點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)
本文轉(zhuǎn)自|深度學(xué)習(xí)這件小事
斯坦福大學(xué)博士生與 Facebook 人工智能研究所研究工程師 Edward Z. Yang 是 PyTorch 開源項目的核心開發(fā)者之一。他在 PyTorch 紐約聚會上做了一個有關(guān) PyTorch 內(nèi)部機(jī)制的演講,本文是該演講的長文章版本。
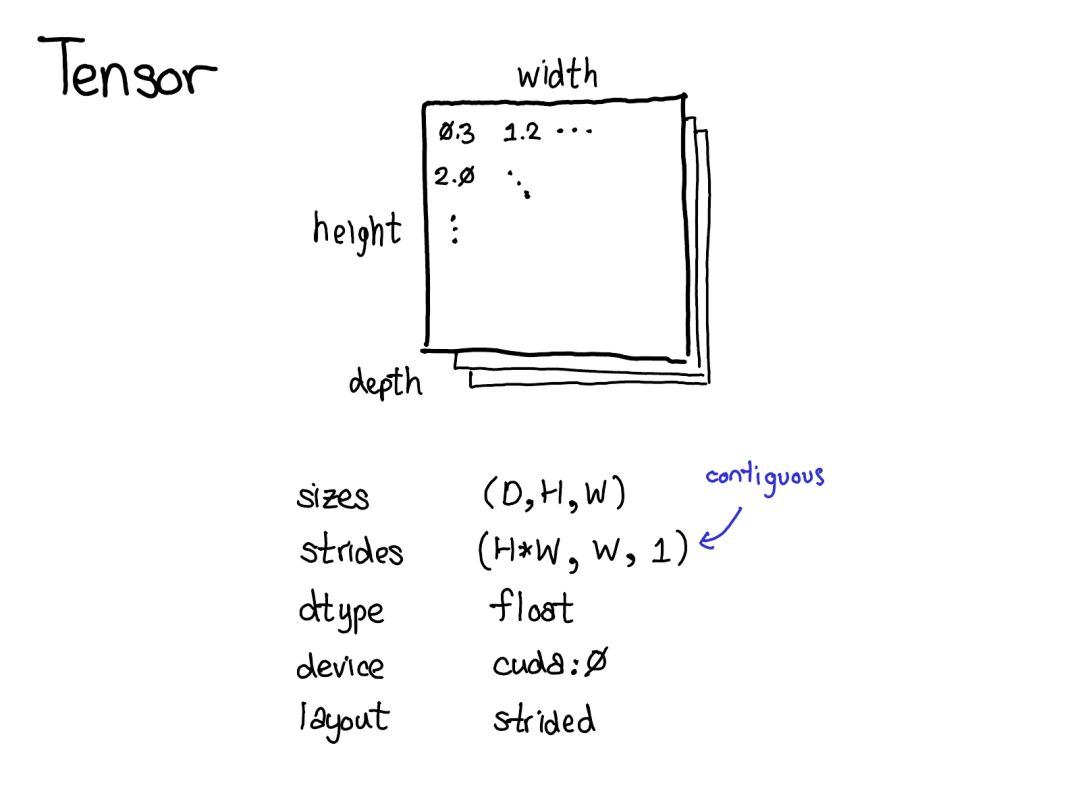
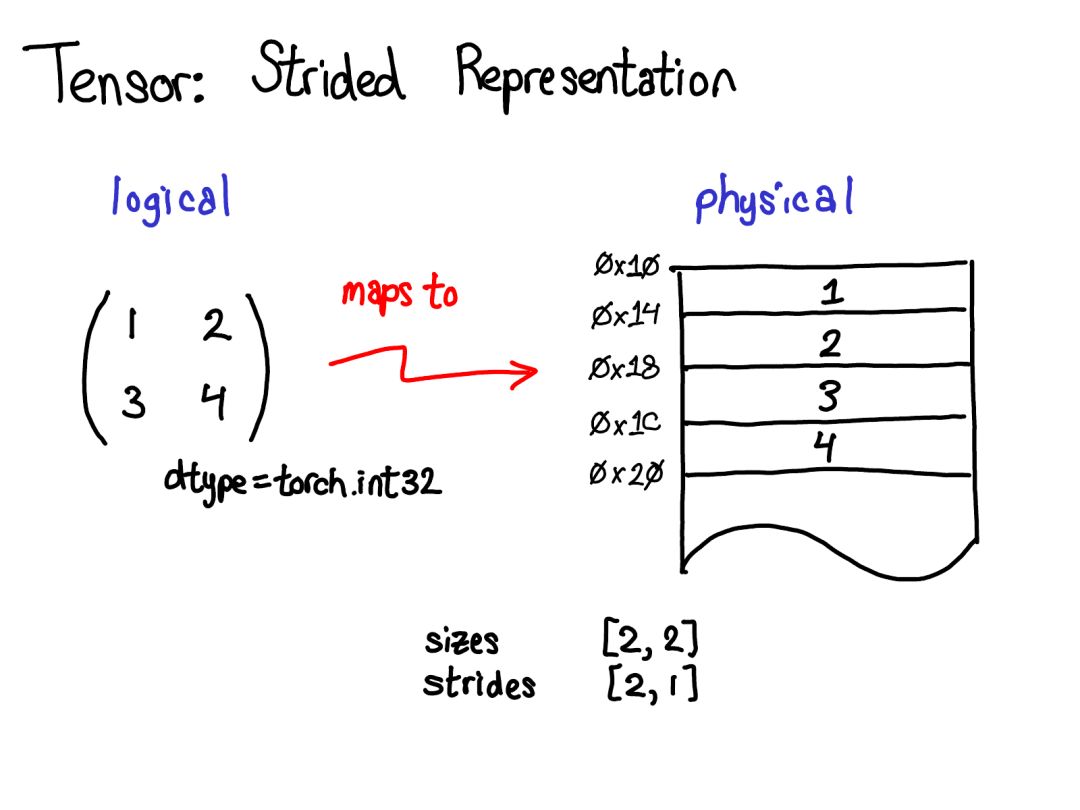
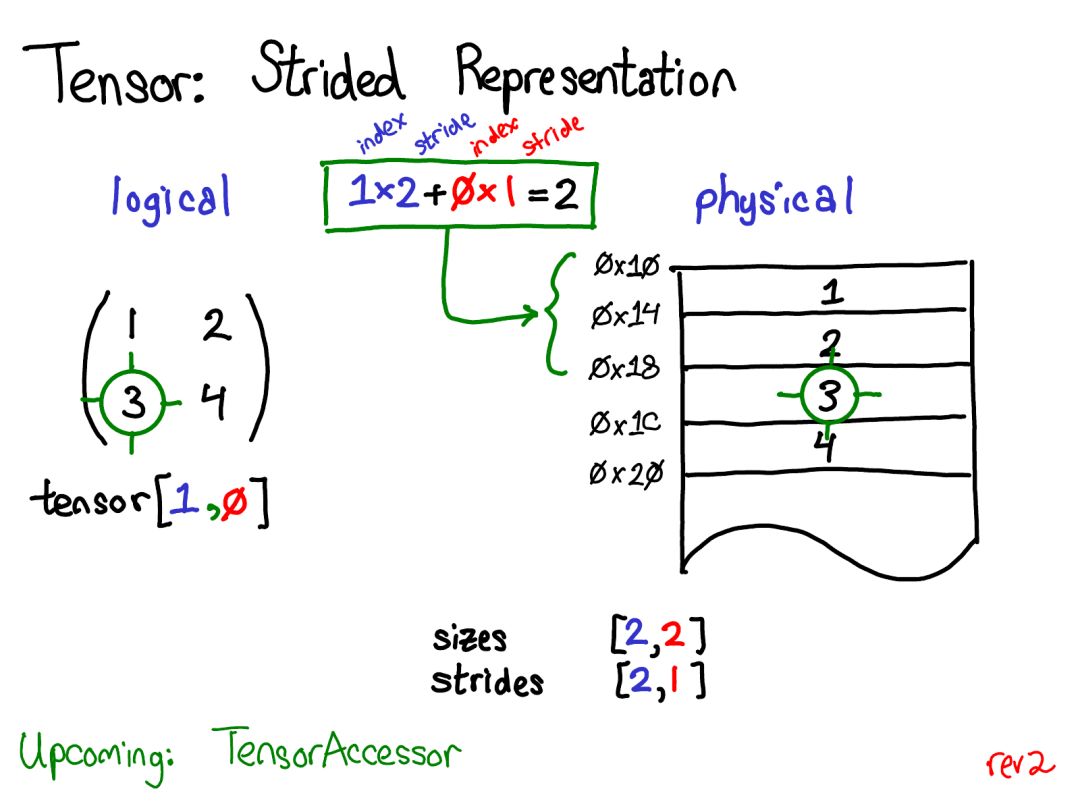
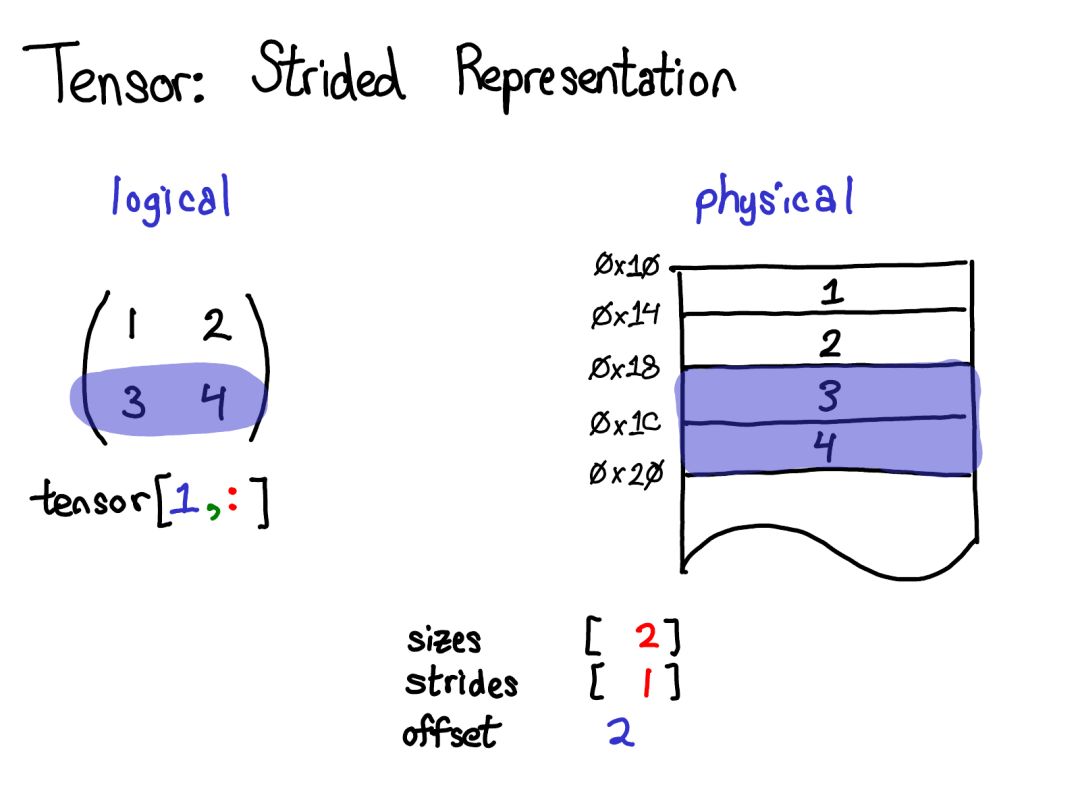
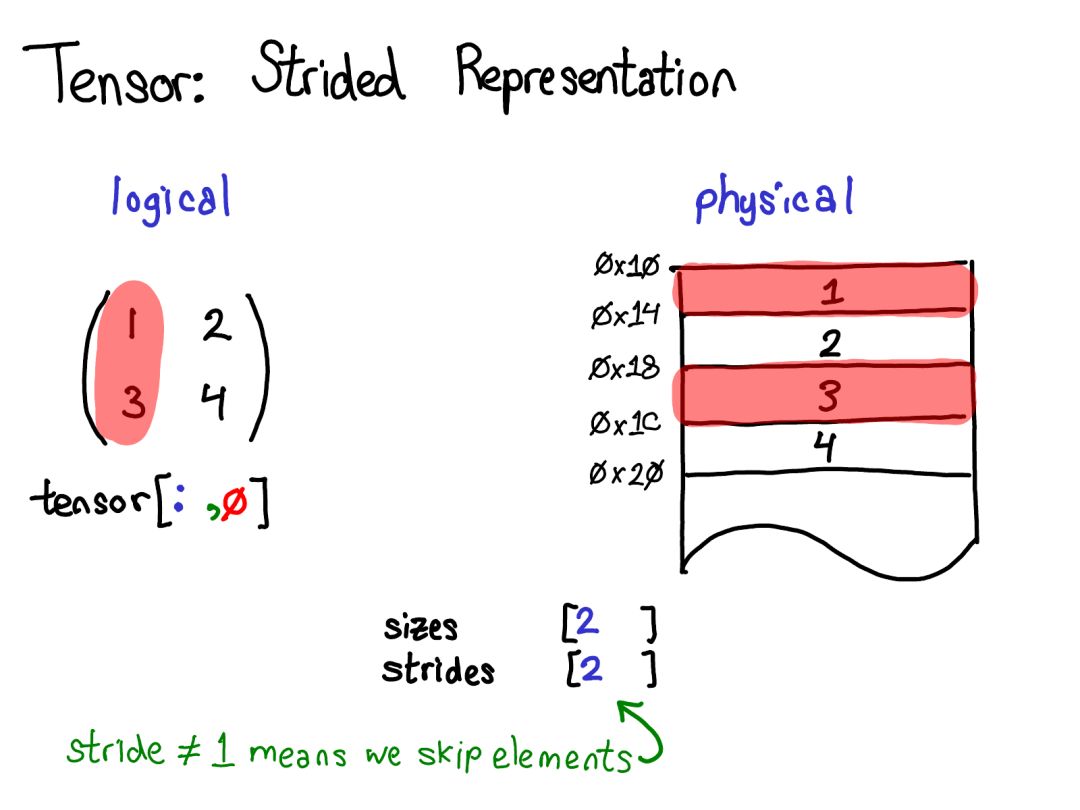
大家好!今天我想談?wù)?PyTorch 的內(nèi)部機(jī)制。這份演講是為用過 PyTorch并且有心為 PyTorch 做貢獻(xiàn)但卻被 PyTorch 那龐大的 C++ 代碼庫勸退的人提供的。沒必要說謊:PyTorch 代碼庫有時候確實讓人難以招架。本演講的目的是為你提供一份導(dǎo)航圖:為你講解一個「支持自動微分的張量庫」的基本概念結(jié)構(gòu),并為你提供一些能幫你在代碼庫中尋路的工具和技巧。我預(yù)設(shè)你之前已經(jīng)寫過一些 PyTorch,但卻可能還沒有深入理解機(jī)器學(xué)習(xí)軟件庫的編寫方式。本演講分為兩部分:在第一部分中,我首先會全面介紹張量庫的各種概念。我首先會談?wù)勀銈冎狼蚁矏鄣?/span>張量數(shù)據(jù)類型,并詳細(xì)討論這種數(shù)據(jù)類型究竟能提供什么,這能讓我們更好地理解其內(nèi)部真正的實現(xiàn)方式。如果你是一位 PyTorch 高級用戶,你可能已經(jīng)熟悉其中大部分材料了。我們也會談到「擴(kuò)展點(extension points)」的三個概念、布局(layout)、設(shè)備(device)和數(shù)據(jù)類型(dtype),這能引導(dǎo)我們思考張量類的擴(kuò)展的方式。在 PyTorch 紐約聚會的現(xiàn)場演講中,我略過了有關(guān)自動梯度(autograd)的幻燈片,但我在這里會進(jìn)行一些講解。第二部分會闡述真正用 PyTorch 寫代碼時所涉及的基本細(xì)節(jié)。我會告訴你如何在 autograd 代碼中披荊斬棘、什么代碼是真正重要的以及怎樣造福他人,我還會介紹 PyTorch 為你寫核(kernel)所提供的所有炫酷工具。張量是 PyTorch 中的核心數(shù)據(jù)結(jié)構(gòu)。對于張量直觀上所表示的東西,你可能已有很好的理解:張量是一種包含某種標(biāo)量類型(比如浮點數(shù)和整型數(shù)等)的 n 維數(shù)據(jù)結(jié)構(gòu)。我們可以將張量看作是由一些數(shù)據(jù)構(gòu)成的,還有一些元數(shù)據(jù)描述了張量的大小、所包含的元素的類型(dtype)、張量所在的設(shè)備(CPU 內(nèi)存?CUDA 內(nèi)存?)另外還有一個你可能沒那么熟悉的元數(shù)據(jù):步幅(stride)。stride 實際上是 PyTorch 最別致的特征之一,所以值得稍微多討論它一些。張量一個數(shù)學(xué)概念。但要在我們的計算機(jī)中表示它,我們必須為它們定義某種物理表示方法。最常用的表示方法是在內(nèi)存中相鄰地放置張量的每個元素(這也是術(shù)語「contiguous(鄰接)」的來源),即將每一行寫出到內(nèi)存,如上所示。在上面的案例中,我已經(jīng)指定該張量包含 32 位的整型數(shù),這樣你可以看到每一個整型數(shù)都位于一個物理地址中,每個地址與相鄰地址相距 4 字節(jié)。