
英偉達(dá)的這款GPU太強(qiáng)了!
點(diǎn)擊下方卡片,關(guān)注“CVer”公眾號(hào)
AI/CV重磅干貨,第一時(shí)間送達(dá)
今年 3 月 21 日 - 24 日舉辦的 NVIDIA GTC 2022 大會(huì)可謂是亮點(diǎn)十足。NVIDIA 不僅一口氣更新了 60 多個(gè) SDK 應(yīng)用程序,繼續(xù)加大在 Omniverse、機(jī)器人平臺(tái)、自動(dòng)駕駛和量子計(jì)算等領(lǐng)域中的布局 ,還重磅發(fā)布了基于全新 Hopper 架構(gòu)的 H100 GPU!
Amusi 聽說 H100 性能炸裂,應(yīng)用在 AI 領(lǐng)域上會(huì)有數(shù)倍的性能提升。那么本文就帶大家看看這一波刷屏的 Hopper 架構(gòu)和首款產(chǎn)品 H100 GPU 究竟有多強(qiáng)!據(jù)了解,NVIDIA H100 將于 2022 年第三季度起開始供貨,也期待能盡快上手實(shí)測一波~

圖1?NVIDIA H100 GPU
首款 Hopper 架構(gòu) GPU:H100
NVIDIA 每代 GPU 的架構(gòu)命名都是有出處的,今年 Hopper 架構(gòu)是以計(jì)算機(jī)科學(xué)家先驅(qū) Grace Murray Hopper 的姓氏命名(Hopper 為夫姓)。她是世界最早一批的程序員之一,也是最早的女性程序員之一,而且創(chuàng)造了現(xiàn)代第一個(gè)編譯器 A-0 系統(tǒng),以及第一個(gè)高級(jí)商用計(jì)算機(jī)程序語言 “COBOL” ,還被譽(yù)為 “COBOL 之母” ,據(jù)說是世界上第一個(gè)發(fā)現(xiàn)【bug】的人,debug 這個(gè)詞也因此誕生。

圖2?1960年在 UNIVAC 鍵盤前的 Hopper
一圖看盡 Hopper H100 GPU 上的六大項(xiàng)突破性創(chuàng)新:

圖3 H100 上的六大項(xiàng)突破性創(chuàng)新
集成超過 800 億個(gè)晶體管(臺(tái)積電 4nm 工藝)
Transformer Engine
第二代 MIG:多實(shí)例 GPU(Multi-Instance GPU)
NVIDIA 機(jī)密計(jì)算(Confidential Computing)
第四代 NVLink
全新 DPX 指令
NVIDIA H100 GPU 硬件上的參數(shù)太炸裂,比如有:英偉達(dá)定制的臺(tái)積電4nm工藝、單芯片設(shè)計(jì)、800 億個(gè)晶體管、132?組 SM、16896?個(gè) CUDA Core,528?個(gè)第四代Tensor Core,3TB/s 的 HBM3 顯存等等。
特別值得提一下:4 nm 工藝使得 H100 時(shí)鐘頻率速度增加了 1.3 倍,SM 數(shù)量增加了 1.2 倍。
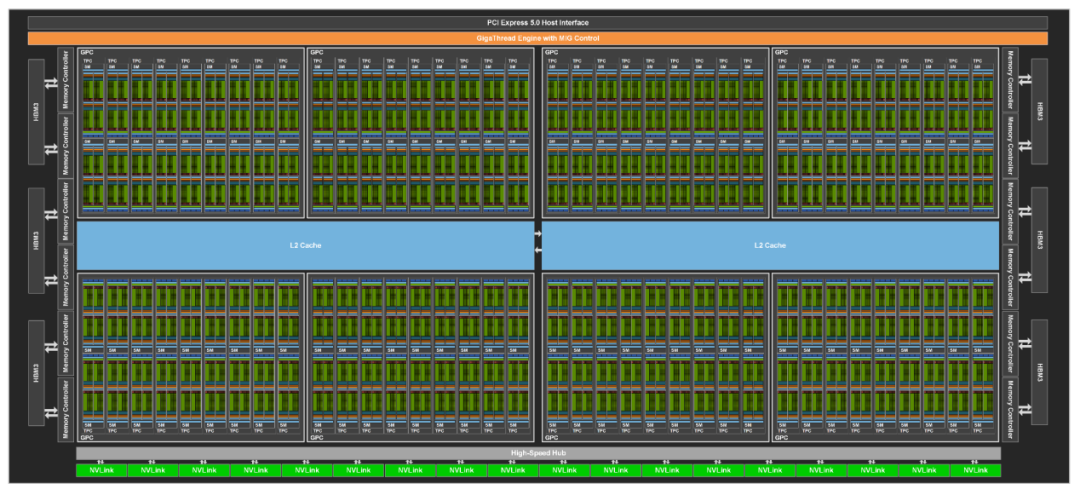
圖4?GH100 Full GPU with 144 SMs
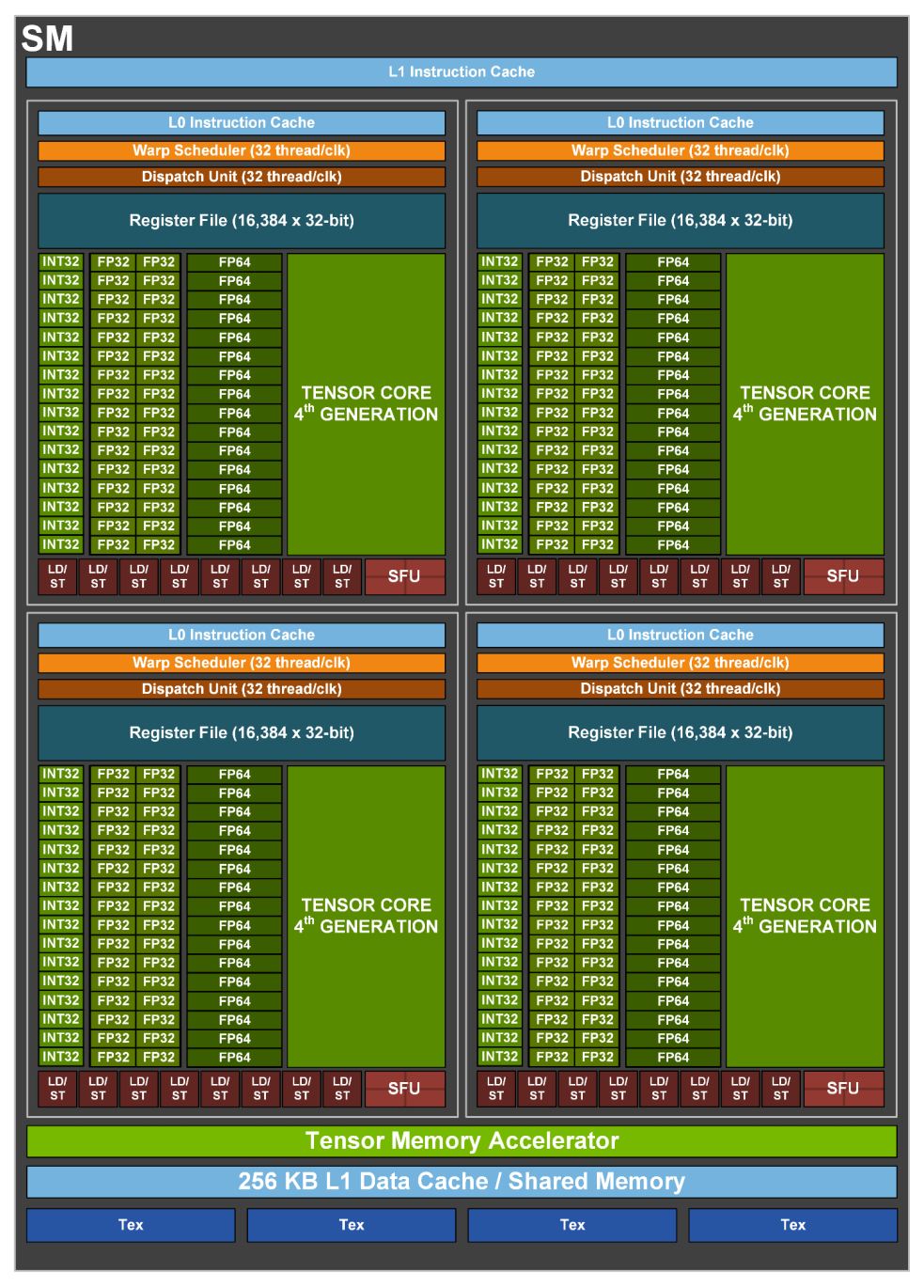
圖5?GH100 Streaming Multiprocessor (SM)
更多硬件參數(shù)這里就不展開說了,感興趣的同學(xué)可以直接看 NVIDIA H100 白皮書深入了解。這里重點(diǎn)介紹 NVIDIA H100 GPU 在 AI 上的性能突破。
與上一代 A100 相比,H100 的 AI 性能更加強(qiáng)大。在計(jì)算機(jī)視覺、自然語言處理等領(lǐng)域,H100 比 A100 的性能增強(qiáng)數(shù)倍,部分?jǐn)?shù)據(jù)如下圖所示:
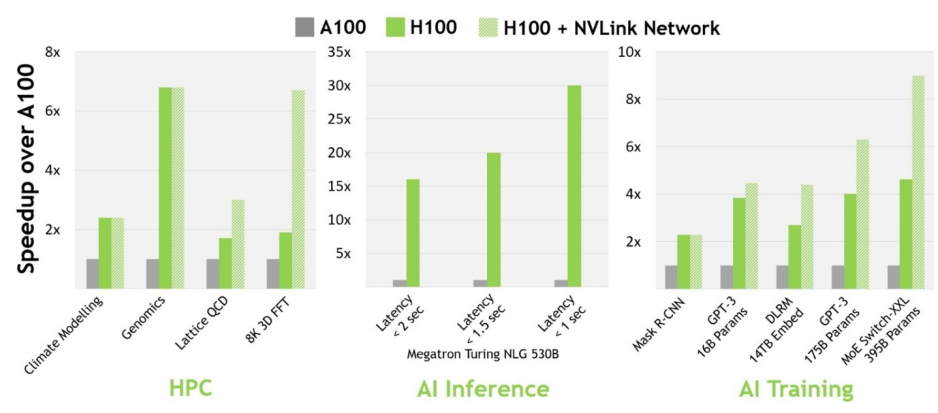
圖6 H100 實(shí)現(xiàn)?AI 和 HPC 突破
