
自監(jiān)督學(xué)習(xí)的知識(shí)點(diǎn)總結(jié)
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺(jué)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)
本篇文章將對(duì)自監(jiān)督學(xué)習(xí)的要點(diǎn)進(jìn)行總結(jié),包括以下幾個(gè)方面:
監(jiān)督學(xué)習(xí)與自監(jiān)督學(xué)習(xí)
自監(jiān)督學(xué)習(xí)需求背后的動(dòng)機(jī)
NLP 和CV中的自監(jiān)督學(xué)習(xí)
聯(lián)合嵌入架構(gòu)
對(duì)比學(xué)習(xí)
關(guān)于數(shù)據(jù)增強(qiáng)的有趣觀察
非對(duì)比學(xué)習(xí)
總結(jié)和參考
監(jiān)督學(xué)習(xí)與自監(jiān)督學(xué)習(xí)
監(jiān)督學(xué)習(xí)
?
機(jī)器學(xué)習(xí)中最常見(jiàn)的方法是監(jiān)督學(xué)習(xí)。
在監(jiān)督學(xué)習(xí)中,我們得到一組標(biāo)記數(shù)據(jù)(X,Y),即(特征,標(biāo)簽),我們的任務(wù)是學(xué)習(xí)它們之間的關(guān)系。但是這種方法并不總是易于處理,因?yàn)?/span>訓(xùn)練通常需要大量數(shù)據(jù),而標(biāo)記數(shù)百萬(wàn)行數(shù)據(jù)既耗時(shí)又昂貴,這就對(duì)許多不同任務(wù)的訓(xùn)練模型造成了瓶頸。
以這種方式訓(xùn)練的模型通常非常擅長(zhǎng)手頭的任務(wù),但不能很好地推廣到相關(guān)但是非相同領(lǐng)域內(nèi)的任務(wù)。因?yàn)榫W(wǎng)絡(luò)只專注于學(xué)習(xí) X 的良好表示以生成之間的直接映射X 和 Y ,而不是學(xué)習(xí) X 的良好通用表示,所以無(wú)法轉(zhuǎn)移到類似的其他任務(wù)。
這種學(xué)習(xí)通常會(huì)導(dǎo)致對(duì)概念的非常膚淺的理解,即它學(xué)習(xí)了 X 和 Y 之間的關(guān)系(它優(yōu)化了網(wǎng)絡(luò)以學(xué)習(xí)這種映射),但它不理解 X 的實(shí)際含義或它背后的含義。
自監(jiān)督學(xué)習(xí)
?
自監(jiān)督學(xué)習(xí)也適用于(特征、標(biāo)簽)數(shù)據(jù)集,即以監(jiān)督的方式,但它不需要人工注釋的數(shù)據(jù)集。它的基本思想是屏蔽/隱藏輸入的某些部分,并使用可觀察的部分來(lái)預(yù)測(cè)隱藏的部分。正如我們將在下面看到的,這是一個(gè)非常強(qiáng)大的想法。但是我們不稱其為無(wú)監(jiān)督學(xué)習(xí)是因?yàn)樗匀恍枰獦?biāo)簽,但不需要人工對(duì)其進(jìn)行標(biāo)注。
SSL的優(yōu)勢(shì)是如果我們手頭有大量未標(biāo)記的數(shù)據(jù),SSL的方式可以讓我們利用這些數(shù)據(jù)。這樣模型可以學(xué)習(xí)更強(qiáng)大的數(shù)據(jù)底層結(jié)構(gòu)的表示,并且這些表示比監(jiān)督學(xué)習(xí)中學(xué)到的更普遍,然后我們可以針對(duì)下游任務(wù)進(jìn)行微調(diào)。
需求和動(dòng)機(jī)
?
