大家好,今天向大家推薦一個(gè)在金融和工業(yè)領(lǐng)域應(yīng)用十分廣泛的異常檢測(cè)算法——孤立隨機(jī)森林。異常檢測(cè)看似是機(jī)器學(xué)習(xí)中一個(gè)有些難度的問(wèn)題,但采用合適的算法也可以很好解決。本文介紹了孤立森林(isolation forest)算法,通過(guò)介紹原理和代碼教你揪出數(shù)據(jù)集中的那些異常值。
從銀行欺詐到預(yù)防性的機(jī)器維護(hù),異常檢測(cè)是機(jī)器學(xué)習(xí)中非常有效且普遍的應(yīng)用。在該任務(wù)中,孤立森林算法是簡(jiǎn)單而有效的選擇。
介紹異常檢測(cè);
異常檢測(cè)的用例;
孤立森林是什么;
用孤立森林進(jìn)行異常檢測(cè);
用 Python 實(shí)現(xiàn)。
離群值是在給定數(shù)據(jù)集中,與其他數(shù)據(jù)點(diǎn)顯著不同的數(shù)據(jù)點(diǎn)。異常檢測(cè)是找出數(shù)據(jù)中離群值(和大多數(shù)數(shù)據(jù)點(diǎn)顯著不同的數(shù)據(jù)點(diǎn))的過(guò)程。真實(shí)世界中的大型數(shù)據(jù)集的模式可能非常復(fù)雜,很難通過(guò)查看數(shù)據(jù)就發(fā)現(xiàn)其模式。這就是為什么異常檢測(cè)的研究是機(jī)器學(xué)習(xí)中極其重要的應(yīng)用。本文要用孤立森林實(shí)現(xiàn)異常檢測(cè)。我們有一個(gè)簡(jiǎn)單的工資數(shù)據(jù)集,其中一些工資是異常的。目標(biāo)是要找到這些異常值。可以想象成,公司中的一些雇員掙了一大筆不同尋常的巨額收入,這可能意味著存在不道德的行為。在繼續(xù)實(shí)現(xiàn)之前,先討論一些異常檢測(cè)的用例。異常檢測(cè)在業(yè)界中應(yīng)用廣泛。下面介紹一場(chǎng)常見的用例:銀行:發(fā)現(xiàn)不正常的高額存款。每個(gè)賬戶持有人通常都有固定的存款模式。如果這個(gè)模式出現(xiàn)了異常值,那么銀行就要檢測(cè)并分析這種異常(比如洗錢)。金融:發(fā)現(xiàn)欺詐性購(gòu)買的模式。每個(gè)人通常都有固定的購(gòu)買模式。如果這種模式出現(xiàn)了異常值,銀行需要檢測(cè)出這種異常,從而分析其潛在的欺詐行為。衛(wèi)生保健:檢測(cè)欺詐性保險(xiǎn)的索賠和付款。制造業(yè):可以監(jiān)測(cè)機(jī)器的異常行為,從而控制成本。許多公司持續(xù)監(jiān)視著機(jī)器的輸入和輸出參數(shù)。眾所周知,在出現(xiàn)故障之前,機(jī)器的輸入或輸出參數(shù)會(huì)有異常。從預(yù)防性維護(hù)的角度出發(fā),需要對(duì)機(jī)器進(jìn)行持續(xù)監(jiān)控。網(wǎng)絡(luò):檢測(cè)網(wǎng)絡(luò)入侵。任何對(duì)外開放的網(wǎng)絡(luò)都面臨這樣的威脅。監(jiān)控網(wǎng)絡(luò)中的異常活動(dòng),可以及早防止入侵。接著了解一下機(jī)器學(xué)習(xí)中的孤立森林算法。孤立森林是用于異常檢測(cè)的機(jī)器學(xué)習(xí)算法。這是一種無(wú)監(jiān)督學(xué)習(xí)算法,通過(guò)隔離數(shù)據(jù)中的離群值識(shí)別異常。孤立森林是基于決策樹的算法。從給定的特征集合中隨機(jī)選擇特征,然后在特征的最大值和最小值間隨機(jī)選擇一個(gè)分割值,來(lái)隔離離群值。這種特征的隨機(jī)劃分會(huì)使異常數(shù)據(jù)點(diǎn)在樹中生成的路徑更短,從而將它們和其他數(shù)據(jù)分開。一般而言,異常檢測(cè)的第一步是構(gòu)造「正常」內(nèi)容,然后報(bào)告任何不能視為正常的異常內(nèi)容。但孤立森林算法不同于這一原理,首先它不會(huì)定義「正常」行為,而且也沒(méi)有計(jì)算基于點(diǎn)的距離。一如其名,孤立森林不通過(guò)顯式地隔離異常,它隔離了數(shù)據(jù)集中的異常點(diǎn)。孤立森林的原理是:異常值是少量且不同的觀測(cè)值,因此更易于識(shí)別。孤立森林集成了孤立樹,在給定的數(shù)據(jù)點(diǎn)中隔離異常值。