
Oceanus的實(shí)時(shí)流式計(jì)算實(shí)踐與優(yōu)化

點(diǎn)擊可觀看精彩演講視頻
一、騰訊云流計(jì)算服務(wù)
今天的內(nèi)容主要分兩大部分:第一部分向大家快速介紹現(xiàn)在騰訊云上流式計(jì)算服務(wù)的基本情況,后一個(gè)較大的重點(diǎn)分為三個(gè)部分——我們?cè)趯?shí)時(shí)的業(yè)務(wù)過程中針對(duì)Flink SQL所遇到的技術(shù)上的痛點(diǎn)、在改造這些痛點(diǎn)的過程中所遇到的技術(shù)挑戰(zhàn),以及在整個(gè)實(shí)踐過程中所做的技術(shù)方案和內(nèi)容。
這是現(xiàn)在騰訊云實(shí)時(shí)計(jì)算服務(wù)的運(yùn)營(yíng)情況,目前在客戶方面我們既有內(nèi)部客戶,也有外部客戶。在外部客戶方面,像B站、叮咚買菜等互聯(lián)網(wǎng)公司都使用了我們的實(shí)時(shí)計(jì)算服務(wù)。內(nèi)部業(yè)務(wù)像比較重要的微信、QQ、QQ音樂、騰訊視頻等都已經(jīng)使用了我們的實(shí)時(shí)計(jì)算服務(wù)。目前整個(gè)實(shí)時(shí)計(jì)算的計(jì)算規(guī)模已經(jīng)超過了3萬(wàn)核,每天的數(shù)據(jù)接入量超過5PB,日實(shí)時(shí)計(jì)算量超過50萬(wàn)/次,而且這個(gè)規(guī)模還在不斷地增長(zhǎng)。

我們整個(gè)服務(wù)的研發(fā)方向也分為四塊:首先是想降低用戶在使用我們的計(jì)算服務(wù)以及開發(fā)他自己的Flink實(shí)時(shí)計(jì)算任務(wù)時(shí)的接入和學(xué)習(xí)成本,所以我們提供了一站式的開發(fā)平臺(tái)。同時(shí)用戶開發(fā)完自己的Flink job之后,可以直接在這個(gè)平臺(tái)上進(jìn)行線上測(cè)試,保證實(shí)時(shí)部署前的數(shù)據(jù)正確性。其次我們提供了一站式的部署功能,能夠讓實(shí)時(shí)的計(jì)算任務(wù)直接部署到騰訊云的TKE容器上。