
3000字 “嬰兒級(jí)” 爬蟲(chóng)圖文教學(xué) | 手把手教你用Python爬取 “實(shí)習(xí)網(wǎng)”!
回復(fù)“書(shū)籍”即可獲贈(zèng)Python從入門(mén)到進(jìn)階共10本電子書(shū)
1. 為"你"而寫(xiě)

2. 頁(yè)面分析
① 你要爬取的網(wǎng)站是什么?
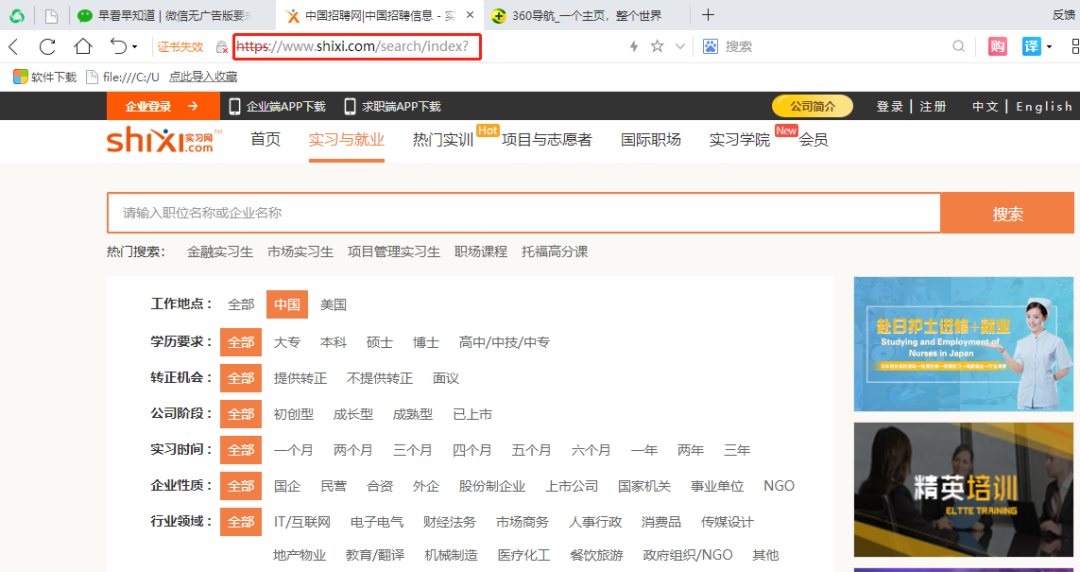
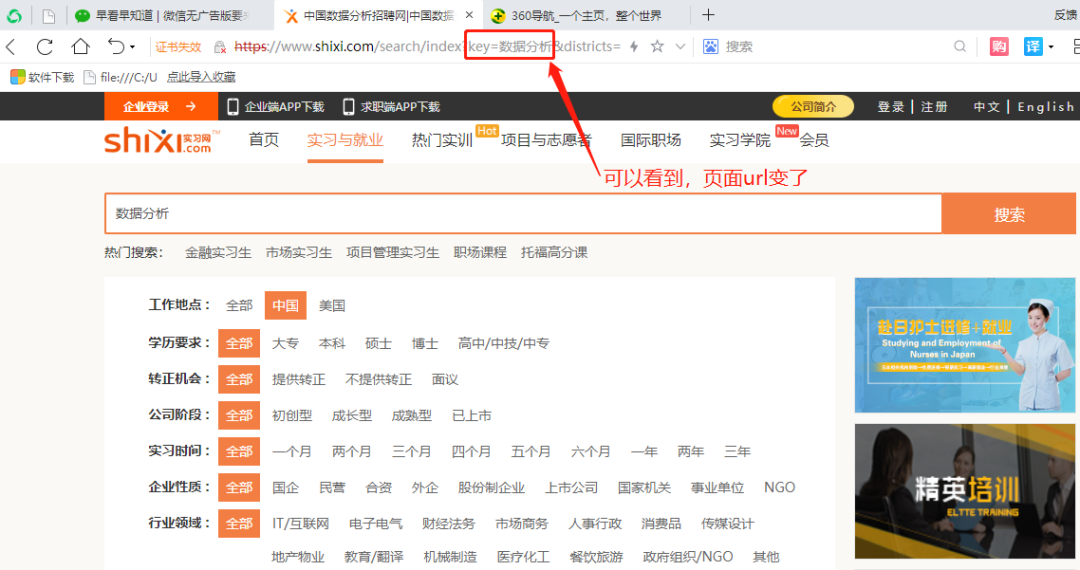
② 你要爬取頁(yè)面上的哪些信息?

