
2020最新自動駕駛綜述,深度解構(gòu)核心技術(shù)

極市導讀
?本文是一篇關(guān)于自動駕駛系統(tǒng)(ADS)的綜述,清晰地介紹了自動駕駛技術(shù)當前面臨的挑戰(zhàn)、系統(tǒng)架構(gòu)、新興方法及核心功能等多方面內(nèi)容。資料翔實,值得一讀。
本文主要翻譯自 A Survey of Autonomous Driving: Common Practices and Emerging Technologies,結(jié)合我自己的理解做了一些精簡和刪改,希望能對大家有一些幫助。這篇文章很新很全,有時間的朋友建議一讀。
摘要
本文主要討論ADS(Autonomous Driving System)的主要問題以及相關(guān)技術(shù)層面的綜述,包括以下幾個方面:當前挑戰(zhàn)、系統(tǒng)架構(gòu)、新興方法、核心功能(定位,建圖,感知,規(guī)劃,人機交互)等。文章最后介紹了相關(guān)可供測試開發(fā)的開源框架及仿真器。
引言
主要介紹了一些背景,提到了兩個著名的自動駕駛研究項目:
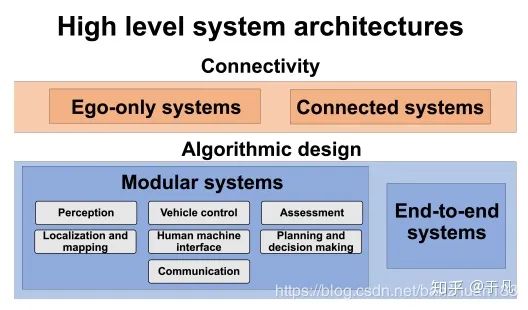
在傳統(tǒng)的自動駕駛方案系統(tǒng)架構(gòu)中,一般將任務劃分為多個模塊,并在各個模塊上使用一系列傳感器和算法。但是隨著深度學習[3]的發(fā)展,逐漸出現(xiàn)了一些端到端的系統(tǒng)。ADS高級系統(tǒng)架構(gòu)分類如下,主要是按連通性和算法實現(xiàn)邏輯劃分,具體介紹在后面。
前景與挑戰(zhàn)
前景就不提了,自動駕駛不缺故事。按照美國汽車工程師學會(SAE)的定義,汽車的自動化水平如下:
目前尚無完全實現(xiàn)L4級別及以上的自動駕駛車輛。
系統(tǒng)構(gòu)成和框架
系統(tǒng)框架
像引言中顯示的那樣,一般從系統(tǒng)框架上可以分為單車輛系統(tǒng)(Ego-only systems)和互聯(lián)車輛系統(tǒng)(Connected multi-agent systems);從算法實現(xiàn)上,可以分為兩大類,一類是通過將各個部分模塊化來實現(xiàn),另一類是直接通過端到端的實現(xiàn)。

最早的端到端系統(tǒng)可以追溯到ALVINN[5],他訓練了一個三層全連接的網(wǎng)絡來輸出車輛的前進方向。文[74]提出了一種輸入圖像輸出轉(zhuǎn)向的深度卷積神經(jīng)網(wǎng)絡。[75]提出了一種時空網(wǎng)絡結(jié)構(gòu),即FCN-LSTM,可以預測車輛的運動。[4]介紹了另一種卷積模型DeepDriving,可以從輸入圖像中學習一組離散的感知指標。實際上這種方法并不是嚴格端到端的,因為如何從一系列感知指標中得到正確的駕駛動作還需要另外的模塊。上述的方法都是有監(jiān)督的訓練,也就是說需要一個專家的行為序列。那么就引入了另一個問題,自動駕駛系統(tǒng)是否應該像人一樣開車?基于上面那個問題,出現(xiàn)了一種新的深度強化學習模型Deep Q Networks(DQN),將強化學習與深度學習相結(jié)合。強化學習的目標是選擇一組能最大化獎勵的行動,深度卷積神經(jīng)網(wǎng)絡在這里的作用是用來逼近最優(yōu)獎勵函數(shù)。簡單來說,基于DQN的系統(tǒng)不再是去模仿專家的行為,而是去學習一種“最佳”的駕駛方式[7] 最后一種神經(jīng)進化是指利用進化算法來訓練人工神經(jīng)網(wǎng)絡,但就實際而言,經(jīng)進化的端到端駕駛不像DQN和直接監(jiān)督學習那樣受歡迎。神經(jīng)網(wǎng)絡的出發(fā)點是去除了反向傳播,從邏輯上來說,更接近生物的神經(jīng)網(wǎng)絡。在[63]中,作者使用駕駛模擬器對RNN進行神經(jīng)進化訓練。上述三種端到端自動駕駛的方法相比,直接監(jiān)督學習的方法可以利用標記數(shù)據(jù)離線訓練,而DQN和神經(jīng)進化都需要在線交互。從理論上講,端到端自動駕駛是可行的,但是還沒有在真實的城市場景中實現(xiàn)(demo不算),最大的缺點是缺乏可解釋性和硬編碼安全措施(Hard coded safety measures)。- 互聯(lián)系統(tǒng)(Connected systems):有一些研究人員認為,靠在單車輛系統(tǒng)上疊傳感器是局限的,自動駕駛的未來應該是側(cè)重在多車輛之間的信息共享。隨著車輛自組織網(wǎng)絡(VANETs)的使用,無論是行人信息,傳感器信息,亦或者是交通信號等,利用V2X(Vehicle to everything),車輛可以輕松訪問其他車輛的數(shù)據(jù),來消除單車的感知范圍,盲點,算力的限制。車輛自組織網(wǎng)絡可以通過兩種不同的方式實現(xiàn):傳統(tǒng)的基于IP的網(wǎng)絡和以信息為中心的網(wǎng)絡( Information-Centric networking,ICN)[8]。