
前沿?zé)狳c(diǎn): 自監(jiān)督學(xué)習(xí)圖鑒
Yann Lecun 曾在演講中以蛋糕來(lái)類明自監(jiān)督學(xué)習(xí)。他在演講中說(shuō),
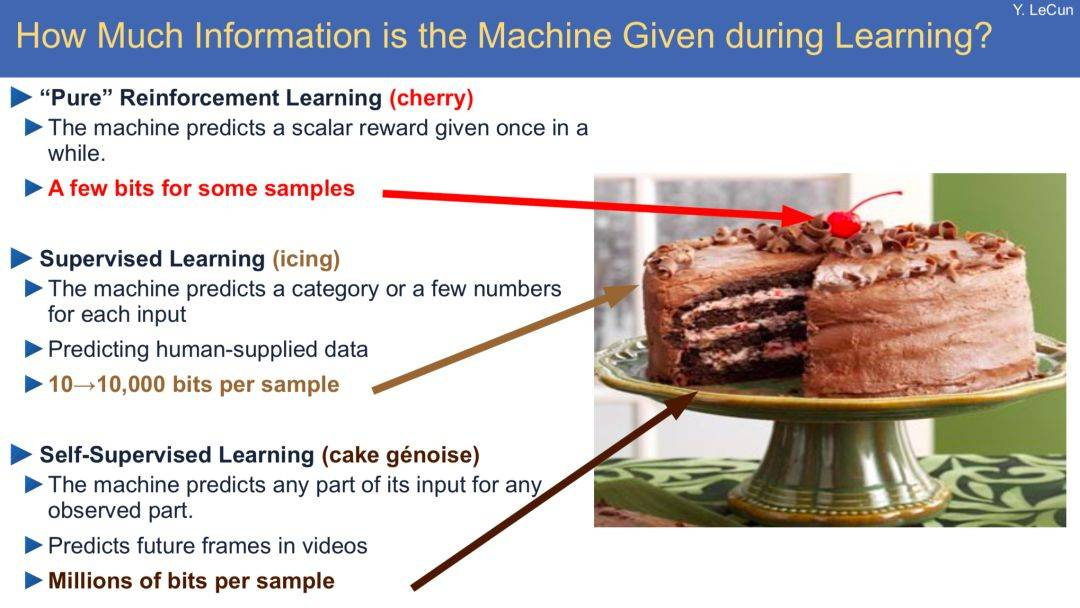
大牛的比喻不用過(guò)于較真,而且這個(gè)說(shuō)法也存在爭(zhēng)議。但我們可以看到,在自然語(yǔ)言處理領(lǐng)域中應(yīng)用自監(jiān)督學(xué)習(xí)的思想確實(shí)已經(jīng)取得了很大進(jìn)展(例如 Word2Vec,Glove,ELMO,BERT)。
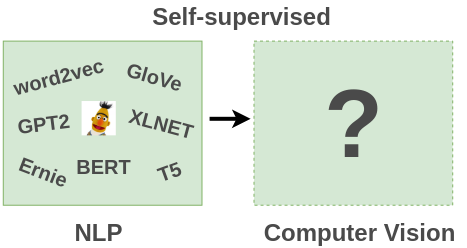
由于對(duì)自監(jiān)督學(xué)習(xí)在圖像領(lǐng)域的進(jìn)展感興趣,因此對(duì)一些相關(guān)文獻(xiàn)做了調(diào)研和總結(jié)。這篇文章將解釋什么是自監(jiān)督學(xué)習(xí),并總結(jié)自監(jiān)督學(xué)習(xí)在圖像領(lǐng)域中的應(yīng)用。
1Why 自監(jiān)督學(xué)習(xí)?