第四代 Tensor Core Architecture
第四代 Tensor Core 是 H100 AI 性能提升的一大神器!Tensor Core 是用于矩陣乘積和累加(MMA)數(shù)學(xué)運(yùn)算的專用高性能計(jì)算核心 ,可為人工智能(AI)高性能計(jì)算(HPC)提供突破性的性能加速。第一代 Tensor Core 首次出現(xiàn)在 Volta 架構(gòu),從 Volta 到 Turing、Ampere 再到2022 最新的 Hopper 架構(gòu),Tensor Core 已經(jīng)發(fā)展到了第四代。?
H100 GPU 中特別加入了 FP8 Tensor Core 來加速 AI 訓(xùn)練和推理。與上一代 A100 GPU(Ampere 架構(gòu))上的 FP16 相比,FP8 精度可提供高達(dá) 6 倍的性能。

圖7?H100 FP8 和 A100 FP16
FP8 Tensor Core 支持 FP32、FP16 累加器和兩種新的 FP8 輸入類型:E4M3 和 E5M2。E5M2 是與 FP16 保持相同的動(dòng)態(tài)范圍,但精度大大降低,而 E4M3 精度稍高但動(dòng)態(tài)范圍較小。Tensor Core 中的 FP8 matrix 可以累加成 FP16 或 FP32,并且根據(jù)神經(jīng)網(wǎng)絡(luò)中的偏差,進(jìn)一步輸出轉(zhuǎn)換為 FP8、BF16、FP16 或 FP32 格式。
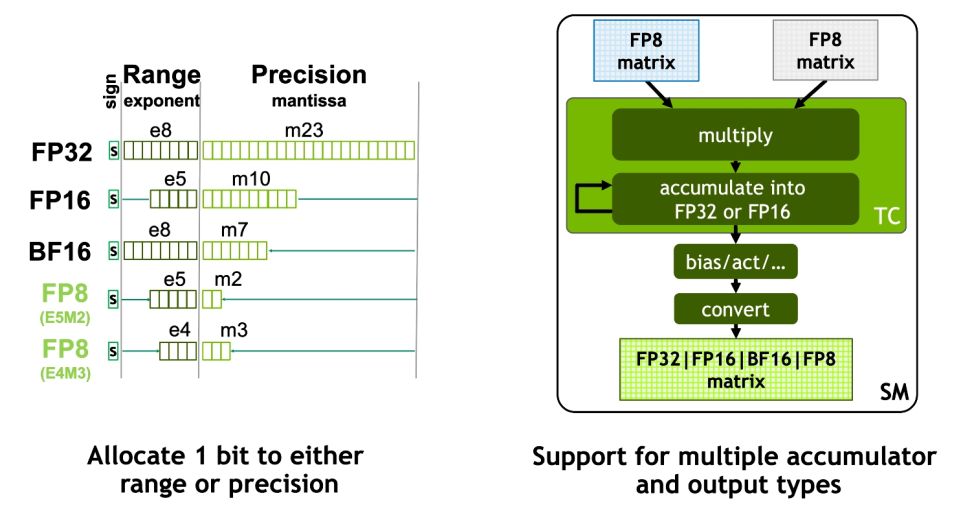
圖8? Hopper FP8
除了新增的 FP8 有恐怖的性能之外,第四代 Tensor Core 還整體加強(qiáng)了 FP16、FP64、TF32 和 INT8 等 Tensor Core。基本都是 3 倍及以上的性能提升,具體參數(shù)如下圖所示(太強(qiáng)了):
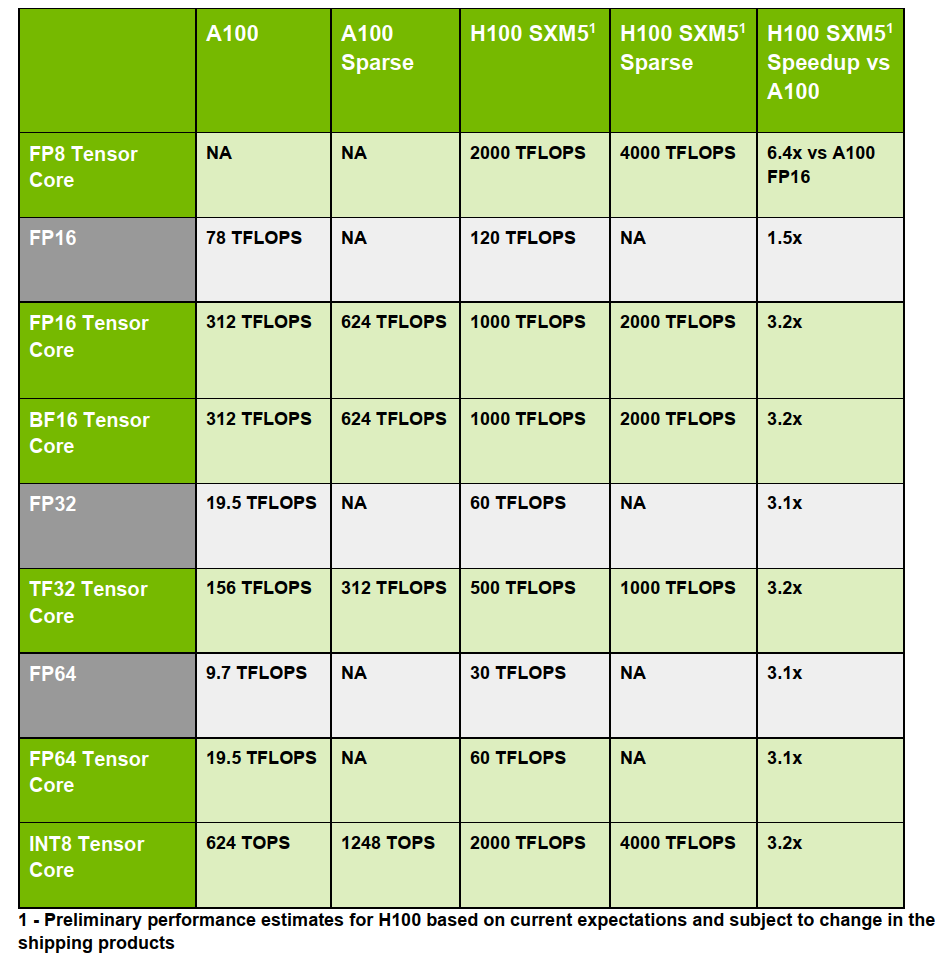