為了記住張量的實際維度,我們必須將規(guī)模大小記為額外的元數(shù)據(jù)。假設(shè)我想要讀取我的邏輯表示中位置張量 [0,1] 的元素。我該如何將這個邏輯位置轉(zhuǎn)譯為物理內(nèi)存中的位置?步幅能讓我們做到這一點:要找到一個張量中任意元素的位置,我將每個索引與該維度下各自的步幅相乘,然后將它們?nèi)考拥揭黄稹T谏蠄D中,我用藍(lán)色表示第一個維度,用紅色表示第二個維度,以便你了解該步幅計算中的索引和步幅。進(jìn)行這個求和后,我得到了 2(零索引的);實際上,數(shù)字 3 正是位于這個鄰接數(shù)組的起點以下 2 個位置。(后面我還會談到 TensorAccessor,這是一個處理索引計算的便利類(convenience class)。當(dāng)你使用 TensorAccessor 時,不會再操作原始指針,這些計算過程已經(jīng)為你隱藏了起來。)步幅是我們?yōu)?PyTorch 用戶講解方法的基本基礎(chǔ)。舉個例子,假設(shè)我想取出一個表示以上張量的第二行的張量:使用高級的索引支持,我只需寫出張量 [1, :] 就能得到這一行。重要的是:當(dāng)我這樣做時,不會創(chuàng)建一個新張量;而是會返回一個基于底層數(shù)據(jù)的不同域段(view)的張量。這意味著,如果我編輯該視角下的這些數(shù)據(jù),它就會反映在原始的張量中。在這種情況下,了解如何做到這一點并不算太困難:3 和 4 位于鄰接的內(nèi)存中,我們只需要記錄一個說明該(邏輯)張量的數(shù)據(jù)位于頂部以下 2 個位置的偏移量(offset)。(每個張量都記錄一個偏移量,但大多數(shù)時候它為零,出現(xiàn)這種情況時我會在我的圖表中省略它。)演講時的提問:如果我取張量的一個域段,我該如何釋放底層張量的內(nèi)存?答案:你必須制作該域段的一個副本,由此斷開其與原始物理內(nèi)存的連接。你能做的其它事情實際上并不多。另外,如果你很久之前寫過 Java,取一個字符串的子字符串也有類似的問題,因為默認(rèn)不會制作副本,所以子字符串會保留(可能非常大的字符串)。很顯然,Java 7u6 將其固定了下來。
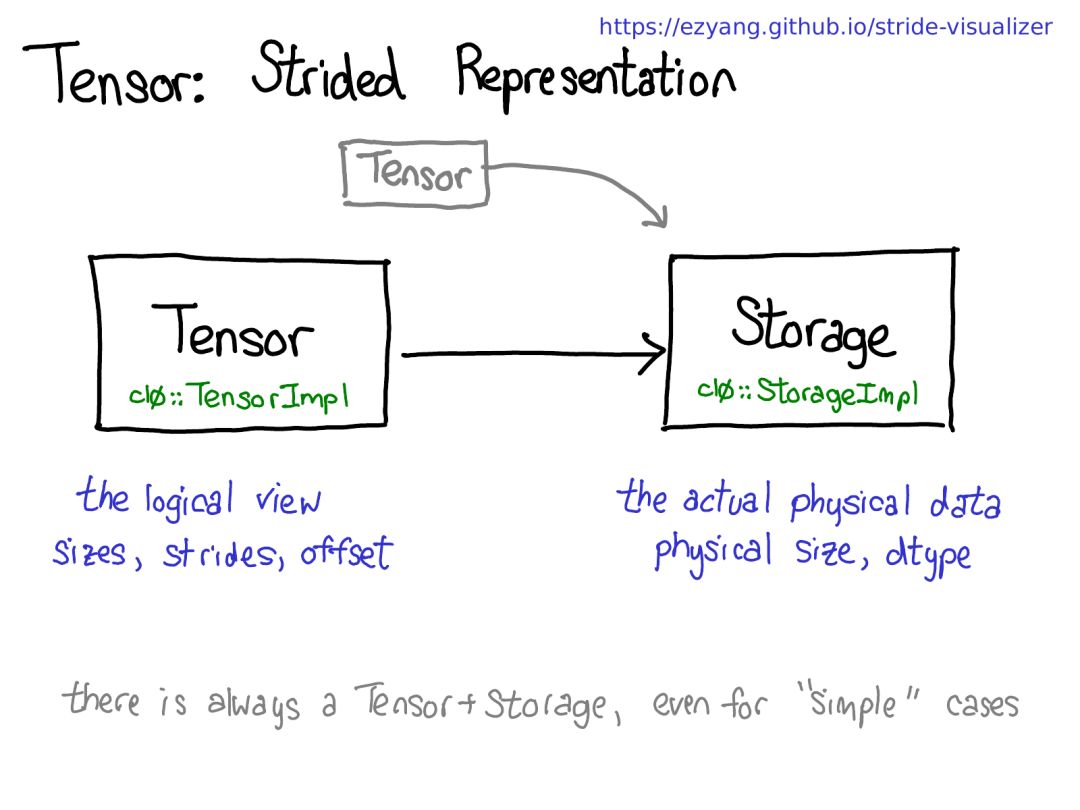
當(dāng)我們查看物理內(nèi)存時,可以看到該列的元素不是相鄰的:兩者之間有一個元素的間隙。步幅在這里就大顯神威了:我們不再將一個元素與下一個元素之間的步幅指定為 1,而是將其設(shè)定為 2,即跳兩步。(順便一提,這就是其被稱為「步幅(stride)」的原因:如果我們將索引看作是在布局上行走,步幅就指定了我們每次邁步時向前多少位置。)步幅表示實際上可以讓你表示所有類型的張量域段;如果你想了解各種不同的可能做法,請參閱 https://ezyang.github.io/stride-visualizer/index.html我們現(xiàn)在退一步看看,想想我們究竟如何實現(xiàn)這種功能(畢竟這是一個關(guān)于內(nèi)部機(jī)制的演講)。如果我們可以得到張量的域段,這就意味著我們必須解耦張量的概念(你所知道且喜愛的面向用戶的概念)以及存儲張量的數(shù)據(jù)的實際物理數(shù)據(jù)的概念(稱為「存儲(storage)」):也許會有多個張量共享同一存儲。存儲會定義張量的 dtype 和物理大小,同時每個張量還會記錄大小、步幅和偏移量,這定義的是物理內(nèi)存的邏輯解釋。有一點需要注意:總是會存在一個張量-存儲對,即使并不真正需要存儲的「簡單」情況也是如此(比如,只是用 torch.zeros(2, 2) 劃配一個鄰接張量時)。順便一提,我們感興趣的不是這種情況,而是有一個分立的存儲概念的情況,只是將一個域段定義為有一個基張量支持的張量。這會更加復(fù)雜一些,但也有好處:鄰接張量可以實現(xiàn)遠(yuǎn)遠(yuǎn)更加直接的表示,而沒有存儲造成的間接麻煩。這樣的變化能讓 PyTorch 的內(nèi)部表示方式更接近 Numpy。
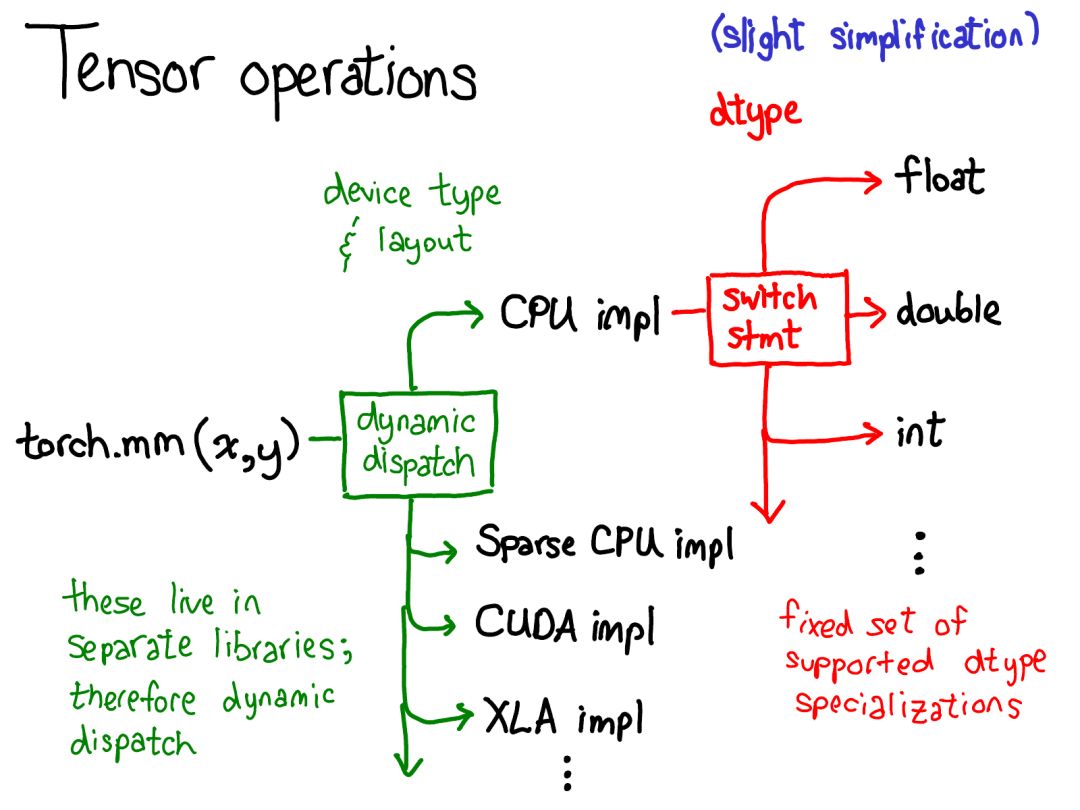
