
京東面試題:ElasticSearch深度分頁(yè)解決方案
前言
Elasticsearch 是一個(gè)實(shí)時(shí)的分布式搜索與分析引擎,在使用過(guò)程中,有一些典型的使用場(chǎng)景,比如分頁(yè)、遍歷等。
在使用關(guān)系型數(shù)據(jù)庫(kù)中,我們被告知要注意甚至被明確禁止使用深度分頁(yè),同理,在 Elasticsearch 中,也應(yīng)該盡量避免使用深度分頁(yè)。
這篇文章主要介紹 Elasticsearch 中分頁(yè)相關(guān)內(nèi)容!
From/Size參數(shù)
在ES中,分頁(yè)查詢(xún)默認(rèn)返回最頂端的10條匹配hits。
如果需要分頁(yè),需要使用from和size參數(shù)。
from參數(shù)定義了需要跳過(guò)的hits數(shù),默認(rèn)為0;
size參數(shù)定義了需要返回的hits數(shù)目的最大值。
一個(gè)基本的ES查詢(xún)語(yǔ)句是這樣的:
POST?/my_index/my_type/_search
{
????"query":?{?"match_all":?{}},
????"from":?100,
????"size":??10
}
上面的查詢(xún)表示從搜索結(jié)果中取第100條開(kāi)始的10條數(shù)據(jù)。
「那么,這個(gè)查詢(xún)語(yǔ)句在ES集群內(nèi)部是怎么執(zhí)行的呢?」
在ES中,搜索一般包括兩個(gè)階段,query 和 fetch 階段,可以簡(jiǎn)單的理解,query 階段確定要取哪些doc,fetch 階段取出具體的 doc。
?Query階段
?
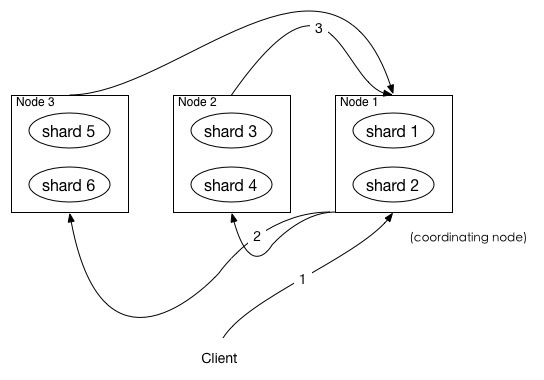
如上圖所示,描述了一次搜索請(qǐng)求的 query 階段:·
Client 發(fā)送一次搜索請(qǐng)求,node1 接收到請(qǐng)求,然后,node1 創(chuàng)建一個(gè)大小為 from + size的優(yōu)先級(jí)隊(duì)列用來(lái)存結(jié)果,我們管 node1 叫 coordinating node。coordinating node將請(qǐng)求廣播到涉及到的 shards,每個(gè) shard 在內(nèi)部執(zhí)行搜索請(qǐng)求,然后,將結(jié)果存到內(nèi)部的大小同樣為 from + size的優(yōu)先級(jí)隊(duì)列里,可以把優(yōu)先級(jí)隊(duì)列理解為一個(gè)包含top N結(jié)果的列表。每個(gè) shard 把暫存在自身優(yōu)先級(jí)隊(duì)列里的數(shù)據(jù)返回給 coordinating node,coordinating node 拿到各個(gè) shards 返回的結(jié)果后對(duì)結(jié)果進(jìn)行一次合并,產(chǎn)生一個(gè)全局的優(yōu)先級(jí)隊(duì)列,存到自身的優(yōu)先級(jí)隊(duì)列里。
在上面的例子中,coordinating node 拿到(from + size) * 6條數(shù)據(jù),然后合并并排序后選擇前面的from + size條數(shù)據(jù)存到優(yōu)先級(jí)隊(duì)列,以便 fetch 階段使用。
另外,各個(gè)分片返回給 coordinating node 的數(shù)據(jù)用于選出前from + size條數(shù)據(jù),所以,只需要返回唯一標(biāo)記 doc 的_id以及用于排序的_score即可,這樣也可以保證返回的數(shù)據(jù)量足夠小。
coordinating node 計(jì)算好自己的優(yōu)先級(jí)隊(duì)列后,query 階段結(jié)束,進(jìn)入 fetch 階段。
?Fetch階段
?