最后是運(yùn)維工具,任務(wù)部署到TKE之后,需要實(shí)時(shí)掌握實(shí)際運(yùn)營(yíng)情況,包括它的失敗告警以及實(shí)際的運(yùn)營(yíng)指標(biāo)等,我們提供了一系列的運(yùn)維工具,幫助用戶快速解決線上的問題。
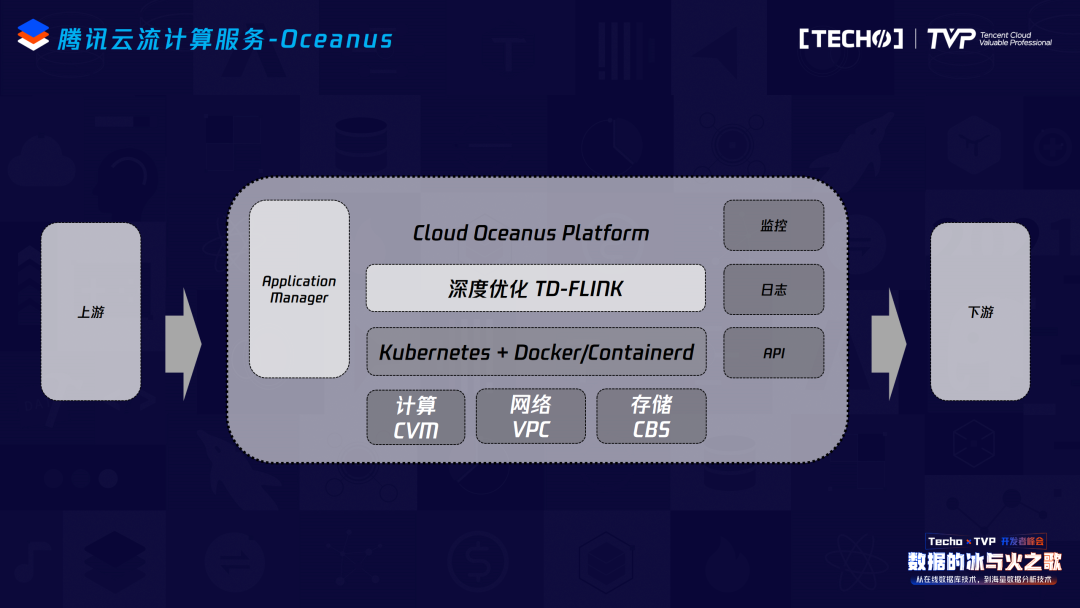
整個(gè)云上生態(tài)中,實(shí)時(shí)計(jì)算更多擔(dān)當(dāng)?shù)氖且粋€(gè)通道的角色,我們?cè)谏舷掠蔚纳鷳B(tài)和數(shù)據(jù)打通上花費(fèi)了非常多的精力,包括修復(fù)了社區(qū)connector相關(guān)的一些bug、基本能支持大數(shù)據(jù)生態(tài)和騰訊云上所有基本組件的數(shù)據(jù)打通,目前我們也已經(jīng)在內(nèi)部測(cè)試的CDC Source、ClickHouse 等connector,最近應(yīng)該會(huì)上線跟大家見面。
接下來的內(nèi)容是今天的重點(diǎn)——我們?cè)贔link SQL上所做的工作,在展開之前,我?guī)Т蠹铱焖倩仡橣link SQL的基本概念和情況。
二、Flink SQL概況
首先看Flink的編程模型,F(xiàn)link本身提供了三層編程模型供大家使用,最底層的是Data Stream和Data Set API,是一個(gè)java API,往上Table這一層是它基于類似于DSL的領(lǐng)域建模語(yǔ)言,再往上是它的Flink SQL,越往上它的抽象層次會(huì)越高,也就意味著用戶在使用不同的編程接口的時(shí)候,越往上所需要花費(fèi)的學(xué)習(xí)成本和接入成本會(huì)更低。所以在實(shí)際接入過程中還是希望用戶能夠使用我們的Flink SQL,因?yàn)楸旧鞸QL的特點(diǎn)也是非常明顯的,首先它是標(biāo)準(zhǔn)化的語(yǔ)言,不同背景的人員來使用SQL都能夠快速閱讀當(dāng)前這一段SQL所表達(dá)的業(yè)務(wù)邏輯,同時(shí)它底層跟計(jì)算引擎和版本可能都是解耦的,所以后續(xù)的版本升級(jí)、平臺(tái)遷移都是比較輕量級(jí)的。