由于車輛的高度流動性和在道路網(wǎng)絡上的分散性,因此傳統(tǒng)的基于IP主機的網(wǎng)絡協(xié)議不是很適用,事實上,信息源的身份有時候不是那么重要的一件事,ICN顯然是更合理的方式。在這種情況下,車輛將查詢信息匯聚到某個區(qū)域而不是某個地址,同時,它們開源接收來自任何發(fā)送方的響應。上面我們提到可以利用車輛間的共享信息來完成一些駕駛?cè)蝿眨沁@里還有一個待解決的問題。想象一下一個城市有幾十萬輛車,每輛車可能有若干個攝像頭,雷達,各種各樣的傳感器,每時每刻產(chǎn)生的數(shù)據(jù)量是十分龐大的,更關(guān)鍵的是,大多數(shù)情況下,這些數(shù)據(jù)是雷同的,即使不考慮傳輸和計算的負擔,對算力來說也是極大的浪費。為了減少待處理的數(shù)據(jù)規(guī)模,[9]引入了一個符號學框架,該框架集成了不同的信息源,并將原始傳感器數(shù)據(jù)轉(zhuǎn)換為有意義的描述。除此之外,車輛云計算(Vehicular Cloud Computing,VCC)[10]與傳統(tǒng)的云計算不同,它將傳感器信息保存在車輛上,只有當本地其他車輛查詢時才會被共享,節(jié)省了將恒定的傳感器數(shù)據(jù)流上載/下載到web的成本。
傳感器和硬件
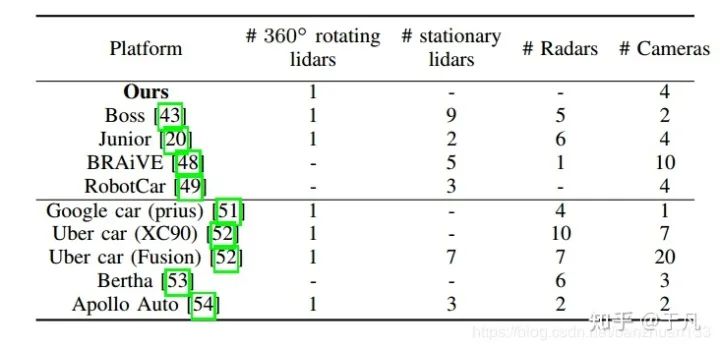
為了保證系統(tǒng)的魯棒性和可靠性,大多數(shù)任務都需要較高的傳感器冗余度,因此ADS一般都采用多種車載傳感器。硬件模塊大致可以分為五類,外部感知傳感器(Exteroceptive sensors),監(jiān)測車輛自身狀態(tài)的本體感知傳感器(Proprioceptive sensors),通信單元,執(zhí)行器和計算單元。常見的外部傳感器比較如下表:

單目相機(Monocular Cameras):最常見最廉價的傳感器之一,除此之外,二維的計算機視覺算是一個比較成熟的研究領域,雖然理論上無法獲得深度,但是現(xiàn)在也有一些基于單目深度的結(jié)果,缺點主要還是在精度和容易受環(huán)境因素影響上。現(xiàn)在還有一些針對特殊場景而開發(fā)的相機,如全景相機(Omnidirection Camera),閃光相機(Flash Camera),熱敏相機(Thermal Cameras),事件相機(Event Camera)[11]等。所謂的全景相機就是理論上擁有360度視角的相機,事實上,這一類相機的難點并不在捕捉圖像而是在圖像拼接上,因為球面圖像是高度失真的,所以校準的難度很大。而事件相機是一種比較新穎的概念,傳統(tǒng)相機是按時間采用,而事件相機是事件觸發(fā)型,它對場景中移動造成的變換比較敏感,因此可以用在檢測動態(tài)目標上。事件相機的簡單示例如下圖所示:

雷達(Radar)和激光雷達(Lidar):一般來說,現(xiàn)在都是采用多傳感器的形式,用雷達或者激光雷達來彌補相機(包括深度相機)在深度信息上的缺陷。激光雷達和雷達的工作原理其實差不多,只不過激光雷達發(fā)射的是紅外線而不是無線電波,在200米以內(nèi)的精度是很高的,但是相對雷達來說,更容易受到天氣的影響。雷達的精度雖然不如激光雷達高,但是由于測距長,成本低,對天氣魯棒性強,目前已經(jīng)廣泛應用于輔助駕駛(ADAS)中,比如接近警告和自適應巡航。(原文中沒有提到這兩種雷達的干擾問題,實際上金屬對電磁波的干擾,生物對紅外的干擾,相同頻段的(激光)雷達互相干擾是十分關(guān)鍵的問題)。- 本體傳感器:一般指車輛自身攜帶的傳感器,如里程計,IMU,轉(zhuǎn)速計等。一些研究機構(gòu)及公司的整車配置如下表所示:
定位與建圖
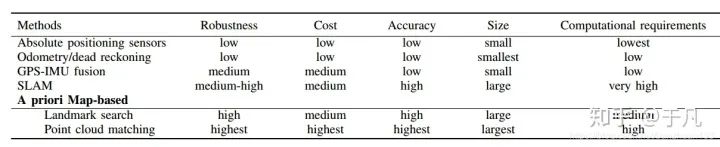
定位指的是在環(huán)境中找到相對于參考系的位置,對于任何移動機器人來說這個任務都是最基本的。下文會詳細接到三種最常見的方法:GPS-IMU融合,SLAM,基于先驗地圖定位。幾種定位方法的比較如下表所示
GPS-IMU融合
GPS-IMU融合的主要原理是用絕對位置數(shù)據(jù)修正航位推算(dead reckoning)的累積誤差[12]。在GPS-IMU系統(tǒng)中,IMU測量機器人位置和方向的變化,并對這些信息進行處理,以便用航位推算法對機器人進行定位。但是IMU有一個顯著的缺點,就是我們常說的累積誤差。因此引入GPS的絕對位置信息(相當于一個反饋),可以有效地對IMU誤差進行校正。
GPS-IMU融合的方法的精度比較低,實際上并不能直接用在車輛定位上。在2004年的DARPA挑戰(zhàn)賽中,卡內(nèi)基梅隆大學(Carnegie Mellon University)的紅隊就因為GPS錯誤而未能通過比賽。除此之外,在密集的城市環(huán)境中,像隧道,高層建筑等都會影響GPS的精度。盡管GPS-IMU系統(tǒng)本身無法滿足自動駕駛的性能要求,但是可以和激光雷達等傳感器相結(jié)合進行位姿估計。
SLAM
