
GPT-5出世,需5萬張H100!全球H100總需求43萬張, 英偉達(dá)GPU陷短缺風(fēng)暴
【導(dǎo)讀】GPT-5的訓(xùn)練,需要5萬張H100加持。英偉達(dá)GPU已成為各大AI公司開發(fā)大模型的首選利器。然而,Sam Altaman自曝GPU很缺,竟不希望太多人用ChatGPT。
「誰將獲得多少H100,何時(shí)獲得H100,都是硅谷中最熱門的話題。」
OpenAI聯(lián)合創(chuàng)始人兼職科學(xué)家Andrej Karpathy近日發(fā)文,闡述了自己對英偉達(dá)GPU短缺的看法。

近來,社區(qū)廣為流傳的一張圖「我們需要多少張GPU」,引發(fā)了眾多網(wǎng)友的討論。

根據(jù)圖中內(nèi)容所示:
– Inflection使用了3500和H100,來訓(xùn)練與GPT-3.5能力相當(dāng)?shù)哪P?/span>
另外,根據(jù)馬斯克的說法,GPT-5可能需要30000-50000個(gè)H100。
此前,摩根士丹利曾表示GPT-5使用25000個(gè)GPU,自2月以來已經(jīng)開始訓(xùn)練,不過Sam Altman之后澄清了GPT-5尚未進(jìn)行訓(xùn)。
不過,Altman此前表示,
我們的GPU非常短缺,使用我們產(chǎn)品的人越少越好。
如果人們用的越少,我們會(huì)很開心,因?yàn)槲覀儧]有足夠的GPU。

在這篇名為「Nvidia H100 GPU:供需」文章中,深度剖析了當(dāng)前科技公司們對GPU的使用情況和需求。
文章推測,小型和大型云提供商的大規(guī)模H100集群容量即將耗盡,H100的需求趨勢至少會(huì)持續(xù)到2024年底。

那么,GPU需求真的是遇到了瓶頸嗎?
各大公司GPU需求:約43萬張H100
當(dāng)前,生成式AI爆發(fā)仍舊沒有放緩,對算力提出了更高的要求。
一些初創(chuàng)公司都在使用英偉達(dá)昂貴、且性能極高的H100來訓(xùn)練模型。
馬斯克說,GPU在這一點(diǎn)上,比藥物更難獲得。
Sam Altman說,OpenAI受到GPU的限制,這推遲了他們的短期計(jì)劃(微調(diào)、專用容量、32k上下文窗口、多模態(tài))。

Karpathy 發(fā)表此番言論之際,大型科技公司的年度報(bào)告,甚至都在討論與GPU訪問相關(guān)的問題。
上周,微軟發(fā)布了年度報(bào)告,并向投資者強(qiáng)調(diào),GPU是其云業(yè)務(wù)快速增長的「關(guān)鍵原材料」。如果無法獲得所需的基礎(chǔ)設(shè)施,可能會(huì)出現(xiàn)數(shù)據(jù)中心中斷的風(fēng)險(xiǎn)因素。

這篇文章?lián)Q是由HK發(fā)帖的作者所寫。

他猜測,OpenAI可能需要50000個(gè)H100,而Inflection需要22,000個(gè),Meta可能需要 25k,而大型云服務(wù)商可能需要30k(比如Azure、Google Cloud、AWS、Oracle)。
Lambda和CoreWeave以及其他私有云可能總共需要100k。他寫道,Anthropic、Helsing、Mistral和Character 可能各需要10k。
作者表示,這些完全是粗略估計(jì)和猜測,其中有些是重復(fù)計(jì)算云和從云租用設(shè)備的最終客戶。

整體算來,全球公司需要約432000張H100。按每個(gè)H100約35k美元來計(jì)算,GPU總需求耗資150億美元。
這其中還不包括國內(nèi),大量需要像H800的互聯(lián)網(wǎng)公司。
還有一些知名的金融公司,比如Jane Street、JP Morgan、Two Sigma等,每家都在進(jìn)行部署,從數(shù)百張A/H100開始,擴(kuò)展到數(shù)千張A/H100。