我們已經(jīng)介紹了一些張量的數(shù)據(jù)布局(有人可能會說,如果你正確地理解了數(shù)據(jù)表示,其它一切都會自然到位)。但還是有必要簡要談?wù)勅绾螌崿F(xiàn)對張量的操作。在最抽象的層面上,當(dāng)你調(diào)用 torch.mm 時,會發(fā)生兩次調(diào)度:
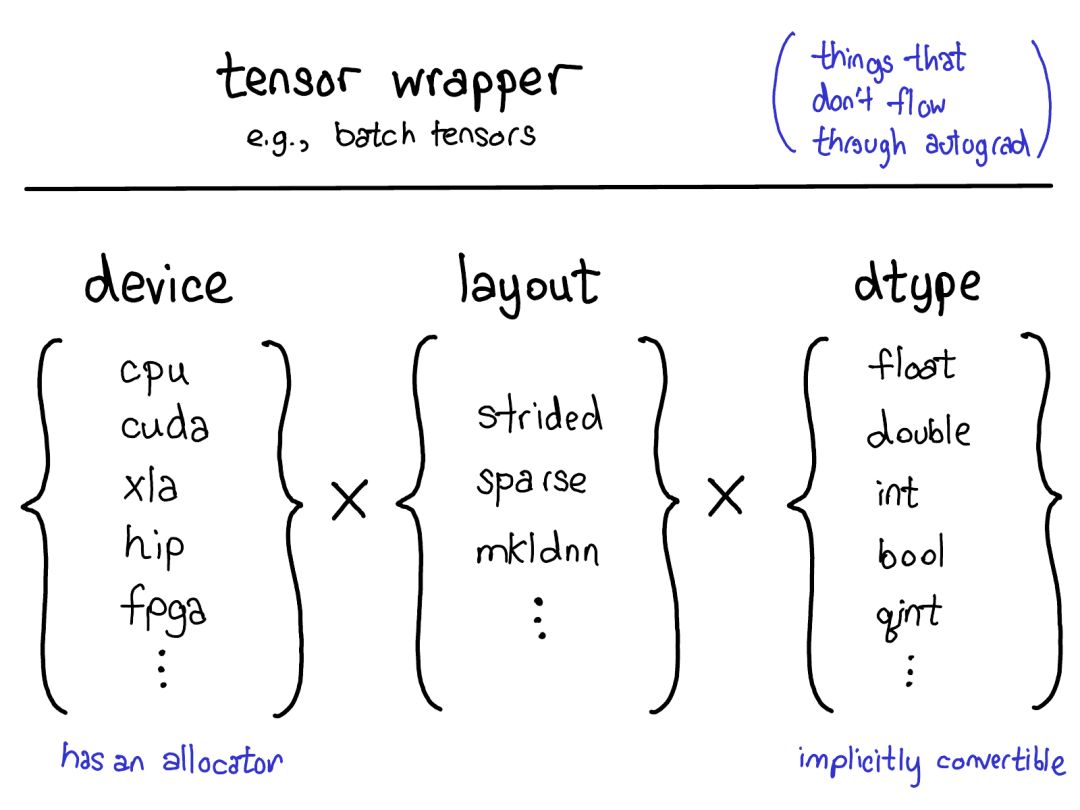
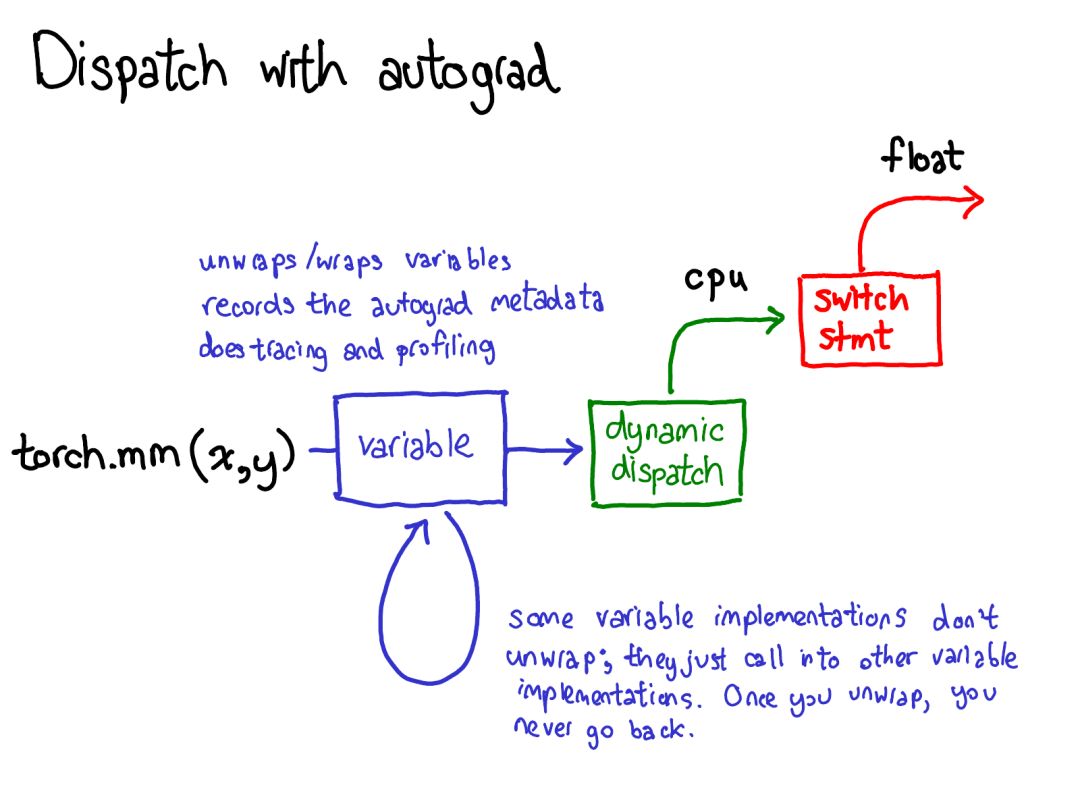
第一次調(diào)度基于設(shè)備類型和張量布局:比如是 CPU 張量還是 CUDA張量,是有步幅的張量還是稀疏的張量。這個調(diào)度是動態(tài)的:這是一個虛函數(shù)(virtual function)調(diào)用(這個虛函數(shù)調(diào)用究竟發(fā)生在何處是本演講后半部分的主題)。這里需要做一次調(diào)度應(yīng)該是合理的:CPU 矩陣乘法的實現(xiàn)非常不同于 CUDA 的實現(xiàn)。這里是動態(tài)調(diào)度的原因是這些核(kernel)可能位于不同的庫(比如 libcaffe2.so 或 libcaffe2_gpu.so),這樣你就別無選擇:如果你想進(jìn)入一個你沒有直接依賴的庫,你必須通過動態(tài)調(diào)度抵達(dá)那里。第二次調(diào)度是在所涉 dtype 上的調(diào)度。這個調(diào)度只是一個簡單的 switch 語句,針對的是核選擇支持的任意 dtype。這里需要調(diào)度的原因也很合理:CPU 代碼(或 CUDA 代碼)是基于 float 實現(xiàn)乘法,這不同于用于 int 的代碼。這說明你需要為每種 dtype 都使用不同的核。如果你想要理解 PyTorch 中算子的調(diào)用方式,這可能就是你頭腦中應(yīng)有的最重要的知識。后面當(dāng)我們更深入代碼時還會回到這里。因為我們已經(jīng)談過了張量,所以我還想花點時間談?wù)剰埩繑U(kuò)展。畢竟,除了密集的 CPU 浮點數(shù)張量,還有其它很多類型的張量,比如 XLA 張量、量化張量、MKL-DNN 張量;而對于一個張量庫,還有一件需要思考的事情:如何兼顧這些擴(kuò)展?我們當(dāng)前的用于擴(kuò)展的模型提供了張量的四個擴(kuò)展點。首先,有三個獨(dú)立地確定張量類型的配套參數(shù):device(設(shè)備):描述了實際存儲張量的物理內(nèi)存,比如在 CPU、英偉達(dá) GPU(cuda)、AMD GPU(hip)或 TPU(xla)上。設(shè)備之間各不相同的特性是有各自自己的分配器(allocator),這沒法用于其它設(shè)備。
layout(布局):描述了對物理內(nèi)存進(jìn)行邏輯解讀的方式。最常用的布局是有步幅的張量(strided tensor),但稀疏張量的布局不同,其涉及到一對張量,一個用于索引,一個用于數(shù)據(jù);MKL-DNN 張量的布局更加奇特,比如 blocked layout,僅用步幅不能表示它。
dtype(數(shù)據(jù)類型):描述了張量中每個元素實際存儲的數(shù)據(jù)的類型,比如可以是浮點數(shù)、整型數(shù)或量化的整型數(shù)。
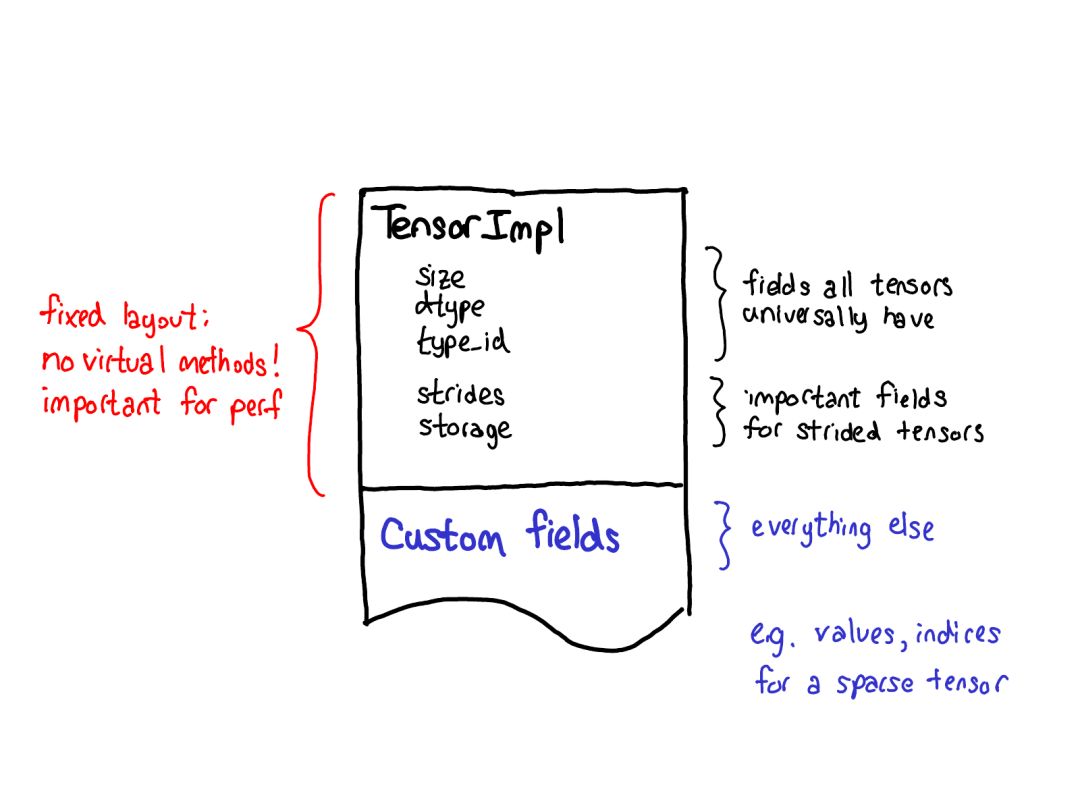
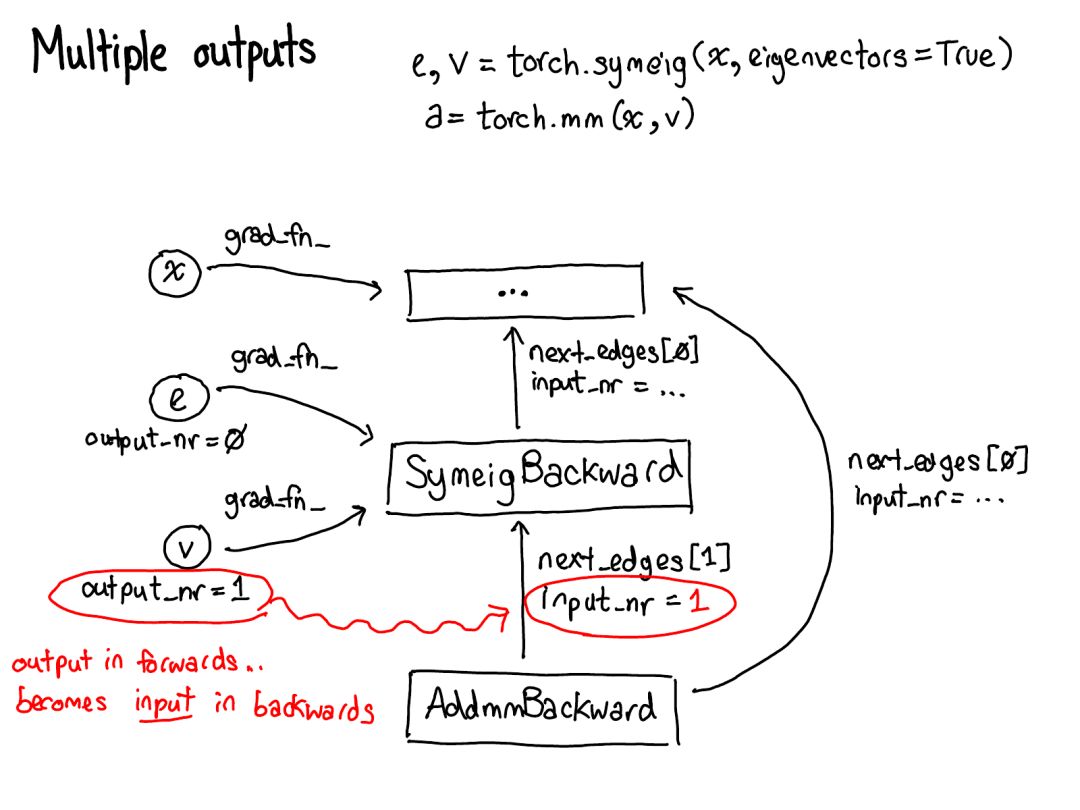
