存占用等,這些指標(biāo)從不同維度評價了模型的大小。本節(jié)僅作簡單介紹,熟悉的小伙伴可以跳過此節(jié),直接看后面的分析與探討。
1. 計算量
計算量可以說是評價模型大小最常用的指標(biāo)了,很多論文在跟 baseline 進(jìn)行比較時,都會把計算量作為重要的比較依據(jù)。
計算量是模型所需的計算次數(shù),反映了模型對硬件計算單元的需求。計算量一般用?OPs?(Operations),即計算次數(shù)來表示。由于最常用的數(shù)據(jù)格式為 float32,因此也常常被寫作?FLOPs?(Floating Point Operations),即浮點(diǎn)計算次數(shù)。(這里為了跟傳統(tǒng)習(xí)慣保持一致,下文就統(tǒng)一采用 FLOPs 啦)
模型的整體計算量等于模型中每個算子的計算量之和。而每個算子的計算量計算方法各不一致。例如對于 Eltwise Sum 來講,兩個大小均為 (N, C, H,W) 的 Tensor 相加,計算量就是 N x C x H x W;而對于卷積來說,計算量公式為(乘加各算一次):
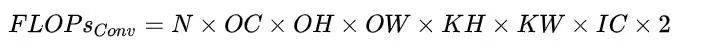
PyTorch 有不少工具可以模型計算量,但需要注意的是這些工具有可能會遺漏一些算子的計算量,將其計算量算成0,從而導(dǎo)致統(tǒng)計的計算量跟實(shí)際計算量有輕微的偏差,不過大多數(shù)情況下這些偏差影響不大。
2. 參數(shù)量
早期的論文也很喜歡用參數(shù)量來評價模型大小。
參數(shù)量是模型中的參數(shù)的總和,跟模型在磁盤中所需的空間大小直接相關(guān)。對于 CNN 來說參數(shù)主要由 Conv/FC 層的 Weight構(gòu)成,當(dāng)然其他的一些算子也有參數(shù),不過一般忽略不計了。
參數(shù)量往往是被算作訪存量的一部分,因此參數(shù)量不直接影響模型推理性能。但是參數(shù)量一方面會影響內(nèi)存占用,另一方面也會影響程序初始化的時間。
參數(shù)量會直接影響軟件包的大小。當(dāng)軟件包大小是很重要的指標(biāo)時,參數(shù)量至關(guān)重要,例如手機(jī) APP 場景,往往對 APK包的大小有比較嚴(yán)格的限制;此外有些嵌入式設(shè)備的 Flash 空間很小,如果模型磁盤所需空間很大的話,可能會放不下,因此也會對參數(shù)量有所要求。
除了在設(shè)計模型時減少參數(shù)量外,還可以通過壓縮模型的方式降低軟件包大小。例如 Caffe 和 ONNX 采用的 Protobuf就會對模型進(jìn)行高效的編碼壓縮。不過壓縮模型會帶來解壓縮開銷,會一定程度增加程序初始化的時間。
3. 訪存量
訪存量往往是最容易忽視的評價指標(biāo),但其實(shí)是現(xiàn)在的計算架構(gòu)中對性能影響極大的指標(biāo)。
訪存量是指模型計算時所需訪問存儲單元的字節(jié)大小,反映了模型對存儲單元帶寬的需求。訪存量一般用?Bytes?(或者?KB/MB/GB)來表示,即模型計算到底需要存/取多少 Bytes 的數(shù)據(jù)。
和計算量一樣,模型整體訪存量等于模型各個算子的訪存量之和。對于 Eltwise Sum 來講,兩個大小均為 (N, C, H, W) 的 Tensor相加,訪存量是 (2 + 1) x N x C x H x W x sizeof(data_type),其中 2 代表讀兩個 Tensor,1 代表寫一個 Tensor;而對于卷積來說,訪存量公式為:
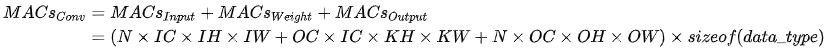
訪存量對模型的推理速度至關(guān)重要,設(shè)計模型時需要予以關(guān)注。
4. 內(nèi)存占用
內(nèi)存占用是指模型運(yùn)行時,所占用的內(nèi)存/顯存大小。一般有工程意義的是最大內(nèi)存占用,當(dāng)然有的場景下會使用平均內(nèi)存占用。這里要注意的是,內(nèi)存占用 ≠ 訪存量。