圖9? H100 和 A100 Tensor Core對(duì)比
Transformer Engine
這里要重點(diǎn)聊聊 NVIDIA H100 最新推出的 Transformer Engine!
先介紹一下 Transformer 是什么來頭?AI 領(lǐng)域的人應(yīng)該都知道,但還是要強(qiáng)調(diào)一下其重要性(不然也不會(huì)特別推出定制版的 Engine)。
2017 年,Transformer 橫空出世!快速席卷并統(tǒng)治了自然語言處理(NLP)領(lǐng)域;接著 2020 年,Vision Transformer 橫空出世,成功將 Transformer 應(yīng)用到了計(jì)算機(jī)視覺(CV)領(lǐng)域,目前也是屠榜了 CV 領(lǐng)域中的很多方向,比如目標(biāo)檢測、圖像分割、目標(biāo)跟蹤等;而且 Transformer 在音頻/語音、藥物發(fā)現(xiàn)等領(lǐng)域也都有廣泛應(yīng)用。
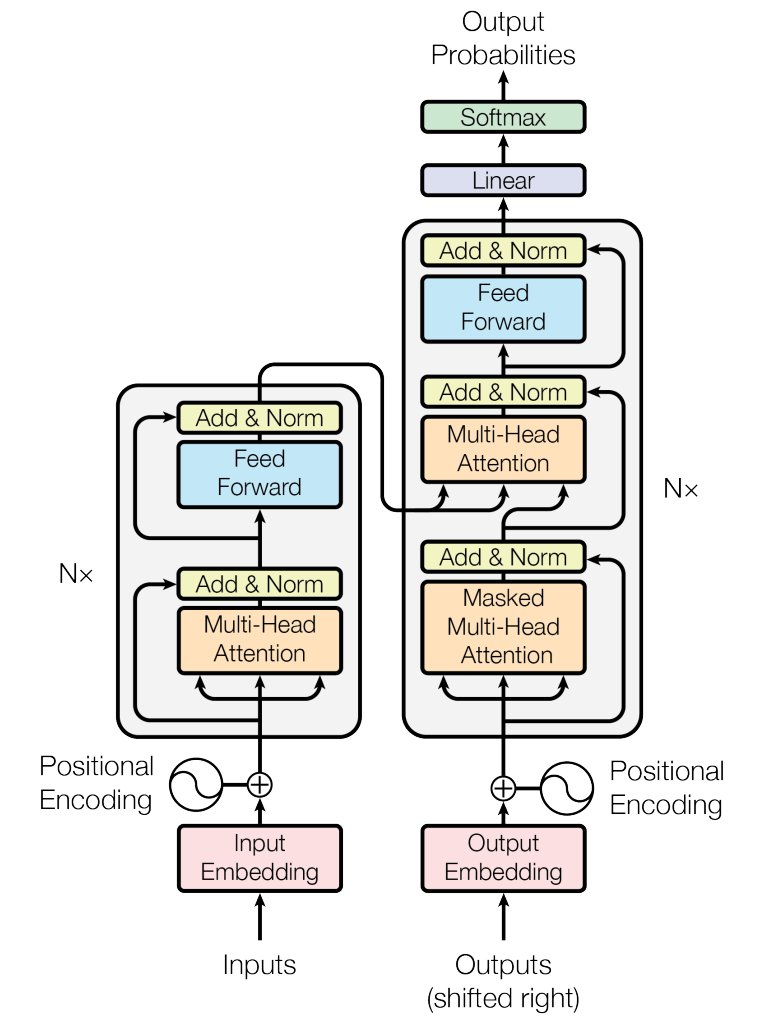
圖10?Transformer 架構(gòu)
可見 Transformer 已經(jīng)成為 AI 領(lǐng)域中舉足輕重的通用模型,但由于在過去五年中,Transformer 模型大小的增長速度比大多數(shù)其他 AI 模型快得多,每兩年接近增長 275 倍,所以 Transformer 網(wǎng)絡(luò)的訓(xùn)練時(shí)間會(huì)很長,而且部署應(yīng)用也會(huì)因?yàn)樗懔υ蚴艿胶艽笙拗啤?/span>
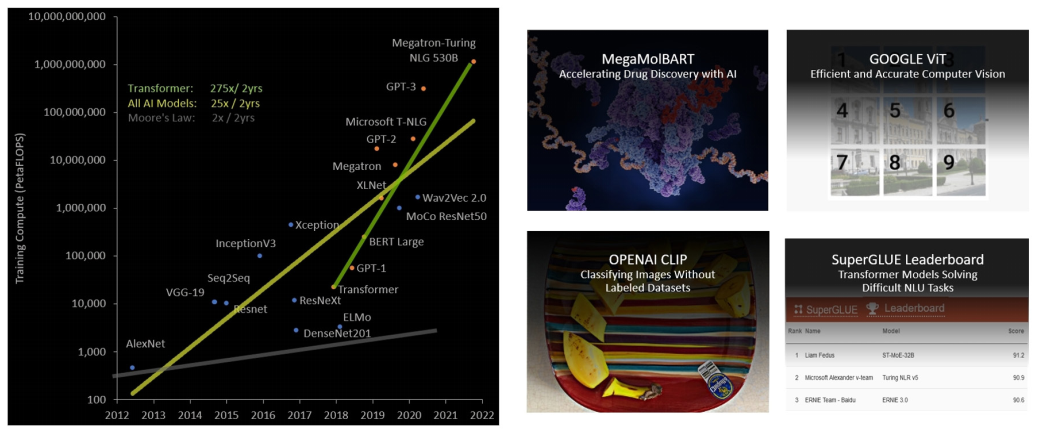
圖11?Transformer?模型大小呈指數(shù)增長