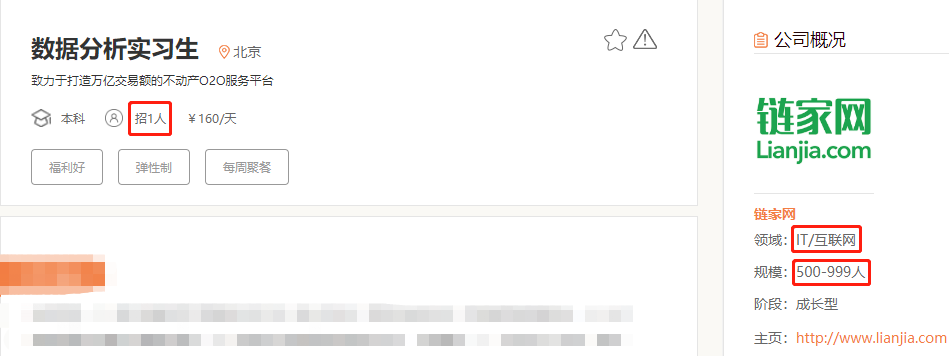
③ 頁(yè)面是 “靜態(tài)網(wǎng)頁(yè)”,還是“動(dòng)態(tài)網(wǎng)頁(yè)”?
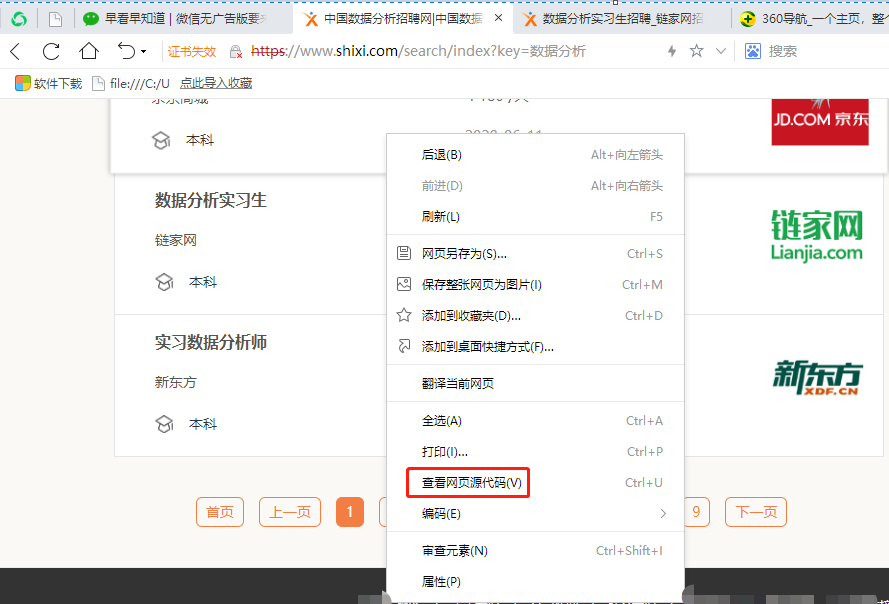

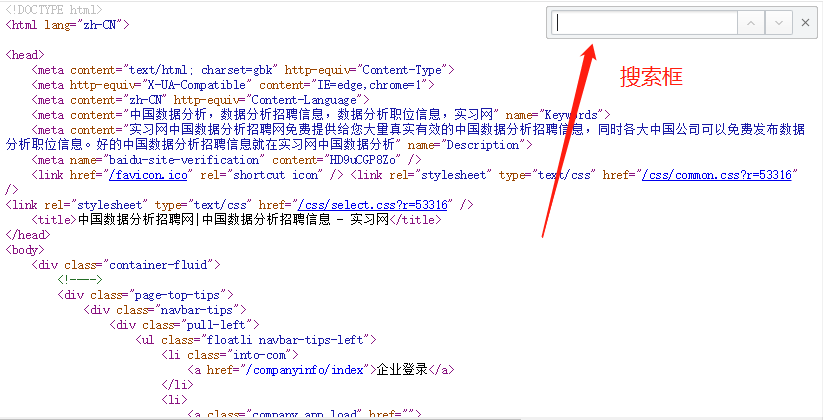
3. 如何定位數(shù)據(jù)
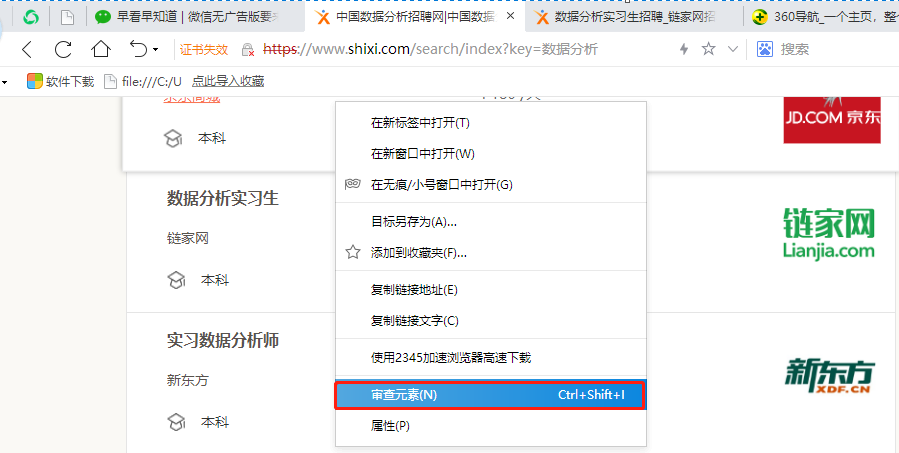
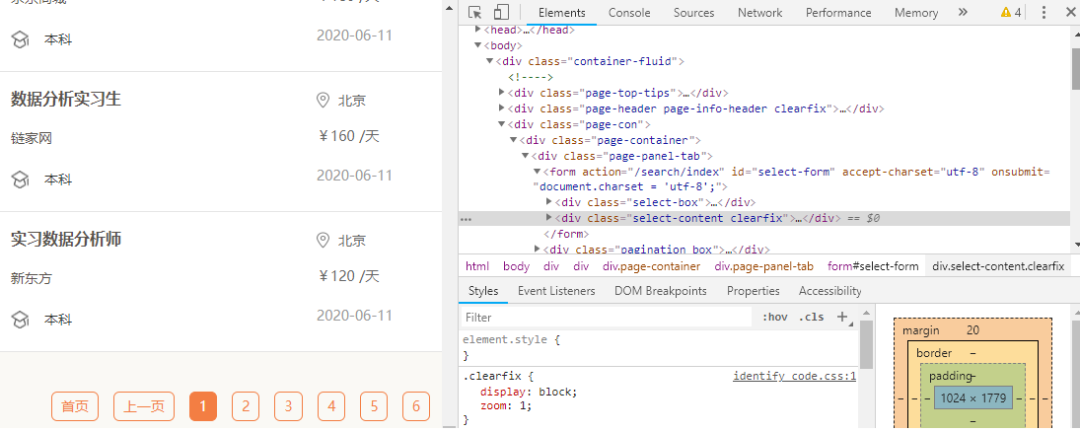
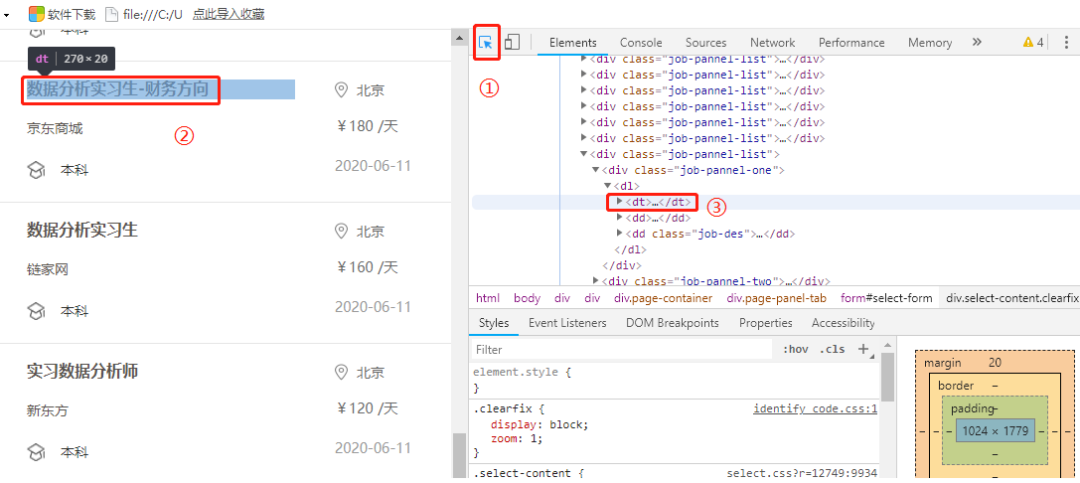
4. 爬蟲(chóng)代碼講解
① 導(dǎo)入相關(guān)庫(kù)
import pandas as pd # 用于數(shù)據(jù)存儲(chǔ)
import requests # 用于請(qǐng)求網(wǎng)頁(yè)
import chardet # 用于修改編碼
import re # 用于提取數(shù)據(jù)
from lxml import etree # 解析數(shù)據(jù)的庫(kù)
import time # 可以粗糙模擬人為請(qǐng)求網(wǎng)頁(yè)的速度
import warnings # 忽略代碼運(yùn)行時(shí)候的警告信息
warnings.filterwarnings("ignore")
② 請(qǐng)求一級(jí)頁(yè)面的網(wǎng)頁(yè)源代碼
url = 'https://www.shixi.com/search/index?key=數(shù)據(jù)分析&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text)
③ 解析一級(jí)頁(yè)面網(wǎng)頁(yè)中的信息
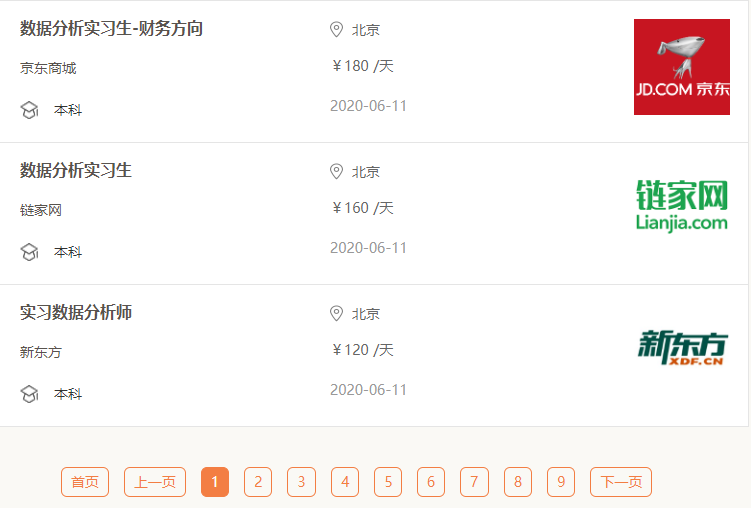
