
自監(jiān)督學(xué)習(xí)新思路!基于蒸餾損失的自監(jiān)督學(xué)習(xí)算法 | CVPR 2021
點(diǎn)擊上方“視學(xué)算法”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
AI 科技評(píng)論 今天給大家介紹一篇被 CVPR 2021 收錄的關(guān)于自監(jiān)督的文章——S2-BNN [1],論文作者來自 CMU,HKUST 和 IIAI。
這篇論文探討了如果網(wǎng)絡(luò)規(guī)模在非常小的情況下(比如efficient networks或者binary neural networks),什么樣的自監(jiān)督訓(xùn)練策略和方法是最好的。
本文發(fā)現(xiàn)基于小網(wǎng)絡(luò)的前提下,基于蒸餾(distillation learning)的自監(jiān)督學(xué)習(xí)得到的模型性能遠(yuǎn)遠(yuǎn)強(qiáng)于對(duì)比學(xué)習(xí)(contrastive learning),同時(shí)他們還發(fā)現(xiàn)同時(shí)使用蒸餾和對(duì)比學(xué)習(xí)效果反而不如單獨(dú)使用蒸餾損失,這也是一個(gè)非常有意思的發(fā)現(xiàn)。

論文:https://arxiv.org/abs/2102.08946
代碼和模型:https://github.com/szq0214/S2-BNN
本文的初衷是:如果網(wǎng)絡(luò)模型的規(guī)模比較小,那么它的表達(dá)能力也會(huì)非常有限,從而會(huì)造成這類網(wǎng)絡(luò)的預(yù)測(cè)概率變得不那么確信(confident);
這時(shí)候作者就產(chǎn)生一個(gè)疑問:最常使用的對(duì)比學(xué)習(xí)在這種類型的網(wǎng)絡(luò)上面還能取得較好的結(jié)果嗎?
基于這個(gè)疑問:作者首先使用默認(rèn)參數(shù)的MoCo V2作為自監(jiān)督學(xué)習(xí)基準(zhǔn)算法(baseline),在使用ReActNet作為主干網(wǎng)的時(shí)候在ImageNet上得到46.9%。由于該主干網(wǎng)是一個(gè)二值化網(wǎng)絡(luò),因此作者提出需要調(diào)整優(yōu)化器、學(xué)習(xí)率策略、數(shù)據(jù)增強(qiáng)策略來匹配二值網(wǎng)絡(luò)的特性。作者嘗試使用Adam和SGD兩種優(yōu)化器來訓(xùn)練主干網(wǎng),在線性評(píng)估(linear evaluation)階段使用不同學(xué)習(xí)率來尋找最佳的參數(shù)設(shè)計(jì)。作者發(fā)現(xiàn)使用使用SGD訓(xùn)練的網(wǎng)絡(luò),在線性評(píng)估階段學(xué)習(xí)率比較大的時(shí)候性能比較高,學(xué)習(xí)率降低時(shí)精度嚴(yán)重下降,而Adam訓(xùn)練的網(wǎng)絡(luò)剛好相反,學(xué)習(xí)率降低時(shí)精度反而上升,同時(shí)Adam訓(xùn)練的網(wǎng)絡(luò)在取得最佳精度的設(shè)置時(shí)結(jié)果明顯優(yōu)于SGD的最佳結(jié)果。因此作者首先提出了一個(gè)基于MoCo V2的更強(qiáng)的baseline+,性能為52.5%。

