
如何解讀決策樹和隨機(jī)森林的內(nèi)部工作機(jī)制?
日期:2020年10月17日
正文共:2918字14圖
預(yù)計(jì)閱讀時(shí)間:8分鐘
來源:pivotal
Ando Saabas 的項(xiàng)目:https://github.com/andosa/treeinterpreter
創(chuàng)建圖表的代碼:https://github.com/gregtam/interpreting-decision-trees-and-random-forests
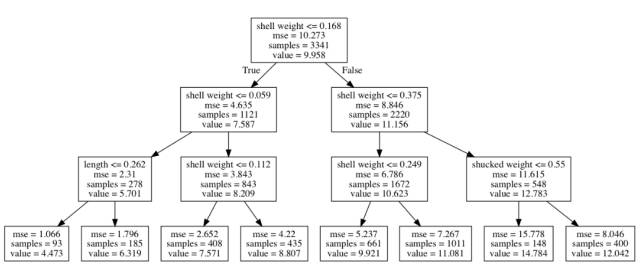
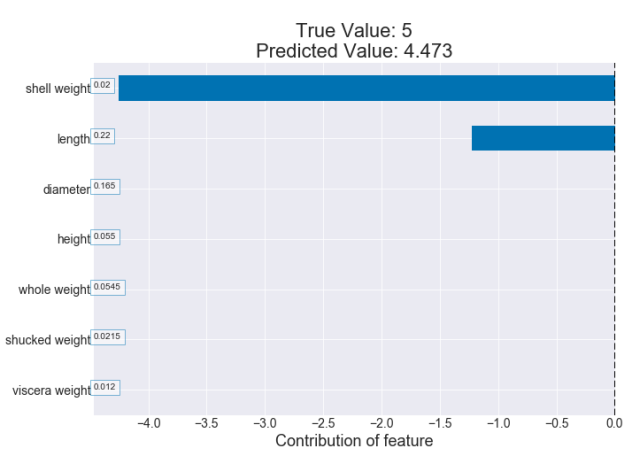
(7.587 - 9.958) + (5.701 - 7.587) = -4.257
(4.473 - 5.701) = -1.228