# 1. 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# 2. 崗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# 3. 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# 4. 學(xué)歷
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# 5. 薪資
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
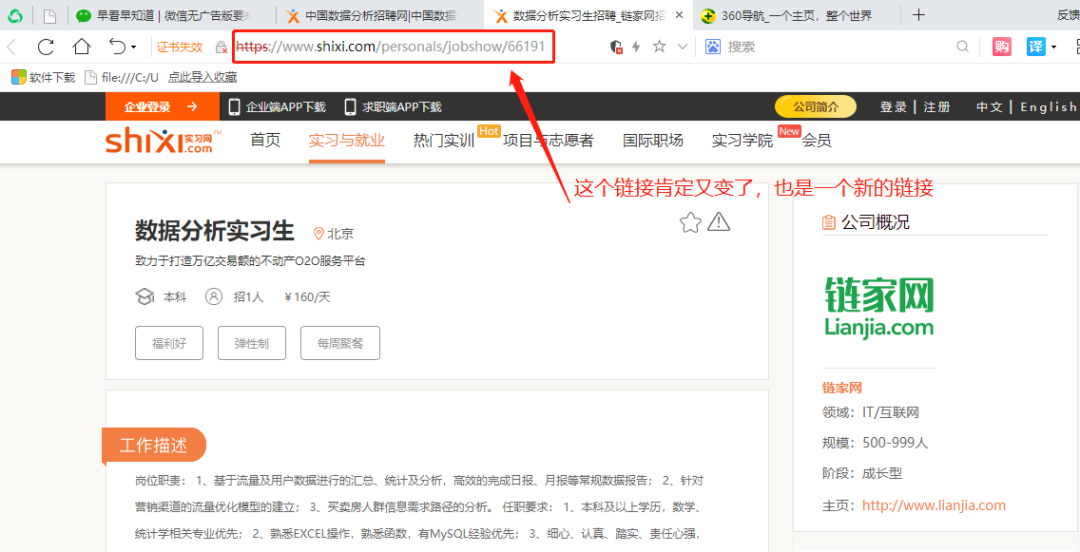
# 獲取二級(jí)頁(yè)面的鏈接
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
④ 解析二級(jí)頁(yè)面網(wǎng)頁(yè)中的信息
demand_list = []
area_list = []
scale_list = []
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False) ①
rqg.encoding = chardet.detect(rqg.content)['encoding'] ②
html = etree.HTML(rqg.text) ③
# 6. 需要幾人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# 7. 公司領(lǐng)域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# 8. 公司規(guī)模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
⑤ 翻頁(yè)操作
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=1
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=2
https://www.shixi.com/search/index?key=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&page=3
x = "https://www.shixi.com/search/index?key=數(shù)據(jù)分析&page="