query 階段知道了要取哪些數(shù)據(jù),但是并沒(méi)有取具體的數(shù)據(jù),這就是 fetch 階段要做的。
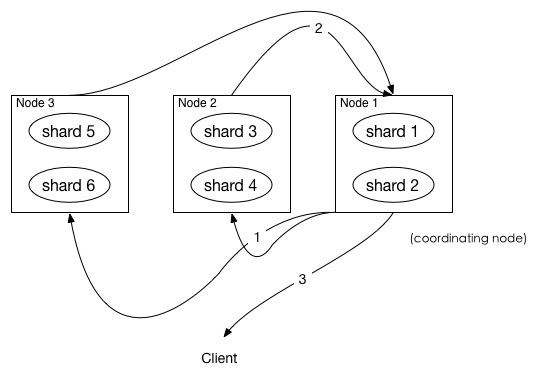
上圖展示了 fetch 過(guò)程:
coordinating node 發(fā)送 GET 請(qǐng)求到相關(guān)shards。 shard 根據(jù) doc 的 _id取到數(shù)據(jù)詳情,然后返回給 coordinating node。coordinating node 返回?cái)?shù)據(jù)給 Client。
coordinating node 的優(yōu)先級(jí)隊(duì)列里有from + size 個(gè)_doc _id,但是,在 fetch 階段,并不需要取回所有數(shù)據(jù),在上面的例子中,前100條數(shù)據(jù)是不需要取的,只需要取優(yōu)先級(jí)隊(duì)列里的第101到110條數(shù)據(jù)即可。
需要取的數(shù)據(jù)可能在不同分片,也可能在同一分片,coordinating node 使用 「multi-get」 來(lái)避免多次去同一分片取數(shù)據(jù),從而提高性能。
「這種方式請(qǐng)求深度分頁(yè)是有問(wèn)題的:」
我們可以假設(shè)在一個(gè)有 5 個(gè)主分片的索引中搜索。當(dāng)我們請(qǐng)求結(jié)果的第一頁(yè)(結(jié)果從 1 到 10 ),每一個(gè)分片產(chǎn)生前 10 的結(jié)果,并且返回給 協(xié)調(diào)節(jié)點(diǎn) ,協(xié)調(diào)節(jié)點(diǎn)對(duì) 50 個(gè)結(jié)果排序得到全部結(jié)果的前 10 個(gè)。
現(xiàn)在假設(shè)我們請(qǐng)求第 1000 頁(yè)—結(jié)果從 10001 到 10010 。所有都以相同的方式工作除了每個(gè)分片不得不產(chǎn)生前10010個(gè)結(jié)果以外。然后協(xié)調(diào)節(jié)點(diǎn)對(duì)全部 50050 個(gè)結(jié)果排序最后丟棄掉這些結(jié)果中的 50040 個(gè)結(jié)果。
「對(duì)結(jié)果排序的成本隨分頁(yè)的深度成指數(shù)上升。」
「注意1:」
size的大小不能超過(guò)index.max_result_window這個(gè)參數(shù)的設(shè)置,默認(rèn)為10000。
如果搜索size大于10000,需要設(shè)置index.max_result_window參數(shù)
PUT?_settings
{
????"index":?{
????????"max_result_window":?"10000000"
????}
}??
「注意2:」
_doc將在未來(lái)的版本移除,詳見(jiàn):
https://www.elastic.co/cn/blog/moving-from-types-to-typeless-apis-in-elasticsearch-7-0 https://elasticsearch.cn/article/158

深度分頁(yè)問(wèn)題
Elasticsearch 的From/Size方式提供了分頁(yè)的功能,同時(shí),也有相應(yīng)的限制。
舉個(gè)例子,一個(gè)索引,有10億數(shù)據(jù),分10個(gè) shards,然后,一個(gè)搜索請(qǐng)求,from=1000000,size=100,這時(shí)候,會(huì)帶來(lái)嚴(yán)重的性能問(wèn)題:CPU,內(nèi)存,IO,網(wǎng)絡(luò)帶寬。
在 query 階段,每個(gè)shards需要返回 1000100 條數(shù)據(jù)給 coordinating node,而 coordinating node 需要接收10 * 1000,100 條數(shù)據(jù),即使每條數(shù)據(jù)只有 _doc _id 和 _score,這數(shù)據(jù)量也很大了?