包括OpenAI、Anthropic、DeepMind、谷歌,以及X.ai在內(nèi)的所有大型實(shí)驗(yàn)室都在進(jìn)行大型語言模型的訓(xùn)練,而英偉達(dá)的H100是無可替代的。
H100為什么成首選?
H100比A100更受歡迎,成為首選,部分原因是緩存延遲更低和FP8計(jì)算。
因?yàn)樗男矢哌_(dá)3倍,但成本只有(1.5-2倍)。考慮到整體系統(tǒng)成本,H100的性能要高得多。
從技術(shù)細(xì)節(jié)來說,比起A100,H100在16位推理速度大約快3.5倍,16位訓(xùn)練速度大約快2.3倍。
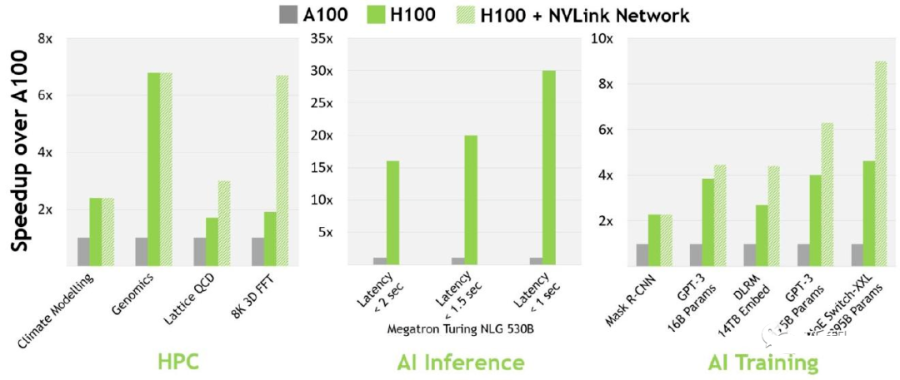
A100 vs H100速度

H100訓(xùn)練MoE
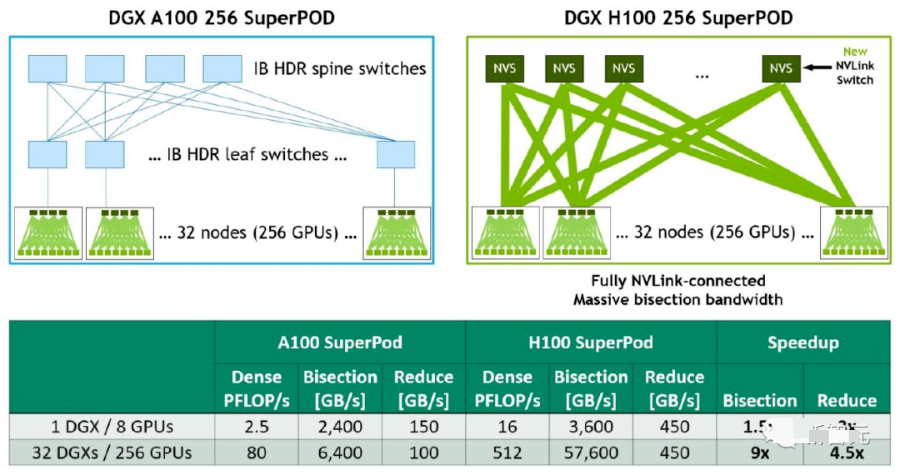
H100大規(guī)模加速
大多數(shù)公司購買H100,并將其用于訓(xùn)練和推理,而A100主要用于推理。
但是,由于成本、容量、使用新硬件和設(shè)置新硬件的風(fēng)險(xiǎn),以及現(xiàn)有的軟件已經(jīng)針對A100進(jìn)行了優(yōu)化,有些公司會(huì)猶豫是否要切換。
GPU 并不短缺,而是供應(yīng)鏈問題
英偉達(dá)的一位高管表示,問題不在于 GPU 短缺,而在于這些 GPU 如何進(jìn)入市場。
英偉達(dá)正在正在開足馬力生產(chǎn)GPU,但是這位高管稱,GPU的產(chǎn)能最主要受到的是供應(yīng)鏈的限制。
芯片本身可能產(chǎn)能充足,但是其他的組件的產(chǎn)能不足會(huì)嚴(yán)重限制GPU的產(chǎn)能。
這些組件的生產(chǎn)要依賴整個(gè)世界范圍內(nèi)的其他供應(yīng)商。
不過需求是可以預(yù)測的,所以現(xiàn)在問題正在逐漸得到解決。
GPU芯片的產(chǎn)能情況
首先,英偉達(dá)只與臺積電合作生產(chǎn)H100。英偉達(dá)所有的5nmGPU都只與臺積電合作。