如果你想為 PyTorch 張量添加一種擴(kuò)展,你應(yīng)該思考你想要擴(kuò)展這些參數(shù)中的哪幾種。這些參數(shù)的笛卡爾積定義了你可以得到的所有可能的張量。現(xiàn)在,并非所有這些組合都有核(誰為 FPGA 上的稀疏量化張量用核?),但原則上這種組合可能有意義,因此我們至少應(yīng)該支持表達(dá)它。要為張量的功能添加「擴(kuò)展」,還有最后一種方法,即圍繞能實現(xiàn)的目標(biāo)類型的 PyTorch 張量編寫一個 wrapper(包裝)類。這可能聽起來理所當(dāng)然,但有時候人們在只需要制作一個 wrapper 類時卻跑去擴(kuò)展那三個參數(shù)。wrapper 類的一個突出優(yōu)點是開發(fā)結(jié)果可以完全不影響原來的類型(out of tree)。你何時應(yīng)該編寫張量 wrapper,而不是擴(kuò)展 PyTorch 本身?關(guān)鍵的指標(biāo)是你是否需要將這個張量傳遞通過 autograd(自動梯度)反向通過過程。舉個例子,這個指標(biāo)告訴我們稀疏張量應(yīng)該是一種真正的張量擴(kuò)展,而不只是一種包含一個索引和值張量的 Python 對象:當(dāng)在涉及嵌入的網(wǎng)絡(luò)上執(zhí)行優(yōu)化時,我們想要嵌入生成稀疏的梯度。我們對擴(kuò)展的理念也會影響張量本身的數(shù)據(jù)布局。對于我們的張量結(jié)構(gòu),我們真正想要的一件事物是固定的布局:我們不想要基本操作(這個說法很常見),比如「一個張量的大小是多少?」來請求虛調(diào)度。所以當(dāng)你查看一個張量的實際布局時(定義為 TensorImpl 結(jié)構(gòu)),會看到所有字段的一個公共前綴——我們認(rèn)為所有類似「張量」的東西都會有;還有一些字段僅真正適用于有步幅的張量,但它們也很重要,所以我們將其保留在主結(jié)構(gòu)中;然后可以在每個張量的基礎(chǔ)上完成有自定義字段的后綴。比如稀疏張量可將其索引和值存儲在這個后綴中。我已經(jīng)說明了張量,但如果 PyTorch 僅有這點把戲,這就只不過是 Numpy 的克隆罷了。PyTorch 的顯著特性是其在最初發(fā)布時就已提供對張量的自動微分(現(xiàn)在我們還有 TorchScript 等炫酷功能,但那時候就只有這個!)自動微分是做啥?這是負(fù)責(zé)運(yùn)行神經(jīng)網(wǎng)絡(luò)的機(jī)制:……以及填充實際計算你的網(wǎng)絡(luò)的梯度時所缺少的代碼:
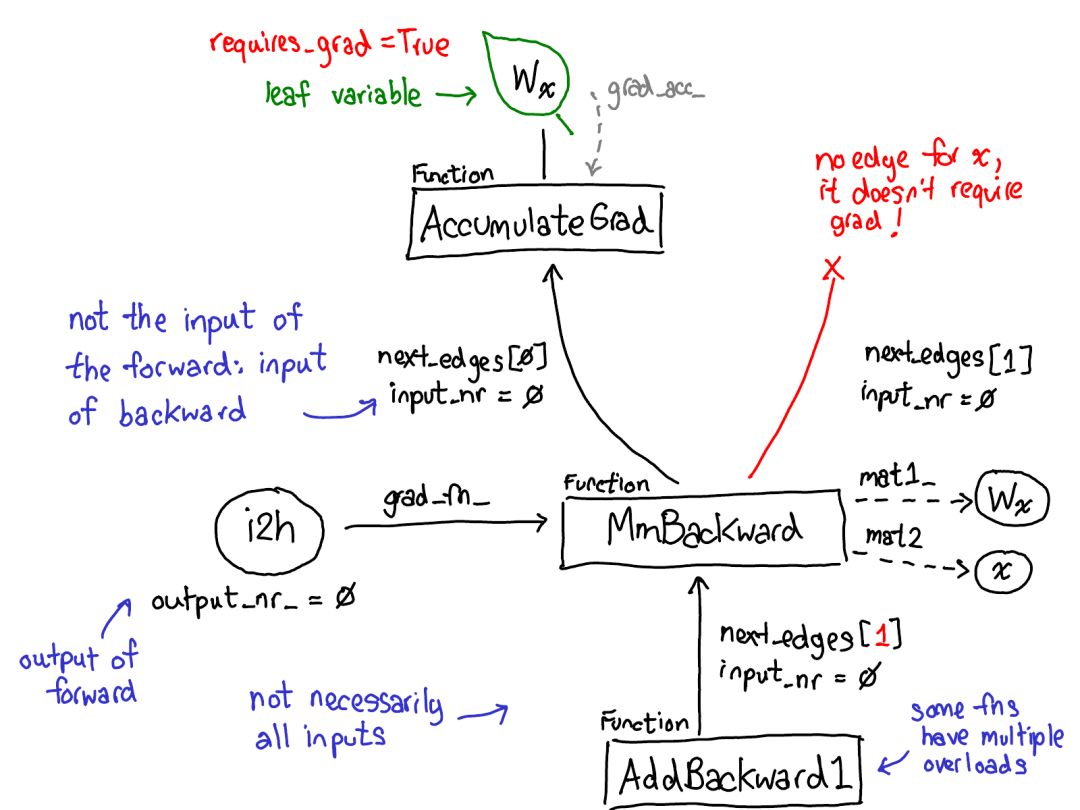
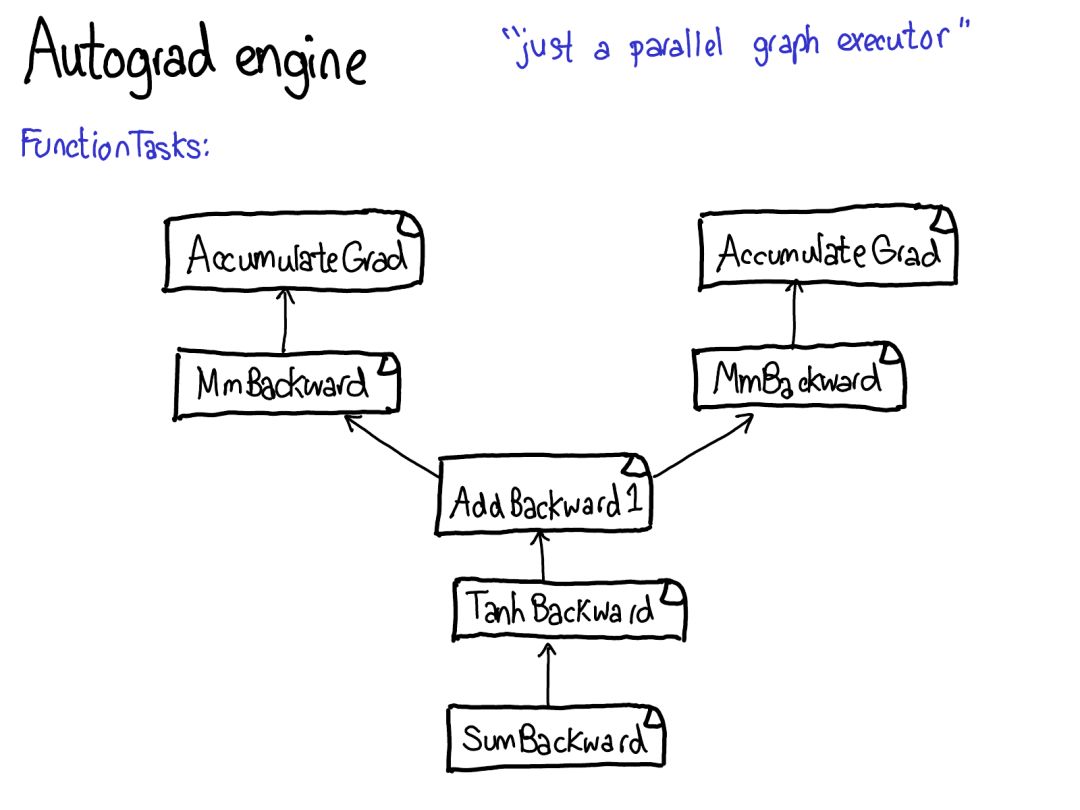
花點時間看看這幅圖。其中有很多東西需要解讀,我們來看看:首先將你的目光投向紅色和藍(lán)色的變量。PyTorch 實現(xiàn)了反向模式自動微分,這意味著我們可以「反向」走過前向計算來有效地計算梯度。查看變量名就能看到這一點:在紅色部分的底部,我們計算的是損失(loss);然后在這個程序的藍(lán)色部分,我們所做的第一件事是計算 grad_loss。loss 根據(jù) next_h2 計算,這樣我們可以計算出 grad_next_h2。從技術(shù)上講,我們加了 grad_ 的變量其實并不是梯度,它們實際上左乘了一個向量的雅可比矩陣,但在 PyTorch 中,我們就稱之為 grad,基本上所有人都知道這是什么意思。
如果代碼的結(jié)構(gòu)保持一樣,而行為沒有保持一樣:來自前向的每一行都被替換為一個不同的計算,其代表了前向運(yùn)算的導(dǎo)數(shù)。舉個例子,tanh 運(yùn)算被轉(zhuǎn)譯成了 tanh_backward 運(yùn)算(這兩行用圖左邊一條灰線連接)。前向和反向運(yùn)算的輸入和輸出交換:如果前向運(yùn)算得到 next_h2,反向運(yùn)算就以 grad_next_h2 為輸入。
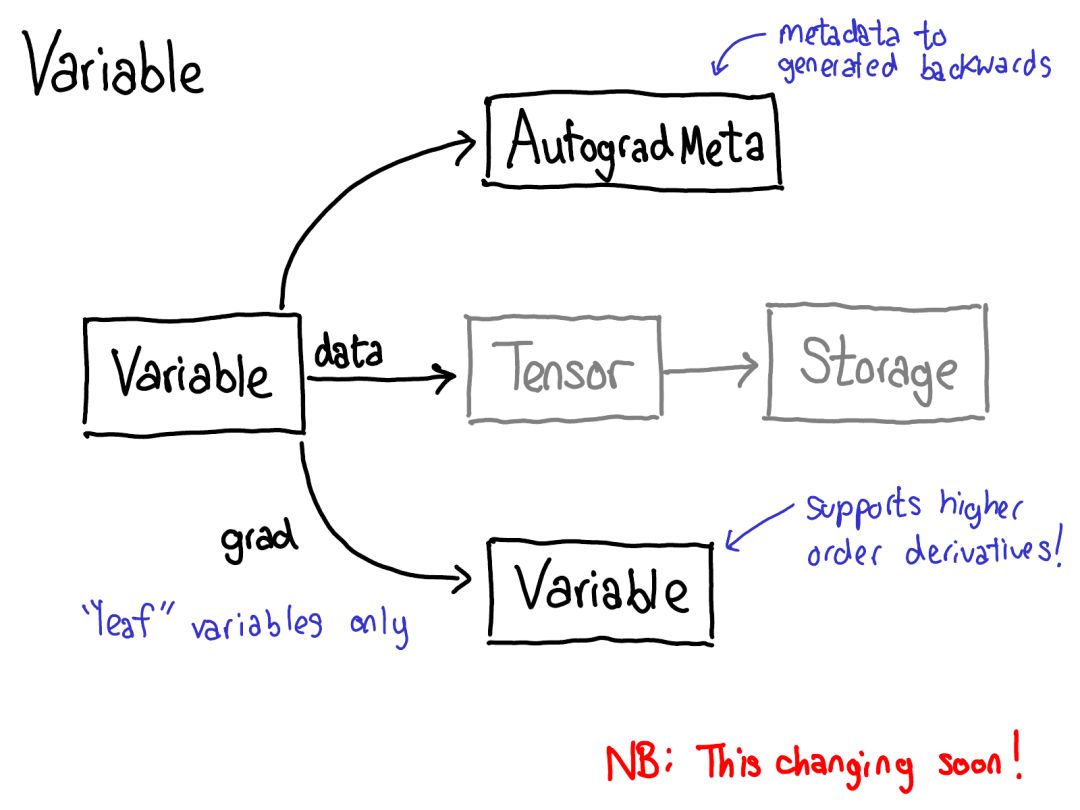
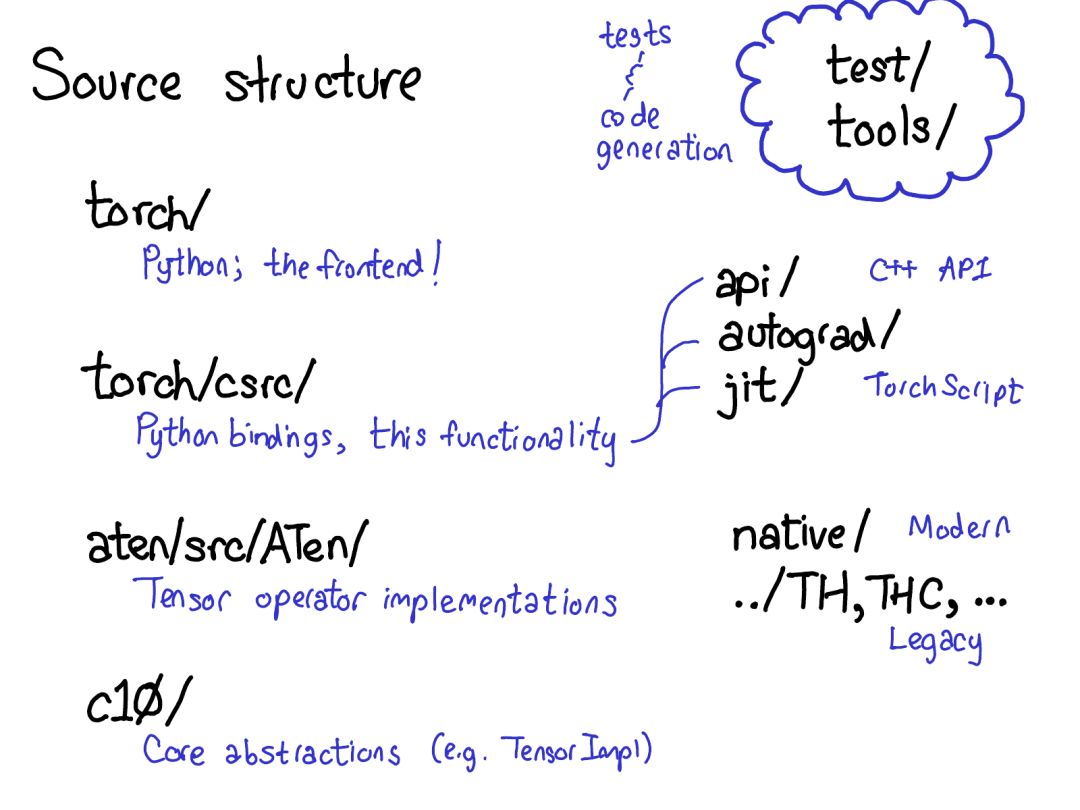
