本文約6500字,建議閱讀13分鐘
本文梳理近年來 GNN預(yù)訓練和自監(jiān)督學習/對比學習的相關(guān)工作。
1 引言
近些年來,對圖神經(jīng)網(wǎng)絡(luò)(GNN)的研究如火如荼。通過設(shè)計基于 GNN 的模型,我們可以對結(jié)構(gòu)化的數(shù)據(jù)(如社交網(wǎng)絡(luò)圖、分子圖等)與對應(yīng)的標簽(點級別、邊級別、圖級別)進行有監(jiān)督的端到端訓練,使神經(jīng)網(wǎng)絡(luò)學習結(jié)構(gòu)化數(shù)據(jù)與標簽的聯(lián)系。流行的 GNN 結(jié)構(gòu)有 GCN [1], GraphSAGE [2], GAT [3], DGI [4], GIN [5] 等。盡管 GNN 相關(guān)模型在多個任務(wù)上取得了驚艷的效果,但仍然存在許多問題,如:- 監(jiān)督標簽很難獲取:一般來說,GNN 的訓練需要充足的任務(wù)相關(guān)的標簽數(shù)據(jù),而獲取這些標簽數(shù)據(jù)又往往是昂貴且費力的 [6]。例如生物/化學數(shù)據(jù)上的標簽,一般需要專業(yè)實驗室進行實驗以獲取 [7, 8]。
- GNN 不易訓練:傳統(tǒng)的 GNN 架構(gòu),在面對新任務(wù)或者更改了節(jié)點/邊的特征時,只能重新訓練。且一般來說,GNN 的訓練需要較大的訓練輪數(shù)才能達到較好的效果 [9]。
為了解決這些問題,一些研究者正在探索 GNN 上新的訓練模式,如預(yù)訓練和自監(jiān)督學習。一方面,可以借鑒預(yù)訓練-微調(diào)的模式,先在容易獲取的、大規(guī)模的、無監(jiān)督的(或者粗粒度的有監(jiān)督的)圖數(shù)據(jù)上,對 GNN 的模型參數(shù)進行預(yù)訓練。再將經(jīng)過預(yù)訓練的 GNN 模型參數(shù)作為下游任務(wù)的初始參數(shù),在少量細粒度標簽上快速地進行微調(diào)。另一方面,可以參考自監(jiān)督學習的模式(其中圖對比學習的研究尤為火熱),通過圖數(shù)據(jù)自身的信號,設(shè)計自監(jiān)督的損失函數(shù),無需標注即可學習出有意義的節(jié)點/圖表示向量。這些自監(jiān)督表示向量進而結(jié)合 SVM 等傳統(tǒng)機器學習方法,也可以達成不錯的效果。預(yù)訓練-微調(diào)(Pre-training Fine-tuning)的模式在自然語言處理 [10]、計算機視覺 [11]、推薦系統(tǒng) [12] 等領(lǐng)域取得了驚人的效果;而對比學習(Contrastive Learning)的流行,也在計算機視覺 [13] 等領(lǐng)域中重燃了學界對自監(jiān)督學習的研究熱情。在圖學習領(lǐng)域,預(yù)訓練和自監(jiān)督的研究都還剛剛起步,具有較大的發(fā)展?jié)摿Α=鼉赡辏?020-2021)學界對 GNN 結(jié)構(gòu)的探索逐步放緩,對預(yù)訓練和自監(jiān)督 GNN 的相關(guān)研究則快速升溫。本文將梳理近年來 GNN 預(yù)訓練和自監(jiān)督學習的相關(guān)工作,匯總常用資源,以思維導圖的形式對主要方法進行分類。本文主要整理來自 ICML、ICLR、NeurIPS、KDD、WWW、AAAI、WSDM 等會議中已發(fā)表的工作。水平有限,難免疏漏,歡迎討論、補充、指正,謝謝!2 GNN + 預(yù)訓練
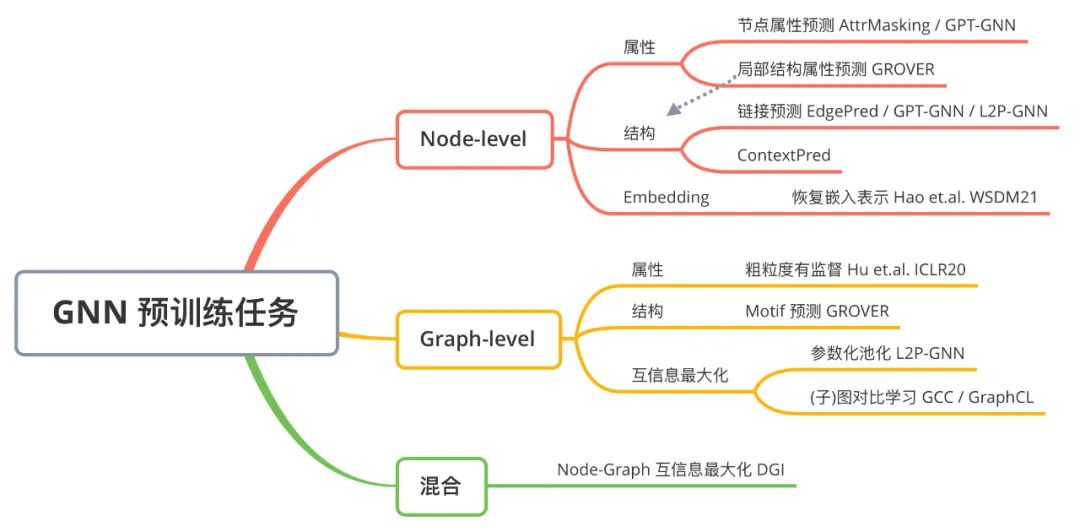
本章節(jié)介紹近年來發(fā)表于頂會的 GNN 預(yù)訓練工作。下圖為對 GNN 預(yù)訓練任務(wù)的歸納:
2.1 Strategies for Pre-training Graph Neural Networks [7]
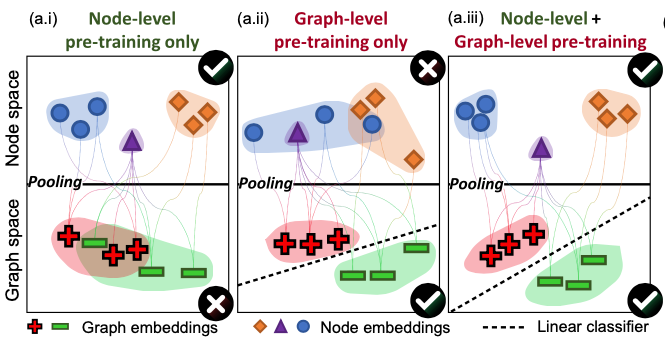
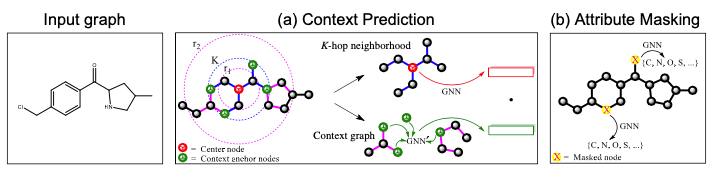
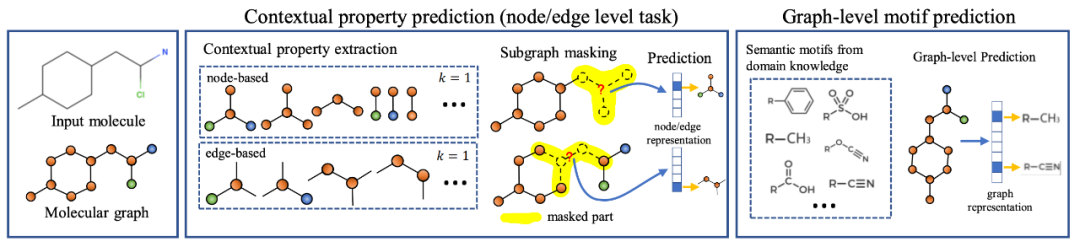
