
視覺分類任務(wù)中處理不平衡問題的loss比較

向AI轉(zhuǎn)型的程序員都關(guān)注了這個號??????
機器學(xué)習(xí)AI算法工程?? 公眾號:datayx
在計算機視覺(CV)任務(wù)里常常會碰到類別不平衡的問題, 例如:
1. 圖片分類任務(wù),有的類別圖片多,有的類別圖片少
2. 檢測任務(wù)。現(xiàn)在的檢測方法如SSD和RCNN系列,都使用anchor機制。訓(xùn)練時正負anchor的比例很懸殊.
3. 分割任務(wù), 背景像素數(shù)量通常遠大于前景像素。
從實質(zhì)上來講, 它們可以歸類成分類問題中的類別不平衡問題:對圖片/anchor/像素的分類。
再者,除了類不平衡問題, 還有easy sample overwhelming的問題。easy sample如果太多,可能會將有效梯度稀釋掉。
這兩個問題通常都會一起出現(xiàn)。如果不處理, 可能會對模型性能造成很大傷害。用Focal Loss里的話說,就是訓(xùn)練不給力, 且會造成模型退化:
(1) training is inefficient as most locations are easy negatives…
(2) the easy negatives can overwhelming training and lead to degenerate models.
如果要處理,那么該怎么處理呢?在CV領(lǐng)域里, 若不考慮修改模型本身, 通常會在loss上做文章, 確切地說,是在樣本選擇或loss weight上做文章。
常見的解決辦法介紹
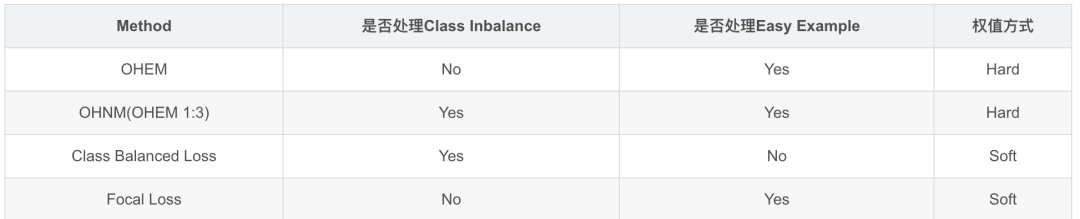
常見的方法有online的, 也有非online的;有只處理類間不平衡的,有只處理easy example的, 也有同時處理兩者的。