autograd 的意義就在于執(zhí)行這幅圖所描述的計算,但卻不用真正生成這個源。PyTorch autograd 并不執(zhí)行源到源的變換(盡管 PyTorch JIT 確實知道如何執(zhí)行符號微分(symbolic differentiation))。要做到這一點,我們需要在張量上執(zhí)行運(yùn)算時存儲更多元數(shù)據(jù)。讓我們調(diào)整一下我們對張量數(shù)據(jù)結(jié)構(gòu)的圖:現(xiàn)在不只是一個指向存儲的張量,我們還有一個包裝這個張量的變量,而且也存儲更多信息(AutogradMeta),這是用戶在自己的 PyTorch 腳本中調(diào)用 loss.backward() 執(zhí)行 autograd 時所需的。這張幻燈片的內(nèi)容在不久的將來就會過時。Will Feng 在簡單融合了 PyTorch 的前端端口之后,正在推動 C++ 中變量和張量的融合:https://github.com/pytorch/pytorch/issues/13638。我們也必須更新上面關(guān)于調(diào)度的圖:在我們調(diào)度到 CPU 或 CUDA 實現(xiàn)之前,還有另一個對變量的調(diào)度,其負(fù)責(zé)打開(unwrap)變量,調(diào)用底層實現(xiàn)(綠色),然后再重新將結(jié)果包裝進(jìn)變量并為反向過程記錄必需的 autograd 元數(shù)據(jù)。某些實現(xiàn)不會 unwrap;它們只是調(diào)用其它變量實現(xiàn)。所以你可能要在變量宇宙中花些時間。但是,一旦你 unwrap 并進(jìn)入了非變量張量宇宙,你就到達(dá)終點了;你再也不用退回變量(除非從你的函數(shù)返回)。在我的紐約聚會演講中,我跳過了以下七頁幻燈片。對它們的文本介紹還要等一段時間。PyTorch 有大量文件夾,在 CONTRIBUTING.md 文檔中有對它們的非常詳細(xì)的描述,但實際上你只需知曉 4 個目錄:首先,torch/ 包含你最熟悉的東西:你導(dǎo)入和使用的實際的 Python 模塊。這些東西是 Python 代碼而且易于操作(只需要進(jìn)行修改然后查看結(jié)果即可)。但是,如果太過深入……
torch/csrc/:實現(xiàn)了你可能稱為 PyTorch 前端的 C++ 代碼。用更描述性的術(shù)語講,它實現(xiàn)了在 Python 和 C++ 間轉(zhuǎn)換的綁定代碼(binding code);另外還有一些相當(dāng)重要的 PyTorch 部分,比如 autograd 引擎和 JIT 編譯器。它也包含 C++ 前端代碼。
aten/:這是「A Tensor Library」的縮寫(由 Zachary DeVito 命名),是一個實現(xiàn)張量運(yùn)算的 C++ 庫。如果你檢查某些核代碼所處的位置,很可能就在 ATen。ATen 本身就分為兩個算子區(qū)域:「原生」算子(算子的現(xiàn)代的 C++ 實現(xiàn))和「傳統(tǒng)」算子(TH、THC、THNN、THCUNN),這些是遺留的 C 實現(xiàn)。傳統(tǒng)的算子是其中糟糕的部分;如果可以,請勿在上面耗費(fèi)太多時間。
c10/:這是「Caffe2」和「A"Ten"」的雙關(guān)語,包含 PyTorch 的核心抽象,包括張量和存儲數(shù)據(jù)結(jié)構(gòu)的實際實現(xiàn)。
找代碼需要看很多地方;我們應(yīng)該簡化目錄結(jié)構(gòu),就是這樣。如果你想研究算子,你應(yīng)該在 aten 上花時間。當(dāng)你調(diào)用一個函數(shù)時,比如 torch.add,會發(fā)生什么?如果你記得我們的有關(guān)調(diào)度的討論,你腦中應(yīng)該已有了這些基礎(chǔ):我們必須從 Python 國度轉(zhuǎn)換到 C++ 國度(Python 參數(shù)解析)。
我們處理變量調(diào)度(VariableType—Type,順便一提,和編程語言類型并無特別關(guān)聯(lián),只是一個用于執(zhí)行調(diào)度的小工具)。
我們處理設(shè)備類型/布局調(diào)度(Type)。
我們有實際的核,這要么是一個現(xiàn)代的原生函數(shù),要么是傳統(tǒng)的 TH 函數(shù)。