顧名思義,SLAM是一種在線地圖繪制同時定位的行為(理論上的同時)。理論上SLAM不需要關(guān)于環(huán)境的先驗信息,就目前而言,更多是應用在室內(nèi)環(huán)境(室外更多還是基于預先構(gòu)建的地圖進行定位)。關(guān)于自動駕駛領域的SLAM可以參見[13]。
基于先驗地圖定位
基于先驗地圖的定位技術(shù)的核心思想是匹配:定位是通過比較在線數(shù)據(jù)同先驗地圖的信息來找到最佳匹配位置[14]。也就是根據(jù)先驗的地圖信息來確定當前的位姿。這個方法有一個缺陷,一般需要額外的一個地圖制作步驟,而且,環(huán)境的變化可能會對結(jié)果產(chǎn)生負面影響(比如光照變化,參照物移動等)。這類方法大致可以分為兩大類:基于路標的定位和基于點云的匹配。- 基于路標:與點云匹配相比,基于路標的定位計算成本要低得多。理論上來說,只要路標的數(shù)量足夠多,這種定位就是魯棒的。[15]中采用了激光雷達和蒙特卡羅結(jié)合的方法,通過匹配路標和路緣(road markers and curbs)來定位車輛的位置。[16]介紹了一種基于視覺的道路標記(road marking)檢測方法,事先保存了一份低容量的全局數(shù)字標記地圖(a low-volume digital marker map with global coordinates),然后與前置相機的采集數(shù)據(jù)進行比較。最后根據(jù)檢測結(jié)果和GPS-IMU輸出利用粒子濾波器進行位置和方向的更新。該方法的主要缺點在于地標的依賴性。
基于點云:點云匹配一般是指局部的在線掃描點云通過平移和旋轉(zhuǎn)同先驗的全局點云進行匹配,根據(jù)最佳匹配的位置來推測機器人相對地圖的局部位置。對于初始位姿的估計,一般是結(jié)合GPS利用航位推算。下圖展示了利用Autoware進行的地圖制作結(jié)果:

文獻[17]中使用了一種帶有概率圖的多模態(tài)方法,在城市環(huán)境中實現(xiàn)了均方誤差小于10cm的定位。與一般逐點進行點云匹配并舍棄不匹配部分相比,該方法中所有觀測數(shù)據(jù)的方差都會被建模并應用于匹配任務。后續(xù)幾種常見的匹配方法包括基于高斯混合模型(Gaussian Mixture Maps ,GMM)),迭代最近點匹配(Iterative Closest Point ,ICP),正態(tài)分布變換(Normal Distribution Transform ,NDT)等。關(guān)于ICP和NDT,[18]進行了詳細的比較(我之前也寫過一篇博客)。ICP和NDT算法都有相應的一些改進和變式,比如[19]提出了一種基于NDT的蒙特卡羅定位方法,該方法利用同時利用了離線的靜態(tài)地圖和不斷進行更新的短期地圖,當靜態(tài)地圖失效時,基于NDT的柵格來更新短期地圖。
基于先驗地圖方法最大的缺陷就在于先驗地圖的獲取上,實際上制作和維護一個可靠的高精度地圖是相當費時又費力的一件事。除此之外,還有一些其他情況,比如跨維度的匹配(二維到三維,三維到二維等)。[20]就提到一種利用單目相機在點云中進行定位的方法。在初始姿態(tài)估計的基礎上,利用離線的三維點云地圖生成二維圖像,并同相機捕捉到的圖像進行在線歸一化比較。這種方法相當于簡化了感知的工作,但是增大了計算的復雜度。
感知
感知周圍環(huán)境并提取可供安全導航的信息是自動駕駛的核心之一。而且隨著近年來計算機視覺研究的發(fā)展,相機包括三維視覺逐漸成為感知中最常用的傳感器。本節(jié)主要討論基于圖像的目標檢測,語義分割,三維目標檢測,道路和車道線檢測,目標跟蹤等。
檢測
基于圖像的目標檢測
一般目標檢測指的是識別感興趣目標的位置和大小(確定圖像中是否存在特定類的對象,然后通過矩形邊界框確定其位置和大小),比如交通燈,交通標志,其他車輛,行人,動物等。目標檢測是計算機視覺的核心問題,更重要的是,它還是其他許多任務的基礎,比如說目標跟蹤,語義分割等。
對于物體識別的研究雖然始于50多年前,但是直到最近幾年,算法的性能才算真正達到自動駕駛相關(guān)的水平。2012年深度卷積神經(jīng)網(wǎng)絡(DCNN) AlexNet[21]一舉玩穿了ImageNet挑戰(zhàn)賽,開啟了深度學習用于目標檢測的浪潮。基于圖像的目標檢測survey也有很多,比如[22]。盡管目前最先進的方法基本都依賴于DCNN,但它們之間也存在明顯的區(qū)別:
1)單級檢測框架(Single stage detection frameworks)使用單個網(wǎng)絡同時生成對象檢測位置和類別預測。
2)區(qū)域生成檢測框架(Region proposal detection frameworks)有兩個不同的階段,首先生成感興趣的一般區(qū)域(候選區(qū)域),然后通過單獨的分類器網(wǎng)絡進行分類。
