全面解讀PyTorch內(nèi)部機(jī)制
點(diǎn)擊上方“人工智能與算法學(xué)習(xí)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
本文轉(zhuǎn)自 深度學(xué)習(xí)這件小事
斯坦福大學(xué)博士生與 Facebook 人工智能研究所研究工程師 Edward Z. Yang 是 PyTorch 開源項(xiàng)目的核心開發(fā)者之一。他在 PyTorch 紐約聚會(huì)上做了一個(gè)有關(guān) PyTorch 內(nèi)部機(jī)制的演講,本文是該演講的長(zhǎng)文章版本。

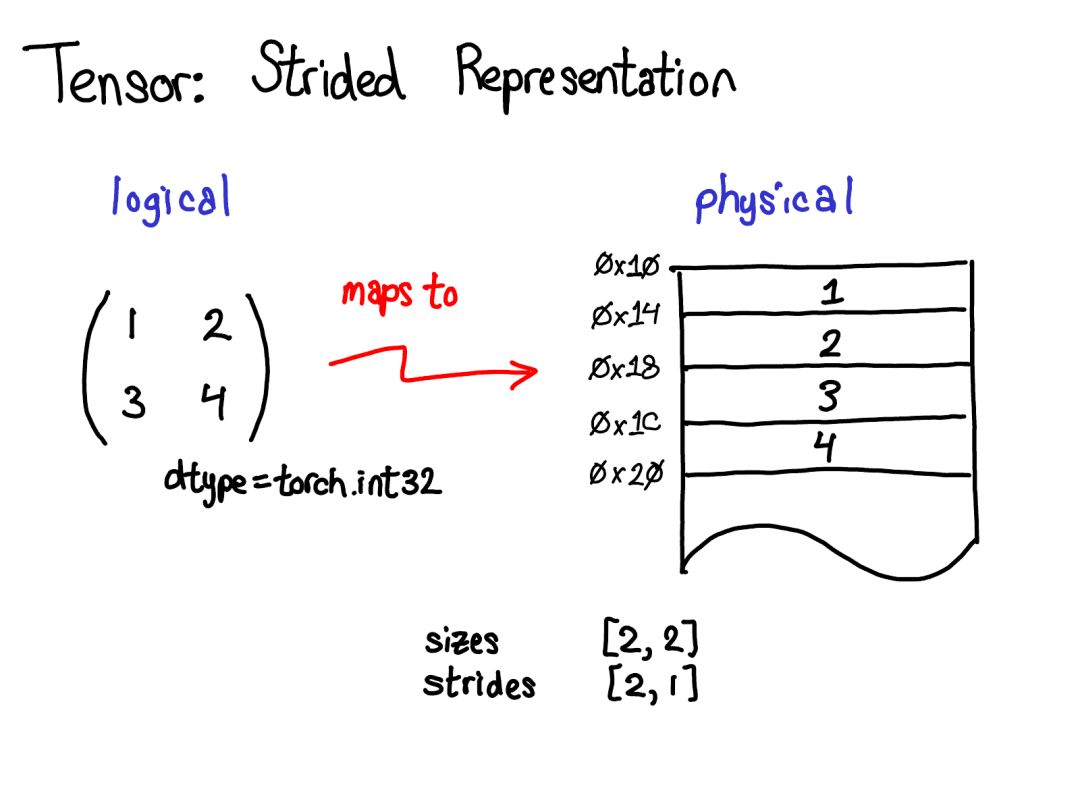
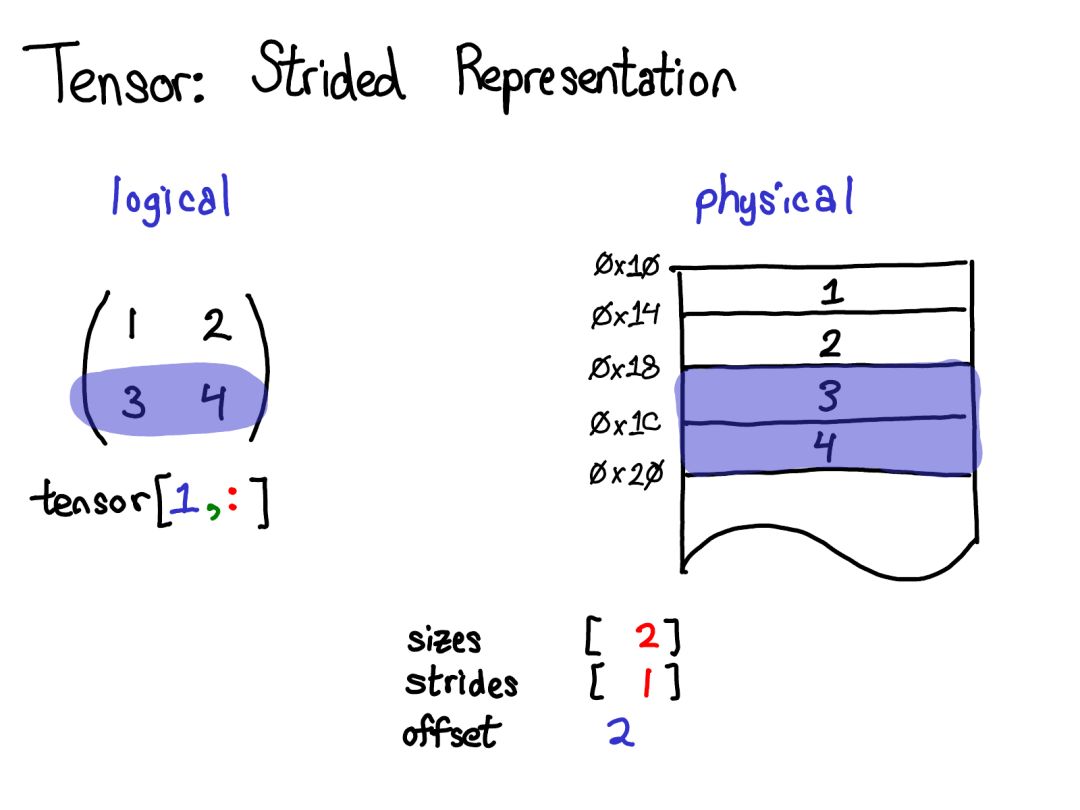
演講時(shí)的提問:如果我取張量的一個(gè)域段,我該如何釋放底層張量的內(nèi)存? 答案:你必須制作該域段的一個(gè)副本,由此斷開其與原始物理內(nèi)存的連接。你能做的其它事情實(shí)際上并不多。另外,如果你很久之前寫過 Java,取一個(gè)字符串的子字符串也有類似的問題,因?yàn)槟J(rèn)不會(huì)制作副本,所以子字符串會(huì)保留(可能非常大的字符串)。很顯然,Java 7u6 將其固定了下來。