「在另一方面,我們意識(shí)到,這種深度分頁(yè)的請(qǐng)求并不合理,因?yàn)槲覀兪呛苌偃藶榈目春芎竺娴恼?qǐng)求的,在很多的業(yè)務(wù)場(chǎng)景中,都直接限制分頁(yè),比如只能看前100頁(yè)。」
比如,有1千萬(wàn)粉絲的微信大V,要給所有粉絲群發(fā)消息,或者給某省粉絲群發(fā),這時(shí)候就需要取得所有符合條件的粉絲,而最容易想到的就是利用 from + size 來(lái)實(shí)現(xiàn),不過(guò),這個(gè)是不現(xiàn)實(shí)的,這時(shí),可以采用 Elasticsearch 提供的其他方式來(lái)實(shí)現(xiàn)遍歷。
深度分頁(yè)問(wèn)題大致可以分為兩類(lèi):
「隨機(jī)深度分頁(yè):隨機(jī)跳轉(zhuǎn)頁(yè)面」 「滾動(dòng)深度分頁(yè):只能一頁(yè)一頁(yè)往下查詢(xún)」
「下面介紹幾個(gè)官方提供的深度分頁(yè)方法」
Scroll
?Scroll遍歷數(shù)據(jù)
?
我們可以把scroll理解為關(guān)系型數(shù)據(jù)庫(kù)里的cursor,因此,scroll并不適合用來(lái)做實(shí)時(shí)搜索,而更適合用于后臺(tái)批處理任務(wù),比如群發(fā)。
這個(gè)分頁(yè)的用法,「不是為了實(shí)時(shí)查詢(xún)數(shù)據(jù)」,而是為了「一次性查詢(xún)大量的數(shù)據(jù)(甚至是全部的數(shù)據(jù)」)。
因?yàn)檫@個(gè)scroll相當(dāng)于維護(hù)了一份當(dāng)前索引段的快照信息,這個(gè)快照信息是你執(zhí)行這個(gè)scroll查詢(xún)時(shí)的快照。在這個(gè)查詢(xún)后的任何新索引進(jìn)來(lái)的數(shù)據(jù),都不會(huì)在這個(gè)快照中查詢(xún)到。
但是它相對(duì)于from和size,不是查詢(xún)所有數(shù)據(jù)然后剔除不要的部分,而是記錄一個(gè)讀取的位置,保證下一次快速繼續(xù)讀取。
不考慮排序的時(shí)候,可以結(jié)合SearchType.SCAN使用。
scroll可以分為初始化和遍歷兩部,初始化時(shí)將「所有符合搜索條件的搜索結(jié)果緩存起來(lái)(注意,這里只是緩存的doc_id,而并不是真的緩存了所有的文檔數(shù)據(jù),取數(shù)據(jù)是在fetch階段完成的)」,可以想象成快照。
在遍歷時(shí),從這個(gè)快照里取數(shù)據(jù),也就是說(shuō),在初始化后,對(duì)索引插入、刪除、更新數(shù)據(jù)都不會(huì)影響遍歷結(jié)果。
「基本使用」
POST?/twitter/tweet/_search?scroll=1m
{
????"size":?100,
????"query":?{
????????"match"?:?{
????????????"title"?:?"elasticsearch"
????????}
????}
}
初始化指明 index 和 type,然后,加上參數(shù) scroll,表示暫存搜索結(jié)果的時(shí)間,其它就像一個(gè)普通的search請(qǐng)求一樣。
會(huì)返回一個(gè)_scroll_id,_scroll_id用來(lái)下次取數(shù)據(jù)用。
「遍歷」
POST?/_search?scroll=1m
{
????"scroll_id":"XXXXXXXXXXXXXXXXXXXXXXX?I?am?scroll?id?XXXXXXXXXXXXXXX"
}
這里的scroll_id即 上一次遍歷取回的_scroll_id或者是初始化返回的_scroll_id,同樣的,需要帶 scroll 參數(shù)。
重復(fù)這一步驟,直到返回的數(shù)據(jù)為空,即遍歷完成。
「注意,每次都要傳參數(shù) scroll,刷新搜索結(jié)果的緩存時(shí)間」。另外,「不需要指定 index 和 type」。
設(shè)置scroll的時(shí)候,需要使搜索結(jié)果緩存到下一次遍歷完成,「同時(shí),也不能太長(zhǎng),畢竟空間有限。」
「優(yōu)缺點(diǎn)」
缺點(diǎn):
「scroll_id會(huì)占用大量的資源(特別是排序的請(qǐng)求)」 同樣的,scroll后接超時(shí)時(shí)間,頻繁的發(fā)起scroll請(qǐng)求,會(huì)出現(xiàn)一些列問(wèn)題。 「是生成的歷史快照,對(duì)于數(shù)據(jù)的變更不會(huì)反映到快照上。」
「優(yōu)點(diǎn):」
適用于非實(shí)時(shí)處理大量數(shù)據(jù)的情況,比如要進(jìn)行數(shù)據(jù)遷移或者索引變更之類(lèi)的。