其中每一步都具體對應(yīng)于一些代碼。讓我們開路穿過這片叢林。我們在 C++ 代碼中的起始著陸點是一個 Python 函數(shù)的 C 實現(xiàn),我們已經(jīng)在 Python 那邊見過它,像是 torch._C.VariableFunctions.add。THPVariable_add 就是這樣一個實現(xiàn)。對于這些代碼,有一點很重要:這些代碼是自動生成的。如果你在 GitHub 庫中搜索,你沒法找到它們,因為你必須實際 build PyTorch 才能看到它們。另外一點也很重要:你不需要真正深入理解這些代碼是在做什么,你應(yīng)該快速瀏覽它,知道它的功能。我在上面用藍(lán)色標(biāo)注了最重要的部分:你可以看到這里使用了一個 PythonArgParser 類來從 Python args 和 kwargs 取出 C++ 對象;然后我們調(diào)用一個 dispatch_add 函數(shù)(紅色內(nèi)聯(lián));這會釋放全局解釋器鎖,然后調(diào)用在 C++ 張量自身上的一個普通的舊方法。在其回來的路上,我們將返回的 Tensor 重新包裝進(jìn) PyObject。(這里幻燈片中有個錯誤:我應(yīng)該講解變量調(diào)度代碼。我這里還沒有修復(fù)。某些神奇的事發(fā)生了,于是……)當(dāng)我們在 Tensor 類上調(diào)用 add 方法時,還沒有虛調(diào)度發(fā)生。相反,我有一個內(nèi)聯(lián)方法,其調(diào)用了一個內(nèi)聯(lián)方法,其會在「Type」對象上調(diào)用一個虛方法。這個方法是真正的虛方法(這就是我說 Type 只是一個讓你實現(xiàn)動態(tài)調(diào)度的「小工具」的原因)。在這個特定案例中,這個虛調(diào)用會調(diào)度到在一個名為 TypeDefault 的類上的 add 的實現(xiàn)。這剛好是因為我們有一個對所有設(shè)備類型(CPU 和 CUDA)都一樣的 add 的實現(xiàn);如果我們剛好有不同的實現(xiàn),我們可能最終會得到 CPUFloatType::add 這樣的結(jié)果。正是這種虛方法的實現(xiàn)能讓我們最終得到實際的核代碼。也希望這張幻燈片很快過時;Roy Li 正在研究使用另一種機(jī)制替代 Type 調(diào)度,這能讓我們更好地在移動端上支持 PyTorch。值得再次強(qiáng)調(diào),一直到我們到達(dá)核,所有這些代碼都是自動生成的。道路蜿蜒曲折,一旦你能基本上把握方向了,我建議你直接跳到核部分。PyTorch 為有望編寫核的人提供了大量有用工具。在這一節(jié)我們會了解其中一些。但首先,編寫核需要什么?我們一般將 PyTorch 中的核看作由以下部分組成:首先有一些我們要寫的有關(guān)核的元數(shù)據(jù),這能助力代碼生成并讓你獲取所有與 Python 的捆綁包,同時無需寫任何一行代碼。
一旦你到達(dá)了核,你就經(jīng)過了設(shè)備類型/布局調(diào)度。你首先需要寫的是錯誤檢查,以確保輸入的張量有正確的維度。(錯誤檢查真正很重要!不要吝惜它!)
接下來,我們一般必須分配我們將要寫入輸出的結(jié)果張量。
該到寫核的時候了。現(xiàn)在你應(yīng)該做第二次 dtype 調(diào)度,以跳至其所操作的每個 dtype 特定的核。(你不應(yīng)該過早做這件事,因為那樣的話你就會毫無用處地復(fù)制在任何情況下看起來都一樣的代碼。)
大多數(shù)高性能核都需要某種形式的并行化,這樣就能利用多 CPU 系統(tǒng)了。(CUDA 核是「隱式」并行化的,因為它們的編程模型構(gòu)建于大規(guī)模并行化之上。)
最后,你需要讀取數(shù)據(jù)并執(zhí)行你想做的計算!