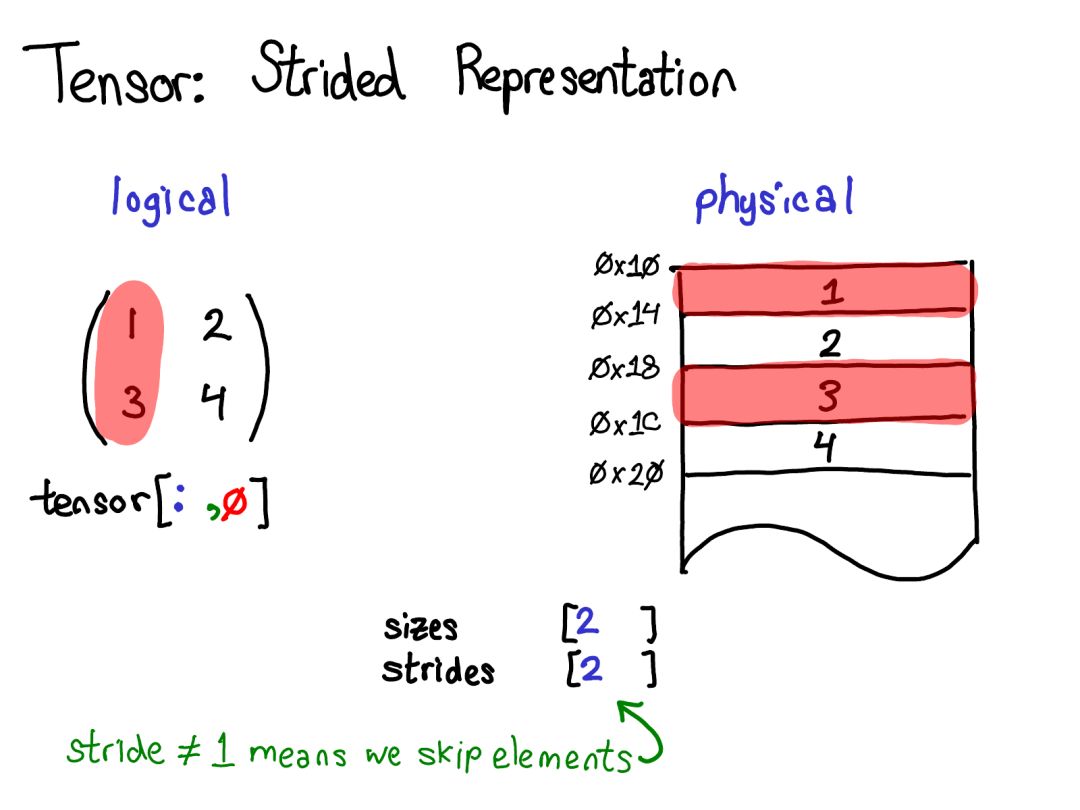
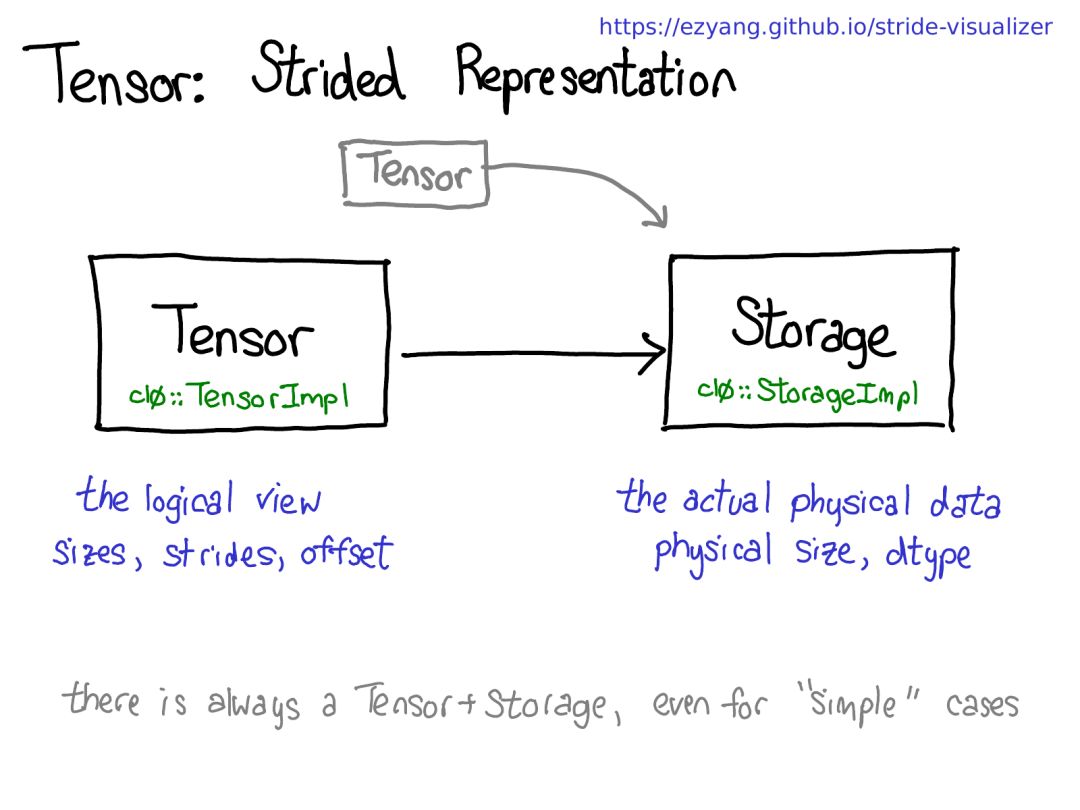
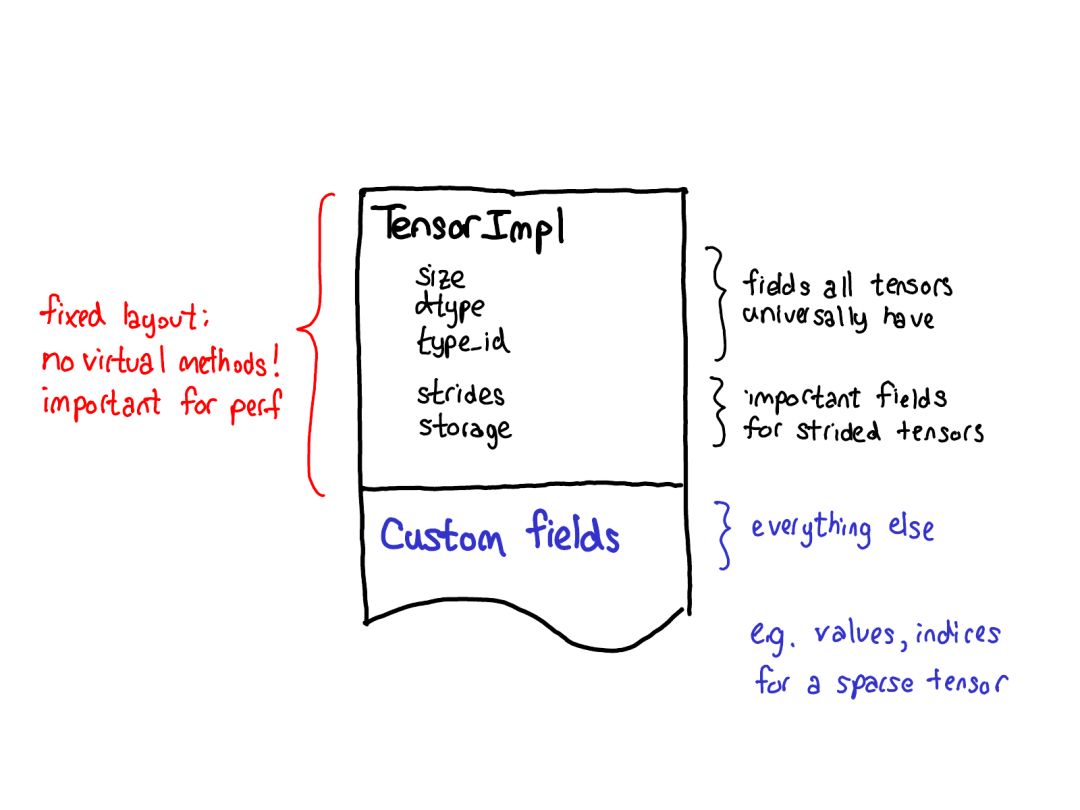
順便一提,我們感興趣的不是這種情況,而是有一個(gè)分立的存儲(chǔ)概念的情況,只是將一個(gè)域段定義為有一個(gè)基張量支持的張量。這會(huì)更加復(fù)雜一些,但也有好處:鄰接張量可以實(shí)現(xiàn)遠(yuǎn)遠(yuǎn)更加直接的表示,而沒有存儲(chǔ)造成的間接麻煩。這樣的變化能讓 PyTorch 的內(nèi)部表示方式更接近 Numpy。
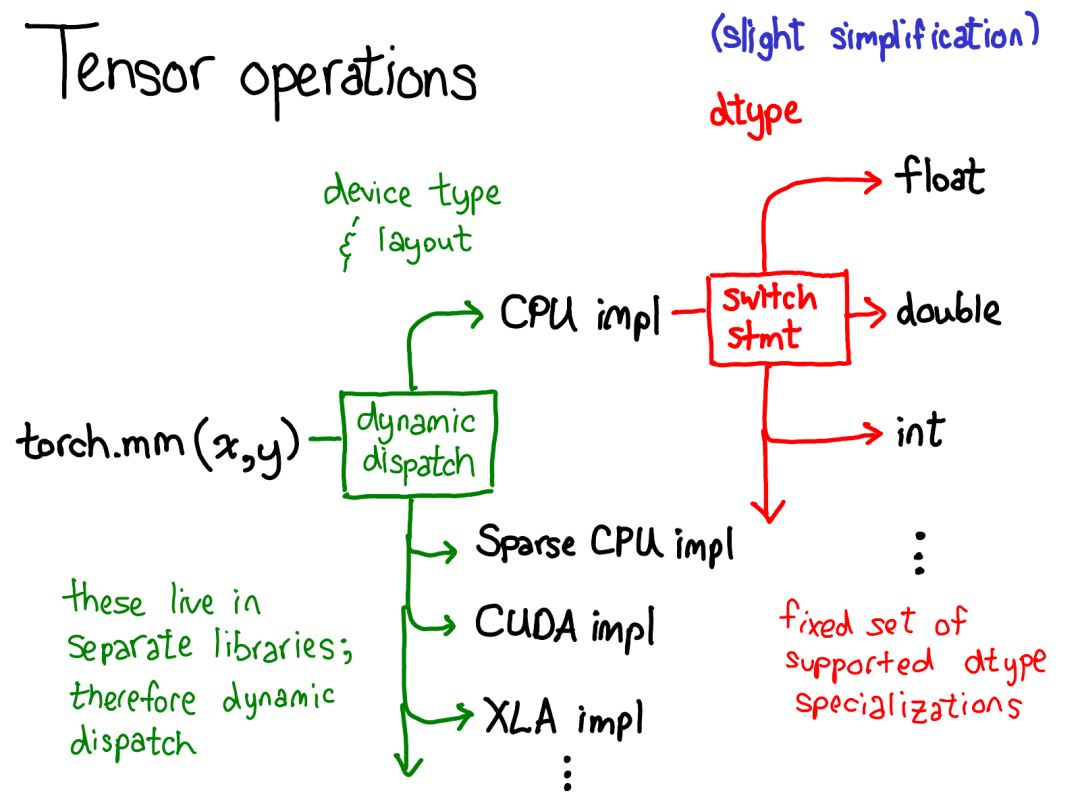

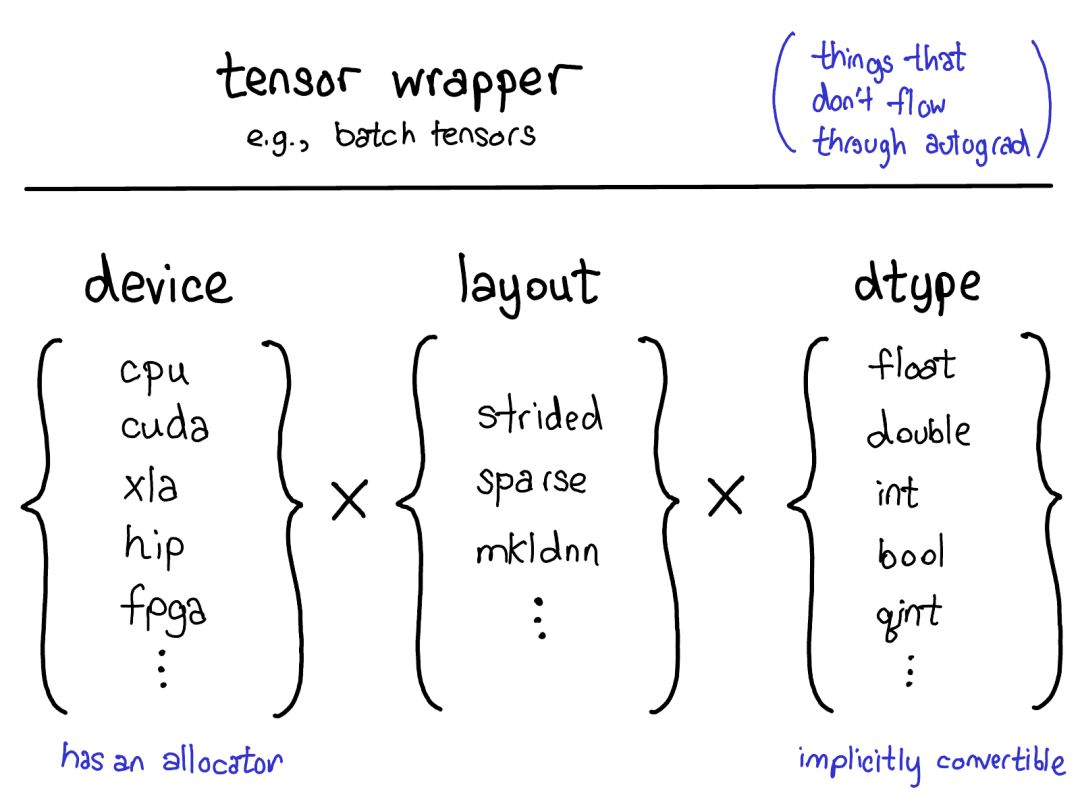
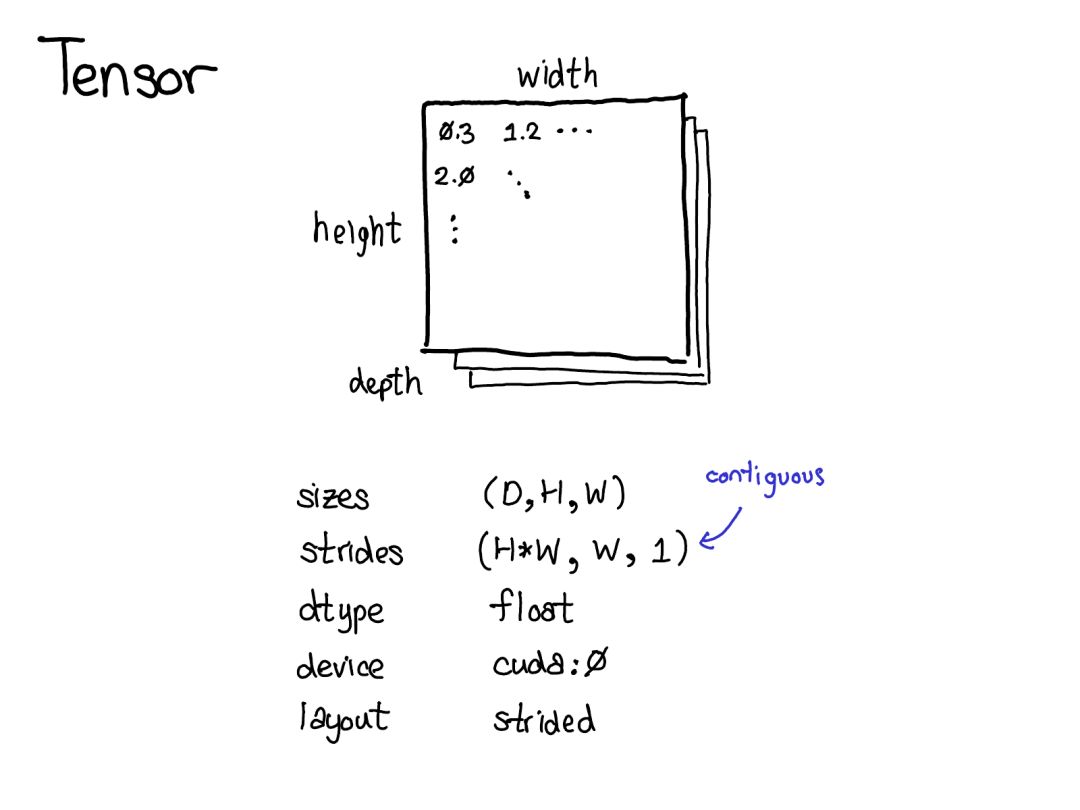