Scroll Scan
ES提供了scroll scan方式進(jìn)一步提高遍歷性能,但是scroll scan不支持排序,因此scroll scan適合不需要排序的場(chǎng)景
「基本使用」
Scroll Scan 的遍歷與普通 Scroll 一樣,初始化存在一點(diǎn)差別。
POST?/my_index/my_type/_search?search_type=scan&scroll=1m&size=50
{
?"query":?{?"match_all":?{}}
}
需要指明參數(shù):
search_type:賦值為scan,表示采用 Scroll Scan 的方式遍歷,同時(shí)告訴 Elasticsearch 搜索結(jié)果不需要排序。scroll:同上,傳時(shí)間。 size:與普通的 size 不同,這個(gè) size 表示的是每個(gè) shard 返回的 size 數(shù),最終結(jié)果最大為 number_of_shards * size。
「Scroll Scan與Scroll的區(qū)別」
Scroll-Scan結(jié)果「沒(méi)有排序」,按index順序返回,沒(méi)有排序,可以提高取數(shù)據(jù)性能。 初始化時(shí)只返回 _scroll_id,沒(méi)有具體的hits結(jié)果size控制的是每個(gè)分片的返回的數(shù)據(jù)量,而不是整個(gè)請(qǐng)求返回的數(shù)據(jù)量。
Sliced Scroll
如果你數(shù)據(jù)量很大,用Scroll遍歷數(shù)據(jù)那確實(shí)是接受不了,現(xiàn)在Scroll接口可以并發(fā)來(lái)進(jìn)行數(shù)據(jù)遍歷了。
每個(gè)Scroll請(qǐng)求,可以分成多個(gè)Slice請(qǐng)求,可以理解為切片,各Slice獨(dú)立并行,比用Scroll遍歷要快很多倍。
POST?/index/type/_search?scroll=1m
{
????"query":?{?"match_all":?{}},
????"slice":?{
????????"id":?0,
????????"max":?5
????}???
}
?
POST?ip:port/index/type/_search?scroll=1m
{
????"query":?{?"match_all":?{}},
????"slice":?{
????????"id":?1,
????????"max":?5
????}???
}
上邊的示例可以單獨(dú)請(qǐng)求兩塊數(shù)據(jù),最終五塊數(shù)據(jù)合并的結(jié)果與直接scroll scan相同。
其中max是分塊數(shù),id是第幾塊。
?官方文檔中建議max的值不要超過(guò)shard的數(shù)量,否則可能會(huì)導(dǎo)致內(nèi)存爆炸。
?
Search After
Search_after是 ES 5 新引入的一種分頁(yè)查詢(xún)機(jī)制,其原理幾乎就是和scroll一樣,因此代碼也幾乎是一樣的。
「基本使用:」
第一步:
POST?twitter/_search
{
????"size":?10,
????"query":?{
????????"match"?:?{
????????????"title"?:?"es"
????????}
????},
????"sort":?[
????????{"date":?"asc"},
????????{"_id":?"desc"}
????]
}
返回出的結(jié)果信息 :
{
??????"took"?:?29,
??????"timed_out"?:?false,
??????"_shards"?:?{
????????"total"?:?1,
????????"successful"?:?1,
????????"skipped"?:?0,
????????"failed"?:?0
??????},
??????"hits"?:?{
????????"total"?:?{
??????????"value"?:?5,
??????????"relation"?:?"eq"
????????},
????????"max_score"?:?null,
????????"hits"?:?[
??????????{
????????????...
????????????},
????????????"sort"?:?[
??????????????...
????????????]
??????????},
??????????{
????????????...
????????????},
????????????"sort"?:?[
??????????????124648691,
??????????????"624812"
????????????]
??????????}
????????]
