
分類(lèi)中解決類(lèi)別不平衡問(wèn)題
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
1.什么是類(lèi)別不平衡問(wèn)題
2.解決類(lèi)別不平衡問(wèn)題
2.1欠采樣方法
(1)什么是欠采樣方法
(2)隨機(jī)欠采樣方法
(3)欠采樣代表性算法-EasyEnsemble
(4)欠采樣代表性算法-BalanceCascade
2.2過(guò)采樣方法
(1)什么是過(guò)采樣方法
(2)隨機(jī)過(guò)采樣方法
(3)過(guò)采樣代表性算法-SMOTE
(4)Borderline-SMOTE算法介紹
2.3代價(jià)敏感學(xué)習(xí)
(1)代價(jià)矩陣
(2)代價(jià)敏感學(xué)習(xí)方法
(3)AdaCost算法
2.4不均衡學(xué)習(xí)的評(píng)價(jià)方法
(1)F1度量
(2)G-Mean
(3)ROC曲線(xiàn)AUC面積
3.如何選擇算法
總結(jié)
如果不同類(lèi)別的訓(xùn)練樣例數(shù)目稍有差別,通常影響不大,但若差別很大,則會(huì)對(duì)學(xué)習(xí)過(guò)程造成困擾。例如有998個(gè)反例,但是正例只有2個(gè),那么學(xué)習(xí)方法只需要返回一個(gè)永遠(yuǎn)將新樣本預(yù)測(cè)為反例的學(xué)習(xí)器,就能達(dá)到99.8%的精度;然而這樣的學(xué)習(xí)器往往沒(méi)有價(jià)值,因?yàn)樗荒茴A(yù)測(cè)出任何正例。
類(lèi)別不平衡(class-imbalance)就是指分類(lèi)任務(wù)中不同類(lèi)別的訓(xùn)練樣例數(shù)目差別很大的情況。在現(xiàn)實(shí)的分類(lèi)學(xué)習(xí)任務(wù)中,我們經(jīng)常會(huì)遇到類(lèi)別不平衡,例如在通過(guò)拆分法解決多分類(lèi)問(wèn)題時(shí),即使原始問(wèn)題中不同類(lèi)別的訓(xùn)練樣例數(shù)目相當(dāng),在使用OvR(一對(duì)其余,One vs. Rest,簡(jiǎn)稱(chēng)OvR)、MvM(多對(duì)多,Many vs. Many,簡(jiǎn)稱(chēng)MvM)策略后產(chǎn)生的二分類(lèi)任務(wù)扔可能出現(xiàn)類(lèi)別不平衡現(xiàn)象,因此有必要了解類(lèi)別不平衡性處理的基本方法。
2.1欠采樣方法
(1)什么是欠采樣方法
直接對(duì)訓(xùn)練集中多數(shù)類(lèi)樣本進(jìn)行“欠采樣”(undersampling),即去除一些多數(shù)類(lèi)中的樣本使得正例、反例數(shù)目接近,然后再進(jìn)行學(xué)習(xí)。
(2)隨機(jī)欠采樣方法
隨機(jī)欠采樣顧名思義即從多數(shù)類(lèi)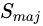 中隨機(jī)選擇一些樣樣本組成樣本集