但是它也有它的不足之處,越往上抽象,它可能會(huì)流失一些基本的功能,即Flink SQL并沒有涵蓋到所有的DataStream或者說Flink原語(yǔ)的語(yǔ)義,所以我們也希望大家和社區(qū)一起共建這部分的能力。

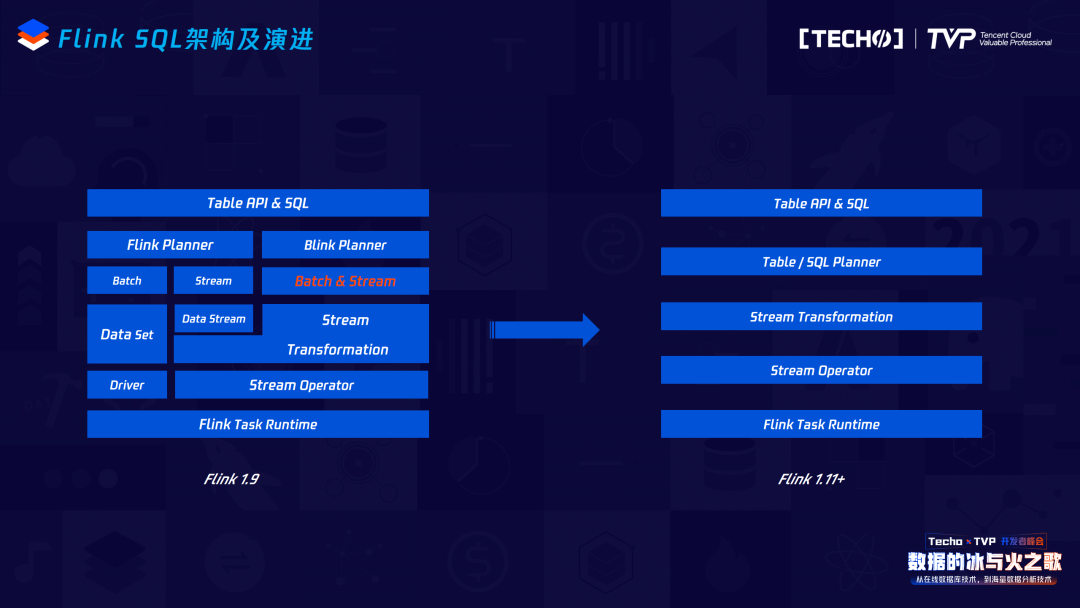
再看當(dāng)前Flink SQL的架構(gòu)及演進(jìn),這其實(shí)是Flink1.9和Flink1.9之后的變化,最主要的變化是在Flink1.9之前它經(jīng)過了Data Set或者Data Stream的一層轉(zhuǎn)換,也就是說轉(zhuǎn)成最終的Stream Graph時(shí),它會(huì)調(diào)用Data Stream或者Data Set的API;但是在Flink1.9之后,它其實(shí)把這一層拿掉了,即在SQL Node變成Stream Graph時(shí),用Stream Transformation就可以達(dá)到直接轉(zhuǎn)化Stream Graph。它的優(yōu)點(diǎn)顯而易見,抽掉了中間這一層,可以保證在做SQL優(yōu)化代碼和邏輯正確化優(yōu)化的規(guī)則上都可以共享,不再區(qū)分它的流與批。
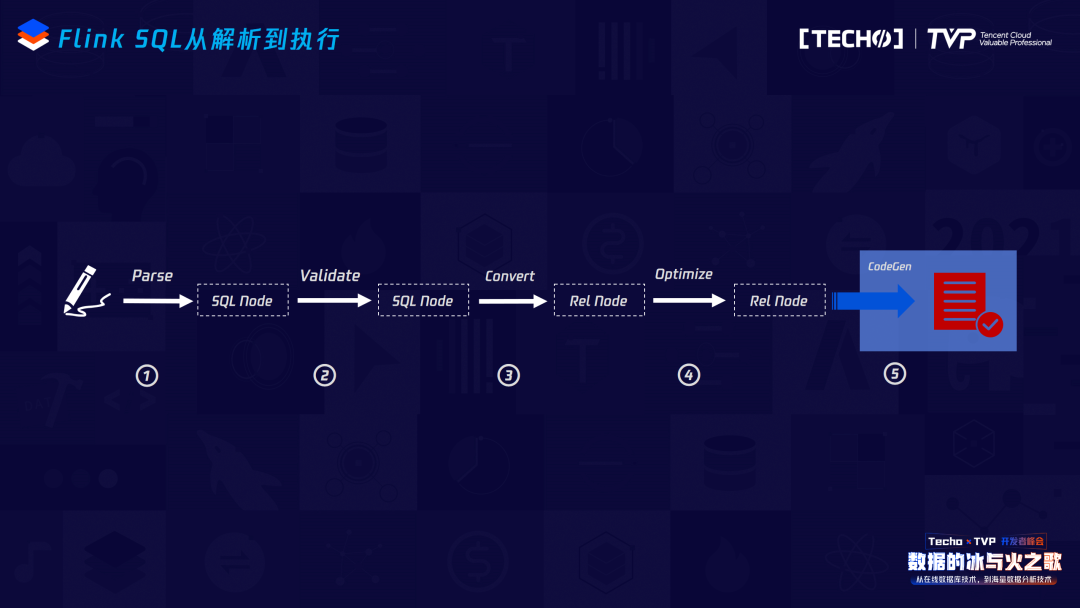
這是一條SQL從SQL文本轉(zhuǎn)成最終Flink Job的過程,主要分五步:第一步調(diào)Flink依賴?yán)锏腏avaCC,將這個(gè)文本轉(zhuǎn)成AST語(yǔ)法樹,也就是它的SQL Node,SQL Node后會(huì)調(diào)一個(gè)Validate接口,這里Validate的內(nèi)容就是SQL的一些元數(shù)據(jù),經(jīng)過這兩步之后就完成了一條SQL的語(yǔ)法分析和語(yǔ)義分析。