為此,NVIDIA 特別打造了 Transformer Engine:一項(xiàng)由軟件和定制的 Hopper Tensor Core 硬件相結(jié)合的專門用于加速 Transformer 模型計(jì)算的技術(shù)。Hopper Tensor Core 能夠利用混合的 FP8 和 FP16 精度格式,減少內(nèi)存使用,大幅加速 Transformer 訓(xùn)練的 AI 計(jì)算,同時(shí)保持準(zhǔn)確性。
具體工作原理:在 Transformer 模型的每一層,Transformer Engine 都會(huì)分析 Tensor Core 產(chǎn)生的輸出值的統(tǒng)計(jì)數(shù)據(jù)。了解了接下來會(huì)出現(xiàn)哪種類型的神經(jīng)網(wǎng)絡(luò)層以及它需要什么精度后,Transformer Engine 還會(huì)決定將 Tensor 轉(zhuǎn)換為哪種目標(biāo)格式,然后再將其存儲(chǔ)到內(nèi)存中。FP8 的范圍比其他數(shù)字格式更有限。為了優(yōu)化使用可用范圍,Transformer Engine 還使用從 Tensor 統(tǒng)計(jì)中計(jì)算出的縮放因子(Scaling Factors)動(dòng)態(tài)地將 Tensor 數(shù)據(jù)縮放到可表示的范圍內(nèi)。因此,每一層都在會(huì)其所需的范圍內(nèi)運(yùn)行,并以最佳方式加速。

圖12?Transformer Engine 概念操作
借助全新 Transformer Engine 和基本硬件參數(shù)提升使 H100 在大型語言模型上的 AI 訓(xùn)練速度提高了 9 倍,AI 推理速度提高了 30 倍。
下面舉幾個(gè)例子,1750 億參數(shù)的 GPT-3 訓(xùn)練時(shí)間從 5 天縮短至 19 個(gè)小時(shí);3950 億參數(shù)的混合專家模型訓(xùn)練時(shí)間從 7 天 縮短至 20 個(gè)小時(shí)。

圖12 GPT-3/MoE/Megatron?