要用深度神經(jīng)網(wǎng)絡(luò)進(jìn)行監(jiān)督學(xué)習(xí),需要足夠的帶標(biāo)簽數(shù)據(jù)。然而,人工標(biāo)注大量數(shù)據(jù)既耗時(shí)又費(fèi)力。另外,還有一些領(lǐng)域,例如醫(yī)學(xué)領(lǐng)域,要獲取足夠的數(shù)據(jù)本身就是一個(gè)挑戰(zhàn)。因此,當(dāng)前監(jiān)督學(xué)習(xí)范式的一個(gè)主要瓶頸就是標(biāo)注數(shù)據(jù)或者叫標(biāo)簽生成。
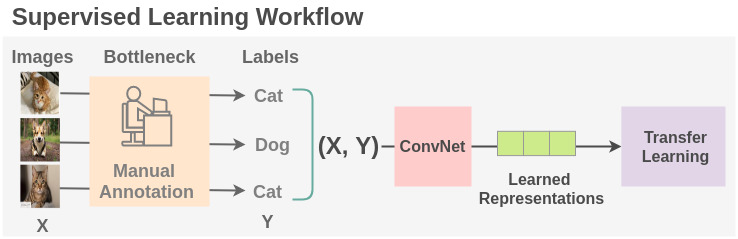
2自監(jiān)督學(xué)習(xí)
自監(jiān)督學(xué)習(xí)是一種提出以下問(wèn)題并將一個(gè)無(wú)監(jiān)督學(xué)習(xí)問(wèn)題轉(zhuǎn)化為監(jiān)督問(wèn)題的方法:
如何設(shè)計(jì)一個(gè)任務(wù),從現(xiàn)有圖像集中生成幾乎無(wú)限多的標(biāo)簽,以便用來(lái)學(xué)習(xí)圖像的表示呢?
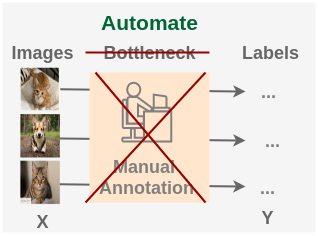
什么意思呢?圖像集本身沒(méi)有標(biāo)簽,只能干點(diǎn)無(wú)監(jiān)督的任務(wù),但是我們還是想用一個(gè)網(wǎng)絡(luò)去學(xué)習(xí)圖像的表示(提取它的特征),怎么辦呢?那就用圖像自身來(lái)制造 ‘標(biāo)簽’,這不就轉(zhuǎn)化為一個(gè)監(jiān)督學(xué)習(xí)的問(wèn)題了嗎!
在自監(jiān)督學(xué)習(xí)中,我們通過(guò)創(chuàng)造性地利用數(shù)據(jù)的某些屬性來(lái)設(shè)置偽監(jiān)督任務(wù)以替代人類標(biāo)注那個(gè)環(huán)節(jié)。例如,在這里我們可以將圖像旋轉(zhuǎn) 0/90/180/270 度,然后訓(xùn)練模型來(lái)預(yù)測(cè)正確的旋轉(zhuǎn),而不是顯式地將圖像標(biāo)注為貓或者狗等類別。我們可以從互聯(lián)網(wǎng)上免費(fèi)提供的數(shù)百萬(wàn)張圖像中生成幾乎無(wú)限的訓(xùn)練數(shù)據(jù)。