未來可能會(huì)與英特爾和三星合作,但是短期內(nèi)不可能,這就使得H100的生產(chǎn)受到了限制。
根據(jù)爆料者稱,臺積電有4個(gè)生產(chǎn)節(jié)點(diǎn)為5nm芯片提供產(chǎn)能:N5,N5P,N4,N5P
而H100只在N5或者是N5P的中的4N節(jié)點(diǎn)上生產(chǎn),是一個(gè)5nm的增強(qiáng)型節(jié)點(diǎn)。
而英偉達(dá)需要和蘋果,高通和AMD共享這個(gè)節(jié)點(diǎn)的產(chǎn)能。
而臺積電晶圓廠需要提前12個(gè)月就對各個(gè)客戶的產(chǎn)能搭配做出規(guī)劃。
如果之前英偉達(dá)和臺積電低估了H100的需求,那么現(xiàn)在產(chǎn)能就會(huì)受到限制。
而爆料者稱,H100到從生產(chǎn)到出廠大約需要半年的時(shí)間。
而且爆料者還援引某位退休的半導(dǎo)體行業(yè)專業(yè)人士的說法,晶圓廠并不是臺積電的生產(chǎn)瓶頸,CoWoS(3D堆疊)封裝才是臺積電的產(chǎn)能大門。
H100內(nèi)存產(chǎn)能
而對于H100上的另一個(gè)重要組件,H100內(nèi)存,也可能存在產(chǎn)能不足的問題。
與GPU以一種特殊方式集成的HBM(High Bandwidth Memory)是保障GPU性能的關(guān)鍵組件。
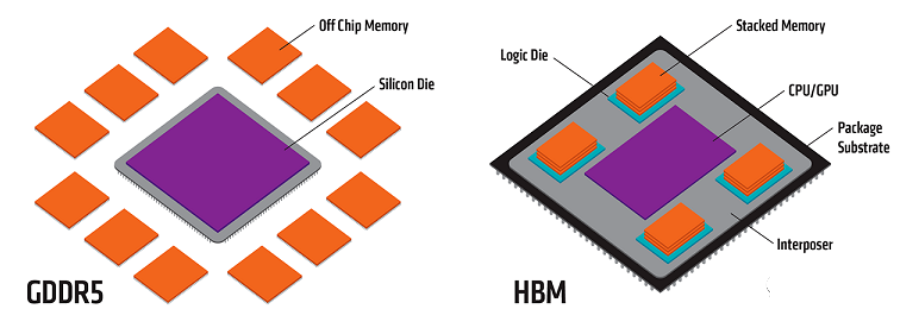
爆料者援引一位業(yè)內(nèi)人士的說法:
主要的問題是 HBM。制造它是一場噩夢。由于 HBM 很難生產(chǎn),供應(yīng)也非常有限。生產(chǎn)和設(shè)計(jì)都必須按照它的節(jié)奏來。
HBM3內(nèi)存,英偉達(dá)幾乎都是采用SK Hynix的產(chǎn)品,可能會(huì)有一部分三星的產(chǎn)品,應(yīng)該沒有鎂光的產(chǎn)品。
英偉達(dá)希望SK Hynix能提高產(chǎn)能,他們也在這么做。但是三星和鎂光的產(chǎn)能都很有限。
而且制造GPU還會(huì)用到包括稀土元素在內(nèi)的許多其他材料和工藝,也會(huì)成為限制GPU產(chǎn)能的可能因素。
GPU芯片未來的情況會(huì)怎么發(fā)展
英偉達(dá)的說法
英偉達(dá)只是透露,下半年他們能夠供應(yīng)更多的GPU,但是沒有提供任何定量的信息。
我們今天正在處理本季度的供應(yīng),但我們也為下半年采購了大量供應(yīng)。
我們相信下半年的供應(yīng)量將大大高于上半年。
– 英偉達(dá)首席財(cái)務(wù)官 Colette Kress 在2023年2月至4月的財(cái)報(bào)電話會(huì)議上透露
接下來會(huì)發(fā)生什么?
GPU的供應(yīng)問題現(xiàn)在是一個(gè)惡性循環(huán),稀缺性導(dǎo)致GPU擁有量被視為護(hù)城河,從而導(dǎo)致更多的GPU被囤積起來,從而加劇稀缺性。
– 某私有云負(fù)責(zé)人透露
H100的下一代產(chǎn)品何時(shí)會(huì)出現(xiàn)?
根據(jù)英偉達(dá)之前的線路圖,H100的下一代產(chǎn)品要在2024年末到2025年初才會(huì)宣布。
在那個(gè)時(shí)間點(diǎn)之前,H100都會(huì)是英偉達(dá)的旗艦產(chǎn)品。
不過英偉達(dá)在此期間內(nèi)會(huì)推出120GB水冷版的H100。
而根據(jù)爆料者采訪到的業(yè)內(nèi)人士稱,到2023年底的H100都已經(jīng)賣完了!!
如何獲得H100的算力?
就像前邊英偉達(dá)的高管提到的,H100的GPU所提供的算力,最終要通過各個(gè)云計(jì)算提供商整合到產(chǎn)業(yè)鏈中去,所以H100的短缺,一方面是GPU生成造成的。
另一個(gè)方面,是算力云提供商怎么能有效地從英偉達(dá)獲得H100,并通過提供云算力最終觸及需要的客戶。
這個(gè)過程簡單來說是:
算力云提供商向OEM采購H100芯片,再搭建算力云服務(wù)出售給各個(gè)AI企業(yè),使得最終的用戶能夠獲得H100的算力。
而這個(gè)過程中同樣存在各種因素,造成了目前H100算力的短缺,而爆料的文章也提供了很多行業(yè)內(nèi)部的信息供大家參考。
H100的板卡找誰買?
戴爾,聯(lián)想,HPE,Supermicro和廣達(dá)等OEM商家都會(huì)銷售H100和HGX H100。
像CoreWeave和Lambda這樣的GPU云提供商從OEM廠家處購買,然后租給初創(chuàng)公司。
超大規(guī)模的企業(yè)(Azure、GCP、AWS、Oracle)會(huì)更直接與英偉達(dá)合作,但也會(huì)向OEM處購買。這和游戲玩家買顯卡的渠道似乎也差不多。但即使是購買DGX,用戶也需要通過OEM購買,不能直接向英偉達(dá)下訂單。
交貨時(shí)間
8-GPU HGX 服務(wù)器的交付時(shí)間很糟糕,4-GPU HGX 服務(wù)器的交付時(shí)間就還好。
但是每個(gè)客戶都想要 8-GPU 服務(wù)器!
初創(chuàng)公司是否從原始設(shè)備制造商和經(jīng)銷商處購買產(chǎn)品?
初創(chuàng)公司如果要獲得H100的算力,最終不是自己買了H100插到自己的GPU集群中去。
他們通常會(huì)向Oracle等大型云租用算力,或者向Lambda和CoreWeave等私有云租用,或者向與OEM和數(shù)據(jù)中心合作的提供商(例如 FluidStack)租用。