區(qū)域生成網(wǎng)絡是目前比較先進的檢測方法,不足是對計算能力要求高,不容易實現(xiàn),訓練和調(diào)整。相應的,單級檢測算法具有推理速度快,存儲成本低等優(yōu)點,非常適合實時自動駕駛場景。YOLO[23]是當前十分流行的一種單級檢測算法,也有許多改進的版本。YOLO的網(wǎng)絡利用DCNN在粗網(wǎng)格上提取圖像特征,顯著地降低了輸入圖像的分辨率。之后用一個全連接的神經(jīng)網(wǎng)絡預測每個網(wǎng)格單元的類概率和邊界框參數(shù),這種設計使得YOLO速度非常快。另一種廣泛使用的方法是單點檢測器(Single Shot Detector,SSD)[24],它的速度甚至比YOLO更快。SSD與YOLO都在粗網(wǎng)格上進行檢測,但是SSD也使用在DCNN早期得到的高分辨率特征來改進對小目標的檢測和定位。
對于自動駕駛?cè)蝿諄碚f,可靠的檢測是至關(guān)重要的,但同時也需要平衡精度和計算成本,以便規(guī)劃和控制模塊能有充足的時間來對檢測結(jié)果做出反應。因此,目前SSD通常是ADS的首選檢測算法。當然,區(qū)域生成網(wǎng)絡(RPN)在目標識別和定位精度方面的性能已經(jīng)遠勝單級檢測框架算法,并且近年來隨著計算能力的不斷提高,也許在不就的將來,RPN或者其他兩階段檢測框架就能適用于ADS任務中。
基于圖像的目標檢測方法的主要不足大多來源于相機的天然缺陷,比如難以處理弱光條件,對于陰影,天氣,光照變化的適應性不足等,尤其是監(jiān)督學習的方法。一方面可以研究一些光照不變特征的方法,另一方面的話,通常來說,采用單傳感器很難能適應各種復雜的現(xiàn)實情況,因此采用多傳感器融合的策略是大勢所趨。比如利用雷達或者紅外傳感器來處理低光條件下的目標檢測等。
語義分割
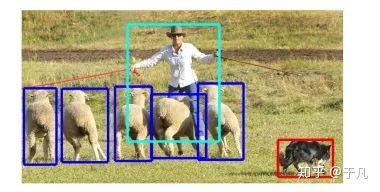
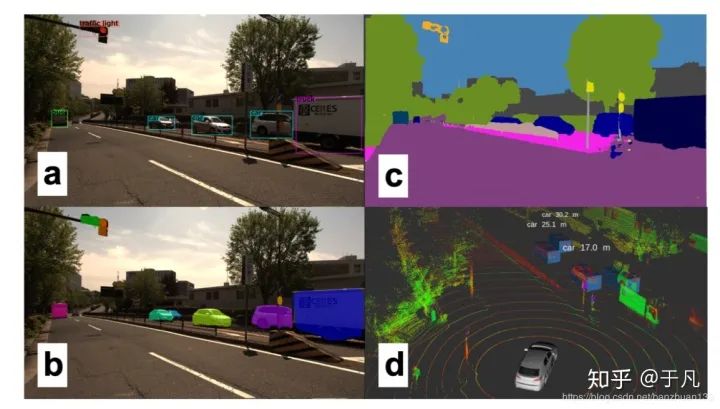
這里簡單談一下我理解的圖像分類,目標檢測和語義分割的區(qū)別。圖像分類是給你一堆圖,告訴我每張圖主要內(nèi)容的類別,最經(jīng)典的就是MNIST上的手寫數(shù)字識別,輸出是每張圖代表什么數(shù)字。目標檢測是輸入一系列圖,把每張圖里我感興趣的目標框出來,比如上面說的用YOLO做行人檢測,輸出就是用矩形框把每張圖里的行人框出來。語義分割的任務是把圖像里的每一個像素都歸到某個類別里,有點像機器學習中聚類的概念。下面兩張圖左邊是目標檢測,右邊是語義分割。

為什么自動駕駛需要研究語義分割呢?因為僅僅簡單用矩形框把目標框出來的效果可能很差,尤其是在道路,交通線上。甚至我們應該更進一步進行實例分割(Instance segmentation),來區(qū)分不同軌跡和行為的對象。得益于目標檢測的發(fā)展,分割方法逐漸在實時應用中變得可行。Mask R-CNN[25]是Faster R-CNN[26]的推廣,多任務網(wǎng)絡可以同時實現(xiàn)精確的邊界框估計和實例分割,該方法可以用來進行行人姿態(tài)估計等任務。Mask R-CNN的速度可以達到每秒5幀,速度接近了實時ADS的要求。
與使用CNN使用區(qū)域生成網(wǎng)絡進行目標檢測不同,分割網(wǎng)絡通常采用卷積的組合進行特征提取,然后利用反卷積(去卷積,deconvolutions)來獲得像素級標簽[27]。此外,特征金字塔網(wǎng)絡(Feature pyramid networks)也被廣泛使用,比如在PSPNet[28]中,它還引入了擴散卷積(dilated convolutions)進行分割。DeepLab[29]是目前最先進的對象分割模型,主要用到了稀疏卷積(sparse convolutions)的思想。在ADS中使用DeepLab進行分割的效果如下:
盡管大多數(shù)分割網(wǎng)絡仍然太慢且計算量巨大,無法在ADS中使用,但需要注意的是,許多分割網(wǎng)絡最初都是針對不同的任務(如邊界框估計)訓練的,然后在推廣到分割網(wǎng)絡。而且之后證明這些網(wǎng)絡可以學習圖像的通用特征表示并推廣到其他任務當中。這也許提供了另一種可能性,利用單一的廣義感知網(wǎng)絡可以解決ADS的所有不同感知任務。
三維目標檢測
鑒于經(jīng)濟性,可用性和研究的廣泛性,幾乎所有的算法都使用相機作為主要的感知方式。把相機應用在ADS中,限制條件除了前面討論到的光照等因素外,還有一個問題就是目標檢測是在圖像空間的,忽略了場景的尺度信息。而當需要進行避障等動態(tài)駕駛?cè)蝿諘r,我們需要將二維圖像映射到三維空間來獲得三維的信息。實際上利用單個相機來估計深度也是可行的[30],當然利用立體相機或者多相機的系統(tǒng)更具魯棒性。從二維到三維的映射必然需要解決一個圖像匹配問題,這給已經(jīng)夠復雜的感知過程又增加了大量的計算處理成本。