內(nèi)存占用在論文里不常用,主要原因是其大小除了受模型本身影響外,還受軟件實(shí)現(xiàn)的影響。例如有的框架為了保證推理速度,會將模型中每一個 Tensor所需的內(nèi)存都提前分配好,因此內(nèi)存占用為網(wǎng)絡(luò)所有 Tensor 大小的總和;但更多的框架會提供 lite 內(nèi)存模式,即動態(tài)為 Tensor分配內(nèi)存,以最大程度節(jié)省內(nèi)存占用(當(dāng)然可能會犧牲一部分性能)。
和參數(shù)量一樣,內(nèi)存占用不會直接影響推理速度,往往算作訪存量的一部分。但在同一平臺上有多個任務(wù)并發(fā)的環(huán)境下,如推理服務(wù)器、車載平臺、手機(jī)APP,往往要求內(nèi)存占用可控。可控一方面是指內(nèi)存/顯存占用量,如果占用太多,其他任務(wù)就無法在平臺上運(yùn)行;另一方面是指內(nèi)存/顯存的占用量不會大幅波動,影響其他任務(wù)的可用性。
5. 小結(jié)
計算量、參數(shù)量、訪存量、內(nèi)存占用從不同維度定義了模型的大小,應(yīng)根據(jù)不同的場合選用合適的指標(biāo)進(jìn)行評價。
模型推理速度不單單受模型計算量的影響,也與訪存量和一些其他因素息息相關(guān)。下文將詳細(xì)討論影響模型推理速度的因素。
二、計算量越小,模型推理就越快嗎
答案是否定的。
實(shí)際上計算量和實(shí)際的推理速度之間沒有直接的因果關(guān)系。計算量僅能作為模型推理速度的一個參考依據(jù)。
模型在特定硬件上的推理速度,除了受計算量影響外,還會受訪存量、硬件特性、軟件實(shí)現(xiàn)、系統(tǒng)環(huán)境等諸多因素影響,呈現(xiàn)出復(fù)雜的特性。因此,在手頭有硬件且測試方便的情況下,?實(shí)測是最準(zhǔn)確的性能評估方式?。
在設(shè)計網(wǎng)絡(luò)結(jié)構(gòu)時,如果有實(shí)測的條件,建議在模型迭代早期對性能也進(jìn)行測試。一些 NAS的方法也會對搜索出來的網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行測速,或者干脆對硬件速度進(jìn)行了建模,也作為初期搜索的重要參數(shù)。這種方法設(shè)計出來的網(wǎng)絡(luò)在后期部署時,會極大減少因性能問題迭代優(yōu)化的時間和人力開銷。
這里我將討論影響模型在硬件上推理速度的一些因素,一方面希望可以幫助手動/自動設(shè)計網(wǎng)絡(luò)結(jié)構(gòu)的同學(xué)更快的設(shè)計更高效的網(wǎng)絡(luò)結(jié)構(gòu),另一方面希望當(dāng)模型部署時性能出現(xiàn)問題時能夠?yàn)榇蠹姨峁┓治鲈虻乃悸贰?/p>
這一問題我將從如下 3 個點(diǎn)進(jìn)行討論:
計算密度與 RoofLine 模型 計算密集型算子與訪存密集型算子 推理時間
1. 計算密度與 RoofLine 模型
計算密度?是指一個程序在單位訪存量下所需的計算量,單位是 FLOPs/Byte。其計算公式很簡單,很多教材、資料里也稱之為?計算訪存比,用于反映一個程序相對于訪存來說計算的密集程度:
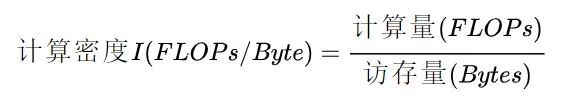
RoofLine 模型?是一個用于評估程序在硬件上能達(dá)到的?性能上界?的模型,可用下圖表示:
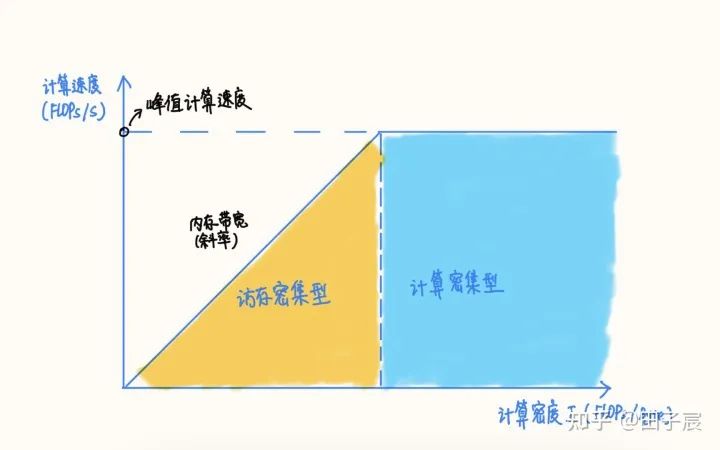
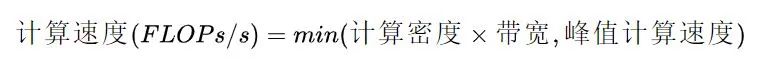
當(dāng)程序的?計算密度I?較小時,程序訪存多而計算少,性能受內(nèi)存帶寬限制,稱為?訪存密集型程序,即圖中橙色區(qū)域。在此區(qū)域的程序性能上界=計算密度×內(nèi)存帶寬,表現(xiàn)為圖中的斜線,其中斜率為內(nèi)存帶寬的大小。計算密度越大,程序所能達(dá)到的速度上界越高,但使用的內(nèi)存帶寬始終為最大值。