上面介紹的第四代 Tensor Core 和 Transformer Engine 對(duì)于 H100 的計(jì)算性能(Compute Performance)提升尤為重要,如下圖所示:
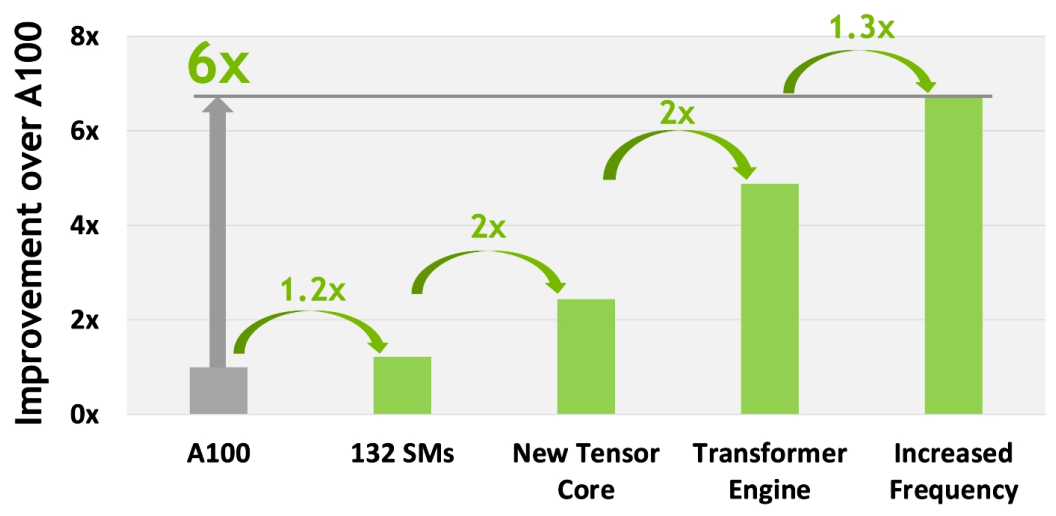
圖13 H100 計(jì)算性能改進(jìn)
DPX 指令
NVIDIA H100 新推出的 DPX 指令可以將動(dòng)態(tài)規(guī)劃(Dynamic Programming)的性能提高多達(dá) 7 倍,可大大加快疾病診斷、物流路徑優(yōu)化和縮短圖分析的時(shí)間。
下圖展示的兩個(gè)示例包括用于基因組學(xué)和蛋白質(zhì)測序的 Smith-Waterman 算法,以及用于為機(jī)器人車隊(duì)在動(dòng)態(tài)倉庫環(huán)境中尋找最佳路線的 Floyd-Warshall 算法。
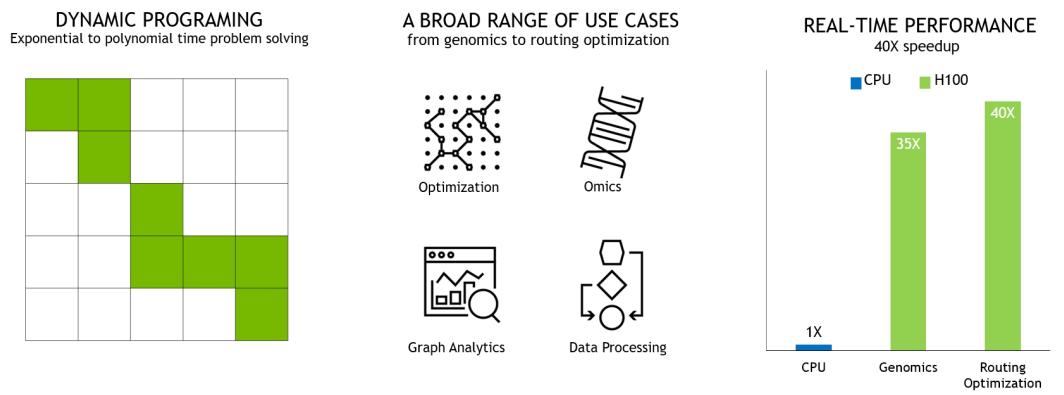
圖14?DPX 指令加速動(dòng)態(tài)規(guī)劃

圖15? 用于基因組測序的 Smith-Waterman 算法
第四代 NVLink 和 第三代 NVSwitch
NVLink 是 NVIDIA 開發(fā)的一種高帶寬、節(jié)能、低延遲、高速 GPU 互連技術(shù),能夠?qū)崿F(xiàn)顯存和性能擴(kuò)展。

圖16 NVIDIA NVLink
NVIDIA NVLink 第四代互連技術(shù)與上一代 NVLink 相比,通信帶寬增加了 50%。H100 包含 18 條第四代 NVLink 鏈路,可提供 900 GB/秒的總帶寬,是 PCIe Gen 5 帶寬的 7 倍。
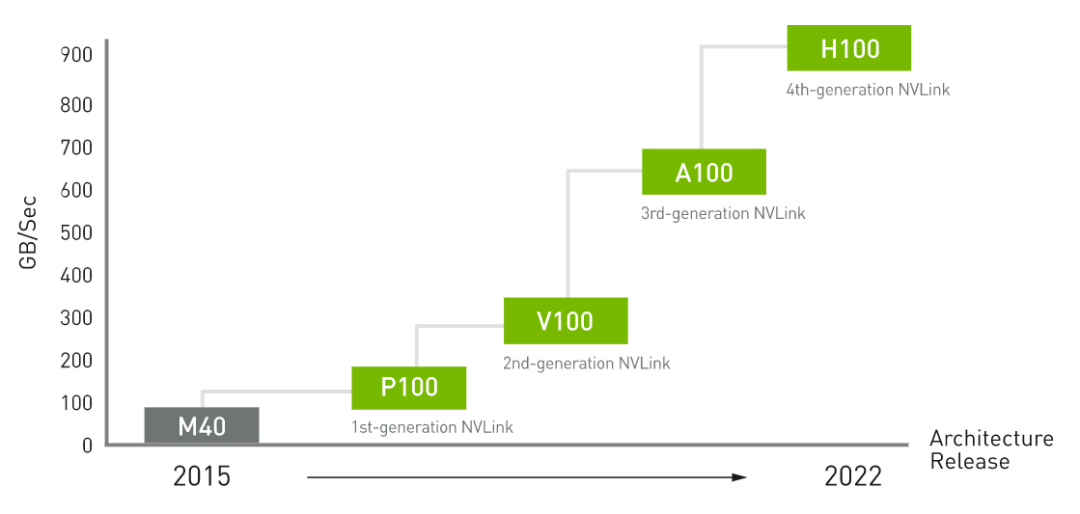
圖17?NVLink 性能改進(jìn)
第三代 NVSwitch 技術(shù)包括位于節(jié)點(diǎn)內(nèi)部和外部的交換機(jī),用于連接服務(wù)器、集群和數(shù)據(jù)中心環(huán)境中的多個(gè) GPU。每個(gè) NVSwitch 提供 64 ?個(gè)第四代 NVLink 鏈路端口,以加速多 GPU 連接。總交換機(jī)吞吐量從上一代的 7.2 Tbits/sec 增加到 13.6 Tbits/sec。新的第三代 NVSwitch 技術(shù)并配有 NVIDIA SHARP 引擎,可用于網(wǎng)絡(luò)內(nèi)歸約和組播加速。
