
英偉達GPU新核彈:Hopper H100揭秘

1、NVIDIA A100 Tensor Core GPU技術白皮書
2、NVIDIA Kepler GK110-GK210架構白皮書
3、NVIDIA Kepler GK110-GK210架構白皮書
4、NVIDIA Kepler GK110架構白皮書
5、NVIDIA Tesla P100技術白皮書
6、NVIDIA Tesla V100 GPU架構白皮書
7、英偉達Turing GPU 架構白皮書
Hopper H100是有史以來最大的代際飛躍。H100具有800億個晶體管,在性能上堪稱NVIDIA的“新核彈”。這顆“新核彈”的核心架構是什么樣的?
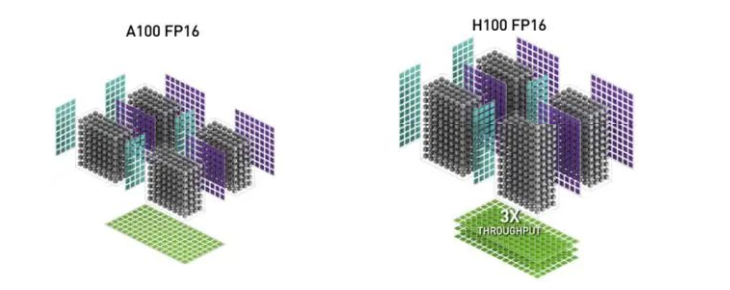
首先是規(guī)格方面,NVIDIA Hopper架構的H100芯片采用臺積電4nm工藝(N4是臺積電N5工藝的優(yōu)化版),核心面積為814平方毫米,比A100小14平方毫米。雖然核心面積比A100小14平方毫米,但得益于4nm工藝,晶體管密度數(shù)量從542億提升到800億。
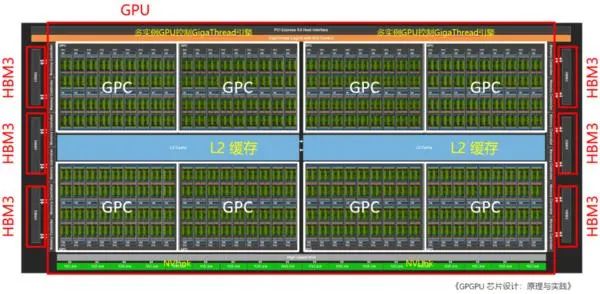
從核心設計圖來看,NVIDIA Hopper架構與蘋果UltraFusion相似,但它在本質(zhì)上還是單獨的一顆晶片,而不是蘋果M1 Ultra那種將兩塊芯片橋接起來。頂層拓撲與Ampere架構差別不大,整個Hopper架構GPU由8個圖形處理集群(Graphics Processing Cluster,GPC)“拼接”組成,但每4個GPC共享25MB得L2緩存。核心兩側則是HBM3顯存,擁有5120 Bit的位寬,最高容量可達80GB。
片上的每個GPC由9個紋理處理集群(Texture Processor Cluster,TPC)組成,由PCIe5或接口進入的計算任務,通過帶有多實例GPU(Multi-Instance GPU,MIG)控制的GigaThread引擎分配給各個GPC。GPC通過L2緩存共享中間數(shù)據(jù),GPC計算的中間數(shù)據(jù)通過NVLink與其他GPU互通。每個TPC由2個流式多處理器(Streaming Multiprocessor)組成。

Hopper架構的性能提升和主要變化體現(xiàn)在新型線程塊集群技術和新一代的流式多處理器。NVIDIA在Hopper中引入了新的線程塊集群機制,可實現(xiàn)跨單元進行協(xié)同計算。H100中的線程塊集群可在同一GPC內(nèi)的大量并發(fā)運行,對較大的模型具有更好的加速能力。
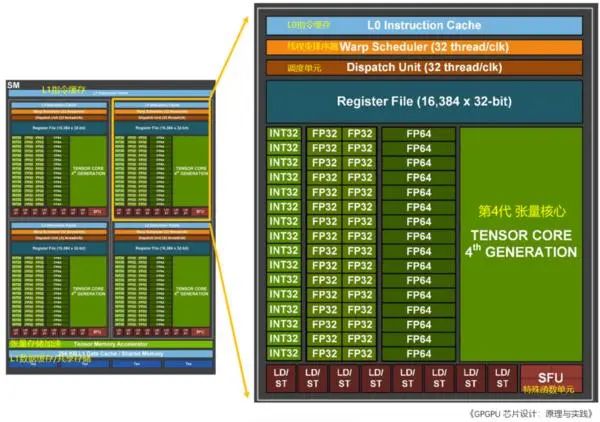