反之如果計算密度I較大,程序性能受?硬件最大計算峰值?(下文簡稱為?算力?)限制,稱為?計算密集型程序,即圖中藍(lán)色區(qū)域。此時性能上界=硬件算力,表現(xiàn)為圖中的橫線。此時計算速度不受計算密度影響,但計算密度越大,所需內(nèi)存帶寬就越少。
在兩條線的交點(diǎn)處,計算速度和內(nèi)存帶寬同時到達(dá)最大值。
2. 計算密集型算子與訪存密集型算子
網(wǎng)絡(luò)中的算子可以根據(jù)計算密度進(jìn)行分類。一般來講,?Conv、FC、Deconv 算子屬于計算密集型算子;ReLU、EltWise Add、Concat等屬于訪存密集型算子。
同一個算子也會因參數(shù)的不同而導(dǎo)致計算密度變化,甚至改變性質(zhì)?,比如在其他參數(shù)不變的前提下,增大 Conv 的 group,或者減小 Conv 的input channel 都會減小計算密度。
舉個栗子,對于不同參數(shù)的卷積,計算密度如下:

可以看到,不同參數(shù)下卷積算子的計算密度有很大的差異。第 4 個算子 Depthwise Conv 計算密度僅有2.346,在當(dāng)下的很多設(shè)備上都屬于訪存密集型算子。
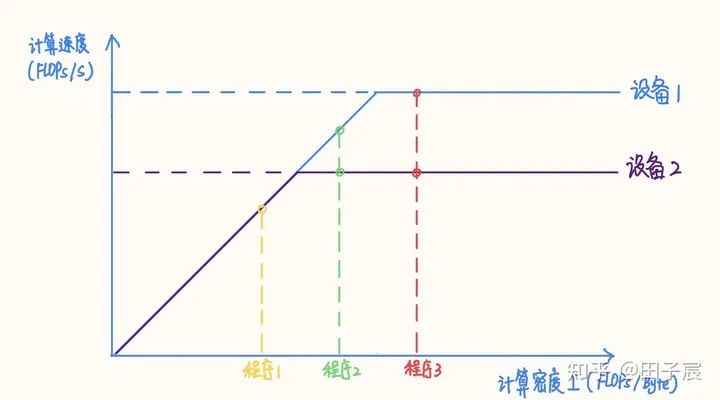
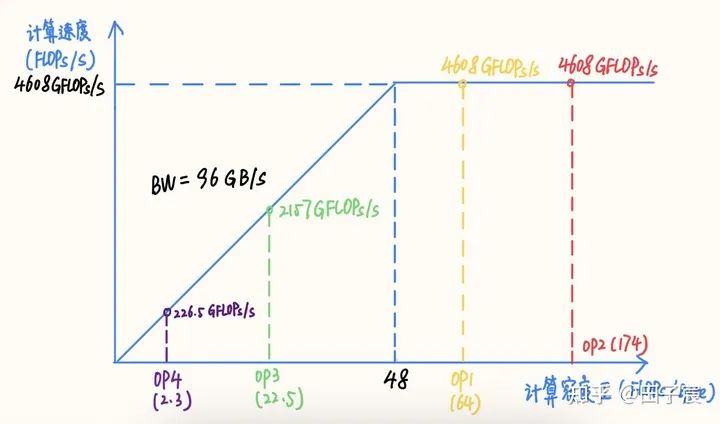
算子的計算密度越大,約有可能提升硬件的計算效率,充分發(fā)揮硬件性能?。我們以一個 Intel X86 服務(wù)器平臺為例(10980 XE)。該平臺CPU 頻率為 4.5 GHz,我們以 16 核為例,其理論 FP32 算力為 4.608 TFLOPs/s,內(nèi)存帶寬理論值為 96 GB/s。在此平臺上的RoofLine 模型為:
3. 推理時間
這里涉及到一個 gap,很多部署的同學(xué)們更喜歡談“計算效率”,而實(shí)際上算法同學(xué)真正關(guān)心的點(diǎn)是“推理時間”,導(dǎo)致兩者在對接的時候經(jīng)常會出現(xiàn)一些misleading。因此我這里單獨(dú)開一節(jié)來探討一下“推理時間”的評估方法。
其實(shí)也很簡單,按照 RoofLine 模型,我們很容易就能得到算子實(shí)際的執(zhí)行時間:

這是一個分段函數(shù),拆開來可得:

一句話總結(jié):對于訪存密集型算子,推理時間跟訪存量呈線性關(guān)系,而對于計算密集型算子,推理時間跟計算量呈線性關(guān)系?。
講到這里,我們就能?初步?回答本章一開始的問題了:按照 RoofLine模型,在計算密集區(qū),計算量越小,確實(shí)推理時間越小。但是在訪存密集區(qū),計算量與推理時間沒關(guān)系,真正起作用的是訪存量,訪存量越小,推理的時間才越快。在全局上,計算量和推理時間并非具有線性關(guān)系。
上一節(jié)中,OP4 雖然計算效率很低,但由于訪存量也很低,因此其實(shí)推理速度還是快于其他幾個 OP 的。但是我們可以觀察到,其計算量雖然只有 OP1 的1/130,但是推理時間僅降低到了 1/6,兩者并非是線性關(guān)系(也是當(dāng)年我把模型減到 1/10 計算量,但其實(shí)沒快多少的原因)。
再舉兩個例子強(qiáng)化一下,首先看這兩個卷積,他們的計算量差不多,但是因?yàn)槎荚谠L存密集區(qū),OP3 的訪存量遠(yuǎn)低于 OP5,其推理也更快:

下面這個栗子更明顯,OP5 和 OP6 的區(qū)別僅僅是一個是 DepthWise Conv,一個是普通Conv,其他參數(shù)沒有變化。按照我們之前的直觀感受,Conv 換成 DepthWise Conv應(yīng)該會更快,但實(shí)際上兩者的推理時間是差不多的(這組參數(shù)也是當(dāng)年我用過的【手動捂臉):

4. 小結(jié)