在過(guò)去的 10 年里,深度學(xué)習(xí)取得了長(zhǎng)足的進(jìn)步。幾年前被認(rèn)為計(jì)算機(jī)似乎不可能完成的任務(wù)(例如機(jī)器翻譯、圖像識(shí)別、分割、語(yǔ)音識(shí)別等)中,已經(jīng)達(dá)到/超過(guò)了人類水平的表現(xiàn)。在經(jīng)歷了十年的成功故事之后,深度學(xué)習(xí)現(xiàn)在正處于一個(gè)關(guān)鍵點(diǎn),人們已經(jīng)慢慢但肯定地開(kāi)始認(rèn)識(shí)到當(dāng)前深度學(xué)習(xí)方法的基本局限性。
人類和當(dāng)前人工智能的主要區(qū)別之一是人類可以比機(jī)器更快地學(xué)習(xí)事物,例如僅通過(guò)查看 1-2 張照片來(lái)識(shí)別動(dòng)物,只需 15-20 小時(shí)即可學(xué)會(huì)駕駛汽車。人類如何做到這一點(diǎn)?常識(shí)!雖然我們還不知道常識(shí)是如何產(chǎn)生的,但卻可以通過(guò)思考人類如何實(shí)際了解世界來(lái)做出一些有根據(jù)的猜測(cè):
人類主要通過(guò)觀察學(xué)習(xí),很少通過(guò)監(jiān)督學(xué)習(xí)。從嬰兒出生的那一刻起(或者之前),它就不斷地聽(tīng)到/看到/感覺(jué)到周圍的世界。因此,發(fā)生的大部分學(xué)習(xí)只是通過(guò)觀察。
人類可以利用隨著時(shí)間的推移獲得的知識(shí)(感知、運(yùn)動(dòng)技能、基礎(chǔ)物理來(lái)幫助導(dǎo)航世界等),而當(dāng)前的 SOTA 機(jī)器卻不能。
自監(jiān)督學(xué)習(xí)通過(guò)學(xué)習(xí)從未屏蔽部分預(yù)測(cè)數(shù)據(jù)的屏蔽部分來(lái)模仿的人類這部分的能力。
NLP 與CV中的 SSL
?
NLP 中的一般做法是屏蔽一些文本并使用附近的文本對(duì)其進(jìn)行預(yù)測(cè)。這種做法已經(jīng)有一段時(shí)間了,現(xiàn)在 SOTA 模型都是以這種方式進(jìn)行訓(xùn)練,例如 BERT、ROBERTA XLM-R、GPT-2,3 等。在 NLP 中應(yīng)用這種技術(shù)相對(duì)容易,因?yàn)槠帘卧~的預(yù)測(cè)只能取離散值,即詞匯表中的一個(gè)詞。所以我們所要做的就是在詞匯表中生成一個(gè)超過(guò) 10-20k 個(gè)單詞的概率分布。
但是在計(jì)算機(jī)視覺(jué)方面,可能性是無(wú)限的。我們?cè)谶@里處理高維連續(xù)對(duì)象,例如,一個(gè) 10X10 的屏蔽圖像塊可能在單個(gè)通道上獲取 2551?? 值,對(duì)于動(dòng)起來(lái)的視頻復(fù)雜性甚至更高(同樣的邏輯也適用于語(yǔ)音識(shí)別)。與 NLP 不同,我們無(wú)法對(duì)每一種可能性做出預(yù)測(cè),然后選擇更高概率的預(yù)測(cè)。這似乎是計(jì)算機(jī)視覺(jué)中一個(gè)棘手的問(wèn)題。
孿生網(wǎng)絡(luò)/聯(lián)合嵌入架構(gòu)
?
這里把圖像識(shí)別作為我們運(yùn)行的任務(wù)。SSL 會(huì)屏蔽一些隨機(jī)圖像塊,然后嘗試預(yù)測(cè)這些被屏蔽的塊。由于我們無(wú)法對(duì)圖像塊中的每一種可能性進(jìn)行預(yù)測(cè),所以我們只能使用相似度匹配。