中隨機(jī)選擇一些樣樣本組成樣本集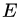 。然后將樣本集從中移除。新的數(shù)據(jù)集
。然后將樣本集從中移除。新的數(shù)據(jù)集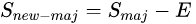 。
。
缺點(diǎn):
隨機(jī)欠采樣方法通過(guò)改變多數(shù)類(lèi)樣本比例以達(dá)到修改樣本分布的目的,從而使樣本分布較為均衡,但是這也存在一些問(wèn)題。對(duì)于隨機(jī)欠采樣,由于采樣的樣本集合要少于原來(lái)的樣本集合,因此會(huì)造成一些信息缺失,即將多數(shù)類(lèi)樣本刪除有可能會(huì)導(dǎo)致分類(lèi)器丟失有關(guān)多數(shù)類(lèi)的重要信息。
為了克服隨機(jī)欠采樣方法導(dǎo)致的信息缺失問(wèn)題,又要保證算法表現(xiàn)出較好的不均衡數(shù)據(jù)分類(lèi)性能,出現(xiàn)了欠采樣法代表性的算法EasyEnsemble和BalanceCascade算法。
(3)欠采樣代表性算法-EasyEnsemble
算法步驟:
1)從多數(shù)類(lèi)中有放回的隨機(jī)采樣n次,每次選取與少數(shù)類(lèi)數(shù)目相近的樣本個(gè)數(shù),那么可以得到n個(gè)樣本集合記作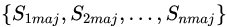 。
。
2)然后,將每一個(gè)多數(shù)類(lèi)樣本的子集與少數(shù)類(lèi)樣本合并并訓(xùn)練出一個(gè)模型,可以得到n個(gè)模型。
3)最終將這些模型組合形成一個(gè)集成學(xué)習(xí)系統(tǒng),最終的模型結(jié)果是這n個(gè)模型的平均值。
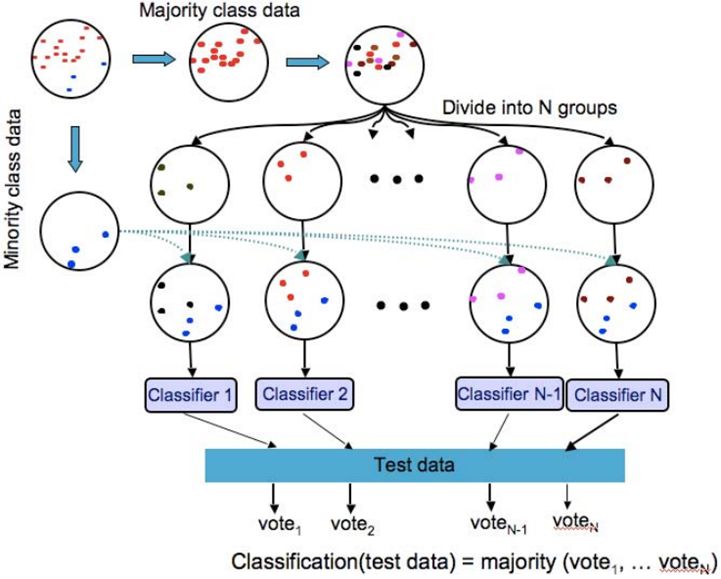
圖1:EasyEnsemble算法
(4)欠采樣代表性算法-BalanceCascade
BalanceCascade算法基于Adaboost,將Adaboost作為基分類(lèi)器,其核心思路是:
1)在每一輪訓(xùn)練時(shí)都使用多數(shù)類(lèi)與少數(shù)類(lèi)數(shù)量相等的訓(xùn)練集,訓(xùn)練出一個(gè)Adaboost基分類(lèi)器。
2)然后使用該分類(lèi)器對(duì)全體多數(shù)類(lèi)進(jìn)行預(yù)測(cè),通過(guò)控制分類(lèi)閾值來(lái)控制假正例率(False Positive Rate),將所有判斷正確的類(lèi)刪除。
3)最后,進(jìn)入下一輪迭代中,繼續(xù)降低多數(shù)類(lèi)數(shù)量。

圖2:BalanceCascade算法
擴(kuò)展閱讀:
Liu X Y, Wu J, Zhou Z H. Exploratory undersampling for class-imbalance learning[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2009, 39(2): 539-550.