從上面的討論中我們可以看出:計算量并不能單獨(dú)用來評估模型的推理時間,還必須結(jié)合硬件特性(算力&帶寬),以及訪存量來進(jìn)行綜合評估。并非是計算量越低模型推理越快。在評價模型大小時,也建議加上訪存量作為重要的評價指標(biāo)?。
需要強(qiáng)調(diào)的一點(diǎn)是,不同的硬件平臺峰值算力和內(nèi)存帶寬不同,導(dǎo)致同一個模型在平臺 1 上可能是計算密集的,在平臺 2 上可能就變成了訪存密集的。例如上文提到的Intel X86 平臺,“拐點(diǎn)”值為 48,而 NVIDIA V100“拐點(diǎn)”值為 173.6,上文舉的例子在 V100 平臺上僅有 OP2落在了計算密集區(qū),剩下的全部是訪存密集的。因此,?同樣的模型在不同平臺上性質(zhì)可能會發(fā)生改變?,需要具體情況具體分析。
我們很難給出一個通用性的結(jié)論,究其原因是 RoofLine 模型本身是一個非線性模型。這里必須要強(qiáng)調(diào)一點(diǎn)的是,除了峰值算力和內(nèi)存帶寬之外,還有硬件限制、系統(tǒng)環(huán)境、軟件實(shí)現(xiàn)等諸多因素會影響程序的實(shí)際性能,使得其非線性特性更加嚴(yán)重。因此 RoofLine模型僅僅只能提供一個性能上界的評估方式,并不代表能夠達(dá)到的實(shí)際性能。實(shí)際性能最準(zhǔn)確的測量方式只有真機(jī)實(shí)測?。
RoofLine模型更重要的是提供了一種分析性能的思想,即計算密集型程序更多的受限于硬件算力,而訪存密集型程序更多的受限于硬件內(nèi)存帶寬。在理解這一點(diǎn)的基礎(chǔ)上設(shè)計網(wǎng)絡(luò)結(jié)構(gòu),并分析網(wǎng)絡(luò)的性能,將更有理論參考。不會再對”計算量減半,為啥推理時間沒變“這種問題抱有疑問了(說的就是我【流淚)
下文將對 RoofLine 模型的一些限制進(jìn)行討論,分析哪些因素將以何種方式影響程序,使得其到達(dá)不了 RoofLine 模型估計的性能上界。
(下文要開始難度升級了,建議沒看懂 RoofLine 模型的同學(xué)們再把這一章看一遍,不然后面會看的有點(diǎn)懵)
三、影響模型推理性能的其他因素
RoofLine模型可以用來評估程序的性能上界,但是實(shí)際能達(dá)到的性能還會受到硬件限制、系統(tǒng)環(huán)境、軟件實(shí)現(xiàn)等諸多因素的影響,距離性能上界有一定距離。本章將對這些影響因素進(jìn)行分析。
1. 硬件限制對性能上界的影響
前面 RoofLine 模型使用的峰值算力及內(nèi)存帶寬,是根據(jù)紙面數(shù)據(jù)計算得到的,是理論上的最大值。但在實(shí)際情況下,硬件會因?yàn)榉N種原因,無法達(dá)到這個理論值。因此建議大家對硬件進(jìn)行micro-benchmark,以獲取硬件的真實(shí)性能上限?。
以上文的 Intel X86 CPU 為例,我們之前計算的 avx512 理論算力為 4.608 TFLOPs/s,但這個數(shù)值的前提是頻率能維持在 4.5GHz。然而實(shí)際上在使用 16 核跑 avx512 指令時,CPU 頻率會下降到約 2.9 GHz,此時理論算力僅剩下 2.96TFLOPs/s,而實(shí)測值僅有 2.86 TFLOPs/s。
除了頻率之外,有些芯片可能會因?yàn)橐恍┰O(shè)計上或?qū)崿F(xiàn)上的原因,導(dǎo)致在實(shí)際使用時達(dá)不到理論峰值。比如一些低端芯片不支持多發(fā)射、不支持亂序執(zhí)行、采用了阻塞式Cache 等等,一些芯片甚至?xí)幸恍┬阅?bug,導(dǎo)致在實(shí)際使用時幾乎到達(dá)不了理論峰值(這里我個人傾向于把這些原因歸結(jié)為硬件限制帶來的損失)。
內(nèi)存同理,該平臺理論帶寬為 96GB/s,但實(shí)測下來最高讀帶寬僅有 74 GB/s,僅能到達(dá)理論帶寬的 77%。