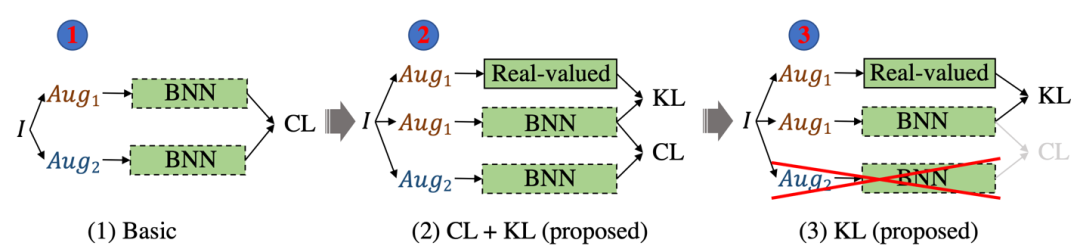
接下來作者提出并比較了如下三種策略:
1. 單純使用對(duì)比學(xué)習(xí)(使用增強(qiáng)后的MoCo V2作為對(duì)比學(xué)習(xí)算法);
2. 對(duì)比學(xué)習(xí)損失加上知識(shí)蒸餾損失(文章使用cross-entropy loss作為蒸餾損失)訓(xùn)練模型;
3. 只使用知識(shí)蒸餾損失(cross-entropy loss)訓(xùn)練模型。
蒸餾損失函數(shù)表達(dá):
作者這邊使用的是soft版本的cross-entropy loss作為蒸餾損失函數(shù),具體實(shí)現(xiàn)細(xì)節(jié)可以去看他們的代碼,損失函數(shù)表達(dá)形式如下:
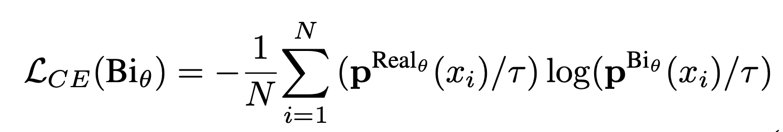
如何獲取teacher呢?
這里作者討論了兩種方案來得到teacher網(wǎng)絡(luò),一種是在線(online)的方式同時(shí)訓(xùn)練teacher和student,如下圖所示。另一種是離線(offline)的方式,即先使用自監(jiān)督方法訓(xùn)好teacher,然后固定teacher的權(quán)重來蒸餾目標(biāo)網(wǎng)絡(luò),這也是本文中采用的策略。
為什么使用offline的策略呢?
其主要好處是效率高,由于teacher只需要訓(xùn)練一次,后面可以重復(fù)使用,從而使student的訓(xùn)練更加高效。其次就是teacher在蒸餾過程中權(quán)重都是freeze的,產(chǎn)生的監(jiān)督信號(hào)也跟精確更穩(wěn)定,對(duì)于student的收斂也會(huì)有幫助。
下面是兩種策略的算法示意圖:

核心實(shí)驗(yàn)結(jié)果:
作者在ImageNets-1k上進(jìn)行了實(shí)驗(yàn),核心結(jié)果如下:
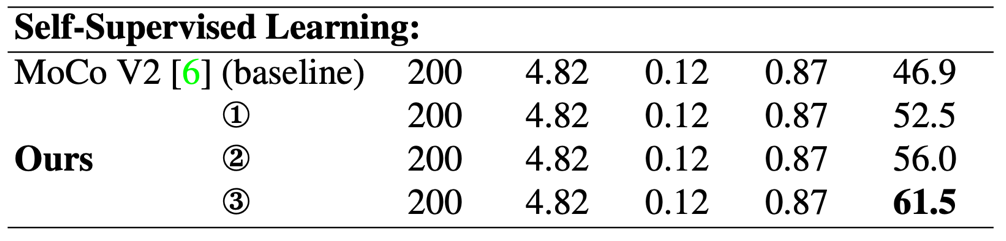
表中① ② ③分別對(duì)應(yīng)了三種訓(xùn)練策略,本文增強(qiáng)之后的結(jié)果比原始的baseline高了5.6%,加上蒸餾損失(distillation loss)之后結(jié)果提升到5.6%,去掉對(duì)比損失(contrastive loss)精度進(jìn)一步提升了5.5%,達(dá)到61.5%。可以看到只使用知識(shí)蒸餾的策略相比其他兩個(gè)方案,對(duì)于性能的提升還是非常可觀的。
為什么同時(shí)使用蒸餾損失和對(duì)比損失效果反而沒有單獨(dú)使用蒸餾損失效果好?
直觀地說,蒸餾損失會(huì)迫使 student 去模仿 teacher 網(wǎng)絡(luò)的預(yù)測(cè)概率輸出,而對(duì)比學(xué)習(xí)傾向于從數(shù)據(jù)本身中發(fā)現(xiàn)潛在模式(patterns)。如下圖所示,在二值化網(wǎng)絡(luò)場(chǎng)景中,對(duì)比損失學(xué)習(xí)細(xì)粒度表示的能力相比蒸餾損失相對(duì)較弱,學(xué)到的表達(dá)在語(yǔ)義層面也更模糊。因此,由于優(yōu)化空間的差異而導(dǎo)致兩者結(jié)合使用可能并不是最佳的解決方案。

同時(shí)期一些基于蒸餾的自監(jiān)督學(xué)習(xí)方法:
最近基于知識(shí)蒸餾的自監(jiān)督方法有不少,包括跟本文同時(shí)期的SEED [2] (發(fā)表于ICLR 2021, 兩者投稿相隔一個(gè)月,可以認(rèn)為是同時(shí)期的工作) 以及后續(xù)比較有名的FAIR的DINO [3] 等等, SEED基本上跟這篇文章的方法是類似的,只是在student 的選取上一個(gè)選擇的是小規(guī)模網(wǎng)絡(luò),本文選擇的是efficient的二值化網(wǎng)絡(luò),但是本身訓(xùn)練方法上沒有大的差別。DINO跟他們兩者的主要區(qū)別在于DINO的teacher的權(quán)重在訓(xùn)練過程是不固定的。
更多分析和消融實(shí)驗(yàn)請(qǐng)閱讀論文原文。

點(diǎn)個(gè)在看 paper不斷!