from?treeinterpreter?import?treeinterpreter?as?ti dt_reg_pred, dt_reg_bias, dt_reg_contrib = ti.predict(dt_reg, X_test)
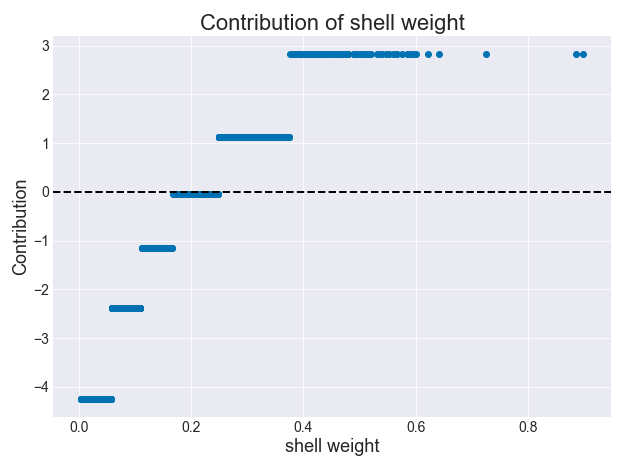
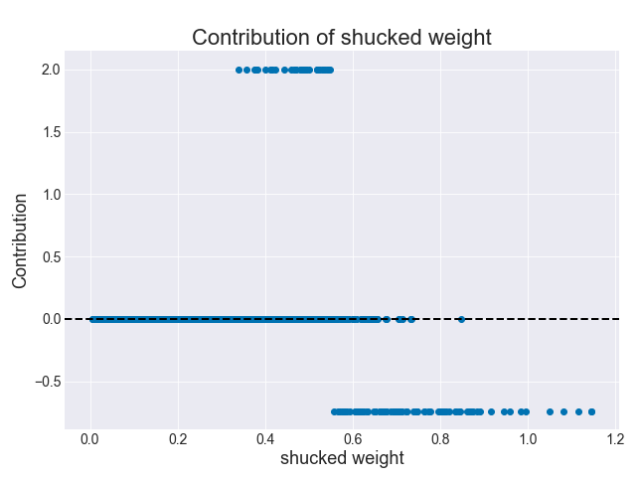
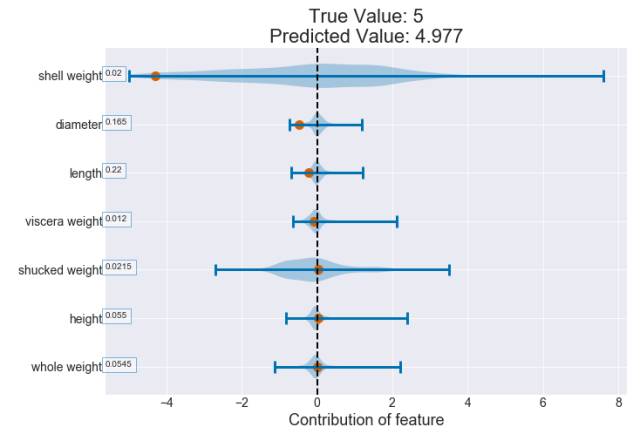
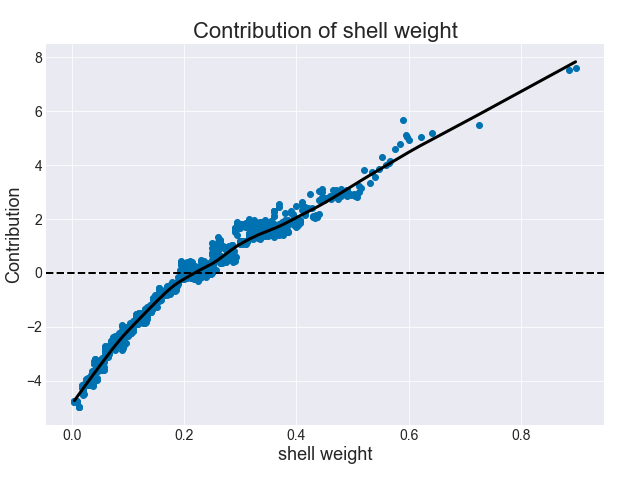
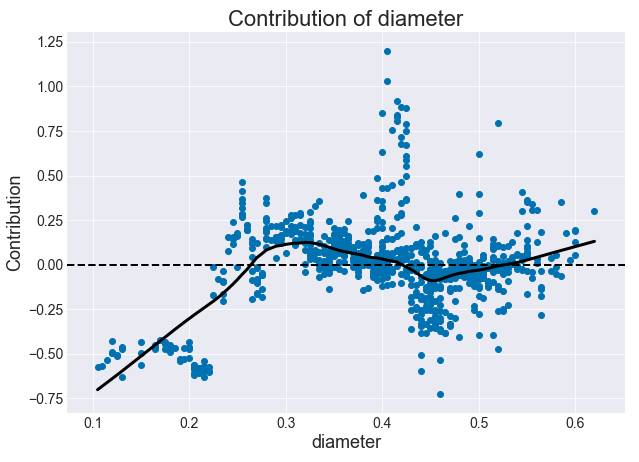
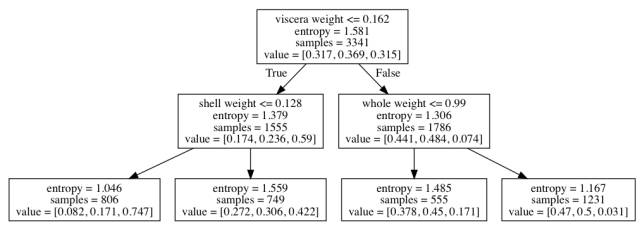
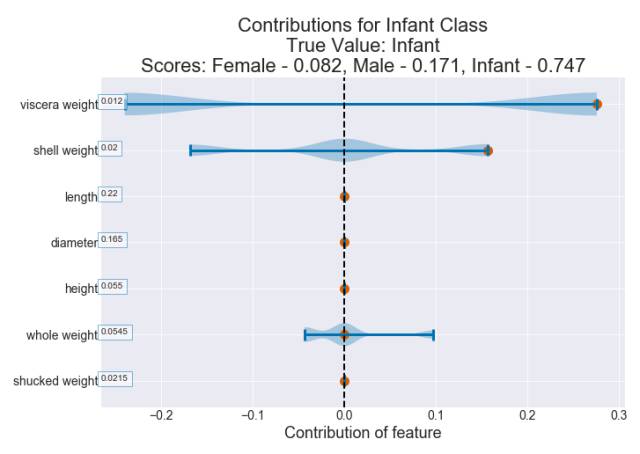
(0.59 - 0.315) = 0.275
(0.747 - 0.59) = 0.157
