
TextCNN可以和對比學(xué)習(xí)融合嗎-SimCSE論文讀后感
最近抽時間把SIMCSE用Pytorch復(fù)現(xiàn)了一下,中途涉及到的幾個思考點,和大家分享一下:
注:原作者有開源論文代碼,不過有些復(fù)雜,大家可以看一下自己魔改一下;
全文思路如下:
SIMCSE理論介紹以及代碼實現(xiàn)的部分細(xì)節(jié)點 TextCNN是否可以借鑒SIMCSE的思路,來訓(xùn)練模型從而獲取比較好的Sentence embedding 是否可以借鑒Dropout數(shù)據(jù)增強(qiáng),使用amsoftmax,減少同類距離,增大不同類距離
1. SIMCSE論文理論介紹
當(dāng)時讀完SIMCSE論文之后,沒時間寫文章,趕緊發(fā)了個朋友圈把思路簡單的記錄了一下;
感興趣的朋友加我微信【dasounlp】,互看朋友圈啊,笑;
論文分為四個部分來講,對比學(xué)習(xí),無監(jiān)督SIMCSE,有監(jiān)督SIMCSE,評價指標(biāo);
1.1 對比學(xué)習(xí)
對比學(xué)習(xí)的目的是,是減少同類距離,增大不同類之間的距離,借此獲得一個文本或者圖片更好的表示向量;
定義句子對:;其中N是一個Batch中句子對樣本數(shù)量,是語義相似的樣本,分別是經(jīng)過編碼器Encoder之后得到的表示向量;
那么對比學(xué)習(xí)的訓(xùn)練目標(biāo)就是:
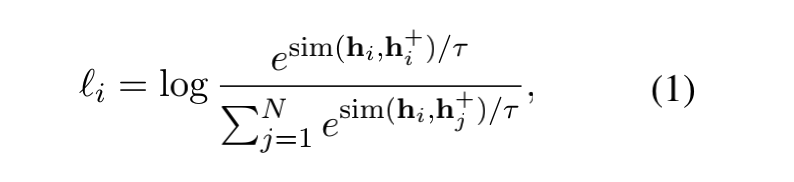
這個公式看著比較唬人,其實本質(zhì)就是一個多分類softamx的交叉熵?fù)p失函數(shù);
需要注意的是參數(shù) 是個超參數(shù),是一個相似性度量函數(shù),原論文使用的cosine,其實使用一些其他的相似性函數(shù)應(yīng)該也沒問題;
注意一下分母這里:其實一個batch,比如有N個句子對,那么就有2N個句子,其中正例是1個,負(fù)樣本應(yīng)該是總樣本數(shù)目2N減去樣本本身加上樣本的正例,也就是2N-2;
不過,看公式,作者這里用到的是一個batch中的N個樣本,也就是使用的是每個句子對中的其中一個;
關(guān)于這個問題,是否使用更多的負(fù)樣本是不是會獲得更好的效果,作者回復(fù)說并沒有。
我自己在復(fù)現(xiàn)的時候,使用的是2N-1個樣本【正例+負(fù)例總和】;
那么在落地到代碼的時候,怎么實現(xiàn)這個交叉熵呢?我畫了一個簡單的圖,比如batch是2:

1.2 正例和負(fù)例的構(gòu)建
上面談到的整個過程,全程沒離開正例和負(fù)例;
在圖像中,一個圖像經(jīng)過平移旋轉(zhuǎn)等數(shù)據(jù)增強(qiáng)的方式,可以看成是生成了圖像的正例;
在文本上,一些常規(guī)的數(shù)據(jù)增強(qiáng)的手段就是刪減單詞,替換同義詞等等;
文本的數(shù)據(jù)增強(qiáng)存在的一個問題就是,一個簡單的操作可能就會導(dǎo)致語義的改變;
在無監(jiān)督的SIMCSE中,正例的構(gòu)造很有意思,就是通過添加一個Dropout的噪聲;