這篇論文提出了兩種欠采樣的方法:EasyEnsemble和BalanceCascade。
2.2過(guò)采樣方法
(1)什么是過(guò)采樣方法
對(duì)訓(xùn)練集里的少數(shù)類(lèi)進(jìn)行“過(guò)采樣”(oversampling),即增加一些少數(shù)類(lèi)樣本使得正、反例數(shù)目接近,然后再進(jìn)行學(xué)習(xí)。
(2)隨機(jī)過(guò)采樣方法
隨機(jī)過(guò)采樣是在少數(shù)類(lèi)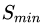 中隨機(jī)選擇一些樣本,然后通過(guò)復(fù)制所選擇的樣本生成樣本集,將它們添加到中來(lái)擴(kuò)大原始數(shù)據(jù)集從而得到新的少數(shù)類(lèi)集合
中隨機(jī)選擇一些樣本,然后通過(guò)復(fù)制所選擇的樣本生成樣本集,將它們添加到中來(lái)擴(kuò)大原始數(shù)據(jù)集從而得到新的少數(shù)類(lèi)集合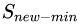 。新的數(shù)據(jù)集
。新的數(shù)據(jù)集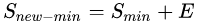 。
。
缺點(diǎn):
對(duì)于隨機(jī)過(guò)采樣,由于需要對(duì)少數(shù)類(lèi)樣本進(jìn)行復(fù)制來(lái)擴(kuò)大數(shù)據(jù)集,造成模型訓(xùn)練復(fù)雜度加大。另一方面也容易造成模型的過(guò)擬合問(wèn)題,因?yàn)殡S機(jī)過(guò)采樣是簡(jiǎn)單的對(duì)初始樣本進(jìn)行復(fù)制采樣,這就使得學(xué)習(xí)器學(xué)得的規(guī)則過(guò)于具體化,不利于學(xué)習(xí)器的泛化性能,造成過(guò)擬合問(wèn)題。
為了解決隨機(jī)過(guò)采樣中造成模型過(guò)擬合問(wèn)題,又能保證實(shí)現(xiàn)數(shù)據(jù)集均衡的目的,出現(xiàn)了過(guò)采樣法代表性的算法SMOTE和Borderline-SMOTE算法。
(3)過(guò)采樣代表性算法-SMOTE
SMOTE全稱(chēng)是Synthetic Minority Oversampling即合成少數(shù)類(lèi)過(guò)采樣技術(shù)。SMOTE算法是對(duì)隨機(jī)過(guò)采樣方法的一個(gè)改進(jìn)算法,由于隨機(jī)過(guò)采樣方法是直接對(duì)少數(shù)類(lèi)進(jìn)行重采用,會(huì)使訓(xùn)練集中有很多重復(fù)的樣本,容易造成產(chǎn)生的模型過(guò)擬合問(wèn)題。而SOMT算法的基本思想是對(duì)每個(gè)少數(shù)類(lèi)樣本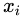 ,從它的最近鄰中隨機(jī)選擇一個(gè)樣本
,從它的最近鄰中隨機(jī)選擇一個(gè)樣本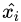 (是少數(shù)類(lèi)中的一個(gè)樣本),然后在和之間的連線(xiàn)上隨機(jī)選擇一點(diǎn)作為新合成的少數(shù)類(lèi)樣本。
(是少數(shù)類(lèi)中的一個(gè)樣本),然后在和之間的連線(xiàn)上隨機(jī)選擇一點(diǎn)作為新合成的少數(shù)類(lèi)樣本。
SMOTE算法合成新少數(shù)類(lèi)樣本的算法描述如下:
1).對(duì)于少數(shù)類(lèi)中的每一個(gè)樣本,以歐氏距離為標(biāo)準(zhǔn)計(jì)算它到少數(shù)類(lèi)樣本集中所有樣本的距離,得到其k近鄰。
2).根據(jù)樣本不平衡比例設(shè)置一個(gè)采樣比例以確定采樣倍率N,對(duì)于每一個(gè)少數(shù)類(lèi)樣本,從其k近鄰中隨機(jī)選擇若干個(gè)樣本,假設(shè)選擇的是。
3).對(duì)于每一個(gè)隨機(jī)選出來(lái)的近鄰,分別與按照如下公式構(gòu)建新的樣本。
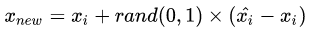
我們用圖文表達(dá)的方式,再來(lái)描述一下SMOTE算法。
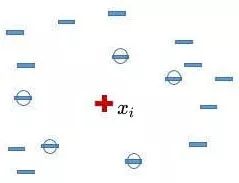
1).先隨機(jī)選定一個(gè)少數(shù)類(lèi)樣本。
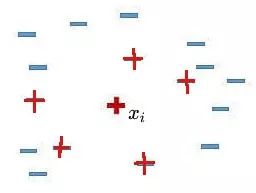
2).找出這個(gè)少數(shù)類(lèi)樣本的K個(gè)近鄰(假設(shè)K=5),5個(gè)近鄰已經(jīng)被圈出。
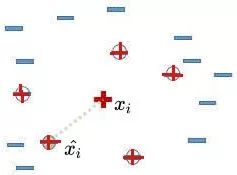
3).隨機(jī)從這K個(gè)近鄰中選出一個(gè)樣本(用綠色圈出來(lái)了)。
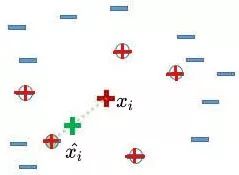
4).在少數(shù)類(lèi)樣本和被選中的這個(gè)近鄰樣本之間的連線(xiàn)上,隨機(jī)找一點(diǎn)。這個(gè)點(diǎn)就是人工合成的新的樣本點(diǎn)(綠色正號(hào)標(biāo)出)。
SMOTE算法摒棄了隨機(jī)過(guò)采樣復(fù)制樣本的做法,可以防止隨機(jī)過(guò)采樣中容易過(guò)擬合的問(wèn)題,實(shí)踐證明此方法可以提高分類(lèi)器的性能。但是SMOTE算法也存以下兩個(gè)缺點(diǎn):
1)由于對(duì)每個(gè)少數(shù)類(lèi)樣本都生成新樣本,因此容易發(fā)生生成樣本重疊的問(wèn)題。
2)在SMOTE算法中,出現(xiàn)了過(guò)度泛化的問(wèn)題,主要?dú)w結(jié)于產(chǎn)生合成樣本的方法。特別是,SMOTE算法對(duì)于每個(gè)原少數(shù)類(lèi)樣本產(chǎn)生相同數(shù)量的合成數(shù)據(jù)樣本,而沒(méi)有考慮其鄰近樣本的分布特點(diǎn),這就使得類(lèi)間發(fā)生重復(fù)的可能性增大。
解釋缺點(diǎn)2)的原因:結(jié)合前面所述的SMOTE算法的原理,SMOTE算法產(chǎn)生新的人工少數(shù)類(lèi)樣本過(guò)程中,只是簡(jiǎn)單的在同類(lèi)近鄰之間插值,并沒(méi)有考慮少數(shù)類(lèi)樣本周?chē)鄶?shù)類(lèi)樣本的分布情況。如3圖所示,綠色正號(hào)1、2分布在多數(shù)類(lèi)樣本周?chē)鼈冸x多數(shù)類(lèi)樣本最近,這就導(dǎo)致它們有可能被劃分成多數(shù)類(lèi)樣本。因此從3圖中可以看出,SMOTE算法的樣本生成機(jī)制存在一定的盲目性。
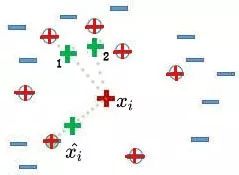
圖3:SMOTE算法結(jié)果
為了克服以上兩點(diǎn)的限制,多種不同的自適應(yīng)抽樣方法相繼被提出,其中具有代表性的算法包括Borderline-SMOTE算法。
擴(kuò)展閱讀:
Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of artificial intelligence research, 2002, 16: 321-357.