??????}
????}
上面的請(qǐng)求會(huì)為每一個(gè)文檔返回一個(gè)包含sort排序值的數(shù)組。
這些sort排序值可以被用于search_after參數(shù)里以便抓取下一頁(yè)的數(shù)據(jù)。
比如,我們可以使用最后的一個(gè)文檔的sort排序值,將它傳遞給search_after參數(shù):
GET?twitter/_search
{
????"size":?10,
????"query":?{
????????"match"?:?{
????????????"title"?:?"es"
????????}
????},
????"search_after":?[124648691,?"624812"],
????"sort":?[
????????{"date":?"asc"},
????????{"_id":?"desc"}
????]
}
若我們想接著上次讀取的結(jié)果進(jìn)行讀取下一頁(yè)數(shù)據(jù),第二次查詢(xún)?cè)诘谝淮尾樵?xún)時(shí)的語(yǔ)句基礎(chǔ)上添加search_after,并指明從哪個(gè)數(shù)據(jù)后開(kāi)始讀取。
「基本原理」
es維護(hù)一個(gè)實(shí)時(shí)游標(biāo),它以上一次查詢(xún)的最后一條記錄為游標(biāo),方便對(duì)下一頁(yè)的查詢(xún),它是一個(gè)無(wú)狀態(tài)的查詢(xún),因此每次查詢(xún)的都是最新的數(shù)據(jù)。
由于它采用記錄作為游標(biāo),因此「SearchAfter要求doc中至少有一條全局唯一變量(每個(gè)文檔具有一個(gè)唯一值的字段應(yīng)該用作排序規(guī)范)」
「優(yōu)缺點(diǎn)」
「優(yōu)點(diǎn):」
無(wú)狀態(tài)查詢(xún),可以防止在查詢(xún)過(guò)程中,數(shù)據(jù)的變更無(wú)法及時(shí)反映到查詢(xún)中。 不需要維護(hù) scroll_id,不需要維護(hù)快照,因此可以避免消耗大量的資源。
「缺點(diǎn):」
由于無(wú)狀態(tài)查詢(xún),因此在查詢(xún)期間的變更可能會(huì)導(dǎo)致跨頁(yè)面的不一值。 排序順序可能會(huì)在執(zhí)行期間發(fā)生變化,具體取決于索引的更新和刪除。 至少需要制定一個(gè)唯一的不重復(fù)字段來(lái)排序。 它不適用于大幅度跳頁(yè)查詢(xún),或者全量導(dǎo)出,對(duì)第N頁(yè)的跳轉(zhuǎn)查詢(xún)相當(dāng)于對(duì)es不斷重復(fù)的執(zhí)行N次search after,而全量導(dǎo)出則是在短時(shí)間內(nèi)執(zhí)行大量的重復(fù)查詢(xún)。
SEARCH_AFTER不是自由跳轉(zhuǎn)到任意頁(yè)面的解決方案,而是并行滾動(dòng)多個(gè)查詢(xún)的解決方案。
總結(jié)
| 分頁(yè)方式 | 性能 | 優(yōu)點(diǎn) | 缺點(diǎn) | 場(chǎng)景 |
|---|---|---|---|---|
| from + size | 低 | 靈活性好,實(shí)現(xiàn)簡(jiǎn)單 | 深度分頁(yè)問(wèn)題 | 數(shù)據(jù)量比較小,能容忍深度分頁(yè)問(wèn)題 |
| scroll | 中 | 解決了深度分頁(yè)問(wèn)題 | 無(wú)法反應(yīng)數(shù)據(jù)的實(shí)時(shí)性(快照版本)維護(hù)成本高,需要維護(hù)一個(gè) scroll_id | 海量數(shù)據(jù)的導(dǎo)出需要查詢(xún)海量結(jié)果集的數(shù)據(jù) |