新的 NVLink Switch System
為加速大型 AI 模型,可以將第四代 NVLink 和第三代 NVSwitch 結(jié)合以構(gòu)建 NVLink Switch System networks。最多支持連接 256 個(gè) H100 GPU(全新的NVIDIA SuperPOD 因此而生),實(shí)現(xiàn) 57.6 TB/s 的多對(duì)多總帶寬。而且新的 NVLink Switch System 在針對(duì)一些大型計(jì)算工作負(fù)載任務(wù),比如需要在多個(gè)GPU加速節(jié)點(diǎn)上進(jìn)行模型并行化時(shí),能夠通過互聯(lián)調(diào)整負(fù)載,可以再次提高性能。
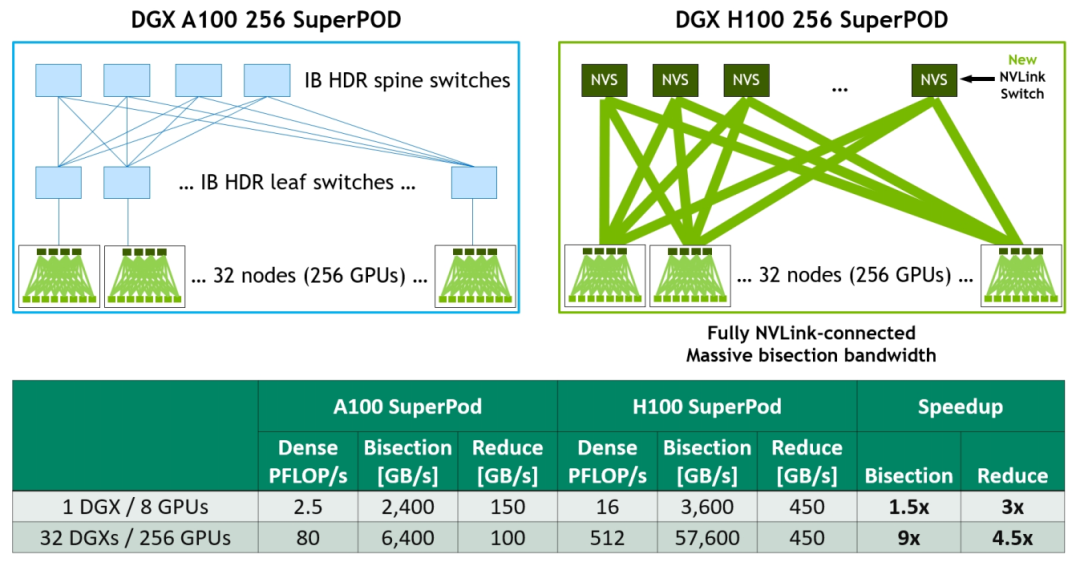
圖18?DGX A100 vs DGX H100 32-node, 256 GPU NVIDIA SuperPOD Comparison
下面再介紹幾款以 H100 為"基本單位" 構(gòu)建的大型 AI 計(jì)算產(chǎn)品。
NVIDIA DGX H100
NVIDIA DGX H100 是世界上第一個(gè)專用 AI 基礎(chǔ)架構(gòu)的第四代產(chǎn)品 ,也是一個(gè)專用于訓(xùn)練,推理和分析的通用高性能 AI 系統(tǒng),集成了 8 個(gè) NVIDIA H100 GPU, 擁有總計(jì) 6400 億個(gè)晶體管,總 GPU 顯存高達(dá) 640GB ,可滿足自然語言處理、深度學(xué)習(xí)推薦系統(tǒng)和醫(yī)療健康研究等大型工作負(fù)載的需求。

圖19?DGX H100
NVIDIA DGX H100 SuperPOD ?
專為企業(yè)級(jí) AI 設(shè)計(jì)的全新 DGX SuperPOD !預(yù)計(jì) 2022 年底即將推出!