這篇論文提出了SMOTE算法。
(4)Borderline-SMOTE算法介紹
對(duì)于Borderline-SMOTE算法最感興趣的就是用于識(shí)別少數(shù)類(lèi)種子樣本的方法。在Borderline-SMOTE算法中,識(shí)別少數(shù)類(lèi)種子樣本的過(guò)程如下:
1)首先,對(duì)于每個(gè)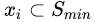 ,確定一系列最近鄰樣本集,成該數(shù)據(jù)集為
,確定一系列最近鄰樣本集,成該數(shù)據(jù)集為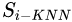 ,且
,且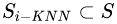 。
。
2)然后,對(duì)每個(gè)樣本,判斷出最近鄰樣本集中屬于多數(shù)類(lèi)樣本的個(gè)數(shù),即:
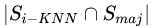 。
。
3)最后,選擇滿(mǎn)足下面不等式的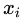 。
。
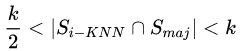
上面式子表明,只有最近鄰樣本集中多數(shù)類(lèi)多于少數(shù)類(lèi)的那些才會(huì)被選中形成“危險(xiǎn)集”(DANGER)。因此,DANGER集中的樣本代表少數(shù)類(lèi)樣本的邊界(最容易被錯(cuò)分的樣本)。然后對(duì)DANGER集中使用SMOTE算法在邊界附近產(chǎn)生人工合成少數(shù)類(lèi)樣本。
我們可以看出,如果 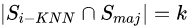 。即:的所有k個(gè)最近鄰樣本都屬于多類(lèi)。如4圖所示的樣本點(diǎn)C,我們就認(rèn)為樣本點(diǎn)C是噪聲且它不能生成合成樣本。
。即:的所有k個(gè)最近鄰樣本都屬于多類(lèi)。如4圖所示的樣本點(diǎn)C,我們就認(rèn)為樣本點(diǎn)C是噪聲且它不能生成合成樣本。
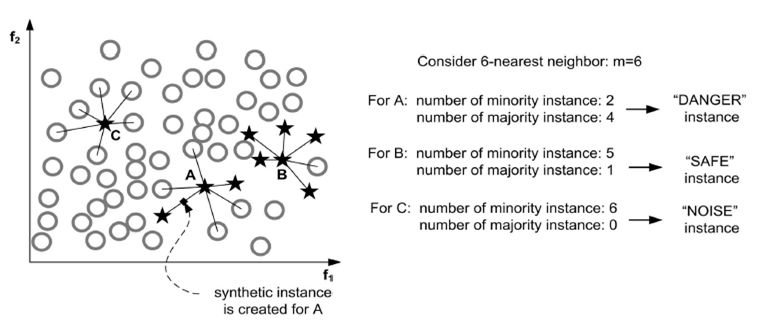
圖4:基于在邊界上樣本的數(shù)據(jù)建立
通過(guò)上面的介紹,我們對(duì)Borderline-SMOTE算法有了一定的了解。為了讓大家理解的更透徹這個(gè)算法,我再給大家畫(huà)一個(gè)流程圖,詳細(xì)介紹一下。
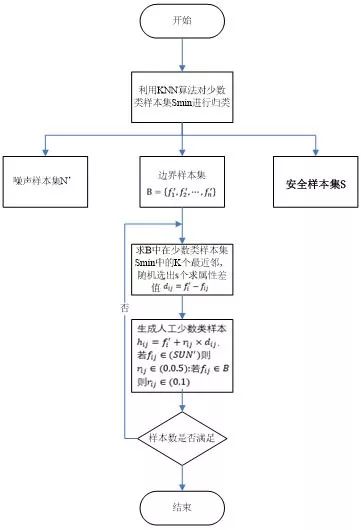
圖5:Borderline-SMOTE算法流程圖
流程圖5中,訓(xùn)練樣本集為F,少數(shù)類(lèi)樣本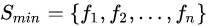 。
。
1)步驟一:
(i)計(jì)算少數(shù)類(lèi)樣本集中每一個(gè)樣本在訓(xùn)練集F中的k個(gè)最近鄰。
(ii)然后,根據(jù)這k個(gè)最近鄰對(duì)中的樣本進(jìn)行歸類(lèi):
假設(shè)這k個(gè)最近鄰都是多數(shù)類(lèi)樣本,則我們將該樣本定義為噪聲樣本,將它放在
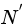 集合中。
集合中。反正k個(gè)最近鄰都是少數(shù)類(lèi)樣本則該樣本是遠(yuǎn)離分類(lèi)邊界的,將其放入S集合中。
最后,K個(gè)最近鄰即有多數(shù)類(lèi)樣本又有少數(shù)類(lèi)樣本,則認(rèn)為是邊界樣本,放入B集合中。
2)步驟二:
(i)設(shè)邊界樣本集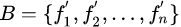 ,計(jì)算B集合中的每一個(gè)樣本
,計(jì)算B集合中的每一個(gè)樣本 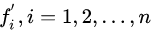 ,在少數(shù)類(lèi)樣本集中的K個(gè)最近鄰,組成集合
,在少數(shù)類(lèi)樣本集中的K個(gè)最近鄰,組成集合 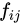 。
。
(ii)隨機(jī)選出s(1<s<n)個(gè)最近鄰。
(iii)計(jì)算出它們各自與該樣本之間的全部屬性的差值 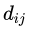 。
。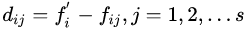 。
。
(iv)然后乘以一個(gè)隨機(jī)數(shù)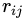 ,
,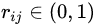 。如果
。如果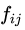 是集合或S集合中的樣本,則
是集合或S集合中的樣本,則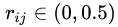 。
。
(v)最后生成的人工少數(shù)類(lèi)樣本為: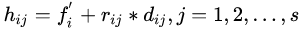 。
。
3)步驟三:
重復(fù)步驟2的過(guò)程,直到生成人工少數(shù)類(lèi)樣本的數(shù)目滿(mǎn)足要求,達(dá)到均衡樣本集的目的后結(jié)束算法。
擴(kuò)展閱讀:
Han H, Wang W Y, Mao B H. Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning[C]//International Conference on Intelligent Computing. Springer, Berlin, Heidelberg, 2005: 878-887.
這篇文章提出了Borderline-SMOTE算法。
2.3代價(jià)敏感學(xué)習(xí)(cost-sensitive learning)
(1)代價(jià)矩陣
采樣算法從數(shù)據(jù)層面解決不平衡數(shù)據(jù)的學(xué)習(xí)問(wèn)題;在算法層面上解決不平衡數(shù)據(jù)學(xué)習(xí)的方法主要是基于代價(jià)敏感學(xué)習(xí)算法(Cost-Sensitive Learning)。
在現(xiàn)實(shí)任務(wù)中常會(huì)遇到這樣的情況:不同類(lèi)型的錯(cuò)誤所造成的后果不同。例如在醫(yī)療診斷中,錯(cuò)誤地把患者診斷為健康人與錯(cuò)誤地把健康人診斷為患者,看起來(lái)都是犯了“一次錯(cuò)誤”,但是后者的影響是增加了進(jìn)一步檢查的麻煩,前者的后果卻可能是喪失了拯救生命的最佳時(shí)機(jī);再如,門(mén)禁系統(tǒng)錯(cuò)誤地把可通行人員攔在門(mén)外,將使得用戶(hù)體驗(yàn)不佳,但錯(cuò)誤地把陌生人放進(jìn)門(mén)內(nèi),則會(huì)造成嚴(yán)重的安全事故;在信用卡盜用檢查中,將正常使用誤認(rèn)為是盜用,可能會(huì)使用戶(hù)體驗(yàn)不佳,但是將盜用誤認(rèn)為是正常使用,會(huì)使用戶(hù)承受巨大的損失。為了權(quán)衡不同類(lèi)型錯(cuò)誤所造成的不同損失,可為錯(cuò)誤賦予“非均等代價(jià)”(unequal cost)。