每個包括128個FP32 CUDA核心、4個第4代張量核心(Tensor Core)。每個單元的指令首先存入L1指令緩存(L1 Instruction Cache),再分發(fā)到L0指令緩存(L1 Instruction Cache)。與L0緩存配套的線程束排序器(Wrap Scheduler,線程束)和調(diào)度單元(Dispatch Unit)為CUDA核心和張量核心分配計算任務。通過使用4個特殊函數(shù)單元(Special Function Unit,SFU)單元,進行超越函數(shù)和插值函數(shù)計算。
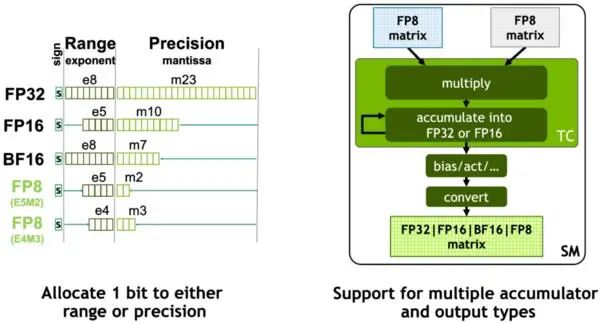
NVIDIA在Hopper架構中引入新一代流式多處理器的FP8張量核心(Tensor Core),用來加速AI訓練和推理。FP8張量核心支持FP32和FP16累加器以及兩種FP8 輸入類型(E4M3和E5M2)。與FP16或BF16相比,F(xiàn)P8將數(shù)據(jù)存儲要求減半,吞吐量翻倍。在Transformer引擎的分析中,還會看到使用FP8可自適應地提升Transformer的計算速度。
在GPU中,張量核心AI加速的關鍵模塊,也是Ampere及之后GPU架構與早期GPU的重要區(qū)別。張量核心是用于矩陣乘法和矩陣累加 (Matrix Multiply-Accumulate,MMA) 數(shù)學運算的專用高性能計算核心,可為AI和HPC應用程序提供突破性的性能加速。
Hopper的張量核心支持FP8、FP16、BF16、TF32、FP64和INT8 MMA數(shù)據(jù)類型。這一代張量核心的關鍵點是引入Transformer引擎。Transformer算子是主流的BERT到GPT-3等NLP模型的基礎,越來越多地應用于計算機視覺、蛋白質(zhì)結構預測等不同領域。

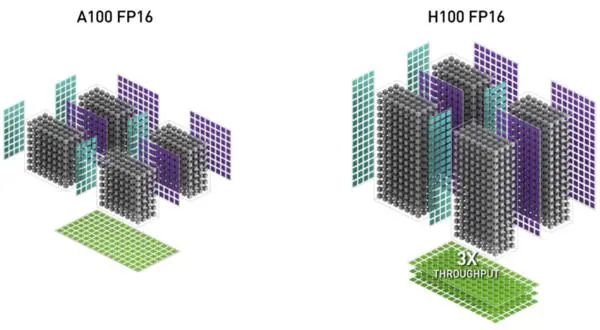
與上一代A100相比,新的Transformer引擎與Hopper FP8張量核心相結合,在大型NLP模型上提供高達9倍的AI訓練速度和30倍的AI推理速度。為了提升Transformer的計算效率,新Transformer引擎使用混合精度,在計算過程中智能地管理計算精度,在Transformer計算的每一層,根據(jù)下一層神經(jīng)網(wǎng)絡層及所需的精度,在FP8和其他浮點格式中進行動態(tài)格式轉換,充分運用張量核心的算力。
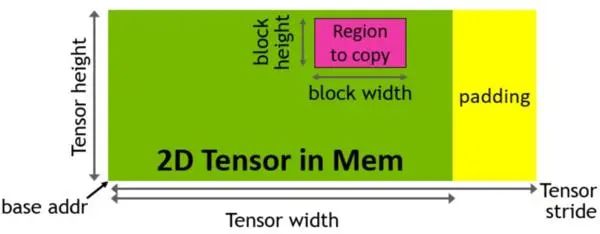