再往后SQL Node會(huì)轉(zhuǎn)成Rel Node,最終會(huì)轉(zhuǎn)成Flink的Native Code,中間會(huì)做一些優(yōu)化,包括:邏輯執(zhí)行計(jì)劃優(yōu)化和物理執(zhí)行計(jì)劃優(yōu)化。最終的執(zhí)行計(jì)劃變成Native Code,中間我們有兩種方式去生成最終的Flink代碼,一種是通過一些規(guī)則的方式靜態(tài)地編碼,另外一種是如果邏輯比較靈活的話,可能需要通過動(dòng)態(tài)代碼生成技術(shù),將代碼生成架構(gòu)文件之后在內(nèi)存里進(jìn)行編譯,直接部署到Flink集群上。
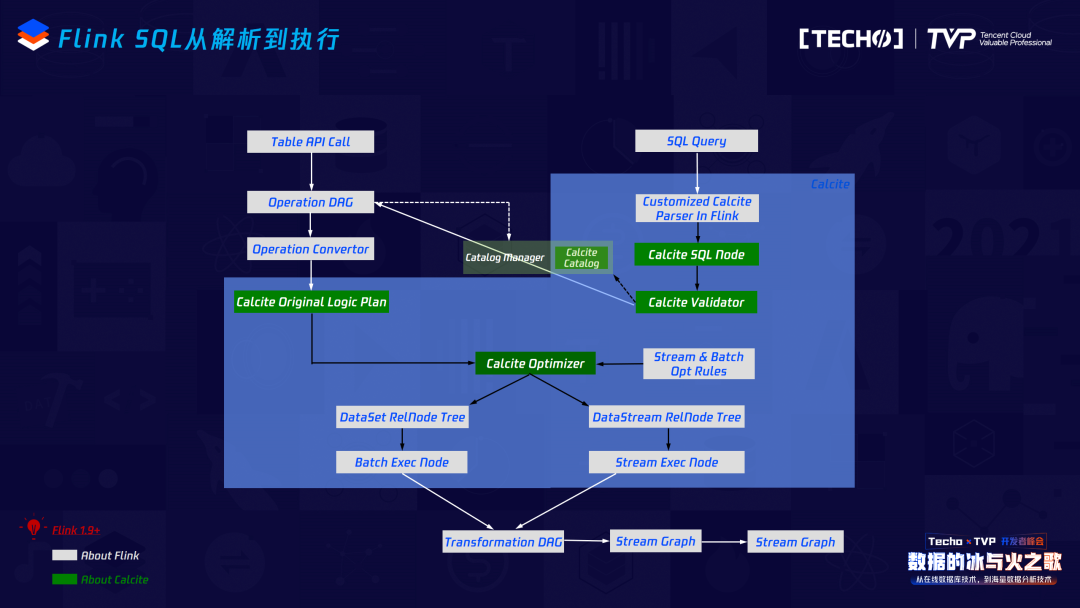
從這個(gè)圖,可以更詳細(xì)的看出Flink SQL從解析到執(zhí)行,跟不同模塊之間的互動(dòng)關(guān)系。同時(shí),跟Flink1.7不同的是,它從calcite交互出來之后不會(huì)再轉(zhuǎn)成SQL Node,而是直接變成Operation DAG,通過Operation Convertor會(huì)再轉(zhuǎn)成最開始的Logical plan,往后的優(yōu)化部分是一樣的,再往下它就不會(huì)再去調(diào)Data Stream或者Data Set API,而直接會(huì)變成Transformation DAG,最終轉(zhuǎn)成Stream Graph,這是整個(gè)的流程。
三、Flink SQL的痛點(diǎn)與挑戰(zhàn)
接下來是我們?cè)谡麄€(gè)接入過程中所遇到的一些痛點(diǎn)與技術(shù)挑戰(zhàn),總結(jié)起來痛點(diǎn)主要分為三個(gè)部分。
第一部分是SQL語(yǔ)法支持,因?yàn)闃?biāo)準(zhǔn)SQL已經(jīng)發(fā)展了很多年,但是Flink的項(xiàng)目快速發(fā)展也就這幾年的時(shí)間,所以Flink SQL的功能并沒有完全覆蓋到所有的標(biāo)準(zhǔn)SQL,比如你在MySQL寫一條SQL,想直接運(yùn)行在Flink上,可能有些語(yǔ)法是不能夠完全支持的,所以這一塊也需要跟社區(qū)一起不斷地去補(bǔ)齊和完善。