本文由 Stanford 圖學習大牛 Jure Leskovec 組的 Weihua Hu 和 Bowen Li 等人出品,發(fā)表于 ICLR 2020。本文首先指出,GNN 的預(yù)訓練-微調(diào)模式是很困難的。如果僅設(shè)計簡單的任務(wù)進行預(yù)訓練(如預(yù)測兩點之間是否有邊),評測下游任務(wù)時則經(jīng)常可以觀測到 negative transfer 的情況(即預(yù)訓練-微調(diào)的結(jié)果要差于直接訓練的結(jié)果)。作者認為出現(xiàn) negative transfer 現(xiàn)象的原因為,預(yù)訓練任務(wù)應(yīng)該同時兼顧圖的局部信息(Node-level)和全局信息(Graph-level)。如果只進行 Node-level 的預(yù)訓練,節(jié)點的性質(zhì)得到充分的學習,但是將圖中節(jié)點 Pooling 起來得到的圖表示向量則比較模糊;只進行 Graph-level 的預(yù)訓練的話,Pooling 得到的圖表示很清晰,但具體到每個節(jié)點的表示則較弱。為此,作者提出了兩個 Node-level 的預(yù)訓練任務(wù),和一個 Graph-level 的預(yù)訓練任務(wù),并強調(diào)預(yù)訓練應(yīng)該同時結(jié)合兩個級別進行。Context Prediction:類似 word2vec [14, 15] 的思想,根據(jù)節(jié)點的鄰居來預(yù)測某個節(jié)點。對于一個中心節(jié)點(Center Node,上圖 (a) 紅色節(jié)點),定義其周圍K跳鄰居構(gòu)成的子圖為 Neighborhood,定義其r1跳至r2跳之間(可以看成一個環(huán))的節(jié)點構(gòu)成的子圖為 Context Graphs。注意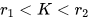 ,這樣同一個中心節(jié)點對應(yīng)的 Neighborhood 和 Context Graphs 之間存在節(jié)點的共享(上圖 (a) 中綠色節(jié)點)。Neighborhood 通過正在預(yù)訓練的 GNN 編碼為向量,Context Graphs 則通過一個輔助的 GNN 編碼為向量。本任務(wù)為,根據(jù) Neighborhood 向量和 Context Graphs 向量,預(yù)測這兩個子圖是否由同一個中心節(jié)點生成而來。具體的預(yù)訓練方法很像 word2vec,也是采用負采樣的方法。
,這樣同一個中心節(jié)點對應(yīng)的 Neighborhood 和 Context Graphs 之間存在節(jié)點的共享(上圖 (a) 中綠色節(jié)點)。Neighborhood 通過正在預(yù)訓練的 GNN 編碼為向量,Context Graphs 則通過一個輔助的 GNN 編碼為向量。本任務(wù)為,根據(jù) Neighborhood 向量和 Context Graphs 向量,預(yù)測這兩個子圖是否由同一個中心節(jié)點生成而來。具體的預(yù)訓練方法很像 word2vec,也是采用負采樣的方法。
- Attribute Masking:簡略地說即為預(yù)測圖中點/邊的屬性(特征)。在預(yù)訓練的 GNN 后接簡單的分類器,隨機 Mask 點/邊的屬性進行預(yù)測。比如上圖 (b) 中,根據(jù)鄰居節(jié)點預(yù)測某個節(jié)點的原子序號。
- Supervised Property Prediction:有時數(shù)據(jù)中會包含一些容易獲得的粗粒度(coarse-grained)圖級別標簽,本任務(wù)即為有監(jiān)督的圖級別標簽預(yù)測。
除以上對于預(yù)訓練策略的思考,本文另一個重要貢獻為給學界提供了兩個 Benchmark。真實場景中經(jīng)常會出現(xiàn)的 out-of-distribution 問題,即測試數(shù)據(jù)(test)和訓練數(shù)據(jù)(train+valid)具有不同的分布(如不同物種的蛋白質(zhì)、不同結(jié)構(gòu)的化學分子等),這種場景非常考驗?zāi)P偷姆夯瓦w移能力。作者聯(lián)合 Stanford 化學學院和生物工程學院的學者,聯(lián)合發(fā)布了兩個 GNN 預(yù)訓練+下游任務(wù)數(shù)據(jù)集,來測試 GNN 預(yù)訓練策略在 out-of-distribution 場景下的遷移能力。這兩個 Benchmark 也被廣泛應(yīng)用于后續(xù)的工作中。實驗表明,結(jié)合 Node-level 和 Graph-level 的預(yù)訓練策略可以有效避免 negative transfer,相比不預(yù)訓練的 GNN 有較大的效果提升,且 fine-tuning 過程中收斂的輪數(shù)大大減少。- 本文對應(yīng)的代碼實現(xiàn)中,先進行 Node-level 預(yù)訓練,再基于 Node-level 的模型進行 Graph-level 的預(yù)訓練,最后使用下游任務(wù)的數(shù)據(jù)集進行 Fine-tuning;
- 同時進行本文的兩種 Node-level 預(yù)訓練任務(wù)會使效果下降;