一旦從數(shù)百萬(wàn)張圖像中學(xué)習(xí)圖像的表示后,我們可以使用遷移學(xué)習(xí)實(shí)現(xiàn)在一些監(jiān)督任務(wù)(例如貓與狗的圖像分類)上用少量幾張實(shí)例圖像進(jìn)行微調(diào)。
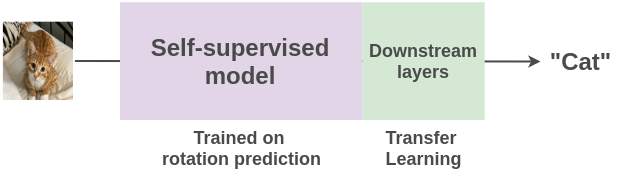
讓我們來(lái)了解一下近年來(lái)研究人員提出的利用圖像和視頻屬性的各種方法,以及應(yīng)用自監(jiān)督學(xué)習(xí)來(lái)實(shí)現(xiàn)表示學(xué)習(xí)。下面分別從圖片和視頻兩方面來(lái)介紹自監(jiān)督學(xué)習(xí)。
圖像篇

3圖像重構(gòu)
?圖像著色
我們將免費(fèi)可獲取的數(shù)百萬(wàn)張彩色圖像轉(zhuǎn)化為灰度圖,來(lái)構(gòu)建(灰度圖, 彩色圖)圖像對(duì)。
我們可以使用基于全卷積神經(jīng)網(wǎng)絡(luò)的編碼器-解碼器(encoder-decoder)網(wǎng)絡(luò)架構(gòu),并計(jì)算預(yù)測(cè)彩色圖像與實(shí)際彩色圖像之間的 L2 損失。
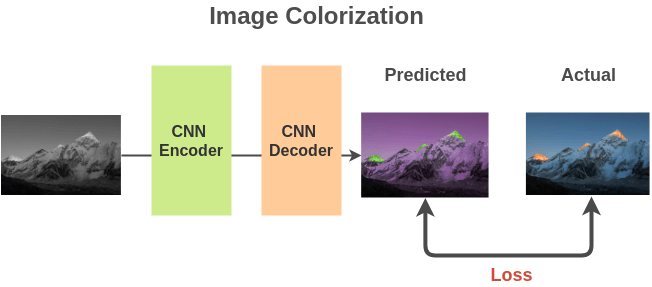
為了完成此任務(wù),模型需要學(xué)習(xí)圖像的表示,即圖像中有哪些物體及相關(guān) part,以便用相同顏色來(lái)繪制這些 part。模型學(xué)習(xí)到的圖像表示將用于下游任務(wù)。
Colorful Image Colorization
Real-Time User-Guided Image Colorization with Learned Deep Priors
Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic
Image Colorization with Simultaneous Classification
?圖像超分辨率
基于 GAN 的模型(例如 SRGAN)非常適合這樣的任務(wù)。生成器使用全卷積網(wǎng)絡(luò)獲取低分辨率圖像并輸出高分辨率圖像。使用均方誤差和內(nèi)容損失來(lái)比較實(shí)際圖像和生成的圖像,以模仿人類對(duì)圖像的質(zhì)量評(píng)估。二分類判別器會(huì)將圖像識(shí)別為真實(shí)的高分辨率圖像(1)還是偽造的超分辨率圖像(0)。這兩個(gè)模型之間的相互作用導(dǎo)致生成器不斷學(xué)習(xí)最終能夠生成具有精細(xì)細(xì)節(jié)的圖像。