我們可以得到修正后的 RoofLine 模型,圖中藍(lán)色填充部分反映了因?qū)嶋H算力和內(nèi)存帶寬達(dá)到不了理論值而造成的損失:
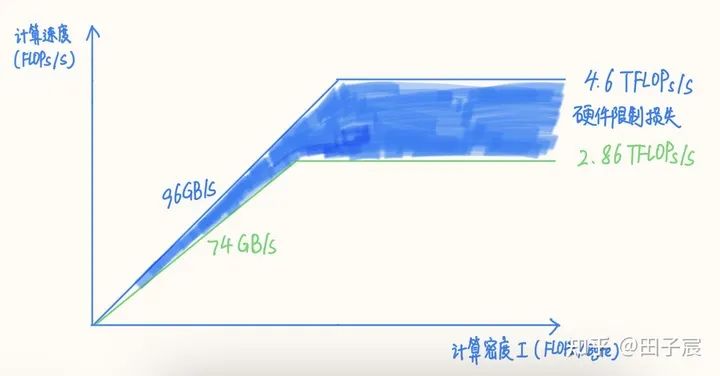
修正后的模型“拐點(diǎn)”發(fā)生了變化,因此算子的性質(zhì)也會發(fā)生變化。建議拿到硬件后對硬件進(jìn)行 micro-benchmark,這里推薦兩個測試工具:
一個是高叔叔寫的浮點(diǎn)峰值測試方法的文章,最后有 github 鏈接,大家可以 clone 下來測試硬件峰值:
https://zhuanlan.zhihu.com/p/28226956
還有一個是 stream 測試工具,可以用于測試內(nèi)存帶寬:
https://www.cs.virginia.edu/stream/
2. 系統(tǒng)環(huán)境對性能的影響
除非程序運(yùn)行在裸機(jī)中,否則操作系統(tǒng)一定會對性能上界產(chǎn)生一定影響,比如操作系統(tǒng)在多核間的調(diào)度損失、操作系統(tǒng)的內(nèi)存管理帶來的損失、操作系統(tǒng)本身占用的運(yùn)算資源等等。
對于一般的深度學(xué)習(xí)推理任務(wù)而言,現(xiàn)代操作系統(tǒng)對性能的影響并不是特別明顯。但是在一些特殊情況下,也會帶來嚴(yán)重的性能損失。我這里將會舉兩個例子:
一個是 Android 系統(tǒng)在大小核上的調(diào)度,一旦程序在 CPU 上的占用率不足(比如是周期工作的任務(wù)),則有可能被 Android調(diào)度到小核上,帶來性能損失。
另一個例子是內(nèi)存缺頁。在 Linux系統(tǒng)上,當(dāng)向系統(tǒng)申請內(nèi)存頁后,系統(tǒng)只是返回了虛擬頁,等到程序?qū)嶋H使用虛擬頁時,才會通過觸發(fā)缺頁異常的方式,進(jìn)入操作系統(tǒng)內(nèi)核分配物理頁,這一過程會嚴(yán)重降低性能。
好在這些問題可以通過軟件進(jìn)行一部分彌補(bǔ),例如調(diào)度問題可以使用綁核來解決,缺頁問題可以通過綁定物理頁(需要內(nèi)核態(tài))或內(nèi)存池來解決。因此操作系統(tǒng)帶來的影響是可控的。
除了操作系統(tǒng)帶來的影響,系統(tǒng)中運(yùn)行的其他進(jìn)程也會對當(dāng)前進(jìn)程造成影響。比如一個系統(tǒng)中運(yùn)行了多個深度學(xué)習(xí)實(shí)例,或者系統(tǒng)后臺一些 APP自啟動了等等。這些進(jìn)程都會占用核心算力和內(nèi)存帶寬,造成當(dāng)前進(jìn)程性能損失。
這往往會導(dǎo)致在工程測試環(huán)境下性能達(dá)標(biāo)的模型,在實(shí)際部署時性能下降。因此,?必須關(guān)注工程測試環(huán)境和實(shí)際部署系統(tǒng)環(huán)境的差異。如有條件,最好在實(shí)際部署環(huán)境下進(jìn)行測試。
3. 軟件實(shí)現(xiàn)對性能的影響
除了硬件限制和系統(tǒng)環(huán)境外,?一個任務(wù)的軟件實(shí)現(xiàn)好壞對性能有著重大的影響?。
例如對于同樣的矩陣操作任務(wù),使用 python 寫的多重 for 循環(huán),和用 numpy 高度優(yōu)化過的矩陣操作函數(shù),性能可以差出 1~2 個數(shù)量級。
對于深度學(xué)習(xí)模型推理而言,推理框架對模型性能的影響主要體現(xiàn)在:是否充分利用了硬件的流水線資源、是否高效利用了硬件中的緩存、是否采用了時間復(fù)雜度更低的算法、是否解決了操作系統(tǒng)帶來的性能損失(如上文的調(diào)度問題和內(nèi)存缺頁問題)、是否進(jìn)行了正確高效的圖優(yōu)化等等。
由于影響因素很多,因此?軟件對性能的影響往往呈現(xiàn)出很強(qiáng)的非線性?,導(dǎo)致在評估性能時很難給出一些普適性的結(jié)論,?很多時候只能具體情況具體分析。(有的時候甚至有點(diǎn)玄學(xué)【捂臉)