- 實驗數(shù)據(jù)集中 out-of-distribution 指的是,下游任務(wù)的 test 和 train+valid 的分布是不同的。但預(yù)訓練的時候其實是會使用下游任務(wù)的 test 中的全部圖結(jié)構(gòu),以及部分粗粒度標簽。為了避免數(shù)據(jù)泄漏,應(yīng)保證 test 中用來評測的具有細粒度標簽的圖的集合,和用于有監(jiān)督預(yù)訓練的具有粗粒度標簽的圖的集合,相互正交。
2.2 GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training [16]
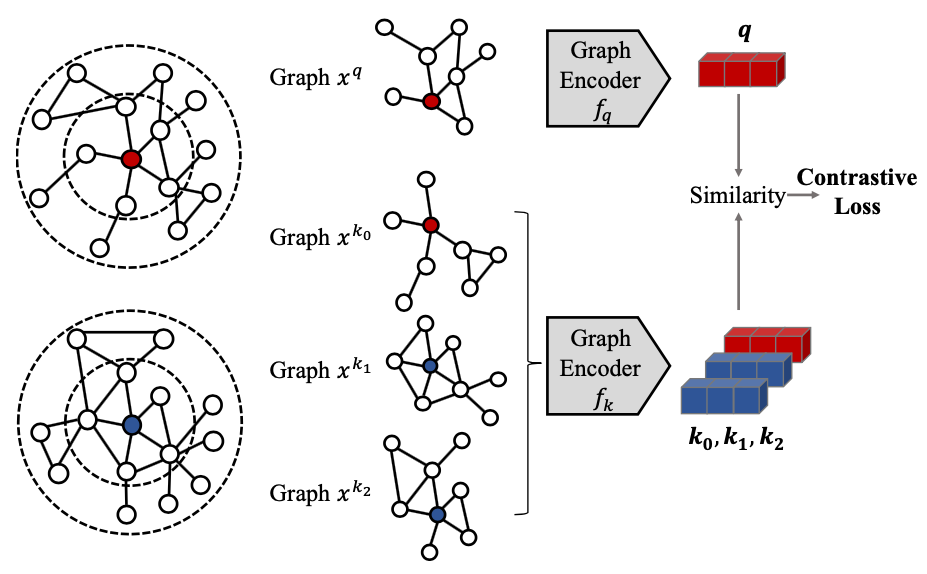
本文來自清華唐杰老師組的 Jiezhong Qiu 等人,發(fā)表于 KDD 2020。本文想解決的重要問題是,圖學習能否進行跨領(lǐng)域(cross-domain)的預(yù)訓練。上一節(jié)的工作中,進行預(yù)訓練的圖和下游任務(wù)上的圖是同領(lǐng)域、同分布的,比如分子圖(都是化學世界中的)、蛋白質(zhì)交互圖(都是從 PPI 網(wǎng)絡(luò)中采樣而來)。本文提出的重要假設(shè)是:富有表達能力的圖結(jié)構(gòu)模式(patterns),在不同的網(wǎng)絡(luò)之間,是通用的(universal)、可遷移的(transferable)。比如網(wǎng)絡(luò)中廣泛存在的 Power Law 定律等。就具體的預(yù)訓練方法而言,則是使用了對比學習的方法。以某個節(jié)點為中心,進行可重新開始的隨機游走(random walk with restart)(一定概率回到起始節(jié)點),從而產(chǎn)生若干子圖。在經(jīng)過 GNN 編碼后,設(shè)計對比學習的損失(Contrastive Loss),使來自同一個中心節(jié)點的向量表示靠近,來自不同中心節(jié)點的向量表示遠離。注意,為了學習廣泛的網(wǎng)絡(luò)結(jié)構(gòu)中的模式,采樣子圖后,節(jié)點會被重新編碼,這樣子圖之間都是匿名的,相互之間不會有共享的節(jié)點表示。本文在節(jié)點分類、圖分類、Top-K 相似度檢索任務(wù)上進行了評測。值得注意的是,盡管經(jīng)過 GCC 預(yù)訓練的 GNN 不一定能在每個數(shù)據(jù)集上都達到最優(yōu)效果,但是都共享同一套 fine-tuning 超參數(shù),即可以達到十分有競爭力的結(jié)果;相比之下,直接訓練的 GNN 需要在不同數(shù)據(jù)集上進行細致的調(diào)參,較為敏感。
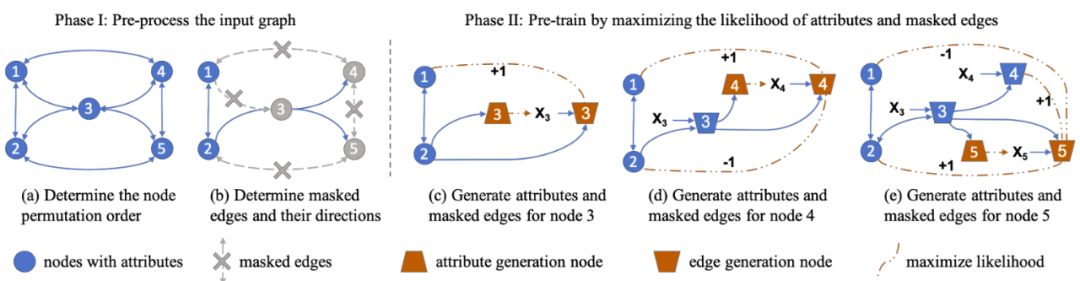
2.3 GPT-GNN: Generative Pre-Training of Graph Neural Networks [6]
本文由 UCLA 孫怡舟老師組的 Ziniu Hu 等人完成,發(fā)表于 KDD 2020。本文提出了一種生成式 GNN 預(yù)訓練任務(wù)。核心想法認為一張圖是根據(jù)某種概率分布生成而來的,因此本文首先根據(jù)假設(shè),人為定義了圖生成所遵循的條件概率分布,進而將圖結(jié)構(gòu)與屬性的恢復(fù)作為 GNN 的預(yù)訓練任務(wù)。作者設(shè)計了一種巧妙的算法,通過將每個節(jié)點拆分成兩個虛擬節(jié)點(Attribute Generation Nodes 和 Edge Generation Nodes),分別對應(yīng)了圖結(jié)構(gòu)恢復(fù)和節(jié)點屬性恢復(fù)的兩個子任務(wù),進而只需運行一次GNN 即可同時完成上述兩個子任務(wù)。另外本文提出的概率生成預(yù)訓練框架,可以直接適配至異構(gòu)的 GNN。本文在 OAG(Open Academic Graph)和 Amazon 評論推薦數(shù)據(jù)集上進行了實驗,并考察了 GPT-GNN 對領(lǐng)域(Field)和時序(Time)的 out-of-distribution 遷移能力。不同于其他工作,本文實驗中圖數(shù)據(jù)的節(jié)點/邊特征均為 XLNet 編碼后的稠密文本特征。對于無特征的節(jié)點/邊,則直接采用鄰居特征的平均作為其自身的特征。
2.4 More Pre-training GNN Papers
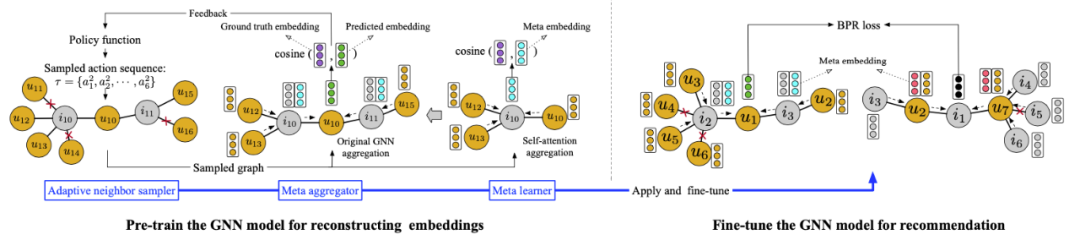
Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation [17]
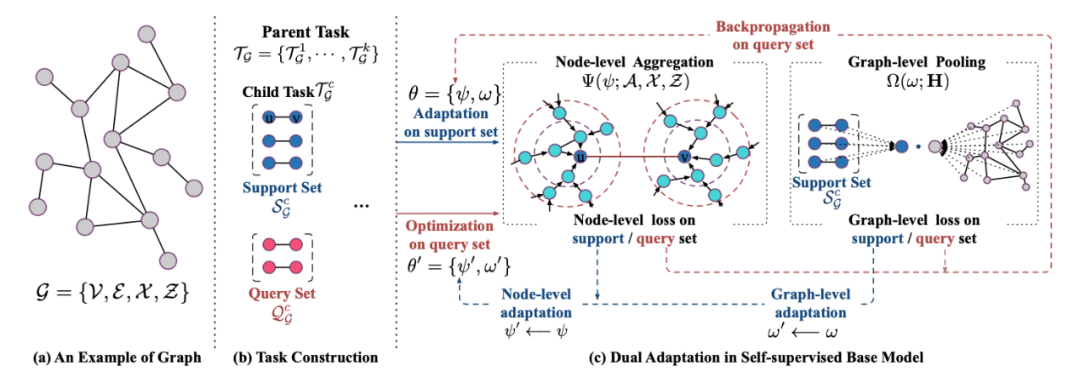