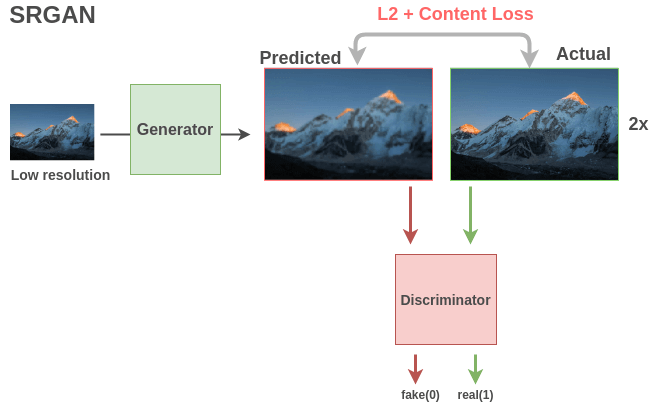
生成器和判別器都學(xué)習(xí)到了可用于下游任務(wù)的圖像語(yǔ)義特征。
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
?圖像修復(fù)
通過(guò)隨機(jī)刪除圖像的部分區(qū)域來(lái)構(gòu)建(損壞的, 修復(fù)的)圖像對(duì)。
與超分辨率任務(wù)相似,我們可以利用基于 GAN 架構(gòu),在該架構(gòu)中生成器可以學(xué)習(xí)重建圖像,而判別器則辨別真實(shí)圖像和生成圖像。
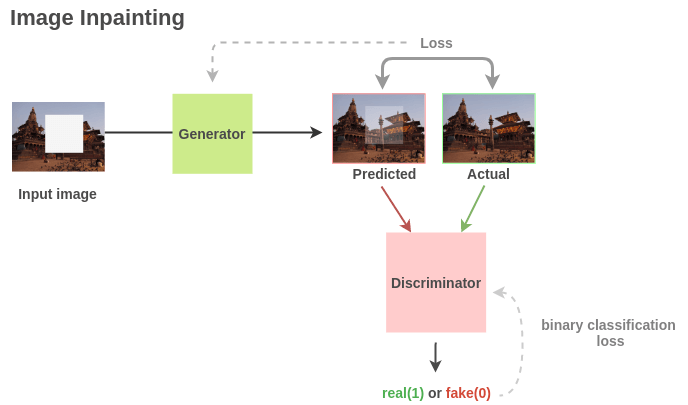
對(duì)于下游任務(wù),Pathak 等人的工作說(shuō)明在 PASCAL VOC 2012 語(yǔ)義分割任務(wù)上,生成器學(xué)到的語(yǔ)義特征相比隨機(jī)初始化有 10.2% 的提升,在分類和物體檢測(cè)任務(wù)上則有 < 4% 的提升。
Context encoders: Feature learning by inpainting
?交叉通道預(yù)測(cè)
用圖像的一個(gè)通道預(yù)測(cè)另一個(gè)通道并將它們重新組合以重建原始圖像。
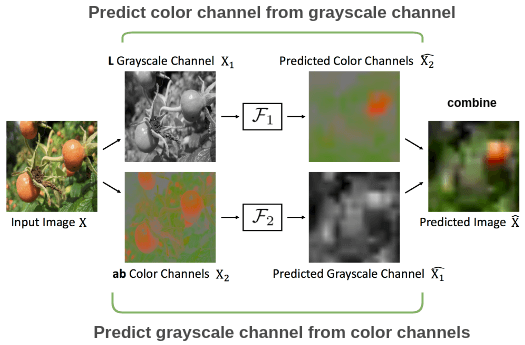
Split-Brain Autoencoder 論文的示例。張等人在論文 Split-Brain Autoencoder 中使用了這種想法。為了理解這種思想,讓我們以番茄的彩色圖像為例。
對(duì)于彩色圖像,我們可以將其分為灰度和彩色通道。對(duì)于灰度通道,預(yù)測(cè)彩色通道;對(duì)于顏色通道,預(yù)測(cè)灰度通道。將兩個(gè)預(yù)測(cè)通道
同樣的設(shè)置也可以應(yīng)用于具有深度的圖像,其中我們使用來(lái)自 RGB-HHA 圖像的顏色通道和深度通道相互預(yù)測(cè)并比較輸出圖像和原始圖像。
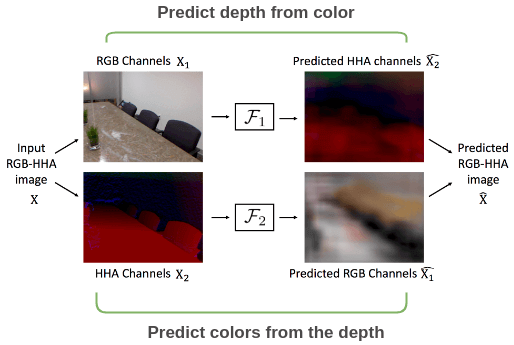