url_list = [x + str(i) for i in range(1,61)]
import pandas as pd
import requests
import chardet
import re
from lxml import etree
import time
import warnings
warnings.filterwarnings("ignore")
def get_CI(url):
# ① 請(qǐng)求獲取一級(jí)頁(yè)面的源代碼
url = 'https://www.shixi.com/search/index?key=數(shù)據(jù)分析&districts=&education=0&full_opportunity=0&stage=0&practice_days=0&nature=0&trades=&lang=zh_cn'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
rqg = requests.get(url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# ② 獲取一級(jí)頁(yè)面中的信息:一共有ⅠⅡⅢⅣⅤⅥ個(gè)信息。
# Ⅰ 公司名
company_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
company_list = [company_list[i].strip() for i in range(len(company_list)) if i % 2 != 0]
# Ⅱ 崗位名
job_list = html.xpath('//div[@class="job-pannel-list"]//div[@class="job-pannel-one"]//a/text()')
job_list = [job_list[i].strip() for i in range(len(job_list)) if i % 2 == 0]
# Ⅲ 地址
address_list = html.xpath('//div[@class="job-pannel-two"]//a/text()')
# Ⅳ 學(xué)歷
degree_list = html.xpath('//div[@class="job-pannel-list"]//dd[@class="job-des"]/span/text()')
# Ⅴ 薪資
salary_list = html.xpath('//div[@class="job-pannel-two"]//div[@class="company-info-des"]/text()')
salary_list = [i.strip() for i in salary_list]
# Ⅵ 獲取二級(jí)頁(yè)面的url
deep_url_list = html.xpath('//div[@class="job-pannel-list"]//dt/a/@href')
x = "https://www.shixi.com"
deep_url_list = [x + i for i in deep_url_list]
demand_list = []
area_list = []
scale_list = []
# ③ 獲取二級(jí)頁(yè)面中的信息:一共有ⅠⅡⅢ三個(gè)信息。
for deep_url in deep_url_list:
rqg = requests.get(deep_url, headers=headers, verify=False)
rqg.encoding = chardet.detect(rqg.content)['encoding']
html = etree.HTML(rqg.text)
# Ⅰ 需要幾人
demand = html.xpath('//div[@class="container-fluid"]//div[@class="intros"]/span[2]/text()')
# Ⅱ 公司領(lǐng)域
area = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[1]/span/text()')
# Ⅲ 公司規(guī)模
scale = html.xpath('//div[@class="container-fluid"]//div[@class="detail-intro-title"]//p[2]/span/text()')