device(設(shè)備):描述了實(shí)際存儲(chǔ)張量的物理內(nèi)存,比如在 CPU、英偉達(dá) GPU(cuda)、AMD GPU(hip)或 TPU(xla)上。設(shè)備之間各不相同的特性是有各自自己的分配器(allocator),這沒法用于其它設(shè)備。
layout(布局):描述了對(duì)物理內(nèi)存進(jìn)行邏輯解讀的方式。最常用的布局是有步幅的張量(strided tensor),但稀疏張量的布局不同,其涉及到一對(duì)張量,一個(gè)用于索引,一個(gè)用于數(shù)據(jù);MKL-DNN 張量的布局更加奇特,比如 blocked layout,僅用步幅不能表示它。
dtype(數(shù)據(jù)類型):描述了張量中每個(gè)元素實(shí)際存儲(chǔ)的數(shù)據(jù)的類型,比如可以是浮點(diǎn)數(shù)、整型數(shù)或量化的整型數(shù)。


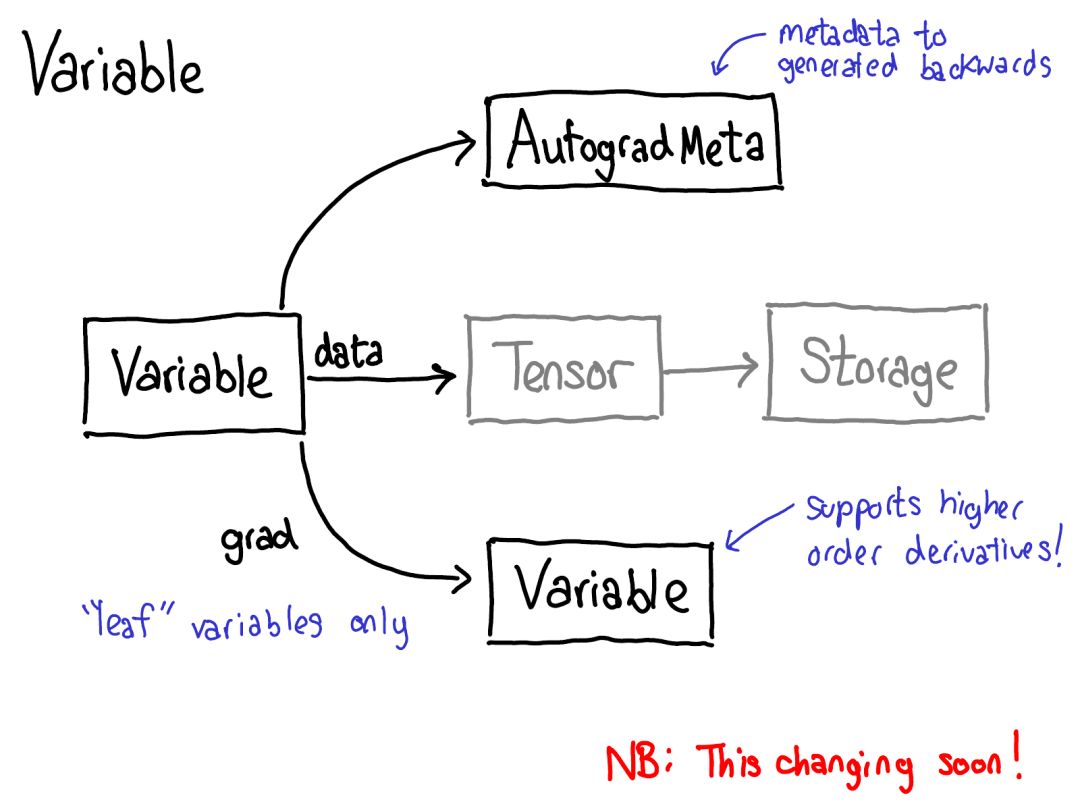
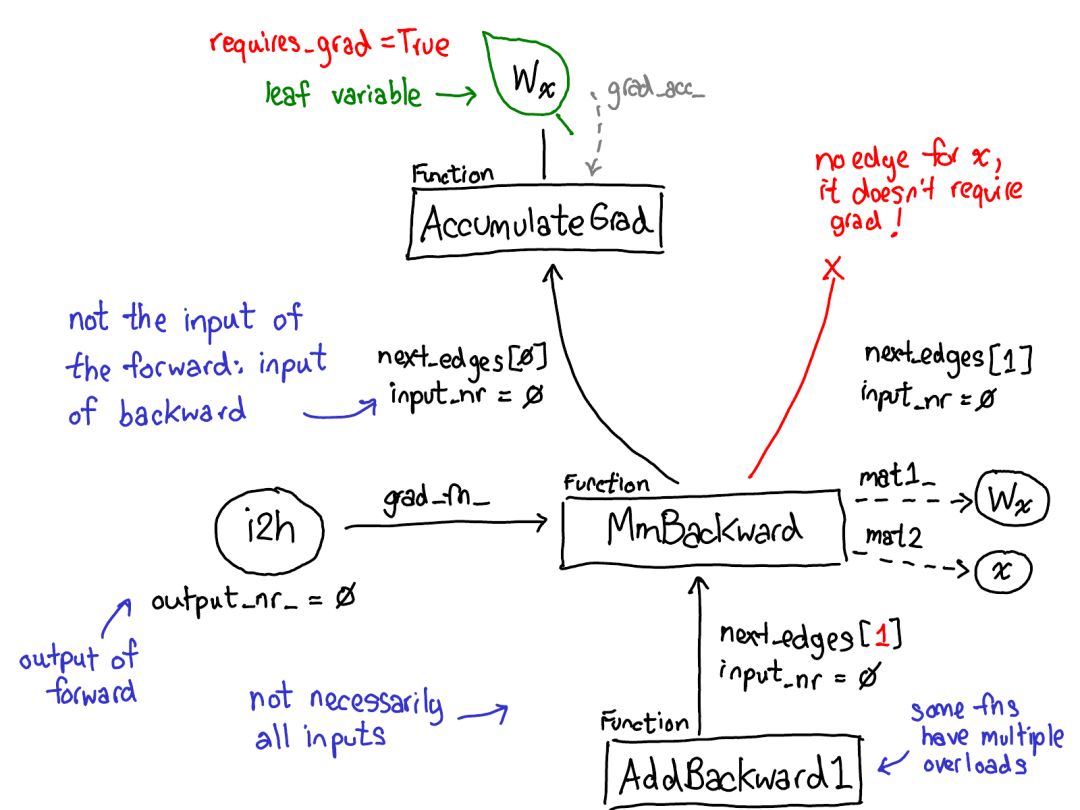
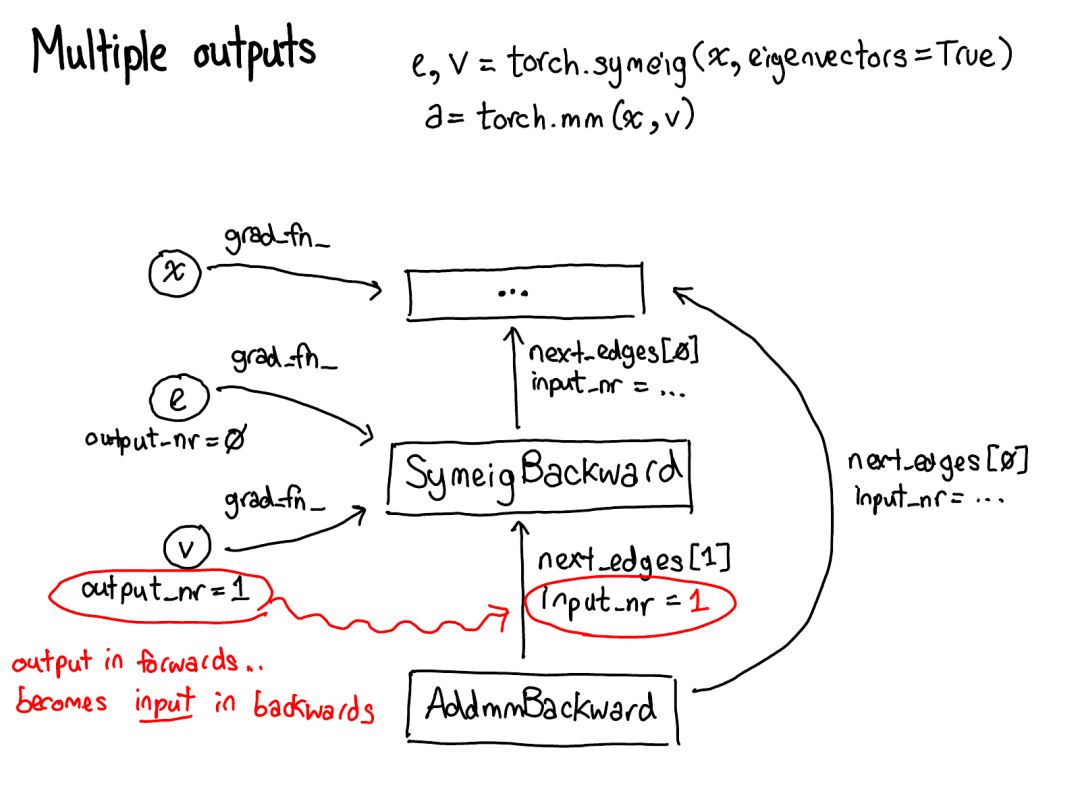
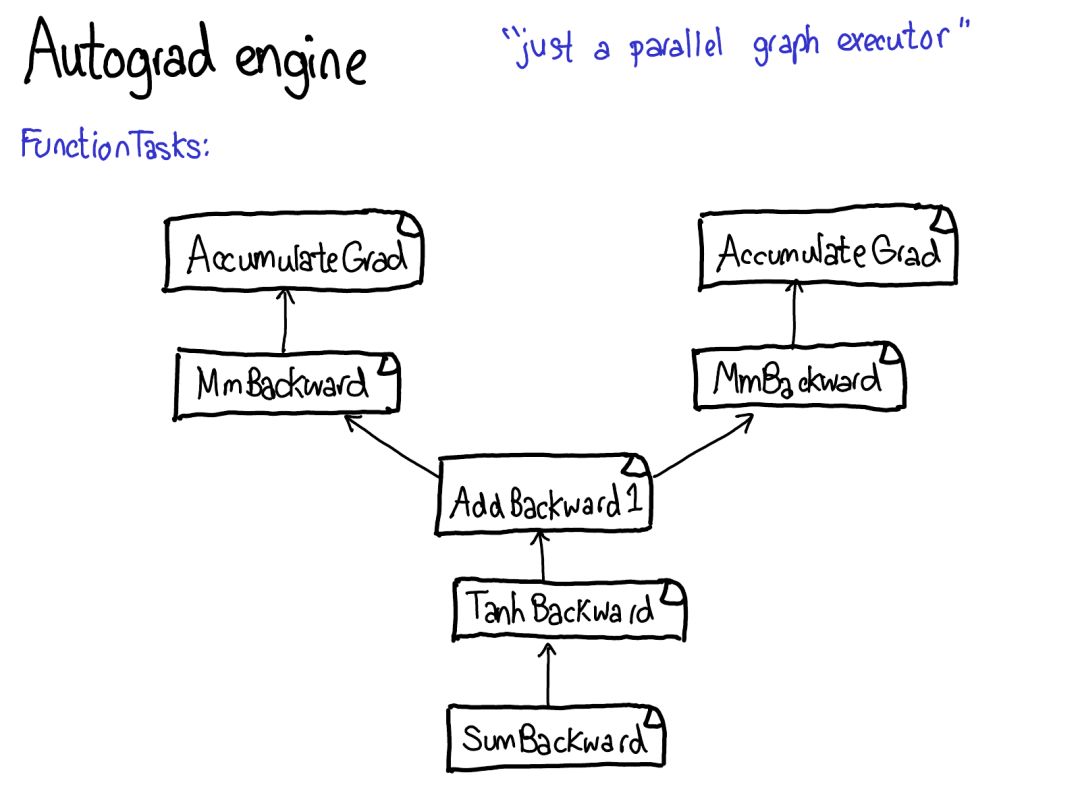