Split-Brain Autoencoder 論文的示例。Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction
4常識(shí)任務(wù)
?圖像拼圖
通過(guò)隨機(jī)打亂圖像 patch 構(gòu)建訓(xùn)練拼圖對(duì)(隨機(jī), 有序)。

即使只有 9 個(gè) patch,也可能存在 362880 個(gè)排列方式。為了克服這個(gè)問(wèn)題,僅僅選取具有最大漢明距離的 64 個(gè)排列。
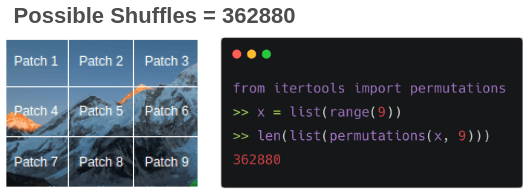
可以使用排列來(lái)改變圖像,總共用到 64 個(gè)排列,其中一個(gè)如下圖所示,
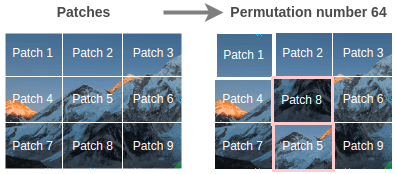
為了恢復(fù)圖像,Noroozi 等人提出了一個(gè)稱為上下文無(wú)關(guān)的神經(jīng)網(wǎng)絡(luò)(CFN),如下圖所示。在這里,各個(gè) patch 通過(guò)相同的共享權(quán)值的 siamese 卷積層傳遞。然后,將這些特征組合在一個(gè)全連接的層中。在輸出中,模型必須預(yù)測(cè)在 64 個(gè)可能的排列類別中使用了哪個(gè)排列。
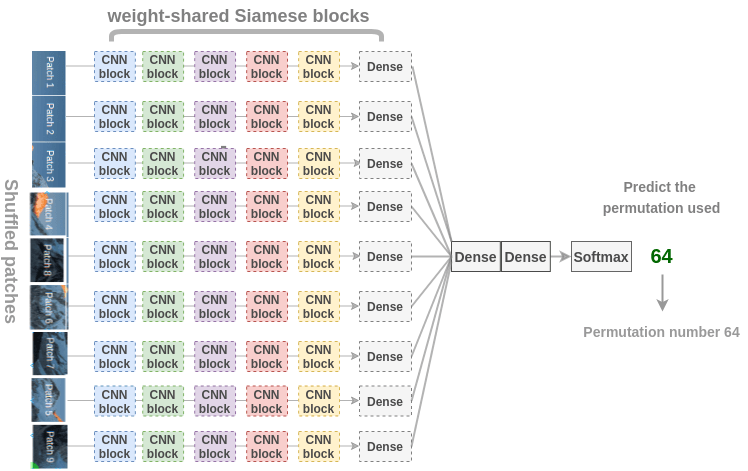
為了解決拼圖問(wèn)題,模型需要學(xué)習(xí)識(shí)別 parts 是如何組裝成物體的,物體不同 parts 的相對(duì)位置以及物體的形狀。因此,這些表示對(duì)于下游的分類和檢測(cè)任務(wù)是有用的。
Unsupervised learning of visual representations by solving jigsaw puzzles
?內(nèi)容預(yù)測(cè)
從不帶標(biāo)記的大型圖像集中隨機(jī)獲取一個(gè)圖像 patch 及其相鄰 patch 來(lái)構(gòu)建訓(xùn)練對(duì)(圖像 patch, 相鄰 patch)。
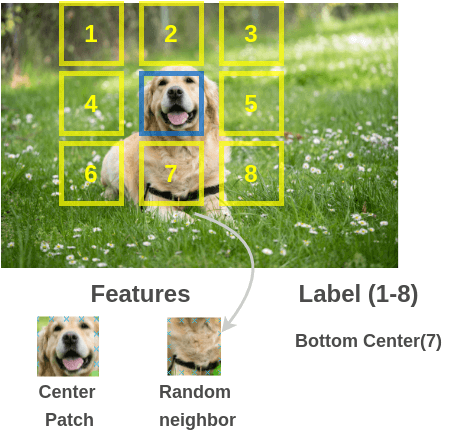
為了解決這個(gè)任務(wù),Doersch 等人使用了類似于拼圖游戲的架構(gòu)。通過(guò)兩個(gè) siamese 卷積神經(jīng)網(wǎng)絡(luò)傳遞圖像 patch 來(lái)提取特征,連接特征并對(duì) 8 個(gè)類進(jìn)行分類,表示 8 個(gè)可能的相鄰位置。