所以我們換一種思路,是否可以直接在三維進行目標檢測。我們知道3D雷達收集的數(shù)據(jù)是三維的,從本質(zhì)上已經(jīng)解決了尺度問題,而且3D雷達不依賴于光照條件,不容易受到惡劣天氣的影響。3D雷達收集的是場景表面的稀疏3D點,這些點很難用于對象檢測和分類,分割反而相對容易。傳統(tǒng)方法使用基于歐式距離的聚類(Euclidean clustering)或者區(qū)域生長(region-growing)算法[31]來將點劃分為不同對象。結(jié)合一些濾波技術(shù),比如地面濾波(ground filtering)[32]或者基于地圖(map-based filtering)的濾波[33],可以使該方法更具魯棒性。下圖我們展示了一個從原始點云輸入中獲取聚類對象的例子

與基于圖像的方法發(fā)展趨勢一樣,機器學習最近也取代了傳統(tǒng)3D檢測方法,而且這種方法還特別適用于RGB-D數(shù)據(jù)。RGB-D產(chǎn)生的數(shù)據(jù)與點云類似,不過包含顏色信息,由于范圍比較有限而且可靠性不高,尚未應用于ADS系統(tǒng)。[34]利用3D占據(jù)柵格(occupancy grid)表示的方法完成了RGB-D數(shù)據(jù)的對象檢測。此后不久,類似的方法被應用于激光雷達創(chuàng)建的點云。受基于圖像的方法的啟發(fā),盡管計算開銷很大,但仍然使用了3D CNN。VoxelNet[35]首次給出了令人信服的點云上三維邊界框估計的結(jié)果。SECOND[36]利用激光雷達數(shù)據(jù)的自然稀疏性,改進了這些工作的準確性和計算效率。最近提出的幾種算法比較如下表所示
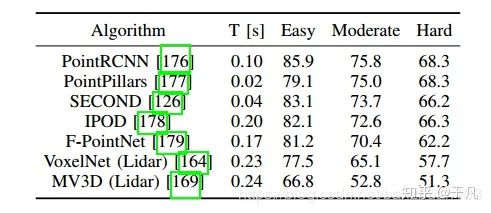
數(shù)據(jù)集是KITTI[42],結(jié)果以中等類別精度排序,算法中只使用點云數(shù)據(jù)。
基于激光雷達的感知的另一個選擇是點云數(shù)據(jù)的二維投影。點云數(shù)據(jù)在2D中有兩種主要表示形式,一種是深度圖,主要是受通過深度估計執(zhí)行3D對象檢測[37]和在RGB-D數(shù)據(jù)上進行操作方法的啟發(fā)。VeloFCN網(wǎng)絡[38]提出使用單通道深度圖像作為淺層單級卷積神經(jīng)網(wǎng)絡的輸入,生成3D車輛候選,許多其他算法也都采用了這種方法。深度圖的另一個用途是用于激光雷達點的語義分類(semantic classification)[39]。另一種2D投影是指對鳥瞰圖(bird’s eye view,BV)的投影,該方式越來越受歡迎。不過鳥瞰圖僅有單純的2D離散信息,因此如果激光雷達點的值僅有高度變化的話,在2D中必定會互相遮擋。MV3D算法[40]使用相機圖像,深度圖像以及多通道BV圖像(這里不同通道對應不同的高度),來最小化這種遮擋。一些工作重復使用基于相機的算法,并訓練了有效的網(wǎng)絡來在2D BV圖像上進行3D對象檢測[41]。這些算法都是在KITTI數(shù)據(jù)集和nuScenes[43]數(shù)據(jù)集上進行測試的。2D的方法計算成本要比3D小得多,而且利用稀疏性改進這些工作的準確性和效率之后[36],這些方法可以迅速接近ADS系統(tǒng)所需的精度。
目標跟蹤
對于復雜和高速情況下的自動駕駛,僅僅估計位置是不夠的,為了避免碰撞,還需要估計動態(tài)目標的航向和速度,以便應用運動模型跟蹤目標并預測目標未來的運動軌跡。同樣的,一般都通過多個相機,激光雷達或者雷達來獲取傳感器信息,且未來更好地應對不同傳感器的局限性和不確定性,通常采用傳感器融合的策略進行跟蹤。
常用目標跟蹤算法依賴于簡單的數(shù)據(jù)關(guān)聯(lián)技術(shù)和傳統(tǒng)的過濾方法。當在三維空間中以高幀速率跟蹤對象時,最近鄰方法通常足以建立對象之間的關(guān)聯(lián)。基于圖像的方法一般需要建立一些外觀模型,例如使用顏色直方圖,梯度或者其他特征(如KLT)等來評估相似度[44]。基于點云的方法也使用一些相似性度量,例如點密度,Hausdorff距離[45]。由于總是可能出現(xiàn)關(guān)聯(lián)錯誤的情況,因此經(jīng)常使用多假設跟蹤(multiplehypothesis tracking)算法[46],這確保了跟蹤算法可以從任一時間內(nèi)的不良數(shù)據(jù)關(guān)聯(lián)中回復。一般我們都是在每幀中使用占據(jù)地圖(occupancy maps),然后在幀之間進行數(shù)據(jù)關(guān)聯(lián),尤其是在使用多個傳感器時。為了獲得平滑的動態(tài)特性,采用傳統(tǒng)的Bayes濾波器對檢測結(jié)果進行濾波。對于簡單的線性模型,Kalman濾波一般是足夠的,而擴展Kalman濾波器(EKF)和無跡Kalman濾波器(UKF)可用于處理非線性動態(tài)模型。我們實現(xiàn)了一個基本的基于粒子濾波的目標跟蹤算法,利用相機和3D激光雷達來跟蹤行人,結(jié)果如下(白色的表示軌跡)