Dropout是在隨機(jī)失活神經(jīng)元,每次句子經(jīng)過網(wǎng)絡(luò),失活的神經(jīng)元是不一致的,導(dǎo)致生成的embedding是不一致的;
這一點其實大家應(yīng)該都懂,但是能聯(lián)想到把這個作為數(shù)據(jù)增強(qiáng)的一個手段,確實很強(qiáng)。
在有監(jiān)督的SIMCSE中,其實是借助了NLI數(shù)據(jù)集中自帶的標(biāo)簽,來構(gòu)造正例和負(fù)例;
直接來看作者原文中的圖吧;

1.3 句子向量評價指標(biāo)
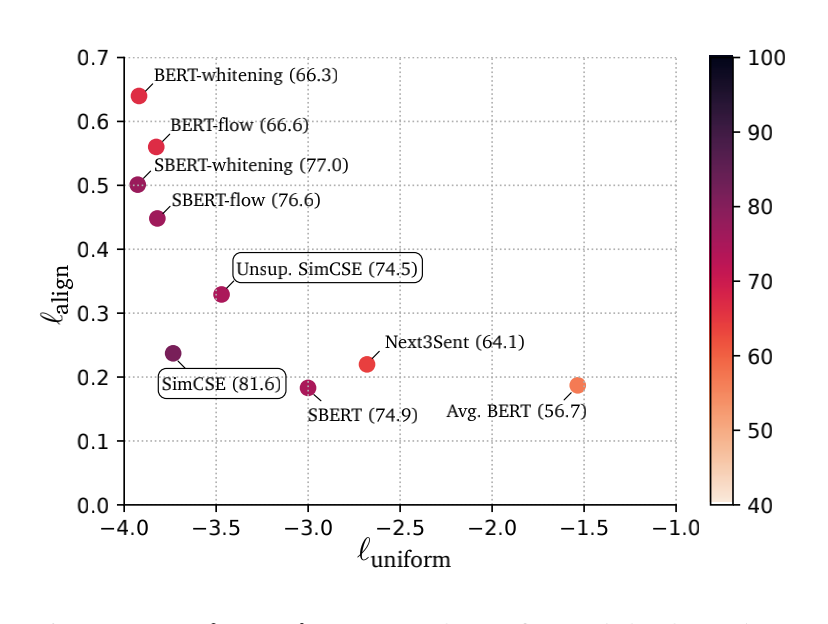
句子向量的評價指標(biāo)這里,用兩個東西來量化一下,alignment和Uniformity;
直接來看圖:
2. TextCNN和Dropout的融合
SIMCSE中,BERT作為Encoder未免太復(fù)雜了,這時候按照常規(guī)思路,我會去思考可不可以使用簡單網(wǎng)絡(luò)比如textcnn代替bert;
那么實現(xiàn)方式就可以分為兩種:
一種是我使用textcnn直接作為encoder,然后仿照無監(jiān)督simcse的訓(xùn)練方式進(jìn)行訓(xùn)練就可以了;
第二種方式就是知識蒸餾,無監(jiān)督simcse訓(xùn)練一個bert的encoder出來之后,使用簡單網(wǎng)絡(luò)textcnn進(jìn)行學(xué)習(xí)就可以了;
我針對第一種方式做了個實驗。
在實驗之前,我就沒報什么大的希望,只是想親眼試一下究竟可行不可行;
為什么沒有報太大希望呢,很簡單,我自己認(rèn)為dropout作為一種數(shù)據(jù)增強(qiáng)的形式,太過簡單了,textcnn這種簡單網(wǎng)絡(luò),不足以學(xué)習(xí)到其中的差異;
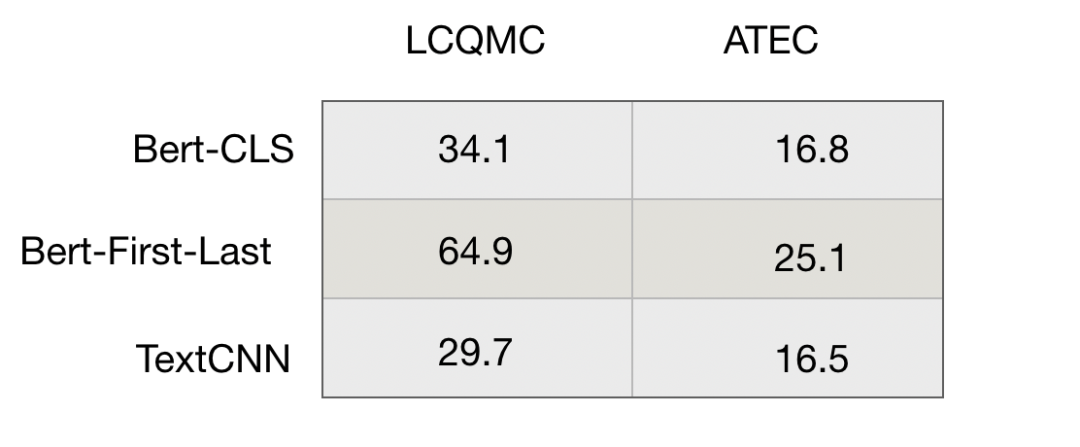
我在中文的LCQMC和ATEC數(shù)據(jù)集上做了一個簡單的測試,Spearman作為評價指標(biāo),結(jié)果如下:
之后,我看情況能不能把這部分代碼開源出來~~,自己實現(xiàn)也挺簡單的;
3. Amsoftmax的引入
第三個小思路是這樣的,dropout可以看做是一個最小化的文本數(shù)據(jù)增強(qiáng)的形式。同一個句子,經(jīng)過encoder,得到的embeding不同,但是語義是相似的,所以可以看做是一個正例;
進(jìn)一步的,如果我同一個句子經(jīng)過多次encoder,比如經(jīng)過10次,那么我得到的就是10個embedding;
也就是說,在同一個語義下面,我得到的是10個語義近似但是embedding不同的向量;
如果我有10萬個句子,可以把這個10萬個句子當(dāng)做是10萬個類別,每個類別下有10個樣本;
想一下這個感覺,不就是人臉識別的操作嗎?
那么可不可以使用這種方式,得到更好的語義表達(dá)呢?
這個我沒做實驗,只是一個思路,之后有時間再去做實驗,有興趣的朋友可以做一下;