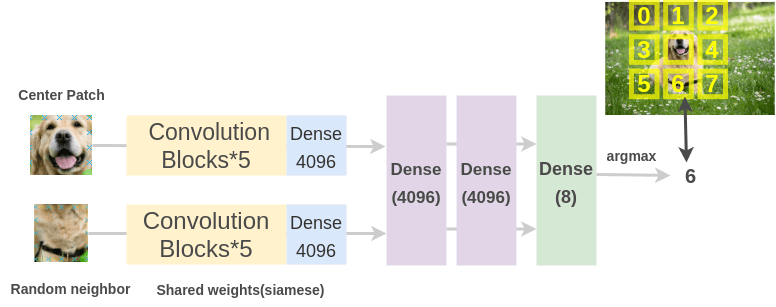
Unsupervised Visual Representation Learning by Context Prediction
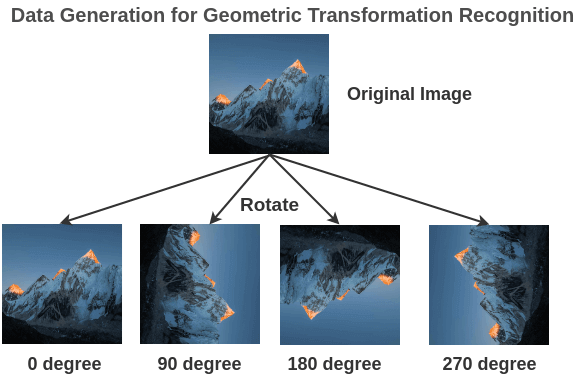
?幾何變換識(shí)別
不帶標(biāo)記的大型圖像集中隨機(jī)旋轉(zhuǎn)圖像(0、90、180、270)度來(lái)構(gòu)建訓(xùn)練對(duì)(旋轉(zhuǎn)圖像,旋轉(zhuǎn)角度)。
為了解決這個(gè)任務(wù), Gidaris 等人提出了一種網(wǎng)絡(luò)架構(gòu),將旋轉(zhuǎn)后的圖像輸入一個(gè)卷積神經(jīng)網(wǎng)絡(luò),網(wǎng)絡(luò)把它分成 4 類(0、90、270、360)度。
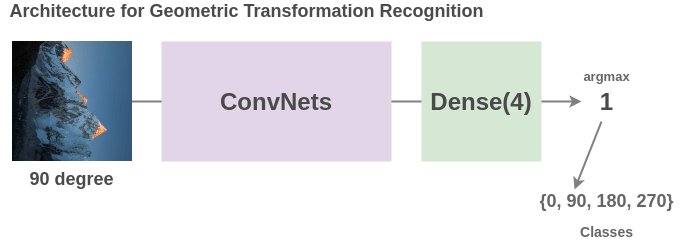
雖然這是一個(gè)非常簡(jiǎn)單的想法,但模型必須理解圖像中物體的位置、類型和姿態(tài)才能完成這項(xiàng)任務(wù),因此,學(xué)習(xí)到的表示方法對(duì)后續(xù)任務(wù)非常有用。
Unsupervised Representation Learning by Predicting Image Rotations
5自動(dòng)標(biāo)簽生成
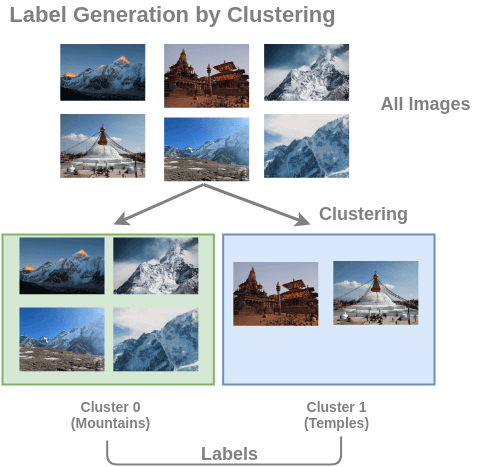
?圖像聚類
通過(guò)對(duì)不帶標(biāo)記的大型圖像集進(jìn)行聚類來(lái)構(gòu)建訓(xùn)練數(shù)據(jù)對(duì)(圖像, 簇編號(hào))。
為了解決這個(gè)任務(wù),Caron 等人提出了一種稱為 deep clustering 的架構(gòu)。在此,首先對(duì)圖像進(jìn)行聚類,然后將簇用作類。ConvNet 的任務(wù)是預(yù)測(cè)輸入圖像的簇標(biāo)簽。
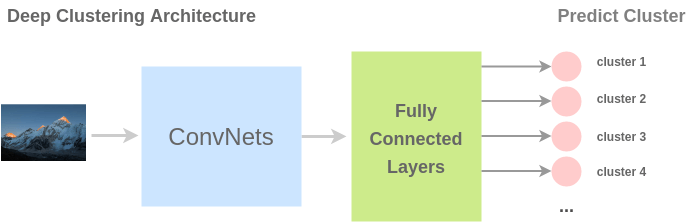
Deep clustering for unsupervised learning of visual features Self-labelling via simultaneous clustering and representation learning CliqueCNN: Deep Unsupervised Exemplar Learning