| search_after | 高 | 性能最好不存在深度分頁(yè)問(wèn)題能夠反映數(shù)據(jù)的實(shí)時(shí)變更 | 實(shí)現(xiàn)復(fù)雜,需要有一個(gè)全局唯一的字段連續(xù)分頁(yè)的實(shí)現(xiàn)會(huì)比較復(fù)雜,因?yàn)槊恳淮尾樵?xún)都需要上次查詢(xún)的結(jié)果,它不適用于大幅度跳頁(yè)查詢(xún) | 海量數(shù)據(jù)的分頁(yè) |
ES7版本變更
參照:https://www.elastic.co/guide/en/elasticsearch/reference/master/paginate-search-results.html#scroll-search-results
在7.*版本中,ES官方不再推薦使用Scroll方法來(lái)進(jìn)行深分頁(yè),而是推薦使用帶PIT的search_after來(lái)進(jìn)行查詢(xún);
從7.*版本開(kāi)始,您可以使用SEARCH_AFTER參數(shù)通過(guò)上一頁(yè)中的一組排序值檢索下一頁(yè)命中。
使用SEARCH_AFTER需要多個(gè)具有相同查詢(xún)和排序值的搜索請(qǐng)求。
如果這些請(qǐng)求之間發(fā)生刷新,則結(jié)果的順序可能會(huì)更改,從而導(dǎo)致頁(yè)面之間的結(jié)果不一致。
為防止出現(xiàn)這種情況,您可以創(chuàng)建一個(gè)時(shí)間點(diǎn)(PIT)來(lái)在搜索過(guò)程中保留當(dāng)前索引狀態(tài)。
POST?/my-index-000001/_pit?keep_alive=1m
返回一個(gè)PIT ID:
{
??"id":?"46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA=="
}
在搜索請(qǐng)求中指定PIT:
GET?/_search
{
??"size":?10000,
??"query":?{
????"match"?:?{
??????"user.id"?:?"elkbee"
????}
??},
??"pit":?{
?????"id":??"46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==",?
?????"keep_alive":?"1m"
??},
??"sort":?[?
????{"@timestamp":?{"order":?"asc",?"format":?"strict_date_optional_time_nanos",?"numeric_type"?:?"date_nanos"?}}
??]
}
性能對(duì)比
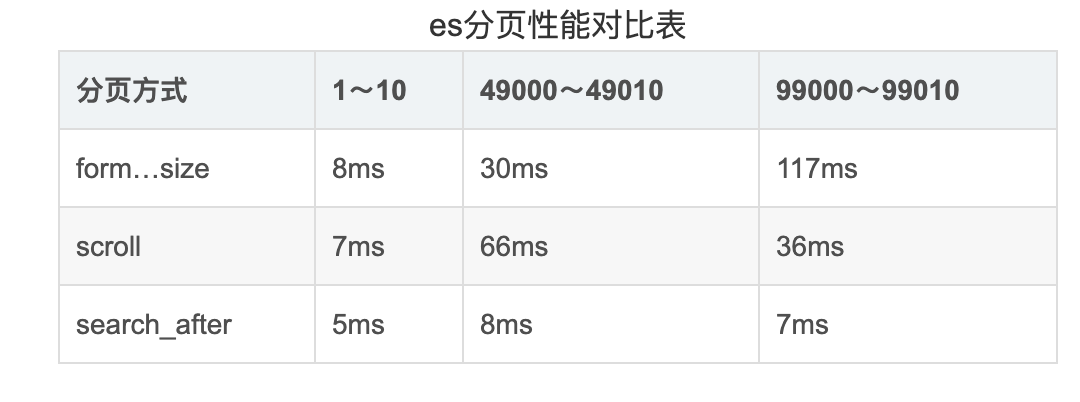
分別分頁(yè)獲取1 - 10,49000 - 49010,99000 - 99010范圍各10條數(shù)據(jù)(前提10w條),性能大致是這樣:
向前翻頁(yè)
對(duì)于向前翻頁(yè),ES中沒(méi)有相應(yīng)API,但是根據(jù)官方說(shuō)法(https://github.com/elastic/elasticsearch/issues/29449),ES中的向前翻頁(yè)問(wèn)題可以通過(guò)翻轉(zhuǎn)排序方式來(lái)實(shí)現(xiàn)即:
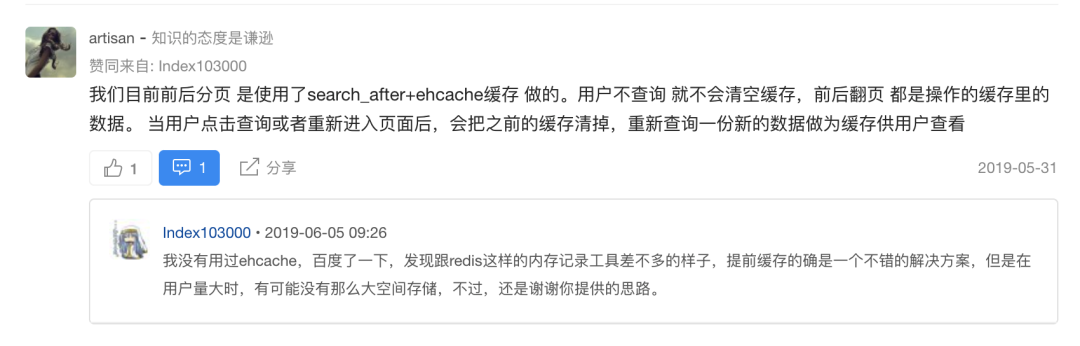