demand_list.append(demand)
area_list.append(area)
scale_list.append(scale)
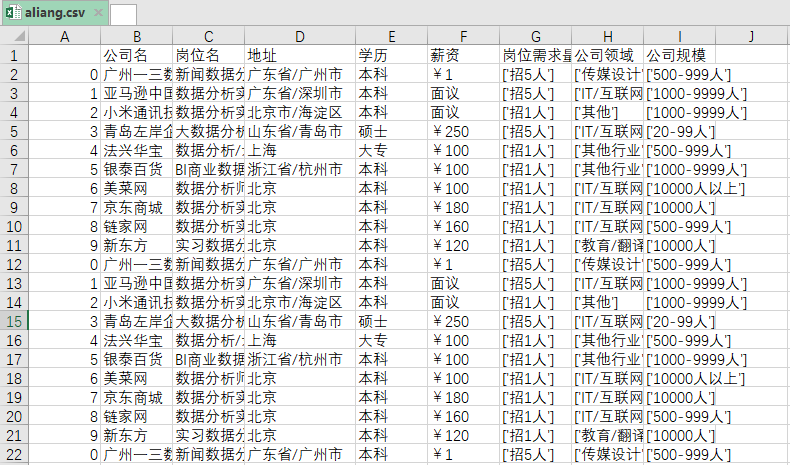
# ④ 將每個(gè)頁(yè)面獲取到的所有數(shù)據(jù),存儲(chǔ)到DataFrame中。
data = pd.DataFrame({'公司名':company_list,'崗位名':job_list,'地址':address_list,"學(xué)歷":degree_list,
'薪資':salary_list,'崗位需求量':demand_list,'公司領(lǐng)域':area_list,'公司規(guī)模':scale_list})
return(data)
x = "https://www.shixi.com/search/index?key=數(shù)據(jù)分析&page="
url_list = [x + str(i) for i in range(1,61)]
res = pd.DataFrame(columns=['公司名','崗位名','地址',"學(xué)歷",'薪資','崗位需求量','公司領(lǐng)域','公司規(guī)模'])
# ⑤ 這里進(jìn)行“翻頁(yè)”操作
for url in url_list:
res0 = get_CI(url)
res = pd.concat([res,res0])
time.sleep(3)
# ⑥ 保存最終數(shù)據(jù)
res.to_csv('aliang.csv',encoding='utf_8_sig')
往期精彩文章推薦:
一篇文章帶你了解Python高階函數(shù)
Python實(shí)例方法、類(lèi)方法和類(lèi)方法靜態(tài)方法淺析
盤(pán)點(diǎn)Python基礎(chǔ)之字符串的那些事兒

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請(qǐng)?jiān)诤笈_(tái)回復(fù)【入群】
萬(wàn)水千山總是情,點(diǎn)個(gè)【在看】行不行
/今日留言主題/
隨便說(shuō)一兩句吧~
評(píng)論
圖片
表情