?圖像合成
通過(guò)使用游戲引擎合成圖像并將其轉(zhuǎn)換成真實(shí)圖像來(lái)構(gòu)建訓(xùn)練數(shù)據(jù)對(duì)(圖像, 屬性)。

為了解決這個(gè)任務(wù),Ren 等人提出一個(gè)架構(gòu),使用共享權(quán)值的卷積網(wǎng)絡(luò)在合成和真實(shí)圖像上進(jìn)行訓(xùn)練,然后鑒別器學(xué)習(xí)辨別合成圖像是否是真實(shí)圖像。由于對(duì)抗性,真實(shí)圖像和合成圖像之間的共享表示隨著訓(xùn)練變得更好。
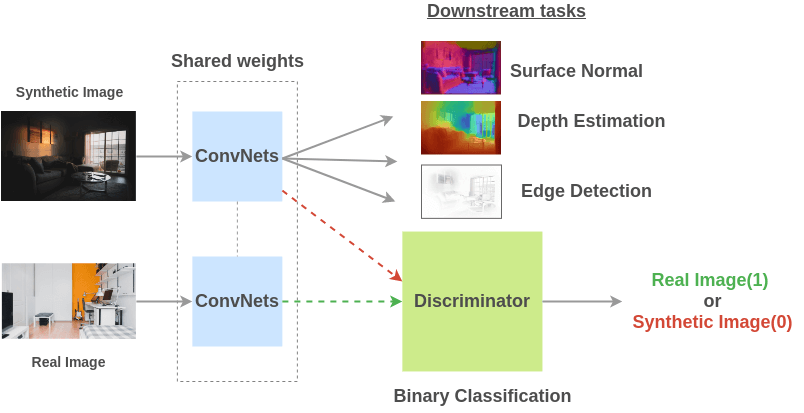
Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic Imagery
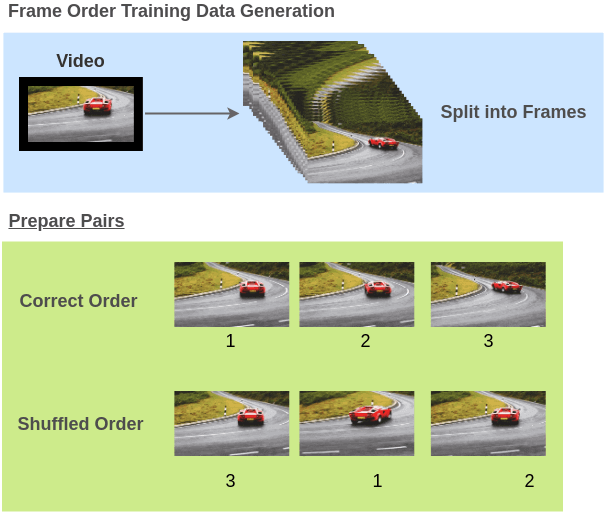
?視頻幀順序驗(yàn)證
將運(yùn)動(dòng)對(duì)象的視頻幀順序打亂來(lái)構(gòu)建訓(xùn)練對(duì)(視頻幀, 正確/不正確的順序)。
為了解決這個(gè)任務(wù),Misra 等人提出了一個(gè)架構(gòu),其中視頻幀通過(guò)共享權(quán)重的 ConvNets 傳遞,模型必須確定幀的順序是否正確。在此過(guò)程中,該模型不僅學(xué)習(xí)了空間特征,還考慮了時(shí)間特征。
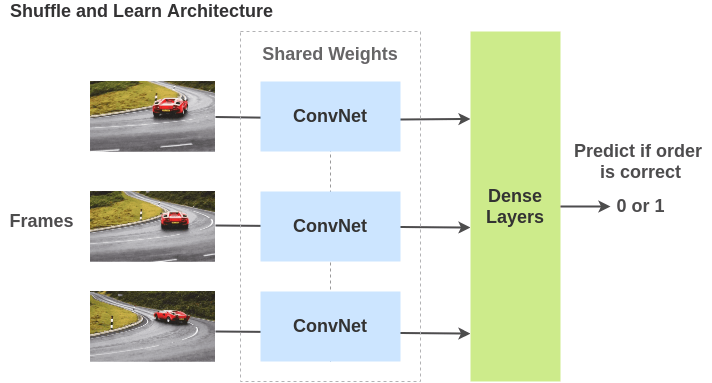
Shuffle and Learn: Unsupervised Learning using Temporal Order Verification Self-Supervised Video Representation Learning With Odd-One-Out Networks
6小結(jié)

?參考資料?
Jing et al.: https://arxiv.org/abs/1902.06162
[2]Amit Chaudhary: https://amitness.com/2020/02/illustrated-self-supervised-learning
這么好的知識(shí)藏著掖著