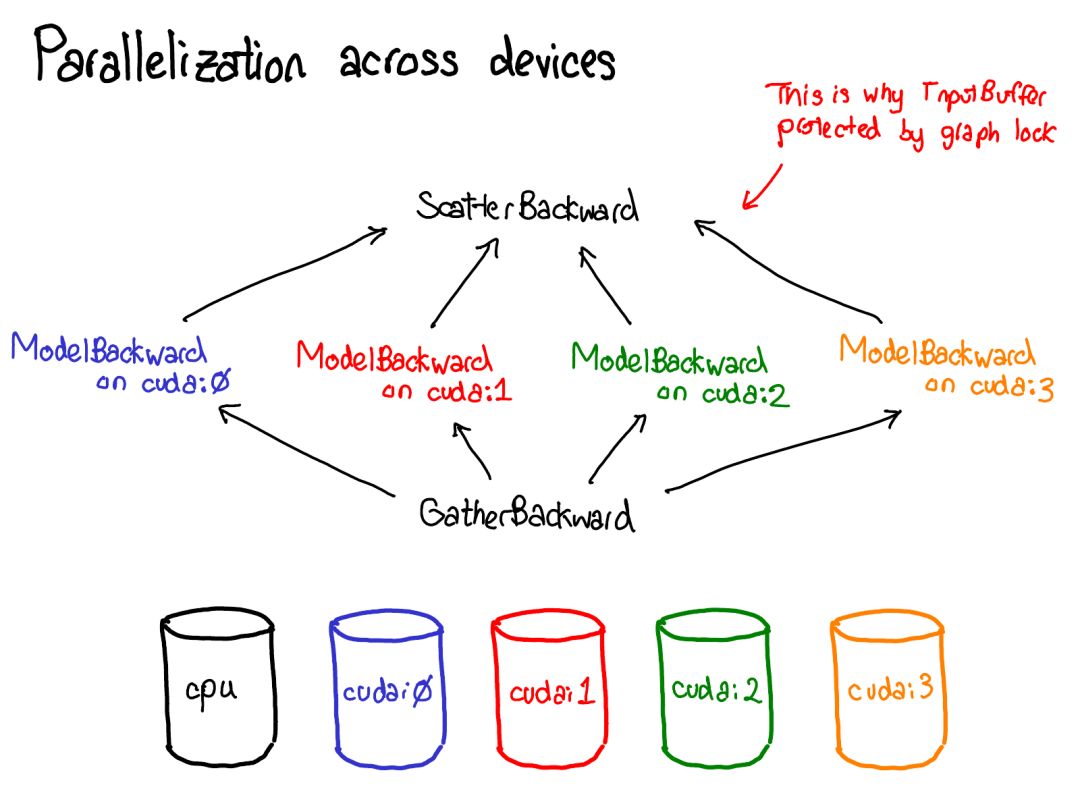
首先將你的目光投向紅色和藍(lán)色的變量。PyTorch 實(shí)現(xiàn)了反向模式自動(dòng)微分,這意味著我們可以「反向」走過前向計(jì)算來有效地計(jì)算梯度。查看變量名就能看到這一點(diǎn):在紅色部分的底部,我們計(jì)算的是損失(loss);然后在這個(gè)程序的藍(lán)色部分,我們所做的第一件事是計(jì)算 grad_loss。loss 根據(jù) next_h2 計(jì)算,這樣我們可以計(jì)算出 grad_next_h2。從技術(shù)上講,我們加了 grad_ 的變量其實(shí)并不是梯度,它們實(shí)際上左乘了一個(gè)向量的雅可比矩陣,但在 PyTorch 中,我們就稱之為 grad,基本上所有人都知道這是什么意思。
如果代碼的結(jié)構(gòu)保持一樣,而行為沒有保持一樣:來自前向的每一行都被替換為一個(gè)不同的計(jì)算,其代表了前向運(yùn)算的導(dǎo)數(shù)。舉個(gè)例子,tanh 運(yùn)算被轉(zhuǎn)譯成了 tanh_backward 運(yùn)算(這兩行用圖左邊一條灰線連接)。前向和反向運(yùn)算的輸入和輸出交換:如果前向運(yùn)算得到 next_h2,反向運(yùn)算就以 grad_next_h2 為輸入。