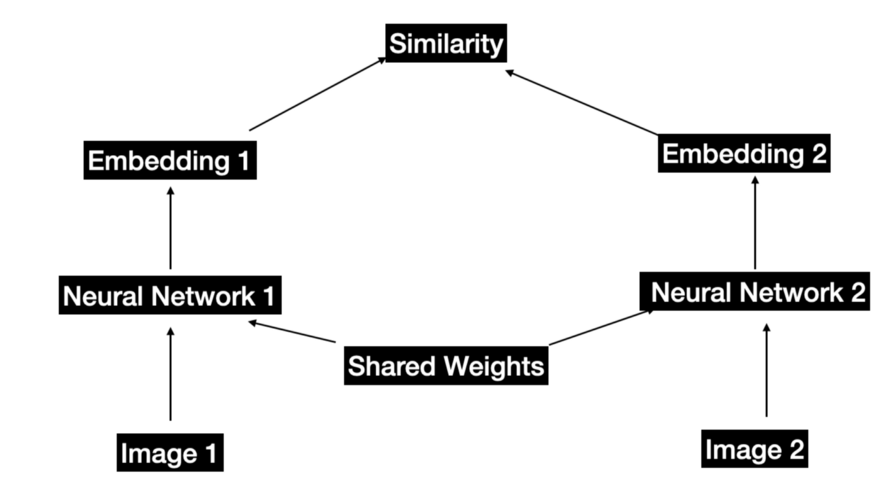
聯(lián)合嵌入架構(gòu)。這兩個(gè)神經(jīng)網(wǎng)絡(luò)可以完全相同,也可以部分共享,也可以完全不同。
這個(gè)想法是訓(xùn)練一種孿生網(wǎng)絡(luò)來(lái)計(jì)算兩張圖像之間的相似度,同時(shí)保證以下結(jié)果 -
相似/兼容的圖像應(yīng)該返回更高的相似度分?jǐn)?shù)。
不同/不兼容的圖像應(yīng)返回較低的相似度分?jǐn)?shù)。
第 1 點(diǎn)很容易實(shí)現(xiàn):可以用不同方式增強(qiáng)圖像,例如裁剪、顏色增強(qiáng)、旋轉(zhuǎn)、移動(dòng)等。然后讓 孿生網(wǎng)絡(luò)學(xué)習(xí)原始圖像和增強(qiáng)圖像的相似表示。在將模型輸出與固定目標(biāo)進(jìn)行比較的意義上,我們不再進(jìn)行預(yù)測(cè)建模,因?yàn)楝F(xiàn)在比較的是模型的兩個(gè)編碼器的輸出,這使得學(xué)習(xí)表示非常靈活。
但是第 2 點(diǎn)很麻煩。因?yàn)楫?dāng)圖像不同時(shí),我們?nèi)绾未_保網(wǎng)絡(luò)學(xué)習(xí)不同的嵌入?如果沒(méi)有進(jìn)一步的激勵(lì),無(wú)論輸入如何,網(wǎng)絡(luò)都可以為所有圖像學(xué)習(xí)相同的表示。這稱為模式崩潰。那么如何解決這個(gè)問(wèn)題?
對(duì)比學(xué)習(xí)?
?
基本思想是提供一組負(fù)樣本和正樣本。損失函數(shù)的目標(biāo)是找到表示以最小化正樣本之間的距離,同時(shí)最大化負(fù)樣本之間的距離。圖像被編碼后的距離可以通過(guò)點(diǎn)積計(jì)算,這正是我們想要的!那么這是否意味著計(jì)算機(jī)視覺(jué)中的 SSL 現(xiàn)在已經(jīng)解決了?其實(shí)還沒(méi)有完全解決。
為什么這么說(shuō)呢?因?yàn)閳D像是非常高維的對(duì)象,在高維度下遍歷所有的負(fù)樣本對(duì)象是幾乎不可能的,即使可以也會(huì)非常低效,所以就衍生出了下面的方法。
在描述這方法之前,讓我們首先來(lái)討論對(duì)比損失這將會(huì)幫助我們理解下面提到的算法。我們可以將對(duì)比學(xué)習(xí)看作字典查找任務(wù)。想象一個(gè)圖像/塊被編碼(查詢),然后與一組隨機(jī)(負(fù) - 原始圖像以外的任何其他圖像)樣本+幾個(gè)正(原始圖像的增強(qiáng)視圖)樣本進(jìn)行匹配。這個(gè)樣本組可以被視為一個(gè)字典(每個(gè)樣本稱為一個(gè)鍵)。假設(shè)只有一個(gè)正例,這意味著查詢將很好地匹配其中一個(gè)鍵。這樣對(duì)比學(xué)習(xí)就可以被認(rèn)為是減少查詢與其兼容鍵之間的距離,同時(shí)增加與其他鍵的距離。
目前對(duì)比學(xué)習(xí)中兩個(gè)關(guān)鍵算法如下:
Momentum Contrast - 這個(gè)想法是要學(xué)習(xí)良好的表示,需要一個(gè)包含大量負(fù)樣本的大型字典,同時(shí)保持字典鍵的編碼器盡可能保持一致。這種方法的核心是將字典視為隊(duì)列而不是靜態(tài)內(nèi)存庫(kù)或小批量的處理。這樣可以為動(dòng)態(tài)字典提供豐富的負(fù)樣本集,同時(shí)還將字典大小與小批量大小解耦,從而根據(jù)需要使負(fù)樣本變得更大。