孤立森林通過(guò)隨機(jī)選擇特征,然后隨機(jī)選擇特征的分割值,遞歸地生成數(shù)據(jù)集的分區(qū)。和數(shù)據(jù)集中「正常」的點(diǎn)相比,要隔離的異常值所需的隨機(jī)分區(qū)更少,因此異常值是樹中路徑更短的點(diǎn),路徑長(zhǎng)度是從根節(jié)點(diǎn)經(jīng)過(guò)的邊數(shù)。用孤立森林,不僅可以更快地檢測(cè)異常,還需要更少的內(nèi)存。孤立森林隔離數(shù)據(jù)點(diǎn)中的異常值,而不是分析正常的數(shù)據(jù)點(diǎn)。和其他正常的數(shù)據(jù)點(diǎn)相比,異常數(shù)據(jù)點(diǎn)的樹路徑更短,因此在孤立森林中的樹不需要太大的深度,所以可以用更小的 max_depth 值,從而降低內(nèi)存需求。接著我們對(duì)數(shù)據(jù)做一些探索性分析,以了解給定數(shù)據(jù)的相關(guān)信息。先導(dǎo)入所需的庫(kù)。導(dǎo)入 numpy、pandas、seaborn 和 matplotlib。此外還要從 sklearn.ensemble 中導(dǎo)入孤立森林(IsolationForest)。
import?numpy?as?np
import?pandas?as?pd
import?seaborn?as?sns
import?matplotlib.pyplot?as?plt
from?sklearn.ensemble?import?IsolationForest
導(dǎo)入庫(kù)后,要將 csv 數(shù)據(jù)讀取為 padas 數(shù)據(jù)框,檢查前十行數(shù)據(jù)。本文所用數(shù)據(jù)是不同職業(yè)的人的年薪(美元)。數(shù)據(jù)中有一些異常值(比如工資太高或太低),目標(biāo)是檢測(cè)這些異常值。
df?=?pd.read_csv('salary.csv')
df.head(10)

為了更好地了解數(shù)據(jù),將工資數(shù)據(jù)繪制成小提琴圖,如下圖所示。小提琴圖是一種繪制數(shù)值數(shù)據(jù)的方法。通常,小提琴圖包含箱圖中所有數(shù)據(jù)——中位數(shù)的標(biāo)記和四分位距的框或標(biāo)記,如果樣本數(shù)量不太大,圖中可能還包括所有樣本點(diǎn)。

為了更好地了解離群值,可能還會(huì)查看箱圖。箱圖一般也稱為箱線圖。箱圖中的箱子顯示了數(shù)據(jù)集的四分位數(shù),線表示剩余的分布。線不表示確定為離群值的點(diǎn)。我們通過(guò) interquartile range, 的函數(shù)檢測(cè)離群值。在統(tǒng)計(jì)數(shù)據(jù)中,interquartile range,(也稱為 midspread 或 middle 50%)是度量統(tǒng)計(jì)學(xué)分散度的指標(biāo),等于第 75% 個(gè)數(shù)和第 25% 個(gè)數(shù)的差。
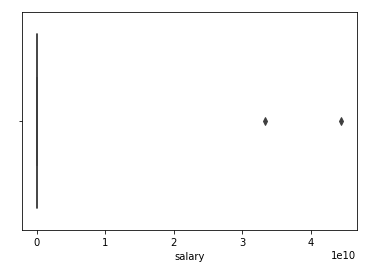
工資的箱圖,指示了右側(cè)的兩個(gè)離群值完成數(shù)據(jù)的探索性分析后,就可以定義并擬合模型了。我們要?jiǎng)?chuàng)建一個(gè)模型變量,并實(shí)例化 IsolationForest(孤立森林)類。將這四個(gè)參數(shù)的值傳遞到孤立森林方法中,如下所示。
評(píng)估器數(shù)量:n_estimators?表示集成的基評(píng)估器或樹的數(shù)量,即孤立森林中樹的數(shù)量。這是一個(gè)可調(diào)的整數(shù)參數(shù),默認(rèn)值是 100;
最大樣本:max_samples?是訓(xùn)練每個(gè)基評(píng)估器的樣本的數(shù)量。如果 max_samples 比樣本量更大,那么會(huì)用所用樣本訓(xùn)練所有樹。max_samples 的默認(rèn)值是『auto』。如果值為『auto』的話,那么 max_samples=min(256, n_samples);
數(shù)據(jù)污染問(wèn)題:算法對(duì)這個(gè)參數(shù)非常敏感,它指的是數(shù)據(jù)集中離群值的期望比例,根據(jù)樣本得分?jǐn)M合定義閾值時(shí)使用。默認(rèn)值是『auto』。如果取『auto』值,則根據(jù)孤立森林的原始論文定義閾值;