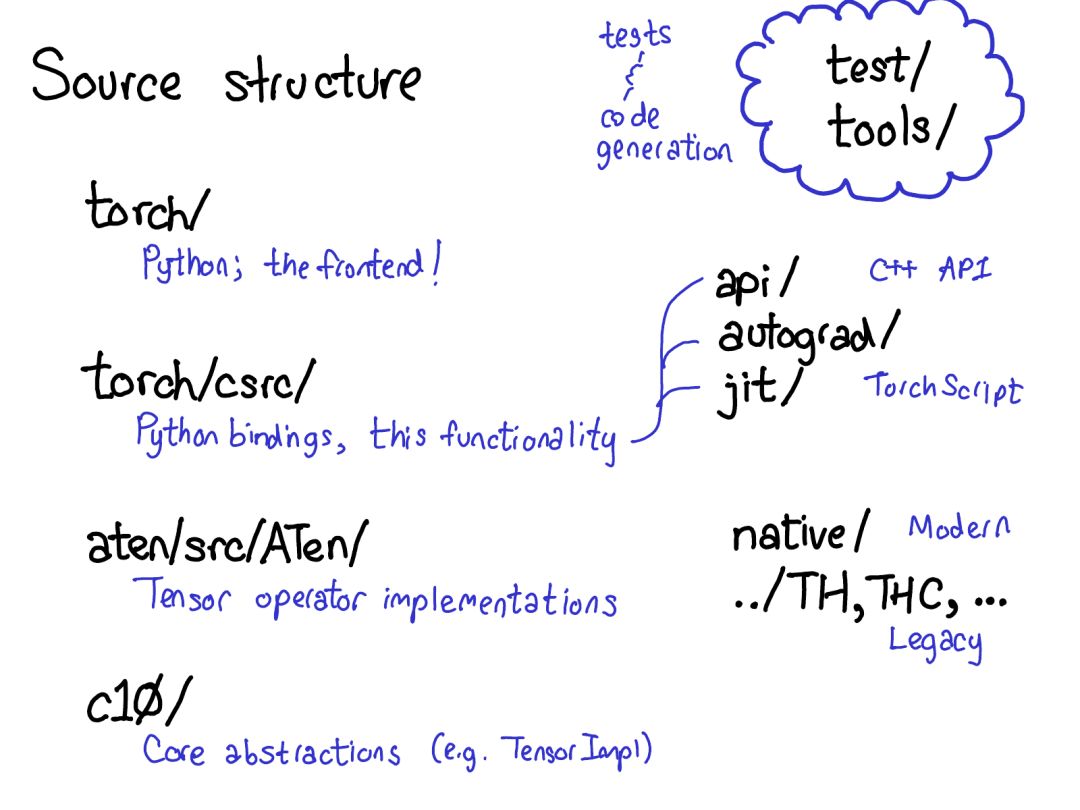
首先,torch/ 包含你最熟悉的東西:你導(dǎo)入和使用的實(shí)際的 Python 模塊。這些東西是 Python 代碼而且易于操作(只需要進(jìn)行修改然后查看結(jié)果即可)。但是,如果太過深入……
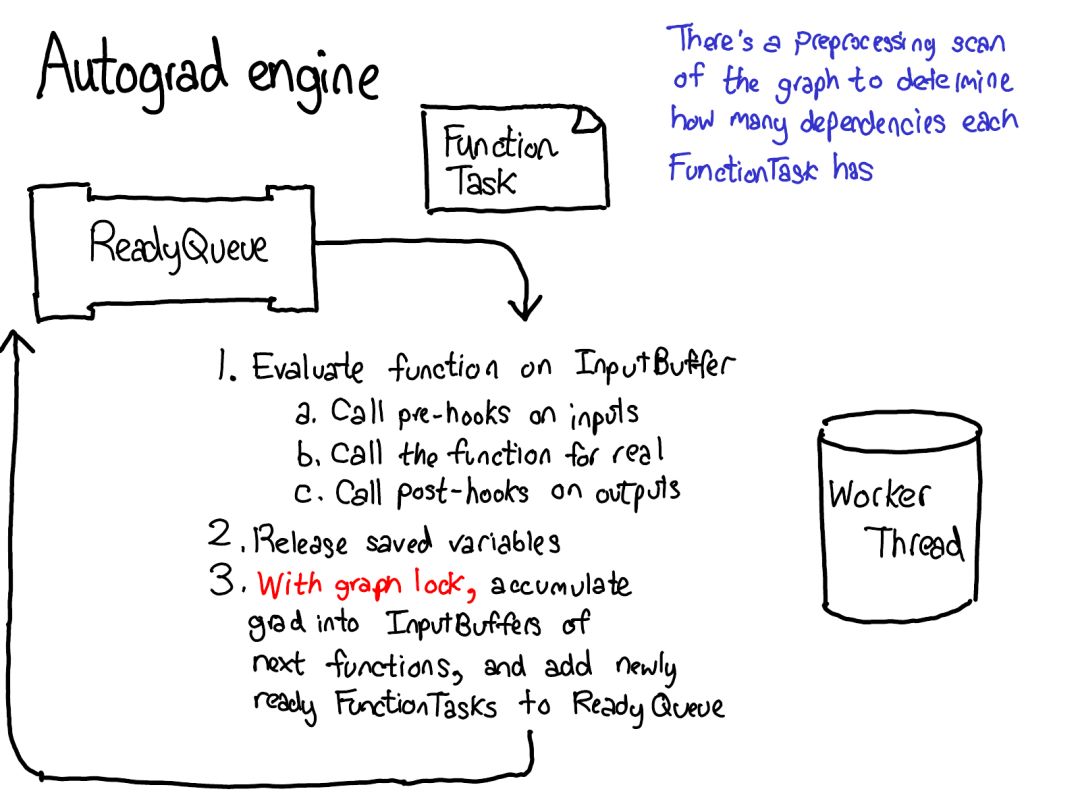
torch/csrc/:實(shí)現(xiàn)了你可能稱為 PyTorch 前端的 C++ 代碼。用更描述性的術(shù)語講,它實(shí)現(xiàn)了在 Python 和 C++ 間轉(zhuǎn)換的綁定代碼(binding code);另外還有一些相當(dāng)重要的 PyTorch 部分,比如 autograd 引擎和 JIT 編譯器。它也包含 C++ 前端代碼。
aten/:這是「A Tensor Library」的縮寫(由 Zachary DeVito 命名),是一個(gè)實(shí)現(xiàn)張量運(yùn)算的 C++ 庫(kù)。