SimCLR - 核心思想是使用更大的批大小(8192,以獲得豐富的負(fù)樣本集),更強(qiáng)的數(shù)據(jù)增強(qiáng)(裁剪,顏色失真和高斯模糊),并在相似性匹配之前嵌入的非線性變換,使用更大模型和更長(zhǎng)的訓(xùn)練時(shí)間。這些都是需要反復(fù)試驗(yàn)的顯而易見(jiàn)的事情,該論文憑經(jīng)驗(yàn)表明這有助于明顯的提高性能。
但是對(duì)比學(xué)習(xí)也有局限性:
需要大量的負(fù)樣本來(lái)學(xué)習(xí)更好的表示。
訓(xùn)練需要大批量或大字典。
更高的維度上不能進(jìn)行縮放。
需要某種不對(duì)稱性來(lái)避免常數(shù)解。
數(shù)據(jù)增強(qiáng)的有趣觀察
在上面提到的所有方法/算法中,數(shù)據(jù)增強(qiáng)都起著關(guān)鍵作用。為了訓(xùn)練類似 SSL 模型,通過(guò)一組規(guī)則(裁剪、移動(dòng)、旋轉(zhuǎn)、顏色失真、模糊等)增強(qiáng)原始圖像來(lái)生成正對(duì)。然后模型學(xué)會(huì)忽略這種噪聲(例如平移、顏色失真和旋轉(zhuǎn)不變性),以學(xué)習(xí)與正對(duì)(原始圖像和增強(qiáng)圖像)接近的表示。但是這些模型在圖像識(shí)別任務(wù)上做得很好,但當(dāng)模型已經(jīng)學(xué)會(huì)忽略這些變化時(shí),以相同的表示進(jìn)行目標(biāo)檢測(cè)任務(wù)時(shí)會(huì)獲得非常差的效果。
這是因?yàn)樗茈y在對(duì)象周圍放置邊界框,因?yàn)閷W(xué)習(xí)的表示被訓(xùn)練為忽略目標(biāo)對(duì)象的位置和定位。
非對(duì)比學(xué)習(xí)
?
與對(duì)比學(xué)習(xí)不同,模型僅從正樣本中學(xué)習(xí),即從圖像及其增強(qiáng)視圖中學(xué)習(xí)。
理論上上感覺(jué)這應(yīng)該行不通,因?yàn)槿绻W(wǎng)絡(luò)只有正例,那么它就學(xué)會(huì)忽略常量向量的輸入和輸出(上面提到的模式崩潰),這樣損失就會(huì)變成0。
而實(shí)際上這并沒(méi)有發(fā)生模型學(xué)習(xí)到了良好的表示。為什么呢?下面通過(guò)描述該領(lǐng)域的一些關(guān)鍵算法來(lái)進(jìn)行說(shuō)明 :
1、BARLOW TWINS:這是一種受神經(jīng)科學(xué)啟發(fā)的算法,基于 1961 年發(fā)表的論文的發(fā)現(xiàn)。它仍然使用如上所述的帶有增強(qiáng)圖像的聯(lián)合嵌入式架構(gòu)。但是它核心思想是使圖像嵌入輸出之間的互相關(guān)矩陣盡可能接近單位矩陣。這個(gè)簡(jiǎn)單的想法避免了復(fù)雜的解決方案,并獲得了 ImageNet 上的 SOTA 性能。并且它在高維度上效果更好,不需要不對(duì)稱,不需要大批量的數(shù)據(jù)或內(nèi)存存儲(chǔ)或任何其他啟發(fā)式方法來(lái)使其工作。
下圖解釋了算法的整體架構(gòu)。單個(gè)圖像在增強(qiáng)策略的分布上被處理兩次。然后兩個(gè)圖像都通過(guò)相同的編碼器網(wǎng)絡(luò)。損失函數(shù)的定義方式是將互相矩陣簡(jiǎn)化為單位矩陣。
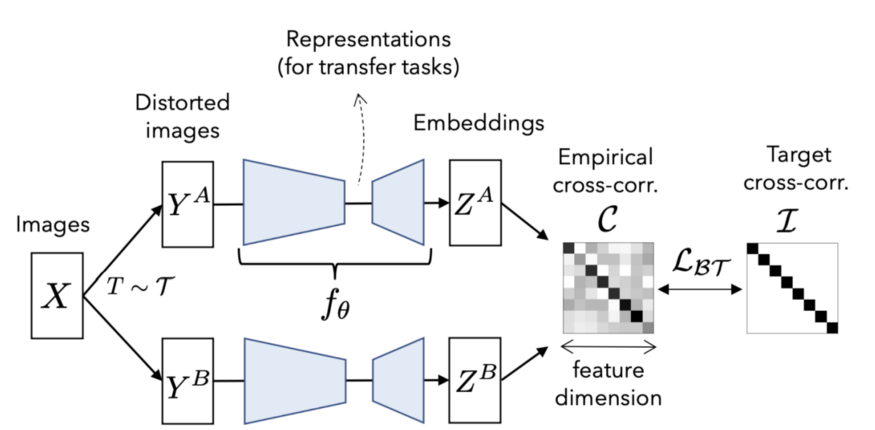
損失函數(shù)非常直觀

這里 C 是兩個(gè)圖像的嵌入之間的互相關(guān)矩陣。在這里沒(méi)有使用任何負(fù)樣本!