代價(jià)敏感學(xué)習(xí)方法的核心要素是代價(jià)矩陣,如表1所示。其中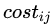 表示將第i 類(lèi)樣本預(yù)測(cè)為第j類(lèi)樣本的代價(jià)。一般來(lái)說(shuō),
表示將第i 類(lèi)樣本預(yù)測(cè)為第j類(lèi)樣本的代價(jià)。一般來(lái)說(shuō),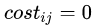 ;若將第0類(lèi)判別為第1類(lèi)所造成的損失更大,則
;若將第0類(lèi)判別為第1類(lèi)所造成的損失更大,則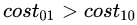 ;損失程度相差越大,
;損失程度相差越大,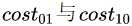 的值差別越大。當(dāng)相等時(shí)為代價(jià)不敏感的學(xué)習(xí)問(wèn)題。
的值差別越大。當(dāng)相等時(shí)為代價(jià)不敏感的學(xué)習(xí)問(wèn)題。
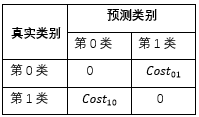
表1:代價(jià)矩陣
(2)代價(jià)敏感學(xué)習(xí)方法
基于以上代價(jià)敏感矩陣的分析,代價(jià)敏感學(xué)習(xí)方法主要有以下三種實(shí)現(xiàn)方式,分別是:
1).從學(xué)習(xí)模型出發(fā),對(duì)某一具體學(xué)習(xí)方法的改造,使之能適應(yīng)不平衡數(shù)據(jù)下的學(xué)習(xí),研究者們針對(duì)不同的學(xué)習(xí)模型如感知機(jī)、支持向量機(jī)、決策樹(shù)、神經(jīng)網(wǎng)絡(luò)等分別提出了其代價(jià)敏感的版本。以代價(jià)敏感的決策樹(shù)為例,可以從三個(gè)方面對(duì)其進(jìn)行改造以適應(yīng)不平衡數(shù)據(jù)的學(xué)習(xí),這三個(gè)方面分別是決策閾值的選擇方面、分裂標(biāo)準(zhǔn)的選擇方面、剪枝方面,這三個(gè)方面都可以將代價(jià)矩陣引入。
2).從貝葉斯風(fēng)險(xiǎn)理論出發(fā),把代價(jià)敏感學(xué)習(xí)看成是分類(lèi)結(jié)果的一種后處理,按照傳統(tǒng)方法學(xué)習(xí)到一個(gè)模型,以實(shí)現(xiàn)損失最小為目標(biāo)對(duì)結(jié)果進(jìn)行調(diào)整,優(yōu)化公式如下所示。此方法的優(yōu)點(diǎn)在于它可以不依賴(lài)所用的具體分類(lèi)器,但是缺點(diǎn)也很明顯,它要求分類(lèi)器輸出值為概率。
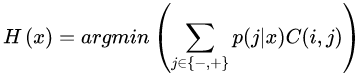
3).從預(yù)處理的角度出發(fā),將代價(jià)用于權(quán)重調(diào)整,使得分類(lèi)器滿(mǎn)足代價(jià)敏感的特性,下面講解一種基于Adaboost的權(quán)重更新策略AdaCost算法。
(3)AdaCost算法
要想了解AdaCost算法,我們得先知道Adaboost算法,如圖6所示。Adaboost算法通過(guò)反復(fù)迭代,每一輪迭代學(xué)習(xí)到一個(gè)分類(lèi)器,并根據(jù)當(dāng)前分類(lèi)器的表現(xiàn)更新樣本的權(quán)重,如圖中紅框所示,其更新策略為正確分類(lèi)樣本權(quán)重降低,錯(cuò)誤分類(lèi)樣本權(quán)重增大,最終的模型是多次迭代模型的一個(gè)加權(quán)線(xiàn)性組合。分類(lèi)越準(zhǔn)確的分類(lèi)器將會(huì)獲得越大的權(quán)重。