如果你檢查某些核代碼所處的位置,很可能就在 ATen。ATen 本身就分為兩個(gè)算子區(qū)域:「原生」算子(算子的現(xiàn)代的 C++ 實(shí)現(xiàn))和「?jìng)鹘y(tǒng)」算子(TH、THC、THNN、THCUNN),這些是遺留的 C 實(shí)現(xiàn)。傳統(tǒng)的算子是其中糟糕的部分;如果可以,請(qǐng)勿在上面耗費(fèi)太多時(shí)間。
c10/:這是「Caffe2」和「A"Ten"」的雙關(guān)語,包含 PyTorch 的核心抽象,包括張量和存儲(chǔ)數(shù)據(jù)結(jié)構(gòu)的實(shí)際實(shí)現(xiàn)。

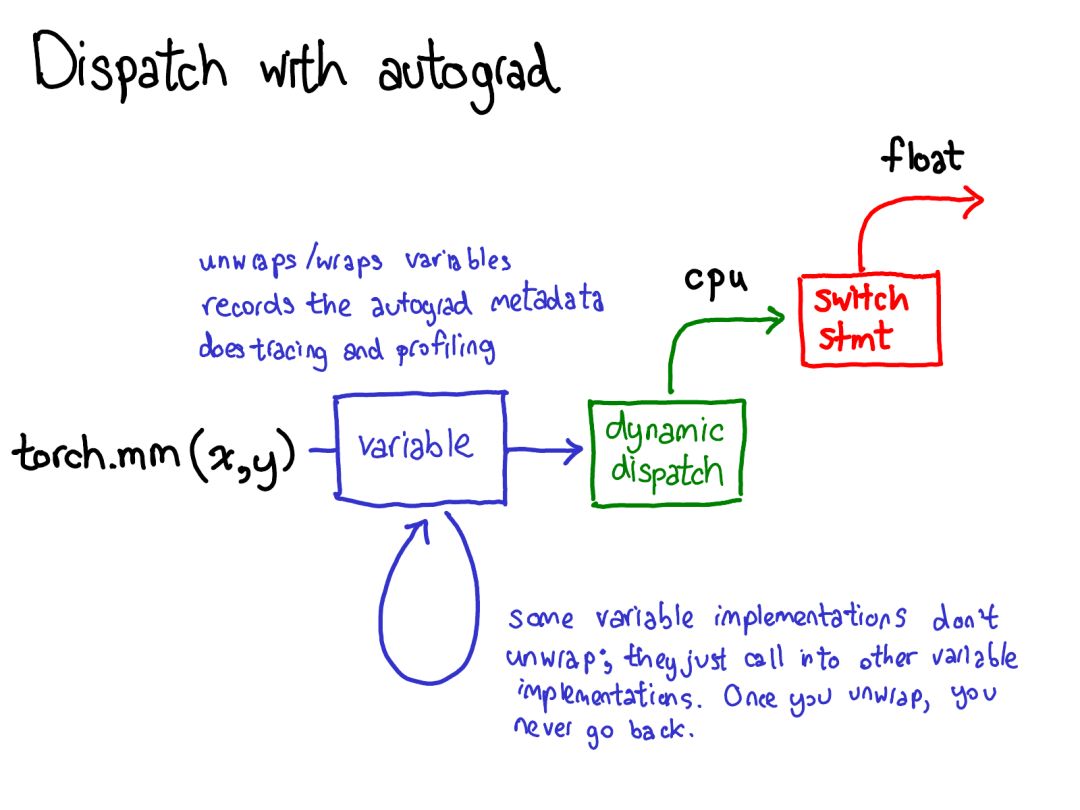
我們必須從 Python 國(guó)度轉(zhuǎn)換到 C++ 國(guó)度(Python 參數(shù)解析)。
我們處理變量調(diào)度(VariableType—Type,順便一提,和編程語言類型并無特別關(guān)聯(lián),只是一個(gè)用于執(zhí)行調(diào)度的小工具)。
我們處理設(shè)備類型/布局調(diào)度(Type)。