對(duì)于某一頁(yè),正序 search_after該頁(yè)的最后一條數(shù)據(jù)id為下一頁(yè),則逆序search_after該頁(yè)的第一條數(shù)據(jù)id則為上一頁(yè)。國(guó)內(nèi)論壇上,有人使用緩存來(lái)解決上一頁(yè)的問(wèn)題:https://elasticsearch.cn/question/7711
總結(jié)
如果數(shù)據(jù)量小(from+size在10000條內(nèi)),或者只關(guān)注結(jié)果集的TopN數(shù)據(jù),可以使用from/size 分頁(yè),簡(jiǎn)單粗暴 數(shù)據(jù)量大,深度翻頁(yè),后臺(tái)批處理任務(wù)(數(shù)據(jù)遷移)之類(lèi)的任務(wù),使用 scroll 方式 數(shù)據(jù)量大,深度翻頁(yè),用戶實(shí)時(shí)、高并發(fā)查詢(xún)需求,使用 search after 方式
個(gè)人思考
Scroll和search_after原理基本相同,他們都采用了游標(biāo)的方式來(lái)進(jìn)行深分頁(yè)。
這種方式雖然能夠一定程度上解決深分頁(yè)問(wèn)題。但是,它們并不是深分頁(yè)問(wèn)題的終極解決方案,深分頁(yè)問(wèn)題「必須避免!!」。
對(duì)于Scroll,無(wú)可避免的要維護(hù)scroll_id和歷史快照,并且,還必須保證scroll_id的存活時(shí)間,這對(duì)服務(wù)器是一個(gè)巨大的負(fù)荷。
對(duì)于Search_After,如果允許用戶大幅度跳轉(zhuǎn)頁(yè)面,會(huì)導(dǎo)致短時(shí)間內(nèi)頻繁的搜索動(dòng)作,這樣的效率非常低下,這也會(huì)增加服務(wù)器的負(fù)荷,同時(shí),在查詢(xún)過(guò)程中,索引的增刪改會(huì)導(dǎo)致查詢(xún)數(shù)據(jù)不一致或者排序變化,造成結(jié)果不準(zhǔn)確。
Search_After本身就是一種業(yè)務(wù)折中方案,它不允許指定跳轉(zhuǎn)到頁(yè)面,而只提供下一頁(yè)的功能。
Scroll默認(rèn)你會(huì)在后續(xù)將所有符合條件的數(shù)據(jù)都取出來(lái),所以,它只是搜索到了所有的符合條件的doc_id(這也是為什么官方推薦用doc_id進(jìn)行排序,因?yàn)楸旧砭彺娴木褪?code style="margin-right: 2px;margin-left: 2px;font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(53, 148, 247);background: rgba(59, 170, 250, 0.1);padding-right: 2px;padding-left: 2px;border-radius: 2px;height: 21px;line-height: 22px;">doc_id,如果用其他字段排序會(huì)增加查詢(xún)量),并將它們排序后保存在協(xié)調(diào)節(jié)點(diǎn)(coordinate node),但是并沒(méi)有將所有數(shù)據(jù)進(jìn)行fetch,而是每次scroll,讀取size個(gè)文檔,并返回此次讀取的最后一個(gè)文檔以及上下文狀態(tài),用以告知下一次需要從哪個(gè)shard的哪個(gè)文檔之后開(kāi)始讀取。
這也是為什么官方不推薦scroll用來(lái)給用戶進(jìn)行實(shí)時(shí)的分頁(yè)查詢(xún),而是適合于大批量的拉取數(shù)據(jù),因?yàn)樗鼜脑O(shè)計(jì)上就不是為了實(shí)時(shí)讀取數(shù)據(jù)而設(shè)計(jì)的。