本文為中國人民大學張靜老師組的 Bowen Hao 等人發(fā)表于 WSDM 2021 的工作。本文通過刪去部分用戶-商品交互來模擬冷啟動場景,并將Embedding 的恢復(fù)作為預(yù)訓練任務(wù)。待恢復(fù)的節(jié)點的 ground-truth Embedding 由 NCF [18] 模型基于完整的交互數(shù)據(jù)學習得來。為了減少冷啟動鄰居的影響,本文還基于元學習的思想設(shè)計了 Meta-Aggregator 算法。本文在 ML-1M、MOOCs、Last.fm 這三個公開的推薦系統(tǒng) Benchmark 上進行實驗。Learning to Pre-train Graph Neural Networks [19]
本文為北京郵電大學石川老師組的 Yuanfu Lu 等人發(fā)表于 AAAI 2021 的工作。本文考慮到現(xiàn)有的 GNN預(yù)訓練任務(wù)與下游任務(wù)之間存在不一致性,進而提出利用元學習 Learn to Learn 的思想,使 GNN 預(yù)訓練的優(yōu)化目標為削減預(yù)訓練任務(wù)與下游任務(wù)之間遷移的成本。本文設(shè)計了參考 LINE [20] 一階的 Node-level 預(yù)訓練目標,以及參考 DGI [4] 的 Graph-level 預(yù)訓練目標。本文除了在 Hu et.al. ICLR20 [7] 分享的蛋白質(zhì)數(shù)據(jù)集上進行實驗,還分享了名為 PreDBLP 的學術(shù)網(wǎng)絡(luò)數(shù)據(jù)集并進行實驗。值得注意的是,本文要求被預(yù)訓練的 GNN Encoder 必須包含可學習的參數(shù)化 Pooling 層以用于 Graph-level 預(yù)訓練。Graph Contrastive Learning with Augmentations [8]
本文的預(yù)訓練任務(wù)為自監(jiān)督的圖對比學習任務(wù),并提出了四種對圖數(shù)據(jù)做數(shù)據(jù)增強的方法。原文第 5 章的 Transfer Learning 小節(jié)對該方法以預(yù)訓練-微調(diào)的模式,在 Hu et.al. ICLR20 [7] 分享的蛋白質(zhì)數(shù)據(jù)集和化學數(shù)據(jù)集上進行了實驗。此工作會在本文第三章 GNN + 自監(jiān)督的部分進行詳細介紹。Self-Supervised Graph Transformer on Large-Scale Molecular Data [21]
本文為騰訊 AI Lab 的 Yu Rong 和 Yatao Bian 等人發(fā)表于 NeurIPS 2020 的工作。雖然本文專注于化學分子圖上的圖級別預(yù)測任務(wù),且不適用于任意的 GNN Encoder 預(yù)訓練,但是其預(yù)訓練思想仍然值得借鑒。本文提出的 Node-level 預(yù)訓練任務(wù)是對 Hu et.al. ICLR20 [7] 中 AttrMasking 任務(wù)的拓展,從預(yù)測中心節(jié)點的屬性,拓展為預(yù)測中心節(jié)點K跳鄰居的屬性的集合,從而使節(jié)點的預(yù)測目標包含了 Context 信息。本文還提出了預(yù)測 Motif(特定的子圖元結(jié)構(gòu))的 Graph-level 預(yù)訓練任務(wù)。先人為約定P個 Motif 結(jié)構(gòu),再對預(yù)訓練數(shù)據(jù)集中每個分子圖預(yù)測其中是否含有這P個 Motif 結(jié)構(gòu)。本文在 Hu et.al. ICLR20 [7] 分享的化學分子數(shù)據(jù)集中的 8 個下游任務(wù)上進行了實驗,并使用了更大的(11M)分子圖數(shù)據(jù)集進行預(yù)訓練。3 GNN + 自監(jiān)督
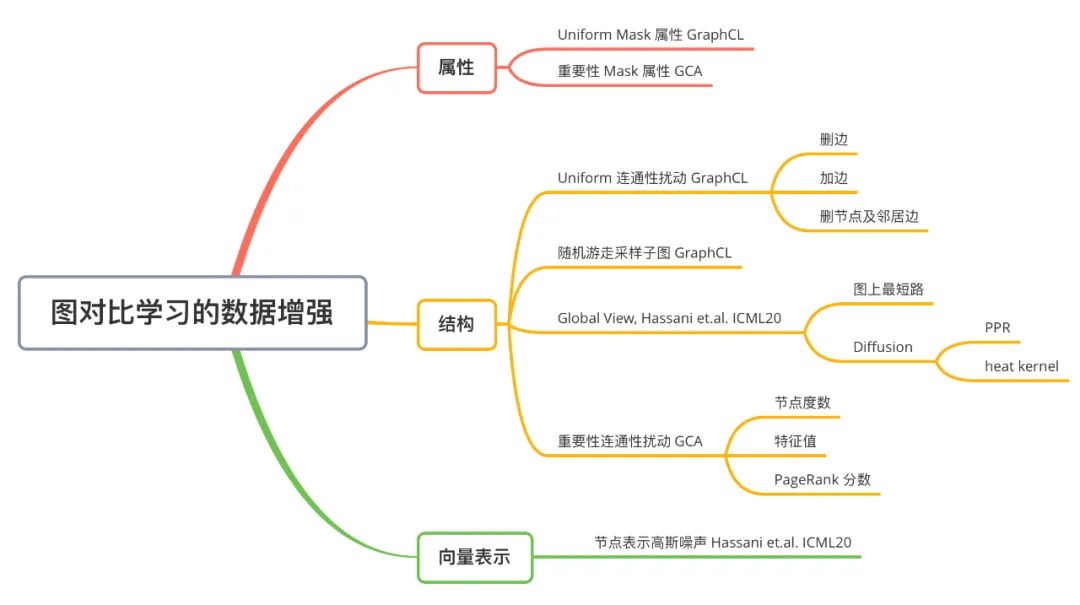
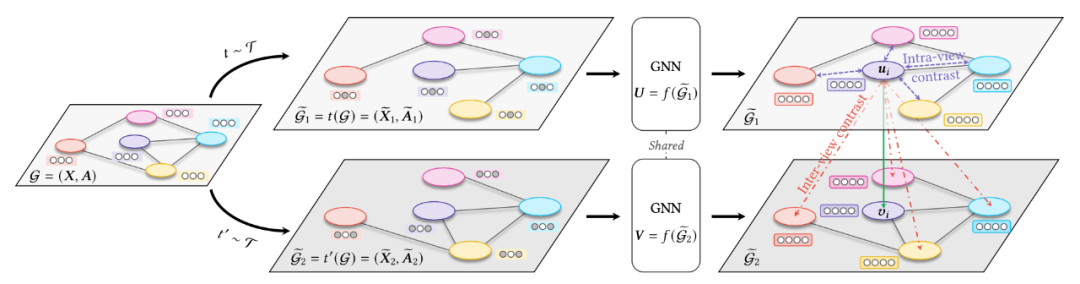
本章節(jié)介紹近年來發(fā)表于頂會的自監(jiān)督 GNN 工作,著重于介紹圖對比學習的發(fā)展。下圖為圖對比學習中,圖數(shù)據(jù)增強方法的歸納:
3.1 Deep Graph Infomax [4]
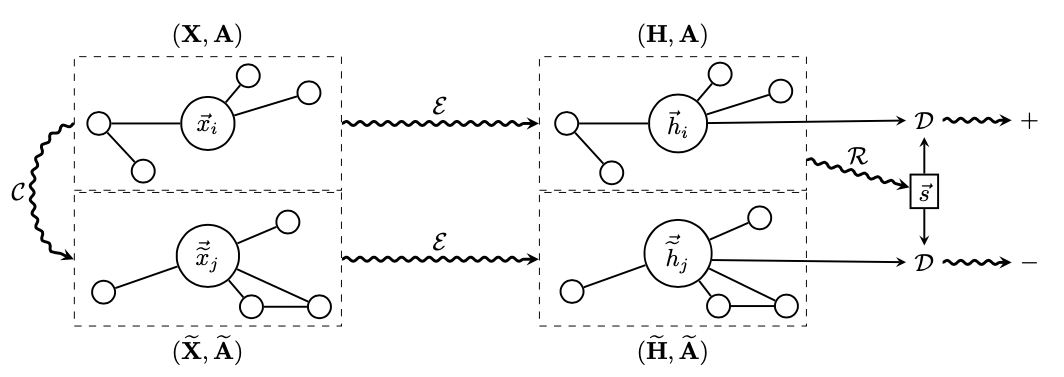