Hard Negative Mining, 非online的mining/boosting方法, 以‘古老’的RCNN(2014)為代表, 但在CV里現(xiàn)在應(yīng)該沒有人使用了(吧?)。若感興趣,推薦去看看OHEM論文里的related work部分。
Mini-batch Sampling,以Fast R-CNN(2015)和Faster R-CNN(2016)為代表。Fast RCNN在訓(xùn)練分類器, Faster R-CNN在訓(xùn)練RPN時,都會從N = 1或2張圖片上隨機選取mini_batch_size/2個RoI或anchor, 使用正負樣本的比例為1:1。若正樣本數(shù)量不足就用負樣本填充。使用這種方法的人應(yīng)該也很少了。從這個方法開始, 包括后面列出的都是online的方法。
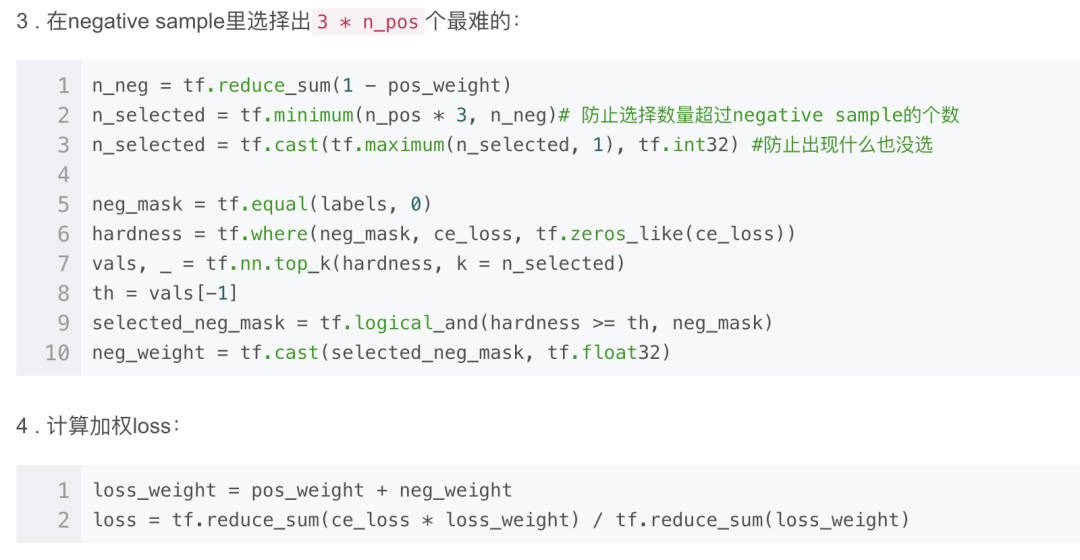
Online Hard Example Mining, OHEM(2016)。將所有sample根據(jù)當(dāng)前l(fā)oss排序,選出loss最大的N個,其余的拋棄。這個方法就只處理了easy sample的問題。
Oline Hard Negative Mining, OHNM, SSD(2016)里使用的一個OHEM變種, 在Focal Loss里代號為OHEM 1:3。在計算loss時, 使用所有的positive anchor, 使用OHEM選擇3倍于positive anchor的negative anchor。同時考慮了類間平衡與easy sample。
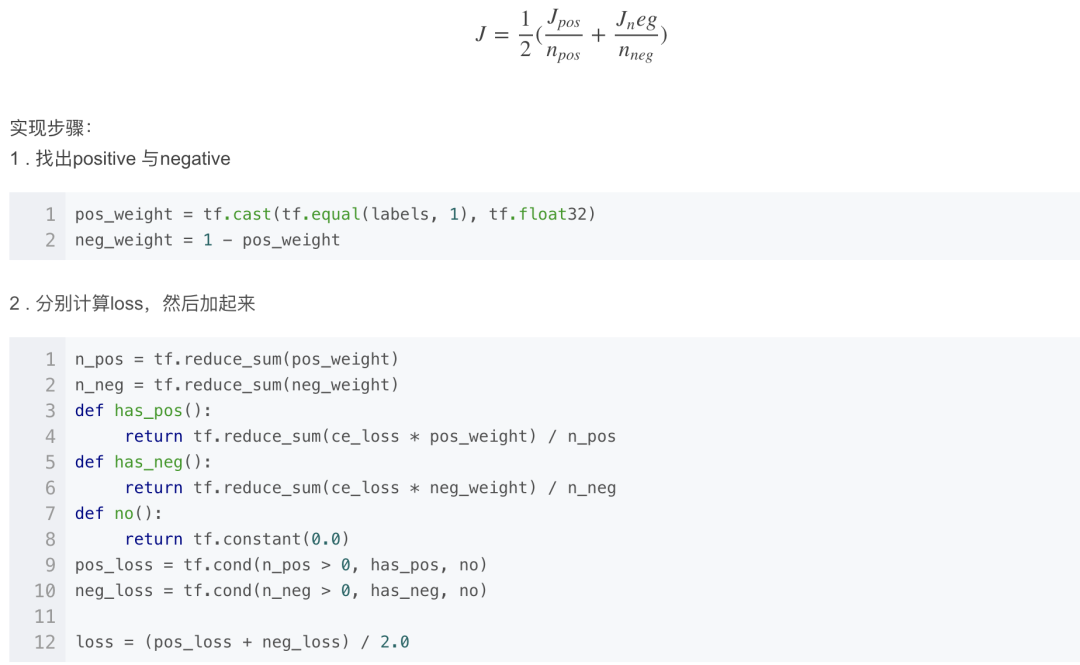
Class Balanced Loss。計算loss時,正負樣本上的loss分別計算, 然后通過權(quán)重來平衡兩者。暫時沒找到是在哪提出來的,反正就這么被用起來了。它只考慮了類間平衡。