我們有實(shí)際的核,這要么是一個(gè)現(xiàn)代的原生函數(shù),要么是傳統(tǒng)的 TH 函數(shù)。



首先有一些我們要寫的有關(guān)核的元數(shù)據(jù),這能助力代碼生成并讓你獲取所有與 Python 的捆綁包,同時(shí)無需寫任何一行代碼。
一旦你到達(dá)了核,你就經(jīng)過了設(shè)備類型/布局調(diào)度。你首先需要寫的是錯(cuò)誤檢查,以確保輸入的張量有正確的維度。(錯(cuò)誤檢查真正很重要!不要吝惜它!)
接下來,我們一般必須分配我們將要寫入輸出的結(jié)果張量。
該到寫核的時(shí)候了。現(xiàn)在你應(yīng)該做第二次 dtype 調(diào)度,以跳至其所操作的每個(gè) dtype 特定的核。(你不應(yīng)該過早做這件事,因?yàn)槟菢拥脑捘憔蜁?huì)毫無用處地復(fù)制在任何情況下看起來都一樣的代碼。)
大多數(shù)高性能核都需要某種形式的并行化,這樣就能利用多 CPU 系統(tǒng)了。(CUDA 核是「隱式」并行化的,因?yàn)樗鼈兊木幊棠P蜆?gòu)建于大規(guī)模并行化之上。)
最后,你需要讀取數(shù)據(jù)并執(zhí)行你想做的計(jì)算!