如果想要自己構(gòu)建數(shù)據(jù)中心,需要考慮的是構(gòu)建數(shù)據(jù)中心的時(shí)間、是否有硬件方面的人員和經(jīng)驗(yàn)以及資本支出是否能夠承擔(dān)。
租用和托管服務(wù)器已經(jīng)變得更加容易了。如果用戶想建立自己的數(shù)據(jù)中心,必須布置一條暗光纖線路才能連接到互聯(lián)網(wǎng) - 每公里 1 萬美元。大部分基礎(chǔ)設(shè)施已經(jīng)在互聯(lián)網(wǎng)繁榮時(shí)期建成并支付了費(fèi)用。租就行了,很便宜。
– 某私有云負(fù)責(zé)人
從租賃到自建云服務(wù)的順序大概是:按需租云服務(wù)(純租賃云服務(wù))、預(yù)定云服務(wù)、托管云服務(wù)(購買服務(wù)器,與提供商合作托管和管理服務(wù)器)、自托管(自己購買和托管服務(wù)器))。
大部分需要H100算力的初創(chuàng)公司都會(huì)選擇預(yù)定云服務(wù)或者是托管云服務(wù)。
大型云計(jì)算平臺之間的比較
而對于很多初創(chuàng)公司而言,大型云計(jì)算公司提供的云服務(wù),才是他們獲得H100的最終來源。
云平臺的選擇也最終決定了他們能否獲得穩(wěn)定的H100算力。
總體的觀點(diǎn)是:Oracle 不如三大云可靠。但是Oracle會(huì)提供更多的技術(shù)支持幫助。
其他幾家大型云計(jì)算公司的主要差異在于:
網(wǎng)絡(luò):盡管大多數(shù)尋求大型 A100/H100 集群的初創(chuàng)公司都在尋求InfiniBand,AWS 和 Google Cloud 采用InfiniBand的速度較慢,因?yàn)樗鼈冇昧俗约旱姆椒▉硖峁┓?wù)。
可用性:微軟Azure的H100大部分都是專供OpenAI的。谷歌獲取H100比較困難。