為了使跟蹤更具魯棒性,經(jīng)常會用到被跟蹤對象的物理模型。在這種情況下,首先使用諸如粒子濾波器之類的非參數(shù)化方法,之后利用一些物理參數(shù)(如大小)來進行動態(tài)跟蹤[47]。更為復雜的濾波方法,如raoblockwelled粒子濾波器,被用于跟蹤L型車輛模型的動態(tài)變量和車輛幾何變量(dynamic variables and vehicle geometry variables)[48]。針對車輛和行人,現(xiàn)在有各種各樣的模型,甚至一些模型可以推廣到任何動態(tài)對象。此外,深度學習也開始被應用于跟蹤問題,尤其是對圖像領域。[49]通過基于CNN的方法實現(xiàn)了單目圖像的實時跟蹤。利用多任務網(wǎng)絡來估計物體動力學的方法也在涌現(xiàn)[50],這進一步表明了能夠處理多種感知任務的廣義網(wǎng)絡可能是ADS感知的未來。
道路和車道線檢測
前面介紹的邊界框估計方法對于某些感興趣的對象十分有用,但對于一些連續(xù)曲面(如道路)則不適用。可行駛曲面的確定是ADS的關(guān)鍵,所以把該問題從檢測問題中單獨出來作為一個子類研究。從理論上講,利用語義分割可以解決該問題。一個簡單的做法是從車輛自身來確定可駕駛區(qū)域,將道路分為若干個車道,并確立主車道,該技術(shù)被應用在許多ADAS中,如車道偏離警告,車道保持和自適應巡航控制[51]。更有挑戰(zhàn)性的任務就是怎么確定其他車道和對應的方向,并在此基礎之上理解更復雜的語義,比如轉(zhuǎn)向和合并[52]。上述具體不同的任務對ADS的探測距離和可靠性要求各不相同,但是自動駕駛需要對道路結(jié)構(gòu)有一個完整的語義理解以及長距離探測多條車道的能力。
前面提到的數(shù)據(jù)預處理(包括圖像和點云)的方法,在道路處理中也同樣適用,比如歸一化照明條件(normalize lighting conditions),濾波,顏色,強度,梯度信息統(tǒng)計等。另外,利用道路的均勻性和邊緣的突變(elevation gap at the edge )我們可以使用區(qū)域生長方法(regiongrowing)[53]。也有一些基于機器學習的方法,包括將地圖與數(shù)據(jù)融合[54]或者完全基于外觀的分割[55]。一旦曲面被估計出來之后,就可以利用一些模型擬合來保證道路和車道的連續(xù)性,包括參數(shù)化模型(比如直線、曲線)和非參數(shù)化模型的幾何擬合。[56]提出了一個集成了拓撲元素(如車道分割與合并)的模型,還可以結(jié)合車輛動力學和動態(tài)信息,利用濾波算法獲得更平滑的結(jié)果。目前道路和車道線檢測已經(jīng)有許多方法,并且有些已經(jīng)集成到了ADAS系統(tǒng)中,但是大多數(shù)方法仍然依賴于各種假設與限制,能夠處理復雜道路拓撲的真正的通用系統(tǒng)尚未開發(fā)出來。通過對拓撲結(jié)構(gòu)進行編碼來獲得標準化的道路圖并結(jié)合新興的基于機器學習的道路與車道線分類方法,也許會形成一個魯棒的可應用于自動駕駛的系統(tǒng)。
評估( ASSESSMENT)
一個魯棒的ADS系統(tǒng)應該能夠不斷地評估當前狀況的總體風險水平并預測周圍駕駛員和行人的意圖,缺乏敏銳的評估機制可能會導致事故。本節(jié)主要討論以下三類評估:總體風險和不確定性評估,人類駕駛行為評估和駕駛風格識別。
總體風險和不確定性評估
總體評估可以理解為去量化駕駛場景的不確定性和風險水平,目的是為了提高ADS的安全性。[57]提出了一種利用貝葉斯方法來量化深度神經(jīng)網(wǎng)絡的不確定性。[3]設計了一個貝葉斯深度學習體系結(jié)構(gòu),并在一個模擬場景中展示了它相對于傳統(tǒng)方法的優(yōu)勢。這種方法的總體邏輯是每個模塊在系統(tǒng)中的傳遞與輸入都服從概率分布,而不是一個精確的結(jié)果。另一種方法就是單獨評估駕駛場景下的風險水平,可以理解為前者是從系統(tǒng)內(nèi)部評估,后者是從系統(tǒng)外部評估。[58]將傳感器數(shù)據(jù)輸入到一個風險推理框架中,利用隱馬爾科夫模型(Hidden Markov Models ,HMMs)和語言模型檢測不安全的車道變更事件。[59]引入了一個深度時空網(wǎng)絡來推斷駕駛場景的總體風險水平,也可以利用來評估車道變更的風險水平。下圖是一個示例,代表兩種圖像序列下的風險評估結(jié)果:

周圍駕駛行為評估
實際環(huán)境中的自動駕駛決策還有周圍駕駛員的意圖與行為相關(guān)。目前該技術(shù)在ADS領域尚不常見。[60]用隱馬爾可夫模型(HMM)對目標車輛的未來行為進行了預測,通過學習人類駕駛特征,將預測時間范圍延長了56%。這里主要是利用了預定義的移動行為來標記觀測值,然后再使用HMM以數(shù)據(jù)位中心學習每種類型的特征。除此之外,還有一些其他的方法,比如貝葉斯網(wǎng)絡分類器,混合高斯模型和隱馬爾科夫模型相結(jié)合[61],支持向量機等。這一類評估的主要問題在于觀測時間短,實時計算量要求高,大多數(shù)情況下,ADS只能觀測周圍車輛幾秒鐘,因此不能使用需要較長觀察周期的復雜模型。
駕駛風格識別