最大特征:所有基評(píng)估器都不是用數(shù)據(jù)集中所有特征訓(xùn)練的。這是從所有特征中提出的、用于訓(xùn)練每個(gè)基評(píng)估器或樹的特征數(shù)量。該參數(shù)的默認(rèn)值是 1。
model=IsolationForest(n_estimators=50,?max_samples='auto',?contamination=float(0.1),max_features=1.0)
model.fit(df[['salary']])

模型定義完后,就要用給定的數(shù)據(jù)訓(xùn)練模型了,這是用?fit()?方法實(shí)現(xiàn)的。這個(gè)方法要傳入一個(gè)參數(shù)——使用的數(shù)據(jù)(在本例中,是數(shù)據(jù)集中的工資列)。正確訓(xùn)練模型后,將會(huì)輸出孤立森林實(shí)例(如圖所示)。現(xiàn)在可以添加分?jǐn)?shù)和數(shù)據(jù)集的異常列了。在定義和擬合完模型后,找到分?jǐn)?shù)和異常列。對(duì)訓(xùn)練后的模型調(diào)用?decision_function(),并傳入工資作為參數(shù),找出分?jǐn)?shù)列的值。類似的,可以對(duì)訓(xùn)練后的模型調(diào)用?predict()?函數(shù),并傳入工資作為參數(shù),找到異常列的值。將這兩列添加到數(shù)據(jù)框 df 中。添加完這兩列后,查看數(shù)據(jù)框。如我們所料,數(shù)據(jù)框現(xiàn)在有三列:工資、分?jǐn)?shù)和異常值。分?jǐn)?shù)列中的負(fù)值和異常列中的?-1 表示出現(xiàn)異常。異常列中的?1 表示正常數(shù)據(jù)。這個(gè)算法給訓(xùn)練集中的每個(gè)數(shù)據(jù)點(diǎn)都分配了異常分?jǐn)?shù)。可以定義閾值,根據(jù)異常分?jǐn)?shù),如果分?jǐn)?shù)高于預(yù)定義的閾值,就可以將這個(gè)數(shù)據(jù)點(diǎn)標(biāo)記為異常。
df['scores']=model.decision_function(df[['salary']])
df['anomaly']=model.predict(df[['salary']])
df.head(20)
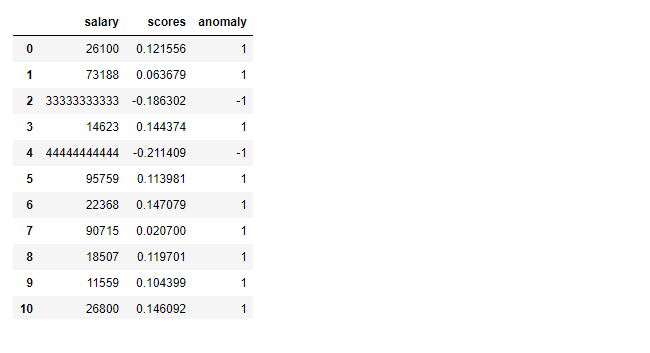
給數(shù)據(jù)的每一行中都添加了分?jǐn)?shù)和異常值后,就可以打印預(yù)測(cè)的異常了。為了打印數(shù)據(jù)中預(yù)測(cè)得到的異常,在添加分?jǐn)?shù)列和異常列后要分析數(shù)據(jù)。如前文所述,預(yù)測(cè)的異常在預(yù)測(cè)列中的值為 -1,分?jǐn)?shù)為負(fù)數(shù)。根據(jù)這一信息,將預(yù)測(cè)的異常(本例中是兩個(gè)數(shù)據(jù)點(diǎn))打印如下。
anomaly=df.loc[df['anomaly']==-1]
anomaly_index=list(anomaly.index)
print(anomaly)

注意,這樣不僅能打印異常值,還能打印異常值在數(shù)據(jù)集中的索引,這對(duì)于進(jìn)一步處理是很有用的。為了評(píng)估模型,將閾值設(shè)置為工資>99999 的為離群值。用以下代碼找出數(shù)據(jù)中存在的離群值:
outliers_counter?=?len(df[df['salary']?>?99999])
outliers_counter
計(jì)算模型找到的離群值數(shù)量除以數(shù)據(jù)中的離群值數(shù)量,得到模型的準(zhǔn)確率。
print("Accuracy?percentage:",?100*list(df['anomaly']).count(-1)/(outliers_counter))
本教程內(nèi)容包括:什么是離群值以及如何用孤立森林算法檢測(cè)離群值。還討論了針對(duì)該問(wèn)題的不同的探索性數(shù)據(jù)分析圖,比如小提琴圖和箱圖。最終我們實(shí)現(xiàn)了孤立森林算法,并打印出了數(shù)據(jù)中真正的離群值。希望你喜歡這篇文章,并希望這篇文章能在未來(lái)的項(xiàng)目中幫到你。來(lái)源?|blog.paperspace?