因?yàn)橛ミ_(dá)似乎傾向于為那些沒有計(jì)劃開發(fā)和他競爭的機(jī)器學(xué)習(xí)芯片的云提供更多的H100配額。(這都是猜測,不是確鑿的事實(shí)。)
而除了微軟外的三大云公司都在開發(fā)機(jī)器學(xué)習(xí)芯片,來自AWS和谷歌的英偉達(dá)替代產(chǎn)品已經(jīng)上市了,占據(jù)了一部分市場份額。
就與英偉達(dá)的關(guān)系而言,可能是這樣的:Oracle和Azure>GCP和AWS。但這只是猜測。
較小的云算力提供商價(jià)格會(huì)更便宜,但在某些情況下,一些云計(jì)算提供商會(huì)用算力去換股權(quán)。
英偉達(dá)如何分配H100
英偉達(dá)會(huì)為每個(gè)客戶提供了H100的配額。
但如果Azure說“嘿,我們希望獲得10,000個(gè)H100,全部給Inflection使用”會(huì)與Azure說“嘿,我們希望 獲得10,000個(gè)H100用于Azure云”得到不同的配額。
英偉達(dá)關(guān)心最終客戶是誰,因此如果英偉達(dá)如果對最終的使用客戶感興趣的話,云計(jì)算提供平臺就會(huì)得到更多的H100。
英偉達(dá)希望盡可能地了解最終客戶是誰,他們更喜歡擁有好品牌的客戶或擁有強(qiáng)大血統(tǒng)的初創(chuàng)公司。
是的,情況似乎是這樣。NVIDIA 喜歡保證新興人工智能公司(其中許多公司與他們有密切的關(guān)系)能夠使用 GPU。請參閱 Inflection——他們投資的一家人工智能公司——在他們也投資的 CoreWeave 上測試一個(gè)巨大的 H100 集群。
– 某私有云負(fù)責(zé)人
結(jié)束語
現(xiàn)在對于GPU的渴求既有泡沫和炒作的成分,但是也確實(shí)是客觀存在的。
OpenAI 等一些公司推出了ChatGPT等產(chǎn)品,這些產(chǎn)品收到了市場的追捧,但他們依然無法獲得足夠的GPU。
其他公司正在購買并且囤積GPU,以便將來能夠使用,或者用來訓(xùn)練一些市場可能根本用不到的大語言模型。這就產(chǎn)生了GPU短缺的泡沫。
但無論你怎么看,英偉達(dá)就是堡壘里的綠色國王。

推薦閱讀:
世界的真實(shí)格局分析,地球人類社會(huì)底層運(yùn)行原理
不是你需要中臺,而是一名合格的架構(gòu)師(附各大廠中臺建設(shè)PPT)
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
【中臺實(shí)踐】華為大數(shù)據(jù)中臺架構(gòu)分享.pdf