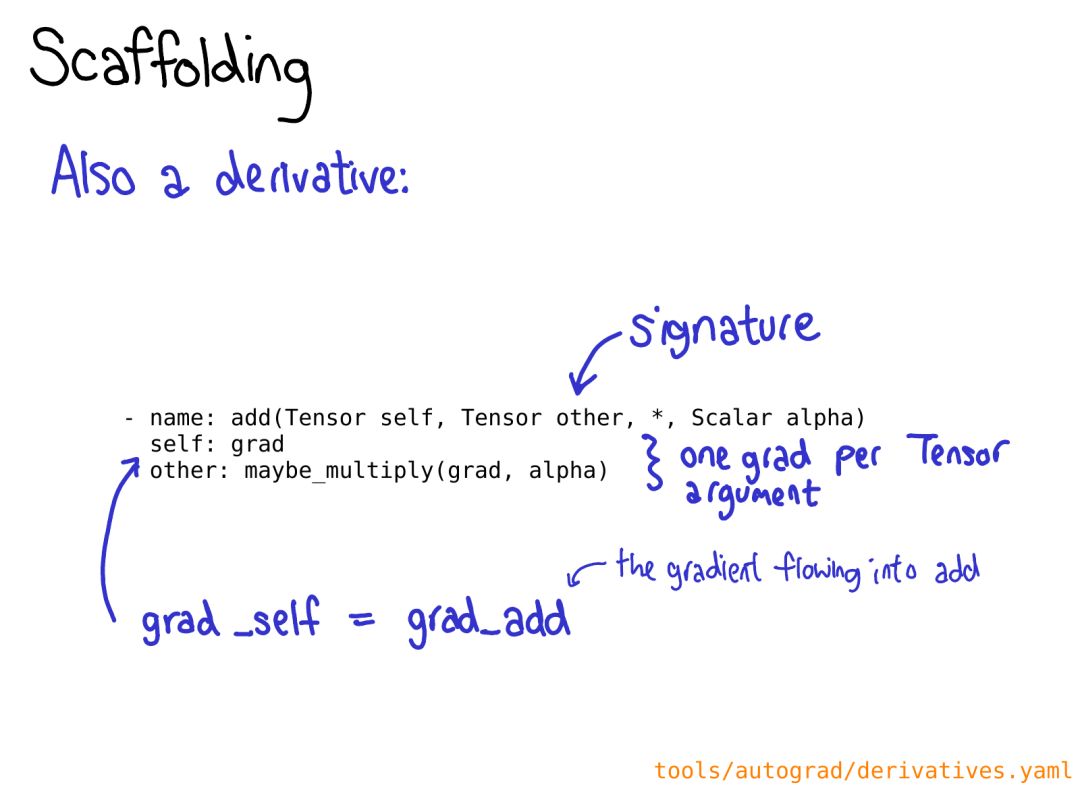





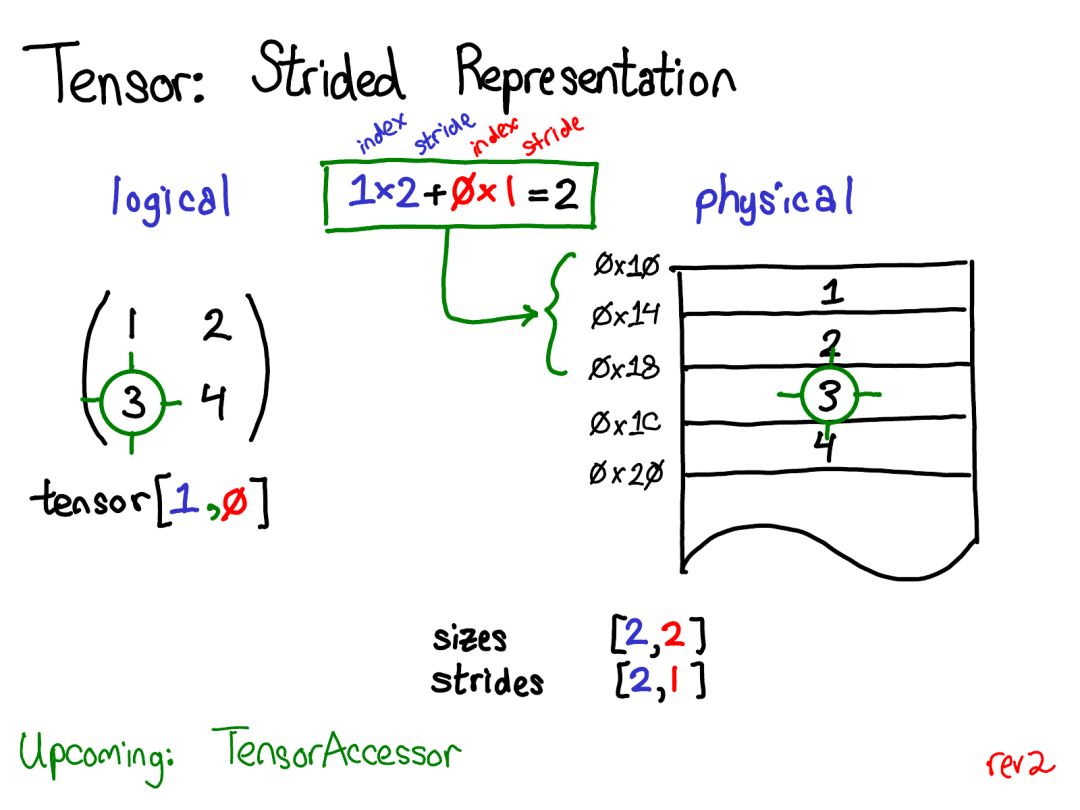
如果你只想獲取某個(gè)特定位置的值,你應(yīng)該使用 TensorAccessor。張量存取器就像是一個(gè)張量,但它將張量的維度和 dtype 硬編碼為了模板參數(shù)。當(dāng)你檢索一個(gè)存取器時(shí),比如 x.accessor
如果你在用很常規(guī)的元素存取編寫某種算子,比如逐點(diǎn)運(yùn)算,那么使用遠(yuǎn)遠(yuǎn)更高級(jí)的抽象要好得多,比如 TensorIterator。這個(gè)輔助類能為你自動(dòng)處理廣播和類型提升(type promotion),相當(dāng)好用。
要在 CPU 上獲得真正的速度,你可能需要使用向量化的 CPU 指令編寫你的核。我們也有用于這方面的輔助函數(shù)!Vec256 類表示一種標(biāo)量向量,并提供了一些能在它們上一次性執(zhí)行向量化運(yùn)算的方法。然后 binary_kernel_vec 等輔助函數(shù)能讓你輕松地運(yùn)行向量化運(yùn)算,然后結(jié)束那些沒法用普通的舊指令很好地轉(zhuǎn)換成向量指令的東西。這里的基礎(chǔ)設(shè)施還能在不同指令集下多次編譯你的核,然后在運(yùn)行時(shí)間測(cè)試你的 CPU 支持什么指令,再在這些情況中使用最佳的核。

它是以 C 風(fēng)格書寫的,沒有(或很少)使用 C++。
其 refcounted 是人工的(使用了對(duì) THTensor_free 的人工調(diào)用以降低你使用張量結(jié)束時(shí)的 refcounts)。
其位于 generic/ 目錄,這意味著我們實(shí)際上要編譯這個(gè)文件很多次,但要使用不同的 #define scalar_t

如果你編輯一個(gè) header,尤其是被許多源文件包含的 header(尤其當(dāng)被 CUDA 文件包含時(shí)),可以預(yù)見會(huì)有很長(zhǎng)的重新 build 時(shí)間。盡量只編輯 cpp 文件,編輯 header 要審慎!
我們的 CI 是一種非常好的零設(shè)置的測(cè)試修改是否有效的方法。但在獲得返回信號(hào)之前你可能需要等上一兩個(gè)小時(shí)。如果你在進(jìn)行一種將需要大量實(shí)驗(yàn)的改變,那就花點(diǎn)時(shí)間設(shè)置一個(gè)本地開發(fā)環(huán)境。類似地,如果你在特定的 CI 配置上遇到了困難的 debug 問題,就在本地設(shè)置它。你可以將 Docker 鏡像下載到本地并運(yùn)行:https://github.com/pytorch/ossci-job-dsl
貢獻(xiàn)指南解釋了如何設(shè)置 ccache:https://github.com/pytorch/pytorch/blob/master/CONTRIBUTING.md#use-ccache ;強(qiáng)烈建議這個(gè),因?yàn)檫@可以讓你在編輯 header 時(shí)幸運(yùn)地避免大量重新編譯。當(dāng)我們?cè)诓粦?yīng)該重新編譯文件時(shí)重新編譯時(shí),這也能幫你覆蓋我們的 build 系統(tǒng)的漏洞。
最后,我們會(huì)有大量 C++ 代碼。如果你是在一臺(tái)有 CPU 和 RAM 的強(qiáng)大服務(wù)器上 build,那么會(huì)有很愉快的體驗(yàn)。特別要說明,我不建議在筆記本電腦上執(zhí)行 CUDA build。build CUDA 非常非常慢,而筆記本電腦往往性能不足,不足以快速完成。