DGX SuperPOD 由 32 個(gè) DGX H100 組成,被稱為“可擴(kuò)展單元”,共集成了 256 個(gè) H100 GPU,通過基于第三代 NVSwitch 技術(shù)的新的第二級(jí) NVLink 交換機(jī)連接,提供前所未有的 FP8 稀疏 AI 計(jì)算性能的 exaFLOP 。非常適合擴(kuò)展基礎(chǔ)架構(gòu),支持更大規(guī)模、更復(fù)雜的 AI 工作負(fù)載,例如使用 NVIDIA NeMo 的大型語言模型和深度學(xué)習(xí)推薦系統(tǒng)。

圖20?NVIDIA DGX H100 SuperPOD
NVIDIA Eos 全球最快 AI 超算
NVIDIA Eos 是目前世界上最快的人工智能超算(AI Supercomputer),共有 576 個(gè) DGX H100 系統(tǒng),4,608 個(gè) ?H100 GPU。NVIDIA Eos 預(yù)計(jì)將提供 18 exaflops 的 AI 計(jì)算性能,比目前世界上最快的系統(tǒng)日本的 Fugaku 超算快 4 倍的 AI 處理速度。

圖21?NVIDIA?Eos
總結(jié)和展望
基于全新 Hopper 架構(gòu)的 H100 GPU 算力再創(chuàng)新高!最新?lián)Q代的 TensorCore,最新推出的 FP8、Transformer Engine 等等創(chuàng)新都將助力 H100 在 AI 上的性能提升。
而且 H100 GPU 上面還有一些專項(xiàng)的增強(qiáng),比如專門針對(duì) Video 解碼的 NVDEC(支持 H264 / HEVC / VP9 等格式)和專門針對(duì) JPEG 解碼的 NVJPG (JPEG) Decode。NVDEC 和 NVJPG 可以大大提高計(jì)算機(jī)視覺數(shù)據(jù)在訓(xùn)練和推理過程中的處理性能(高速吞吐量)。H100 相較于上一代 A100 ,NVDEC 和 NVJPG 的解碼吞吐能力提高了2倍以上。
Amusi 相信 H100 GPU 可以進(jìn)一步推進(jìn) AI、元宇宙、自動(dòng)駕駛等領(lǐng)域的發(fā)展!也期待更優(yōu)秀的相關(guān)衍生產(chǎn)品和應(yīng)用!

整理不易,請(qǐng)點(diǎn)贊和在看![]()