圖6:Adaboost算法
AdaCost算法修改了Adaboost算法的權(quán)重更新策略,其基本思想是對(duì)代價(jià)高的誤分類(lèi)樣本大大地提高其權(quán)重,而對(duì)于代價(jià)高的正確分類(lèi)樣本適當(dāng)?shù)亟档推錂?quán)重,使其權(quán)重降低相對(duì)較小。總體思想是代價(jià)高樣本權(quán)重增加得大降低的慢。其樣本權(quán)重按照如下公式進(jìn)行更新。其中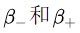 分別表示樣本被正確和錯(cuò)誤分類(lèi)情況下的
分別表示樣本被正確和錯(cuò)誤分類(lèi)情況下的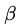 的取值。
的取值。
2.4不平衡學(xué)習(xí)的評(píng)價(jià)方法
(1)F1度量
這一部分涉及到模型的評(píng)價(jià)方法,如果你還沒(méi)有學(xué)習(xí)過(guò),可以看我的公眾號(hào)之前發(fā)的關(guān)于這部分文章。同時(shí),我也把鏈接地址貼出來(lái),供大家快速學(xué)習(xí)。
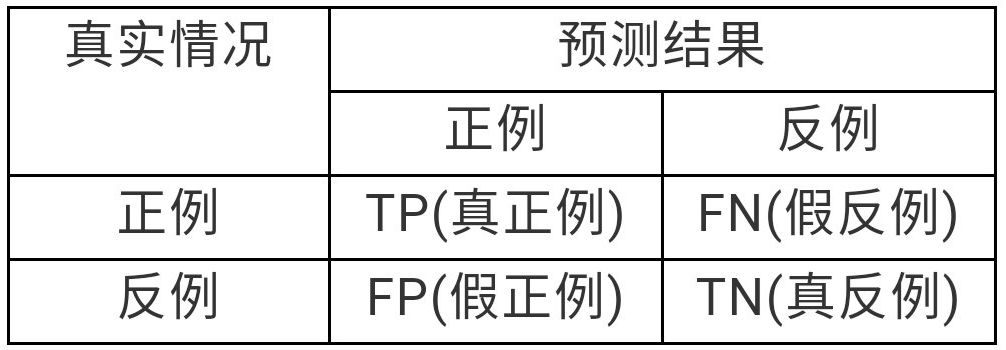
表2:分類(lèi)結(jié)果混淆矩陣
例如在癌癥預(yù)測(cè)的場(chǎng)景中,假設(shè)沒(méi)有患癌癥的樣本為正例,患癌癥的樣本為反例,反例占的比例很少(大概0.1%),如果直接把分類(lèi)器設(shè)置為預(yù)測(cè)都是正例,那么精度和查準(zhǔn)率的值都是99.9%。可見(jiàn)精度、錯(cuò)誤率和查準(zhǔn)率都不能表示不平衡數(shù)據(jù)下的模型表現(xiàn)。而F1值則同時(shí)考慮了少數(shù)類(lèi)的查準(zhǔn)率和召回率,因此能衡量不平衡數(shù)據(jù)下模型的表現(xiàn)。

(2)G-Mean
G-Mean是另外一個(gè)指標(biāo),也能評(píng)價(jià)不平衡數(shù)據(jù)的模型表現(xiàn),其計(jì)算公式如下。
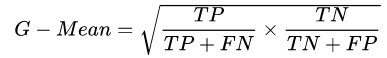
(3)ROC曲線(xiàn)和AUC面積
我的這篇文章把ROC曲線(xiàn)和AUC面積分析的全面。ROC曲線(xiàn)和AUC面積可以很好的評(píng)價(jià)不平衡數(shù)據(jù)的模型表現(xiàn)。
(1)在正負(fù)樣本都非常少的情況下,應(yīng)該采用數(shù)據(jù)合成的方式,例如:SMOTE算法和Borderline-SMOTE算法。
(2)在正負(fù)樣本都足夠多且比例不是特別懸殊的情況下,應(yīng)該考慮采樣的方法或者是加權(quán)的方法。
本文主要介紹了分類(lèi)中類(lèi)別不均衡時(shí)學(xué)習(xí)中常用的算法及評(píng)價(jià)指標(biāo),算法主要從數(shù)據(jù)和模型兩個(gè)層面介紹,數(shù)據(jù)層面的算法主要關(guān)于過(guò)采樣和欠采樣以及改進(jìn)的算法,模型方面主要講解了基于代價(jià)的敏感學(xué)習(xí)。評(píng)價(jià)指標(biāo)主要講解了F1度量、G-Mean和ROC曲線(xiàn)AUC面積。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~