在后面的幻燈片中,我將介紹 PyTorch 中能幫你實現(xiàn)這些步驟的工具。要充分利用 PyTorch 的代碼生成能力,你需要為你的算子寫一個模式(schema)。這個模式能提供你的函數(shù)的 mypy 風(fēng)格類型,并控制是否為 Tensor 上的方法或函數(shù)生成捆綁包。你還可以告訴模式針對給定的設(shè)備-布局組合,應(yīng)該調(diào)用你的算子的哪種實現(xiàn)。有關(guān)這種格式的更多信息,請參閱:https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/README.md你可能也需要為你在 derivatives.yaml 中的操作定義一個導(dǎo)數(shù)。錯誤檢查可以在低層 API 完成,也能通過高層 API 實現(xiàn)。低層 API 只是一個宏 TORCH_CHECK,其接收的是一個布爾值,然后還有任意數(shù)量的參數(shù)構(gòu)成錯誤字符串(error string)以便得出結(jié)論看該布爾值是否為真。這個宏有個很好的地方:你可以將字符串與非字符串?dāng)?shù)據(jù)混合起來;每一項都使用它們的 operator<< 實現(xiàn)進(jìn)行格式化,PyTorch 中大多數(shù)重要的數(shù)據(jù)類型都有 operator<< 實現(xiàn)。高層 API 能讓你免于反復(fù)編寫重復(fù)的錯誤消息。其工作方法是;你首先將每個張量包裝為 TensorArg,這包含有關(guān)張量來處的信息(比如其參數(shù)名稱)。然后它提供了一些預(yù)先裝好的用于檢查多種屬性的函數(shù);比如 checkDim() 測試的是張量的維度是否是一個固定數(shù)值。如果不是,該函數(shù)就基于 TensorArg 元數(shù)據(jù)提供一個用戶友好的錯誤消息。在用 PyTorch 寫算子時,有一點很重要:你往往要注冊三個算子:abs_out(其操作的是一個預(yù)分配的輸出,其實現(xiàn)了 out= keyword 參數(shù))、abs_(其操作的是 inplace)、abs(這只是一個算子的普通的舊功能版本)。大部分時間,abs_out 是真正的主力,abs 和 abs_ 只是圍繞 abs_out 的薄弱 wrapper;但有時候也可為每個案例編寫專門的實現(xiàn)。要執(zhí)行 dtype 調(diào)度,你應(yīng)該使用 AT_DISPATCH_ALL_TYPES 宏。這會獲取你想要進(jìn)行調(diào)度操作的張量的 dtype,并還會為可從該宏調(diào)度的每個 dtype 指定一個 lambda。通常而言,這個 lambda 只是調(diào)用一個模板輔助函數(shù)。
這個宏不只是「執(zhí)行調(diào)度」,它也會決定你的核將支持的 dtype。這樣,這個宏實際上就有相當(dāng)多一些版本,這能讓你選取不同的 dtype 子集以生成特定結(jié)果。大多數(shù)時候,你只需要 AT_DISPATCH_ALL_TYPES,但也要關(guān)注你可能需要調(diào)度其它更多類型的情況。在 CPU 上,你通常需要并行化你的代碼。過去,這通常是通過直接在你的代碼中添加 OpenMP pragma 來實現(xiàn)。某些時候,你必須真正訪問數(shù)據(jù)。PyTorch 為此提供了相當(dāng)多一些選擇。如果你只想獲取某個特定位置的值,你應(yīng)該使用 TensorAccessor。張量存取器就像是一個張量,但它將張量的維度和 dtype 硬編碼為了模板參數(shù)。當(dāng)你檢索一個存取器時,比如 x.accessor
();,我們會做一次運(yùn)行時間測試以確保張量確實是這種格式;但那之后,每次存取都不會被檢查。張量存取器能正確地處理步幅,因此你最好使用它們,而不是原始的指針訪問(不幸的是,很多傳統(tǒng)的核是這樣做的)。另外還有 PackedTensorAccessor,這特別適用于通過 CUDA launch 發(fā)送存取器,這樣你就能從你的 CUDA 核內(nèi)部獲取存取器。(一個值得一提的問題:TensorAccessor 默認(rèn)是 64 位索引,這比 CUDA 中的 32 位索引要慢得多!)