Focal Loss(2017), 最近提出來的。不會像OHEM那樣拋棄一部分樣本, 而是和Class Balance一樣考慮了每個樣本, 不同的是難易樣本上的loss權(quán)重是根據(jù)樣本難度計算出來的。
從更廣義的角度來看,這些方法都是在計算loss時通過給樣本加權(quán)重來解決不平衡與easy example的問題。不同的是,OHEM使用了hard weight(只有0或1),而Focal Loss使用了soft weight(0到1之間).
現(xiàn)在依然常用的方法特性比較如下:
接下來, 通過修改過的Cifar數(shù)據(jù)集來比較這幾種方法在分類任務(wù)上的表現(xiàn),當(dāng)然, 主要還是期待Focal Loss的表現(xiàn)。
實驗數(shù)據(jù)
實驗數(shù)據(jù)集
Cifar-10, Cifar-100。使用Cifar的原因沒有別的, 就因為窮,畢竟要像Focal Loss論文里那樣跑那么多的大實驗對大部分學(xué)校和企業(yè)來說是不現(xiàn)實的。
處理數(shù)據(jù)得到類間不平衡
將多分類任務(wù)轉(zhuǎn)換成二分類:
new_label = label == 1
原始Cifar-10和100里有很多類別,每類圖片的數(shù)量基本一樣。按照這種方式轉(zhuǎn)變后,多分類變成了二分類, 且正負樣本比例相差懸殊:9倍和99倍。
實驗?zāi)P?/p>
一個5層的CNN,完成一個不平衡的二分類任務(wù)。使用Cross Entropy Loss,按照不同的方法使用不同的權(quán)值方案。以不加任何權(quán)重的CE Loss作為baseline。
衡量方式
在這種不平衡的二分類問題里, 準確率已經(jīng)不適合用來衡量模型的好與壞了。此處使用F-Score作標準.
實現(xiàn)細節(jié)
CE(Cross Entroy Loss)