例如同樣計算量的向量四則運(yùn)算和超越函數(shù),后者往往會慢于前者的原因是很多硬件不支持超越函數(shù)的 SIMD 指令;再比如空洞卷積(dilated Conv)性能會弱于普通卷積的原因是前者對訪存的利用不如后者高效等等。
在軟件實(shí)現(xiàn)的影響下,RoofLine 模型的上界再次下降,達(dá)到圖中的紅線(真實(shí)的非線性可能會比我隨手畫的要復(fù)雜的多):
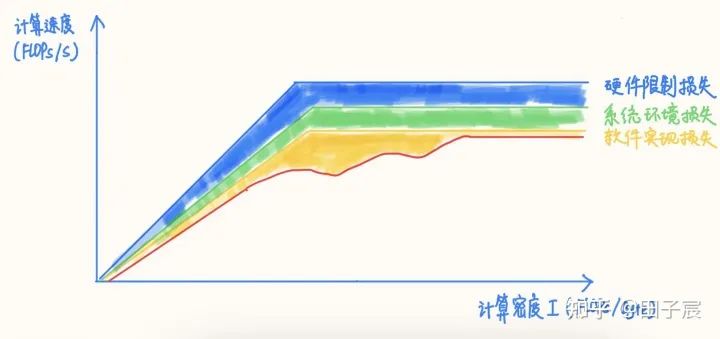
因此,在評估或分析深度學(xué)習(xí)推理性能時,簡單的計算量/訪存量指標(biāo)是完全不夠的,只能做個性能上界參考。實(shí)際能達(dá)到的性能其實(shí)還要關(guān)注很多很多因素,例如算子的訪存模式、數(shù)據(jù)排布、是否能夠進(jìn)行圖融合、是否有精度可接受的低時間復(fù)雜度算法、算法并行度是否充足、各種運(yùn)算的比例等等因素。
這些因素對于算法同學(xué)而言可能過于復(fù)雜,并不需要掌握。但如果所在的公司/部門有交流的機(jī)會的話,可以跟部署/優(yōu)化的同學(xué)針對模型結(jié)構(gòu)和算子進(jìn)行探討,以獲取性能優(yōu)化的建議。
這里可以一些?一般性的結(jié)論?,僅供參考:
對于一些訪存非常密集且訪存 pattern 連續(xù)的算子,如 Concat、Eltwise Sum、ReLU、LeakyReLU、ReflectionPad 等,在 Tensor 數(shù)據(jù)量很大的情況下,軟件實(shí)現(xiàn)的損失會非常小,正常情況下基本都能達(dá)到內(nèi)存帶寬實(shí)測上限;如果框架采用了融合策略的話,基本可以達(dá)到 0 開銷。
對于 Conv/FC/Deconv 等算子,在計算密度很高的情況下,大多數(shù)框架是能夠很接近算力峰值的。但對于計算密度不是特別高的 case,不同框架的表現(xiàn)不一,需要實(shí)測才能確定。不過從大趨勢而言,都是計算密度越高,硬件的利用率越高的。
盡量使用常用的算子參數(shù),例如 Conv 盡量使用 3x3_s1/s2,1x1 ___ s1/s2 等,這些常用參數(shù)往往會被特殊優(yōu)化,性能更好。
4. 小結(jié)
RoofLine 模型僅能用于估計模型所能達(dá)到的性能上界,而實(shí)際部署時,還會受硬件限制、系統(tǒng)環(huán)境、軟件實(shí)現(xiàn)等因素的影響,導(dǎo)致無法達(dá)到 RoofLine模型所定義的性能上界。
此外,由于這些因素往往會導(dǎo)致性能曲線有較強(qiáng)的非線性,理論分析和實(shí)測會有一定差距,有時這些因素會嚴(yán)重影響性能曲線,甚至?xí)?dǎo)致算子的性質(zhì)發(fā)生變化。因此本節(jié)討論的內(nèi)容只是提供一些分析的思路與技巧,實(shí)測始終是最準(zhǔn)確的性能評估方式?。
四、面向推理速度的模型設(shè)計建議
前面討論了一大堆,其實(shí)最實(shí)用的還是“怎么設(shè)計模型能夠達(dá)到更快的推理速度”。
在給出我的個人建議之前,首先要先聲明的是:由于不同硬件、不同環(huán)境、不同框架的差異會很大,這些建議可能并不是在所有條件下都適用。在設(shè)計算法或性能測試遇到疑問時,建議咨詢部署/優(yōu)化的同學(xué)。
好了,廢話不多說(其實(shí)已經(jīng)說了很多了),給出我的一些個人建議:
方法論建議?:
了解目標(biāo)硬件的峰值算力和內(nèi)存帶寬,最好是實(shí)測值,用于指導(dǎo)網(wǎng)絡(luò)設(shè)計和算子參數(shù)選擇。 明確測試環(huán)境和實(shí)際部署環(huán)境的差異,最好能夠在實(shí)際部署環(huán)境下測試性能,或者在測試環(huán)境下模擬實(shí)際部署環(huán)境。 針對不同的硬件平臺,可以設(shè)計不同計算密度的網(wǎng)絡(luò),以在各個平臺上充分發(fā)揮硬件計算能力(雖然工作量可能會翻好幾倍【捂臉)。 除了使用計算量來表示/對比模型大小外,建議引入訪存量、特定平臺執(zhí)行時間,來綜合反映模型大小。 實(shí)測是最準(zhǔn)確的性能評估方式,如果有條件快速實(shí)測的話,建議以實(shí)測與理論分析相結(jié)合的方式設(shè)計并迭代網(wǎng)絡(luò)。 遇到性能問題時,可以逐層 profiling,并與部署/優(yōu)化同學(xué)保持緊密溝通,具體問題具體分析(適當(dāng)了解一下計算相關(guān)理論的話,可以更高效的溝通)。
網(wǎng)絡(luò)設(shè)計建議?:
對于低算力平臺(CPU、低端 GPU 等),模型很容易受限于硬件計算能力,因此可以采用計算量低的網(wǎng)絡(luò)來降低推理時間。 對于高算力平臺(GPU、DSP 等),一味降低計算量來降低推理時間就并不可取了,往往更需要關(guān)注訪存量。單純降低計算量,很容易導(dǎo)致網(wǎng)絡(luò)落到硬件的訪存密集區(qū),導(dǎo)致推理時間與計算量不成線性關(guān)系,反而跟訪存量呈強(qiáng)相關(guān)(而這類硬件往往內(nèi)存弱于計算)。相對于低計算密度網(wǎng)絡(luò)而言,高計算密度網(wǎng)絡(luò)有可能因?yàn)橛布矢撸臅r不變乃至于更短。 面向推理性能設(shè)計網(wǎng)絡(luò)結(jié)構(gòu)時,盡量采用經(jīng)典結(jié)構(gòu),大部分框架會對這類結(jié)構(gòu)進(jìn)行圖優(yōu)化,能夠有效減少計算量與訪存量。例如 Conv->BN->ReLU 就會融合成一個算子,但 Conv->ReLU->BN 就無法直接融合 BN 層 算子的參數(shù)盡量使用常用配置,如 Conv 盡量使用 3x3_s1/s2、1x1 ___ s1/s2 等,軟件會對這些特殊參數(shù)做特殊優(yōu)化。 CNN 網(wǎng)絡(luò) channel 數(shù)盡量選擇 4/8/16/32 的冪次,很多框架的很多算子實(shí)現(xiàn)在這樣的 channel 數(shù)下效果更好(具體用多少不同平臺不同框架不太一樣)。 框架除了計算耗時外,也處理網(wǎng)絡(luò)拓?fù)洹?nèi)存池、線程池等開銷,這些開銷跟網(wǎng)絡(luò)層數(shù)成正比。因此相比于“大而淺”的網(wǎng)絡(luò),“小而深”的網(wǎng)絡(luò)這部分開銷更大。一般情況下這部分開銷占比不大。但在網(wǎng)絡(luò)算子非常碎、層數(shù)非常多的時候,這部分開銷有可能會影響多線程的擴(kuò)展性,乃至于成為不可忽視的耗時因素。
一些其他建議?:
除了優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu)、推理框架性能外,還可以考慮通過一些其他工程技巧來提升系統(tǒng)整體的性能。例如:對推理服務(wù)流水化,并行數(shù)據(jù)讀取與計算的過程,掩蓋 IO 延時。
本文介紹了評估模型大小的四個常用指標(biāo)——計算量、參數(shù)量、訪存量、內(nèi)存占用,從 RoofLine模型入手詳細(xì)討論了影響模型推理速度的影響因素,并給出了面向推理速度的模型設(shè)計方法論與建議。
撰寫本文的目的,不僅僅是給算法同學(xué)提供有效的網(wǎng)絡(luò)設(shè)計建議,更多的還是希望能夠傳達(dá)性能優(yōu)化的基礎(chǔ)知識與分析思路,減少算法設(shè)計到部署之間的gap,更快速高效的設(shè)計推理友好的網(wǎng)絡(luò)模型。希望能對大家的工作有所幫助。
看到評論區(qū)有人問有沒有訪存量小的模型結(jié)構(gòu)。一些研究工作,例如 ShuffleNetV2, 已經(jīng)在設(shè)計網(wǎng)絡(luò)的時候兼顧訪存量了。但據(jù)我所知目前還沒有像DepthWise Conv 一樣經(jīng)典的節(jié)省訪存量的模型結(jié)構(gòu)。