第一項(xiàng),當(dāng)所有 C_ii 為 1 即相關(guān)矩陣的對(duì)角元素為 1 時(shí),損失函數(shù)中的不變項(xiàng)最小。這使得隨著相關(guān)性的加強(qiáng),嵌入對(duì)增強(qiáng)處理保持不變。第二項(xiàng),即冗余縮減項(xiàng)強(qiáng)制非對(duì)角線值為 0,即它使嵌入的其他維度去相關(guān)。這使得模型在增強(qiáng)處理的同時(shí)學(xué)習(xí)有關(guān)樣本的非冗余信息。
2、BYOL:這種方法不像 Barlow Twins 那樣簡(jiǎn)單,因?yàn)樗枰承﹩l(fā)式方法才可以正常工作。它依賴于兩個(gè)神經(jīng)網(wǎng)絡(luò)(target和 target),并試圖從online 中預(yù)測(cè)target。兩個(gè)網(wǎng)絡(luò)中的權(quán)重不同。為了在架構(gòu)中引入不對(duì)稱性以避免瑣碎的常量嵌入,target網(wǎng)絡(luò)中引入了預(yù)測(cè)器模塊。

本文中沒(méi)有對(duì)BYOL進(jìn)行像 BARLOW TWINS 清晰和直觀的解釋,所以如果想了解其詳細(xì)內(nèi)容請(qǐng)參考原論文:arxiv 2006.07733
另外還有一種最新的方法 VICReg(arxiv:2105.04906)如果有幾乎的話會(huì)在后面介紹
總結(jié)
總結(jié)整篇文章,下圖展示了 SSL 在 NLP 和計(jì)算機(jī)視覺(jué)中的細(xì)分。
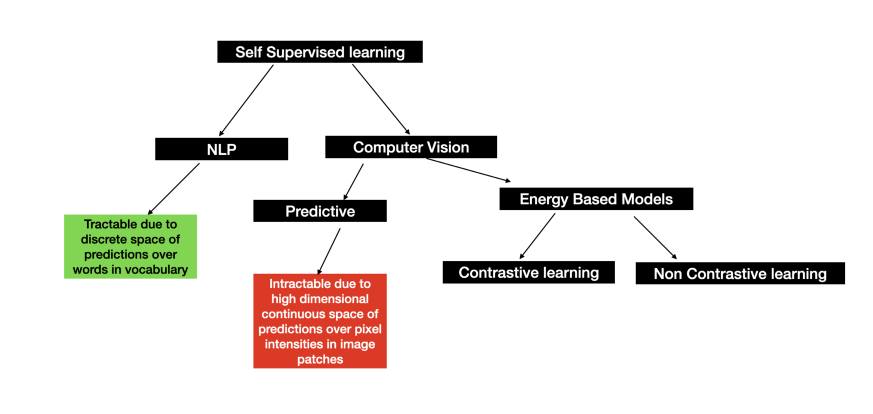

來(lái)源:海豚數(shù)據(jù)科學(xué)實(shí)驗(yàn)室
本文僅做學(xué)術(shù)分享,如有侵權(quán),請(qǐng)聯(lián)系刪文。