OHEM

Class Balance CE


優(yōu)化方法
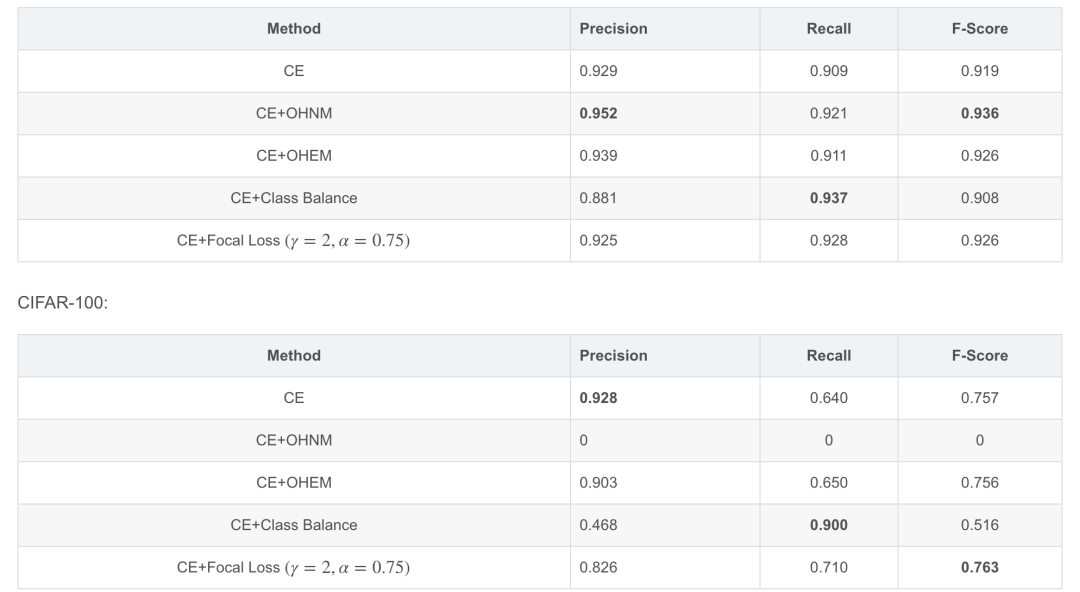
實驗結(jié)果

Focal Loss的一個補丁
對于CIFAR-100,batch_size=128時, 一個batch內(nèi)可能會一個positive sample都沒有, 即n_pos == 0, 這時,paper里用n_pos來normalize loss 的方式就不可行了。測試過兩種簡單的選擇:一是用所有weight之和來normalize, 二是直接不normalize。前者很難訓(xùn)練甚至訓(xùn)練不出來, 后者可用。所以上面的Focal loss計算代碼應(yīng)該補充為:

經(jīng)驗總結(jié)

Code Available On Github
https://github.com/dengdan/test_tf_models
Branch:focal_loss
References
Focal Loss for Dense Object Detection, https://arxiv.org/pdf/1708.02002.pdf
RCNN, https://arxiv.org/abs/1311.2524
Fast RCNN, http://arxiv.org/abs/1504.08083
Faster-RCNN, http://arxiv.org/abs/1506.01497
Training Region-based Object Detectors with Online Hard Example Mining, https://arxiv.org/abs/1604.03540
機器學(xué)習(xí)算法AI大數(shù)據(jù)技術(shù)
?搜索公眾號添加:?datanlp
長按圖片,識別二維碼
閱讀過本文的人還看了以下文章:
TensorFlow 2.0深度學(xué)習(xí)案例實戰(zhàn)
基于40萬表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測
《基于深度學(xué)習(xí)的自然語言處理》中/英PDF
《美團機器學(xué)習(xí)實踐》_美團算法團隊.pdf
《深度學(xué)習(xí)入門:基于Python的理論與實現(xiàn)》高清中文PDF+源碼
《深度學(xué)習(xí):基于Keras的Python實踐》PDF和代碼
python就業(yè)班學(xué)習(xí)視頻,從入門到實戰(zhàn)項目
2019最新《PyTorch自然語言處理》英、中文版PDF+源碼
《21個項目玩轉(zhuǎn)深度學(xué)習(xí):基于TensorFlow的實踐詳解》完整版PDF+附書代碼
《深度學(xué)習(xí)之pytorch》pdf+附書源碼
PyTorch深度學(xué)習(xí)快速實戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評分8.1,《機器學(xué)習(xí)實戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車行業(yè)完整知識圖譜項目實戰(zhàn)視頻(全23課)
李沐大神開源《動手學(xué)深度學(xué)習(xí)》,加州伯克利深度學(xué)習(xí)(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計學(xué)習(xí)方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》最新2018版中英PDF+源碼
重要開源!CNN-RNN-CTC 實現(xiàn)手寫漢字識別
同樣是機器學(xué)習(xí)算法工程師,你的面試為什么過不了?
前海征信大數(shù)據(jù)算法:風(fēng)險概率預(yù)測
【Keras】完整實現(xiàn)‘交通標志’分類、‘票據(jù)’分類兩個項目,讓你掌握深度學(xué)習(xí)圖像分類
VGG16遷移學(xué)習(xí),實現(xiàn)醫(yī)學(xué)圖像識別分類工程項目
特征工程(二) :文本數(shù)據(jù)的展開、過濾和分塊
如何利用全新的決策樹集成級聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競賽華人第1名團隊-深度學(xué)習(xí)與特征工程
不斷更新資源
深度學(xué)習(xí)、機器學(xué)習(xí)、數(shù)據(jù)分析、python
?搜索公眾號添加:?datayx??