Hopper架構中新增加張量存儲加速器 (Tensor Memory Accelerator,TMA) ,以提高張量核心與全局存儲和共享存儲的數(shù)據(jù)交換效率。新的TMA使用張量維度和塊坐標指定數(shù)據(jù)傳輸,而不是簡單的按數(shù)據(jù)地址直接尋址。TMA通過支持不同的張量布局(1D-5D張量)、不同的存儲訪問模式、顯著降低尋址開銷并提高了效率。
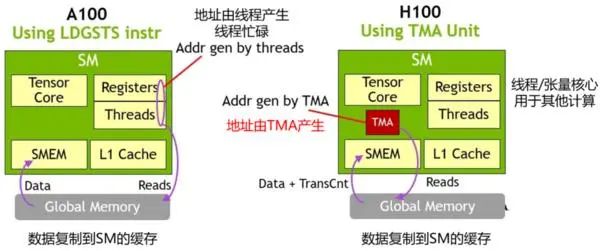
TMA操作是異步的,多個線程可以共享數(shù)據(jù)通道,排序完成數(shù)據(jù)傳輸。TMA的關鍵優(yōu)勢是可以在進行數(shù)據(jù)復制的時候,釋放線程的算力來執(zhí)行其他工作。例如,在A100由線程本身負責生成所有地址執(zhí)行所有數(shù)據(jù)復制操作;但Hopper中得TMA來負責生成地址序列(這個思路類似DMA控制器),接管數(shù)據(jù)復制任務,讓線程去做其他事。
與Ampere A100線相比,基于Hopper架構的H100計算性能提高大約6倍。性能大幅提升的核心原因是NVIDIA引入FP8張量核心和針對NLP任務的Transformer引擎,加上TMA技術減少單元在數(shù)據(jù)復制時的無用功。
相關下載:
1、AI芯片:下一代計算革命基石
2、從自主可控滲透國產(chǎn)GPU提升市場規(guī)模
3、從全球領先企業(yè)看GPU 發(fā)展方向
4、人工智能核“芯”,GPU迎來發(fā)展良機
5、AI芯片的競爭:GPU、ASIC和FPGA
6、自動駕駛芯片:GPU的現(xiàn)在和ASIC的未來
7、GPU制霸AI數(shù)據(jù)中心市場
2021年信創(chuàng)產(chǎn)業(yè)發(fā)展報告
信創(chuàng)產(chǎn)業(yè)系列專題(總篇)
中國信創(chuàng)產(chǎn)業(yè)發(fā)展白皮書(2021)
中國數(shù)據(jù)處理器行業(yè)概覽(2021)
來源:智能計算芯世界,更多內(nèi)容請登錄智能計算芯知識(知識星球)星球下載全部資料。
???????????????? END ????????????????
轉載申明:轉載本號文章請注明作者和來源,本號發(fā)布文章若存在版權等問題,請留言聯(lián)系處理,謝謝。
推薦閱讀
更多架構相關技術知識總結請參考“架構師全店鋪技術資料打包”相關電子書(37本技術資料打包匯總詳情可通過“閱讀原文”獲取)。
全店內(nèi)容持續(xù)更新,現(xiàn)下單“全店鋪技術資料打包(全)”,后續(xù)可享全店內(nèi)容更新“免費”贈閱,價格僅收198元(原總價350元)。
溫馨提示:
掃描二維碼關注公眾號,點擊閱讀原文鏈接獲取“架構師技術全店資料打包匯總(全)”電子書資料詳情。