如果你在用很常規(guī)的元素存取編寫某種算子,比如逐點運(yùn)算,那么使用遠(yuǎn)遠(yuǎn)更高級的抽象要好得多,比如 TensorIterator。這個輔助類能為你自動處理廣播和類型提升(type promotion),相當(dāng)好用。
要在 CPU 上獲得真正的速度,你可能需要使用向量化的 CPU 指令編寫你的核。我們也有用于這方面的輔助函數(shù)!Vec256 類表示一種標(biāo)量向量,并提供了一些能在它們上一次性執(zhí)行向量化運(yùn)算的方法。然后 binary_kernel_vec 等輔助函數(shù)能讓你輕松地運(yùn)行向量化運(yùn)算,然后結(jié)束那些沒法用普通的舊指令很好地轉(zhuǎn)換成向量指令的東西。這里的基礎(chǔ)設(shè)施還能在不同指令集下多次編譯你的核,然后在運(yùn)行時間測試你的 CPU 支持什么指令,再在這些情況中使用最佳的核。
PyTorch 中大量核都仍然是用傳統(tǒng)的 TH 風(fēng)格編寫的。(順便一提,TH 代表 TorcH。這是個很好的縮寫詞,但很不幸被污染了;如果你看到名稱中有 TH,可認(rèn)為它是傳統(tǒng)的。)傳統(tǒng) TH 風(fēng)格是什么意思呢?它是以 C 風(fēng)格書寫的,沒有(或很少)使用 C++。
其 refcounted 是人工的(使用了對 THTensor_free 的人工調(diào)用以降低你使用張量結(jié)束時的 refcounts)。
其位于 generic/ 目錄,這意味著我們實際上要編譯這個文件很多次,但要使用不同的 #define scalar_t
這種代碼相當(dāng)瘋狂,而且我們討厭回顧它,所以請不要添加它。如果你想寫代碼但對核編寫了解不多,你能做的一件有用的事情:將某些 TH 函數(shù)移植到 ATen。最后我想談?wù)勗?PyTorch 上的工作效率。如果 PyTorch 那龐大的 C++ 代碼庫是阻攔人們?yōu)?PyTorch 做貢獻(xiàn)的第一只攔路虎,那么你的工作流程的效率就是第二只。如果你想用 Python 習(xí)慣開發(fā) C++,那可能會很艱辛:重新編譯 PyTorch 需要大量時間,你也需要大量時間才能知道你的修改是否有效。如何高效工作本身可能就值得做一場演講,但這頁幻燈片總結(jié)了一些我曾見過某些人抱怨的最常見的反模式:「開發(fā) PyTorch 很困難。」如果你編輯一個 header,尤其是被許多源文件包含的 header(尤其當(dāng)被 CUDA 文件包含時),可以預(yù)見會有很長的重新 build 時間。盡量只編輯 cpp 文件,編輯 header 要審慎!
我們的 CI 是一種非常好的零設(shè)置的測試修改是否有效的方法。但在獲得返回信號之前你可能需要等上一兩個小時。如果你在進(jìn)行一種將需要大量實驗的改變,那就花點時間設(shè)置一個本地開發(fā)環(huán)境。類似地,如果你在特定的 CI 配置上遇到了困難的 debug 問題,就在本地設(shè)置它。你可以將 Docker 鏡像下載到本地并運(yùn)行:https://github.com/pytorch/ossci-job-dsl
貢獻(xiàn)指南解釋了如何設(shè)置 ccache:https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md#use-ccache ;強(qiáng)烈建議這個,因為這可以讓你在編輯 header 時幸運(yùn)地避免大量重新編譯。當(dāng)我們在不應(yīng)該重新編譯文件時重新編譯時,這也能幫你覆蓋我們的 build 系統(tǒng)的漏洞。
最后,我們會有大量 C++ 代碼。如果你是在一臺有 CPU 和 RAM 的強(qiáng)大服務(wù)器上 build,那么會有很愉快的體驗。特別要說明,我不建議在筆記本電腦上執(zhí)行 CUDA build。build CUDA 非常非常慢,而筆記本電腦往往性能不足,不足以快速完成。
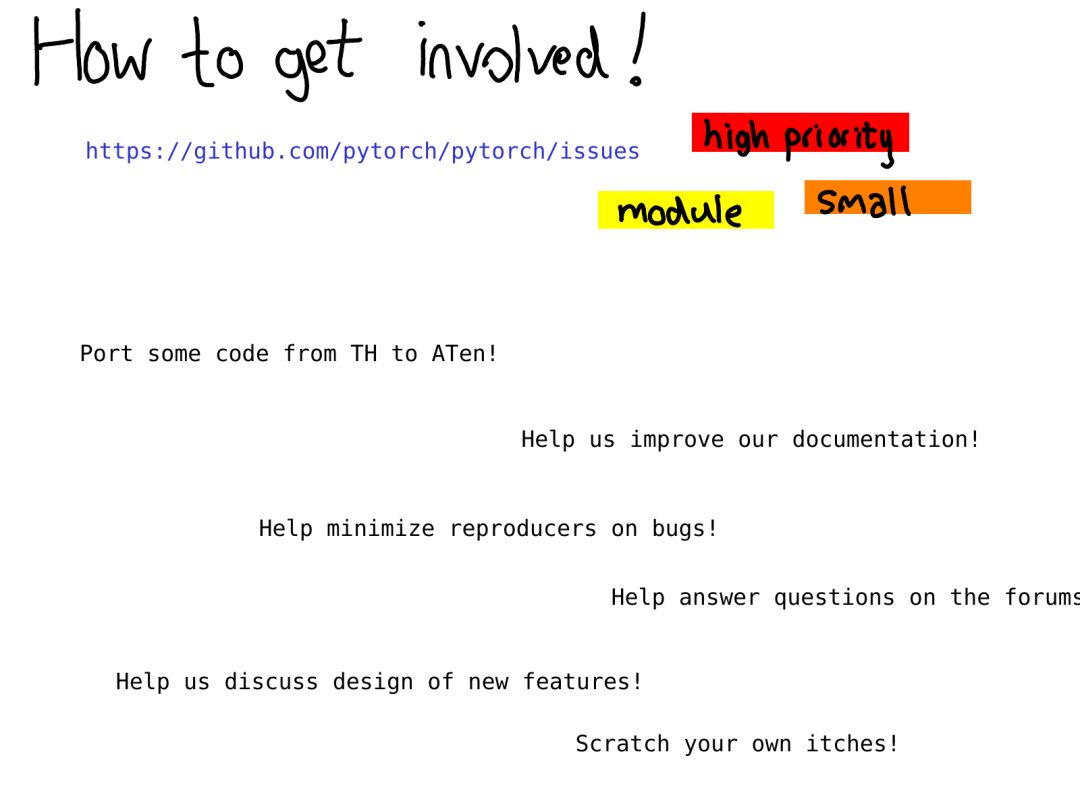
這就是我們旋風(fēng)一般的 PyTorch 內(nèi)核之旅了!其中省略了很多很多東西;但希望這里的描述和解釋至少能幫你消化其代碼庫中相當(dāng)大一部分。接下來該做什么?你能做出怎樣的貢獻(xiàn)?我們的問題跟蹤器是個開始的好地方:https://github.com/pytorch/pytorch/issues。從今年開始,我們一直在分類鑒別問題;標(biāo)注有「triaged」的問題表示至少有一個 PyTorch 開發(fā)者研究過它并對該問題進(jìn)行了初步評估。你可以使用這些標(biāo)簽找到我們認(rèn)為哪些問題是高優(yōu)先級的或查看針對特定模塊(如 autograd)的問題,也能找到我們認(rèn)為是小問題的問題。(警告:我們有時是錯的!)即使你并不想馬上就開始寫代碼,也仍有很多其它有用的工作值得去做,比如改善文檔(我很喜歡合并文檔 PR,它們都很贊)、幫助我們重現(xiàn)來自其他用戶的 bug 報告以及幫助我們討論問題跟蹤器上的 RFC。沒有我們的開源貢獻(xiàn)者,PyTorch 不會走到今天;我們希望你也能加入我們!原文地址:http://blog.ezyang.com/2019/05/pytorch-internals/
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程
在「小白學(xué)視覺」公眾號后臺回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。下載2:Python視覺實戰(zhàn)項目52講在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學(xué)校計算機(jī)視覺。在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~