本文由 GAT 的作者 Petar Veli?kovi? 等人發(fā)表于 ICLR 2019。受到 Deep InfoMax [22] 的啟發(fā),作者將其思想運用至圖學習領(lǐng)域。本文提出了一個非隨機游走的,基于互信息最大化的自監(jiān)督圖學習通用框架。方法部分和 Deep InfoMax 類似,上圖中 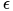 為 GNN Encoder,根據(jù)圖結(jié)構(gòu)將節(jié)點編碼為H,節(jié)點表示經(jīng)過一個 Read-out 函數(shù)可匯總為圖表示向量
為 GNN Encoder,根據(jù)圖結(jié)構(gòu)將節(jié)點編碼為H,節(jié)點表示經(jīng)過一個 Read-out 函數(shù)可匯總為圖表示向量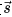 。同時,我們對原圖進行擾動,并將擾動過的圖經(jīng)過相同的 GNN Encoder 得到擾動后的節(jié)點向量
。同時,我們對原圖進行擾動,并將擾動過的圖經(jīng)過相同的 GNN Encoder 得到擾動后的節(jié)點向量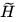 。通過 DecoderD,我們應(yīng)使圖表示與原圖的節(jié)點表示H更接近,并使圖表示與擾動圖的節(jié)點表示更疏遠。本文在較為傳統(tǒng)的 Transductive 數(shù)據(jù)集 Cora、Citeseer、Pubmed 和 Inductive 數(shù)據(jù)集 Reddit 和 PPI 上進行實驗,以驗證 DGI 框架的通用性與有效性。注意本工作是將圖表示與節(jié)點表示做對比,是 Node-Graph 模式的。
。通過 DecoderD,我們應(yīng)使圖表示與原圖的節(jié)點表示H更接近,并使圖表示與擾動圖的節(jié)點表示更疏遠。本文在較為傳統(tǒng)的 Transductive 數(shù)據(jù)集 Cora、Citeseer、Pubmed 和 Inductive 數(shù)據(jù)集 Reddit 和 PPI 上進行實驗,以驗證 DGI 框架的通用性與有效性。注意本工作是將圖表示與節(jié)點表示做對比,是 Node-Graph 模式的。
3.2 Graph Contrastive Learning with Augmentations [8]
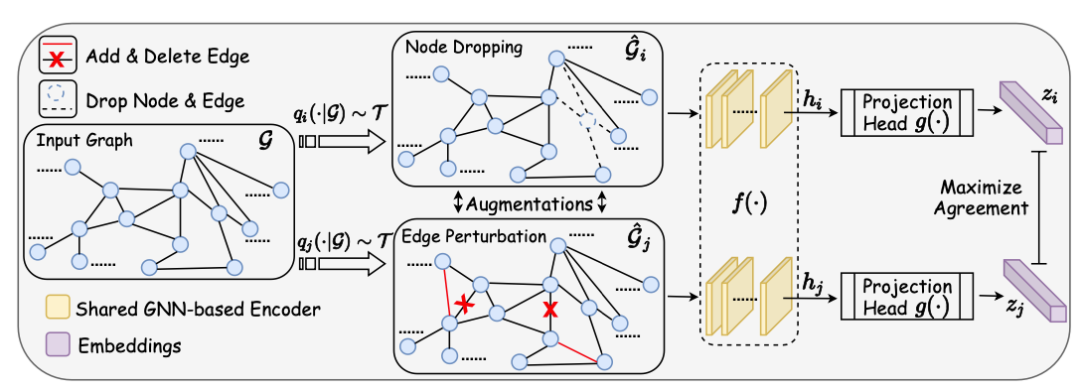
本文由 Texas A&M University 的 Yuning You 和 Tianlong Chen 等人發(fā)表于 NeurIPS 2020。本文基本沿用了 SimCLR [23] 的對比學習架構(gòu)。提出圖對比學習框架 GraphCL。具體而言,首先隨機采樣一個 batch 的圖,之后對每個圖進行兩次隨機的數(shù)據(jù)增強,增強得到的圖數(shù)據(jù)被稱為 View,此后這個 batch 中由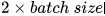 的 View 組成。這樣同一個 batch 中,由相同的圖增強得到的 View 互相之間為正例,不同的圖增強得到的 View 互相之間為負例。對一個 batch 內(nèi)的 View 均過一下 GNN Encoder(上圖中的
的 View 組成。這樣同一個 batch 中,由相同的圖增強得到的 View 互相之間為正例,不同的圖增強得到的 View 互相之間為負例。對一個 batch 內(nèi)的 View 均過一下 GNN Encoder(上圖中的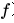 ),得到節(jié)點的表示向量
),得到節(jié)點的表示向量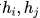 等。再經(jīng)過非線形映射層g后,得到的圖表示向量之間即可根據(jù)先前約定的正負例關(guān)系,計算對比學習的損失函數(shù)。在經(jīng)過自監(jiān)督的訓練后,GNN Encoder 被保留,而非線形映射層被遺棄。
等。再經(jīng)過非線形映射層g后,得到的圖表示向量之間即可根據(jù)先前約定的正負例關(guān)系,計算對比學習的損失函數(shù)。在經(jīng)過自監(jiān)督的訓練后,GNN Encoder 被保留,而非線形映射層被遺棄。
本文的對比學習的框架并無大的創(chuàng)新,重點在于討論如何對圖數(shù)據(jù)做數(shù)據(jù)增強。本文提出了四種圖數(shù)據(jù)增強的方法,具體而言:- Node Dropping:隨機刪除圖中的節(jié)點及與之相連的邊;
- Edge Perturbation:隨機增加 / 刪除圖中一定比例的邊;
- Attribute Masking:隨機 Mask 節(jié)點的屬性;