人和機器最大的不同在于人是有情緒的,有些駕駛員比較激進,有些比較穩(wěn)重。2016年,谷歌的自動駕駛汽車在換道時和迎面而來的巴士相撞,原因就是自動駕駛汽車以為巴士會減速,而巴士司機卻加速了。如果能事先知道司機的駕駛風格,并結(jié)合進行預測,這場事故也許是可以避免的。當然,駕駛風格目前還沒有一個準確的定義,因此分類的依據(jù)也有很多種,比如油耗,均速,跟車行為等。一般來說,對駕駛風格的分類大多是將其分為若干類,對應于不同的離散值,但是也有連續(xù)型的駕駛風格分類算法,比如[62]將其描述為介于-1到+1之間的值。
同樣,也有一些基于機器學習的方法。[63]采用主成分分析法( Principal component analysis, PCA),以無監(jiān)督的方式檢測出5個不同的駕駛類別。[64]使用了基于GMM的駕駛員模型來識別單個駕駛員的行為,主要研究了跟車行為和踏板操作(pedal operation)。[65]使用詞袋(Bag-of-words)和K均值聚類來表示個體的駕駛特征。[66]使用了一個自編碼網(wǎng)絡(autoencoder network)來提取基于道路類型的駕駛特征。類似的還有將駕駛行為編碼到3通道RGB空間中,利用一個深度稀疏的自編碼器(deep sparse autoencoder)來可視化各個駕駛風格[67]。將駕駛風格識別成功應用到真實的ADS系統(tǒng)的目前還沒有相關(guān)報道,但是這些研究可能是未來ADS發(fā)展的一個方向。
規(guī)劃與決策
全局規(guī)劃
全局規(guī)劃是比較成熟的一個研究領域,幾乎所有車都已經(jīng)配備了導航系統(tǒng),利用GPS和離線地圖能夠輕易規(guī)劃全局路徑。全局路徑規(guī)劃可以分為以下四種:目標導向(goal-directed),基于分割( separator-based),分級規(guī)劃( hierarchical)和有界跳躍(bounded-hop)。目標導向最常見,比如Djikstra和A*,已經(jīng)廣泛應用于各個領域。基于分割的邏輯有點像路由算法,刪去一些邊或者頂點,計算每個子區(qū)域間的最短路徑,這種方法可以有效加快計算速度,示例如下
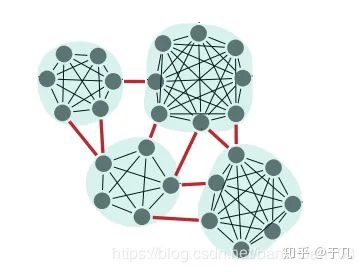
基于分級的技術(shù)利用了道路的層次邏輯,比如道路有國道省道鄉(xiāng)道等,對于路線的查詢,層次結(jié)構(gòu)的重要性應該隨著距離的增長而增加。有界跳躍是一種典型的空間換時間做法,很明顯,計算一對頂點間的所有可能路徑是不切實際的,事先保存若干選定頂點之間的距離和路徑并在導航中使用才是一種合理的做法,對于路徑規(guī)劃的查詢可以利用標簽集線器(hub labeling)[68]來加快查詢速度。當然,這些方法并不互斥,互相組合的方法也很常見。[69]將分割法與有界跳躍法相結(jié)合,提出了Transit Node Routing with Arc Flags(TNR + AF)算法。
局部規(guī)劃
局部規(guī)劃實際可以理解為為了實現(xiàn)全局規(guī)劃來找到一條足夠優(yōu)化且能避開障礙物的軌跡。同樣可以分為四類:基于圖搜索(graph-based planners),基于采樣( sampling-basedplanners),曲線插值( interpolating curve planners)和數(shù)值優(yōu)化( numerical optimization)方法。當然,后續(xù)還有一些基于深度學習的方法。基于圖搜索的方法基本和基于圖的全局規(guī)劃差不多,Dijkstra和A*以及其改進算法依然是最常見的方法。基于圖搜索常見的做法都是將地圖離散成狀態(tài)格,這種做法在高維的情況下會產(chǎn)生指數(shù)爆炸。因此就有了基于采樣的方法,最常見的基于采樣的方法是概率圖(PRM)和快速隨機搜索樹(RRT)。這類方法的缺陷主要是不穩(wěn)定,在某些特定環(huán)境下可能要很長時間才能收斂。曲線插值是在一系列已知點上擬合一條可行的軌跡曲線,常見的曲線有回旋線,多項式曲線,貝塞爾曲線等,這種方法的避障策略一般是插入新的無碰撞的軌跡,如果偏離了初始軌跡,則避開障礙之后再返回初始軌跡。這種方法生成的軌跡較光滑,計算量也比較大,但是在實際ADS中,軌跡光滑一般意味著對乘客比較友好。數(shù)值優(yōu)化一般可以用來改善已有的軌跡,比如[70]利用非線性數(shù)值函數(shù)(numeric non-linear functions )來優(yōu)化A*得到的軌跡,[71]利用牛頓法解決了勢場法(Potential Field Method,PFM)的固有震蕩問題。我之前寫過一篇博客詳細介紹了幾種主流方法的原理,有興趣的可以戳這里。
隨著人工智能的火熱,一些基于深度學習和強化學習方法的規(guī)劃策略也開始涌現(xiàn)出來。[72]利用三維全卷積神經(jīng)網(wǎng)絡(Fully convolutional 3D neural networks)從激光雷達等輸入設備獲取點云并生成未來的軌跡。[73]利用深度強化學習在仿真環(huán)境下實現(xiàn)了交叉路口的安全路徑規(guī)劃。基于深度學習的缺陷前面已經(jīng)提到過了,缺乏硬編碼的安全措施,除此之外還有泛化能力問題,數(shù)據(jù)來源問題等,但總的來說,這一類方法應該是未來的趨勢之一。