關(guān)于這個問題,我個人是這么看的:
訪存量可以減小,但網(wǎng)絡(luò)精度很難保證不變,因此需要一系列的研究來探索 一些白給訪存量的技巧可以用上,一些白白浪費(fèi)訪存量的操作不要搞 低精度/量化有的時候節(jié)省訪存量的意義遠(yuǎn)大于節(jié)省計算量
回顧 Xception/ MobileNet 的研究就可以看出,DWConv 3X3 + Conv 1X1的結(jié)構(gòu)之所以成為經(jīng)典結(jié)構(gòu),一方面是計算量確實(shí)減少了,另一方面也是其精度確實(shí)沒有太大的損失。計算量可以在設(shè)計完網(wǎng)絡(luò)時就可以算出,但網(wǎng)絡(luò)精度只有在網(wǎng)絡(luò)訓(xùn)練完之后才能評估,需要花費(fèi)大量的時間與精力反復(fù)探索才能找到這一結(jié)構(gòu)。
一些研究確實(shí)開始關(guān)注訪存量對推理速度的影響,例如 ShuffleNetV2 在選定 group 的時候就是以訪存量為依據(jù)的,但并不是整體的 block都是圍繞降低訪存量來設(shè)計的。由于本人很久沒有關(guān)注算法的研究進(jìn)展了,據(jù)我所知目前是沒有專注于減少放存量的模型結(jié)構(gòu)及研究工作的(如果有的話歡迎在評論區(qū)留言)。
我個人認(rèn)為這可以成為一個很好的研究主題,可以為模型部署帶來很大的幫助。一種方法是可以通過手工設(shè)計網(wǎng)絡(luò)結(jié)構(gòu),另一種方法是可以將訪存量作為 NAS的一個參數(shù)進(jìn)行搜索。前者可解釋性更強(qiáng)一些,后者可能研究起來更容易。但是有一點(diǎn)請務(wù)必注意:降低訪存量的最終目的一定是為了減少模型的推理時間。如果模型處在目標(biāo)設(shè)備的計算密集區(qū),降低訪存量的意義有限。
關(guān)于實(shí)際工程部署,有一些技巧/注意的點(diǎn)可以保證不浪費(fèi)訪存量:
channel 數(shù)盡量保持在 4/8/16/32 的倍數(shù),不要設(shè)計 channel = 23 這種結(jié)構(gòu)。目前大部分推理框架為了加速計算,都會用特殊的數(shù)據(jù)排布,channel 會向上 pad。比如框架會把 channel pad 到 4 的倍數(shù),那么 channel = 23 和 24 在訪存量上其實(shí)是一致的。 一些非常細(xì)碎乃至毫無意義的后處理算子,例如 Gather、Squeeze、Unsqueeze 等,最好給融合掉。這種現(xiàn)象往往見于 PyTorch 導(dǎo)出 onnx 的時候,可以嘗試使用 onnxsim 等工具來進(jìn)行融合,或者手動添加大算子。 嘗試一些部署無感的技巧,例如蒸餾、RepVGG(感謝 @OLDPAN )等。
最后想聊一下低精度/量化。對于設(shè)備算力很強(qiáng)但模型很小的情況,低精度/量化我個人認(rèn)為其降低訪存量的作用要遠(yuǎn)大于節(jié)省計算量,可以有效加快模型推理速度。但是要注意兩點(diǎn):一個是框架如果不支持requant,而是每次計算前都量化一次,計算完之后再反量化,那么使用低精度/量化反而會增加訪存量,可能造成推理性能的下降;另一個是對于支持混合精度推理的框架,要注意不同精度轉(zhuǎn)換時是否會有額外的性能開銷。如果有的話,要盡量減少精度的轉(zhuǎn)換。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有美顏、三維視覺、計算攝影、檢測、分割、識別、NeRF、GAN、算法競賽等微信群
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR,即可下載1467篇CVPR?2020論文 和 CVPR 2021 最新論文