- Subgraph:使用隨機游走算法得到的子圖(假設(shè)圖的語義信息可以較大程度上被局部結(jié)構(gòu)保留);
本文也對這四種圖數(shù)據(jù)增強策略的使用進行了討論。(1)圖數(shù)據(jù)增強策略的選擇對圖對比學習至關(guān)重要;(2)組合多種合適的圖數(shù)據(jù)增強策略可以達到更好的效果;(3)對邊的擾動(Edge Perturbation)對社交網(wǎng)絡(luò)圖有益,但會損害化學分子圖(由于分子圖中化學鍵對分子性質(zhì)起重要作用);(4)稠密圖中 Attribute Masking 效果更好;(5)一般而言,Node Dropping 和 Subgraph 都可以起到比較好的效果。本文提出的框架得到的 GNN Encoder 可以被用于多種模式。在自監(jiān)督實驗設(shè)置中,可以固定 GNN Encoder 的參數(shù),得到的自監(jiān)督的節(jié)點表示,進而通過 SVM 等傳統(tǒng)機器學習方法進行分類。也可以進行遷移學習,不固定 GNN Encoder 的參數(shù),在下游任務(wù)做微調(diào)。本文在眾多 Benchmark 上進行了大量實驗,包括半監(jiān)督學習、無監(jiān)督表示學習、遷移學習(預(yù)訓練)和魯棒性測試等,具體細節(jié)請參照原論文。本工作是圖表示與圖表示之間做對比,是 Graph-Graph 模式的。3.3 Contrastive Multi-View Representation Learning on Graphs [24]
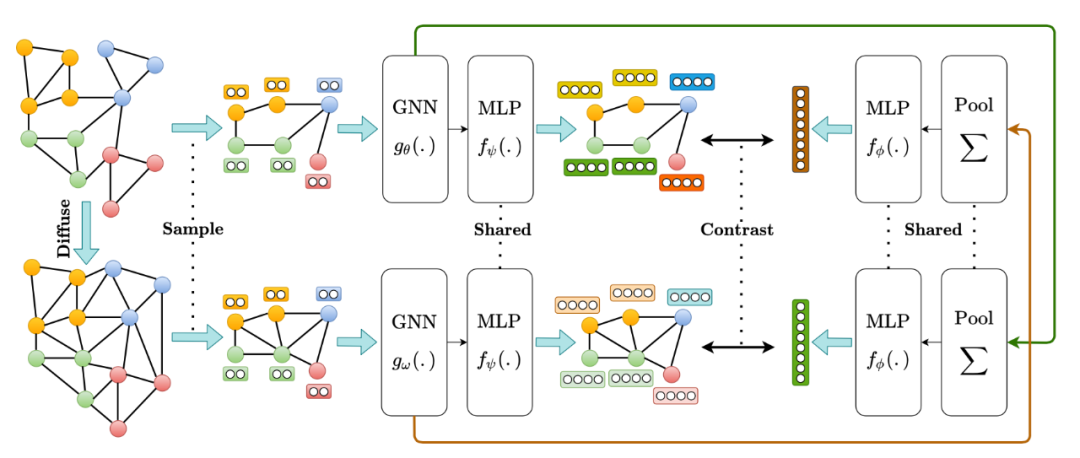
本文由加拿大 AutoDesk AI Lab 的 Kaveh Hassani 和 Amir Hosein Khasahmadi 發(fā)表于 ICML 2020 上。本文提出的方法在框架上與 DGI (Node-Graph 對比的模式)和 SimCLR(同一張圖增強出兩個 View)類似,主要創(chuàng)新點在于提出 Diffusion 這種數(shù)據(jù)增強方法,以及經(jīng)驗化地分析了圖對比學習的一些實驗 Trick。圖數(shù)據(jù)增強方面,主要分為特征層面和結(jié)構(gòu)層面兩種。特征層面的數(shù)據(jù)增強方法主要為隨機 Mask 特征,以及加入高斯噪聲;結(jié)構(gòu)層面的數(shù)據(jù)增強主要包括增加或刪除邊、采樣子圖、或者產(chǎn)生全局層面的 View(Global View)。本工作的主要創(chuàng)新則集中在 Global View 上。文中的Global View 即是將離散的鄰接矩陣稠密化,對鄰接矩陣進行重新賦值,任意兩點之間都可以有一個浮點數(shù)值,兩點聯(lián)系的密切程度。一種平凡的方式是將兩點之間的值設(shè)為圖上的最短距離;更普適性的方式則沿用 NeurIPS 2019 的工作,使用 Diffusion [25]操作。Diffusion 也包含多種方式,如 Personalized PageRank (PPR) 或 heat kernel。詳細推導請參考原文。本文實驗中發(fā)現(xiàn) PPR 方式的 Diffusion 效果最好。本文還通過大量實驗,給出了若干圖對比學習的經(jīng)驗性結(jié)論。(1)多于 2 個的 View 對效果幾乎沒有提升,只用兩個 View 即可;(2)只做 Node-Graph 模式的對比,效果要優(yōu)于 Graph-Graph 的對比,或者多種對比方式混合;(3)對于由節(jié)點表示產(chǎn)生圖表示的過程,簡單的 Readout 函數(shù)要優(yōu)于參數(shù)化的 Pooling 層;(4)正則 (regularization)和標準化(normalization)往往會產(chǎn)生負面影響。3.4 More Self-supervised GNN (Graph Contrastive Learning) Papers
Graph Contrastive Learning with Adaptive Augmentation [26]
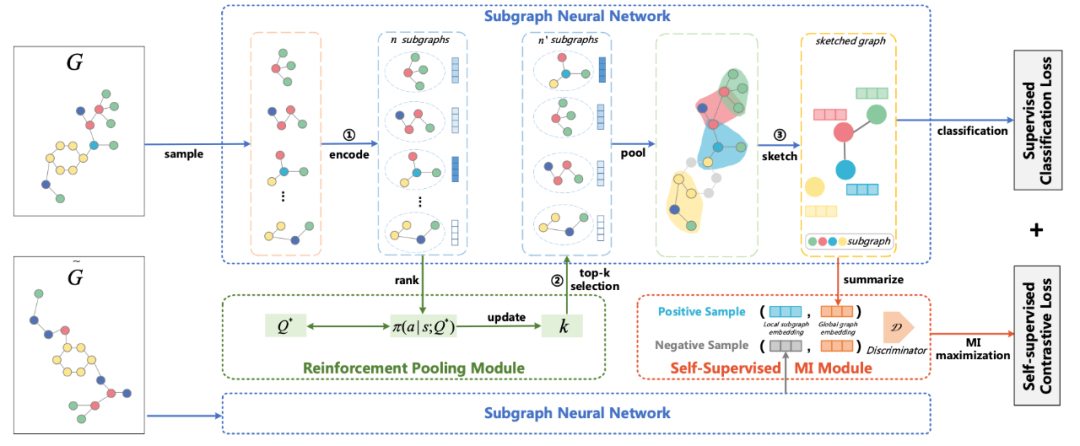
本文為中科院吳書老師組的 Yanqiao Zhu 和 Yichen Xu 等人發(fā)表于 WWW 2021 的工作。本文提出 GCA 方法,主要思想為圖數(shù)據(jù)增強不應(yīng)改變圖的屬性/標簽/性質(zhì)等。因此本文提出,對圖數(shù)據(jù)增強時,應(yīng)該盡量擾動那些不重要的邊/節(jié)點/屬性。本文對圖上節(jié)點的重要性(以 Centrality 為核心)及屬性的重要性(以離散特征出現(xiàn)的頻率為核心)做了詳細定義。此外,本文定義了同時計算“圖內(nèi)”以及“圖間”的 Node-Node 對比學習的損失函數(shù)。SUGAR: Subgraph Neural Network with Reinforcement Pooling and Self-Supervised Mutual Information Mechanism [27]