人機交互
車輛一般通過人機模塊(HMI)與駕駛員或乘客交互。互動的強度取決于自動化程度,傳統(tǒng)的L0的車需要持續(xù)的用戶操作輸入,而理論上L5級別的車僅需要在行程開始的時候給予一個輸入即可。根據(jù)目的不同大致可以把交互任務分為兩類:首要任務(與駕駛相關(guān))和次要任務,理論上講,次要任務的交互輸入更期望是非視覺選項,因為視覺在駕駛?cè)蝿罩惺遣豢商娲模枰曈X的次要任務界面會影響首要任務,從而影響駕駛的可靠性[72]。一個可替代的方案就是聽覺用戶界面(Auditory User Interfaces ,AUI),聽覺不需要刻意集中注意力于某個界面之上。音頻交互的主要挑戰(zhàn)是自動語音識別(automatic speech recognition, ASR)。ASR算是一個比較成熟的領域,但是在車輛領域還有一些挑戰(zhàn),比如一些不可控的噪聲(駕駛噪聲,風聲,道路噪聲等)。除此之外,如何與ADS實現(xiàn)對話也是一個尚未解決的挑戰(zhàn)。人機交互最大的挑戰(zhàn)應該是出現(xiàn)在L3和L4,這兩個階段需要人和ADS互相理解對方的意圖來實現(xiàn)手動和自動的切換。在監(jiān)控自動駕駛時,駕駛員會表現(xiàn)出較低的主觀認知欲望,盡管可以通過一些基于頭部和眼睛追蹤的攝像機來識別駕駛員的活動,并使用視覺和聽覺來提示駕駛員做好切換準備,但目前主要是在模擬環(huán)境下實現(xiàn)[73],在真實環(huán)境中能夠高效切換的系統(tǒng)目前還未出現(xiàn)。這是一個懸而未決的問題,未來的研究應著重于提供更好的方法來告知駕駛員以簡化過渡過程。
數(shù)據(jù)集和開源工具
數(shù)據(jù)集和標準
數(shù)據(jù)集對于研究人員和開發(fā)人員來說至關(guān)重要,因為大多數(shù)算法和工具在上路之前都必須經(jīng)過測試和訓練。通常的做法是將傳感器數(shù)據(jù)輸入到一系列具有不同目標的算法中,并在標注過的數(shù)據(jù)集上測試和驗證這些算法。有些算法的測試是相互關(guān)聯(lián)的,有些則是單獨的。CV領域已經(jīng)有很多專門用于目標檢測和跟蹤的標注數(shù)據(jù)集,而對于端到端系統(tǒng),還需要額外的車輛信號,主要包括轉(zhuǎn)向和徑向控制信號。
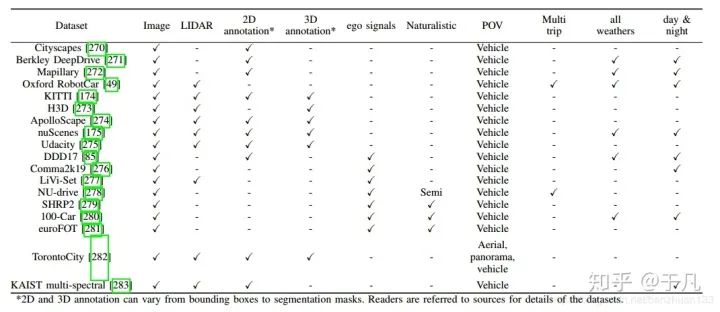
隨著學習方法的出現(xiàn),支持它們的訓練數(shù)據(jù)集也隨之出現(xiàn)。從2005年一直增長到2012年,PASCAL VOC數(shù)據(jù)集是第一個包含大量ADS相關(guān)數(shù)據(jù)的數(shù)據(jù)集之一。但是這些數(shù)據(jù)通常以單個對象為特征,不能代表駕駛場景中遇到的情況。2012年,KITTI Vision Benchmark通過提供大量的標記駕駛場景彌補了這一缺陷,直到現(xiàn)在它仍然是自動駕駛中使用最廣泛的數(shù)據(jù)集之一。當然,從數(shù)量上來說,它遠遠比不上ImageNet和COCO這樣的通用圖像數(shù)據(jù)庫。通用數(shù)據(jù)庫在訓練某一特定模塊是有用的,但是由于缺少前后關(guān)聯(lián)信息(the adequate context),不足以用來測試ADS的能力。加州大學伯克利分校DeepDrive是一個帶有注釋圖像數(shù)據(jù)的最新數(shù)據(jù)集。牛津的RobotCar在英國使用六個攝像頭、激光雷達、GPS和慣性導航系統(tǒng)收集了超過1000公里的駕駛數(shù)據(jù),不過這些數(shù)據(jù)沒有標注。還有一些其他的數(shù)據(jù)集可以見下表
開源框架和模擬器
常見的ADS開源框架包括Autoware、Apollo、Nvidia DriveWorks和openpilot等。常見的模擬器包括CARLA、TORCS、Gazebo 、SUMO等。CARLA可以模仿各種城市場景包括碰撞場景,TORCS是一個賽車仿真模擬器,Gazebo 是一個常見的機器人模擬器,SUMO可以模擬車流量。
總結(jié)
這篇文章概述了在ADS中現(xiàn)有的一些系統(tǒng)及關(guān)鍵的創(chuàng)新。目前來看,自動駕駛在很多方面都存在著明顯的缺陷。無論是模塊化還是端到端系統(tǒng),不同的模型都存在著各自的缺陷。具體到算法,建圖,定位,感知等方面,仍然缺乏準確性和效率,對不理想的路況或者天氣的魯棒性也仍有待提高。V2X仍然處于起步階段,由于所需的基礎設施比較復雜,基于云的集中式信息管理也尚未實現(xiàn)。人機交互的研究還比較少,存在著許多問題。本文也討論了一些可能對自動駕駛產(chǎn)生重要影響的新技術(shù)的研究進展,這些進展可以克服以前的問題或者作為一種替代方法。總的來說,未來可期,但路還很長。
推薦閱讀