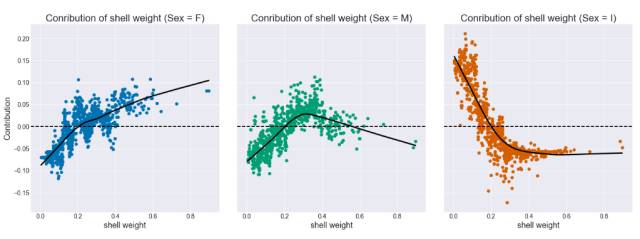

最小值等于 5
最大值等于 10
平均值為 8
下四分位數(shù)為 7,即第一四分位數(shù)(Q1),等于該樣本中所有數(shù)值由小到大排列后第 25% 的值。
中位數(shù)為 8.5,即第二四分位數(shù)(Q2),等于該樣本中所有數(shù)值由小到大排列后第 50% 的值。
上四分位數(shù)為 9,即第三四分位數(shù)(Q3),等于該樣本中所有數(shù)值由小到大排列后第 75% 的值。
四分位距為 2(即ΔQ=Q3-Q1)。
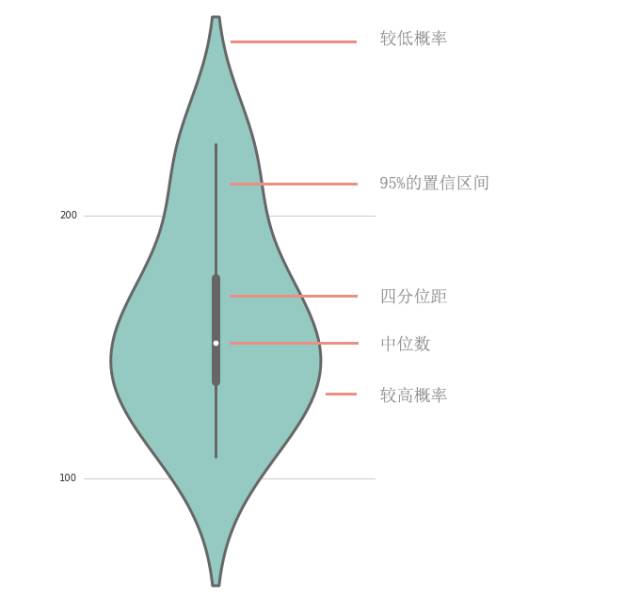
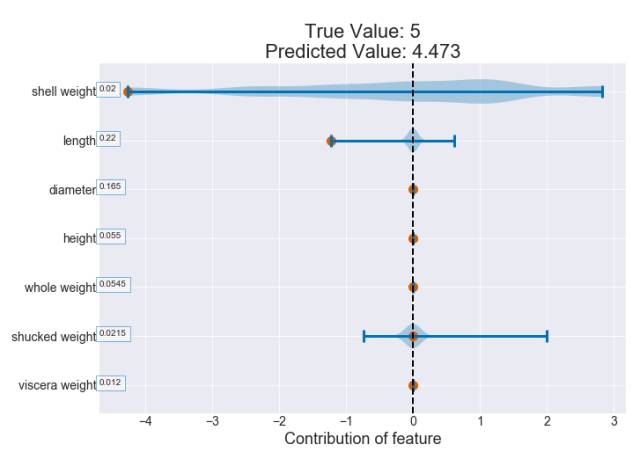
上圖白點(diǎn)代表中位數(shù)
灰色的矩形代表 Q3 和 Q1 之間的四分位距
灰線代表 95% 的置信區(qū)間
—?THE END —

評(píng)論
圖片
表情