本文為北京航空航天大學李建欣老師組的 Qingyun Sun 等人發(fā)表于 WWW 2021 的工作。本文通過對比學習損失,來增強子圖表示的表達能力。
4 總結(jié)與討論
GNN 的預(yù)訓練和自監(jiān)督學習關(guān)系緊密又有所區(qū)別,筆者認為最核心的區(qū)別在于兩點:- 預(yù)訓練的核心為遷移能力,即經(jīng)過預(yù)訓練的 GNN 參數(shù)能否快速、準確地遷移至新的下游任務(wù)上,而自監(jiān)督學習一般會固定經(jīng)過訓練的節(jié)點/圖表示向量。對于預(yù)訓練方法 / 模型的遷移能力,現(xiàn)有工作基本以經(jīng)驗性地實驗驗證為主,而理論分析較少;
- 預(yù)訓練時可以利用容易獲取的粗粒度標簽作為監(jiān)督信號,而自監(jiān)督學習一般不使用監(jiān)督信號。但是如何平衡預(yù)訓練過程中的無監(jiān)督任務(wù)和有監(jiān)督任務(wù),以及它們?nèi)绾螌δP偷倪w移能力產(chǎn)生影響的,目前也較為缺少相關(guān)研究。
總之,GNN 的預(yù)訓練和自監(jiān)督學習(對比學習)仍然是個年輕的領(lǐng)域,有眾多問題值得進一步地分析研究。也歡迎對這個方向感興趣的研究者通過郵件([email protected])等方式與筆者聯(lián)系,深入地交流討論,相信思維的碰撞會產(chǎn)生別樣的火花。5 資源匯總
5.1 論文列表
- awesome-self-supervised-gnn: https://github.com/ChandlerBang/awesome-self-supervised-gnn
5.2 預(yù)訓練 GNN 數(shù)據(jù)集
- 蛋白質(zhì)關(guān)系圖(Hu et.al. ICLR 2020 [7])
- [stanford.edu]http://snap.stanford.edu/gnnpretrain/data/bio_dataset.zip
- [GoogleDrive] https://drive.google.com/drive/folders/18vpBvSajIrme2xsbx8Oq8aTWIWMlSgJT?usp=sharing
- https://pan.baidu.com/s/1Yv6dN7F1jgTSz9-nU1eN-A(解壓碼:j97n)
- 化學分子圖(Hu et.al. ICLR 2020 [7])
- [stanford.edu] http://snap.stanford.edu/gnn-pretrain/data/chem_dataset.zip
- PreDBLP(Lu et.al. AAAI 2020 [19])
- [GoogleDrive] https://drive.google.com/drive/folders/18vpBvSajIrme2xsbx8Oq8aTWIWMlSgJT?usp=sharing
- https://pan.baidu.com/s/1Yv6dN7F1jgTSz9-nU1eN-A(解壓碼:j97n)
- Open Academic Graph (OAG, Hu et.al. KDD 2020 [6])
- [GoogleDrive]https://drive.google.com/open?id=1a85skqsMBwnJ151QpurLFSa9o2ymc_rq
Reference
[1]: Thomas N. Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. ICLR 2017.
[2]: William L. Hamilton and Rex Ying et.al. Inductive Representation Learning on Large Graphs. NIPS 2017.
[3]: Petar Veli?kovi? et.al. Graph Attention Networks. ICLR 2018.
[4]: Petar Veli?kovi? et.al. Deep Graph Infomax. ICLR 2019.
[5]: Keyulu Xu and Weihua Hu et.al. How Powerful are Graph Neural Networks? ICLR 2019.
[6]: Ziniu Hu et.al. GPT-GNN: Generative Pre-Training of Graph Neural Networks. KDD 2020.
[7]: Weihua Hu and Bowen Li et.al. Strategies for Pre-training Graph Neural Networks. ICLR 2020.
[8]: Yuning You and Tianlong Chen et.al. Graph Contrastive Learning with Augmentations. NeurIPS 2020.
[9]: Jiaxuan You et.al. Design Space for Graph Neural Networks. NeurIPS 2020.
[10]: Jacob Devlin et.al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
[11]: Ross Girshick et.al. Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR 2014.
[12]: Kun Zhou and Hui Wang et.al. S3 -Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. CIKM 2020.
[13]: Kaiming He et.al. Momentum contrast for unsupervised visual representation learning. CVPR 2020.
[14]: Tomas Mikolov et.al. Distributed Representations of Words and Phrases and their Compositionality. NIPS 2013.
[15]: Tomas Mikolov et.al. Efficient Estimation of Word Representations in Vector Space. ICLR 2013.
[16]: Jiezhong Qiu et.al. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training. KDD 2020.
[17]: Bowen Hao et.al. Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation. WSDM 2021.
[18]: Xiangnan He et.al. Neural Collaborative Filtering. WWW 2017.
[19]: Yuanfu Lu et.al. Learning to Pre-train Graph Neural Networks. AAAI 2021.
[20]: Jian Tang et.al. LINE: Large-scale Information Network Embedding. WWW 2015.
[21]: Yu Rong and Yatao Bian et.al. Self-Supervised Graph Transformer on Large-Scale Molecular Data. NeurIPS 2020.
[22]: R Devon Hjelm et.al. Learning deep representations by mutual information estimation and maximization. ICLR 2019.
[23]: Ting Chen et.al. A Simple Framework for Contrastive Learning of Visual Representations. ICML 2020.
[24]: Kaveh Hassani and Amir Hosein Khasahmadi. Contrastive Multi-View Representation Learning on Graphs. ICML 2020.
[25]: Johannes Klicpera et.al. Diffusion Improves Graph Learning. NeurIPS 2019.
[26]: Yanqiao Zhu and Yichen Xu et.al. Graph Contrastive Learning with Adaptive Augmentation. WWW 2021.
[27]: Qingyun Sun et.al. SUGAR: Subgraph Neural Network with Reinforcement Pooling and Self-Supervised Mutual Information Mechanism. WWW 2021.
編輯:于騰凱
校對:林亦霖