另外一方面是它的語(yǔ)法不統(tǒng)一。因?yàn)榱魃系恼Z(yǔ)義本就非常復(fù)雜,不同的平臺(tái)語(yǔ)法也不同,包括Flink也有自己的“方言”,不同的版本之間Flink其實(shí)在快速的演進(jìn)過程中,做得也不是很好,所以在同一個(gè)功能上它的語(yǔ)法寫法也不一樣,這都帶來一些學(xué)習(xí)上的成本。
第二是功能覆蓋,對(duì)SQL來說,無(wú)法完全覆蓋Data Stream或者Data Set API的功能,還是要持續(xù)補(bǔ)齊Data Stream和Data Set的能力。Flink任務(wù)其實(shí)是一個(gè)DAG的組織圖,通過DAG的方式來表示不同算子之間的執(zhí)行順序,但是SQL語(yǔ)言從最開始發(fā)展到現(xiàn)在其實(shí)并不是很擅長(zhǎng)描述DAG,如果DAG非常復(fù)雜,想通過一個(gè)SQL去表達(dá)是非常困難,或者說基本上不可能的,當(dāng)前有一些方案,比如可以把一個(gè)復(fù)雜的DAG切分成多個(gè)SQL,通過視圖的方式把整個(gè)DAG組裝起來,但即使這樣做,如果SQL非常復(fù)雜,它的閱讀性和后續(xù)的擴(kuò)展性都是比較差的,所以這部分相對(duì)于Data Stream有比較多短板。
第三是運(yùn)維支撐,SQL的執(zhí)行性能包括三部分,第一部分是它的業(yè)務(wù)邏輯本身,第二部分是它的執(zhí)行計(jì)劃優(yōu)化,第三部分是執(zhí)行計(jì)劃轉(zhuǎn)換成Flink Native Code,后面這兩部分主要是平臺(tái)來?yè)?dān)當(dāng)優(yōu)化的角色,所以各家平臺(tái)技術(shù)上的實(shí)現(xiàn)都有各自的長(zhǎng)處,用戶能夠把控的優(yōu)化性能方向可能就是業(yè)務(wù)邏輯本身,如果想像Data Stream做一些精細(xì)化優(yōu)化,那SQL這一塊也是非常不足。即使現(xiàn)在我們提供一些參數(shù)的方式調(diào)優(yōu),也是基于平臺(tái)自己提供的一些能力才能做優(yōu)化,這是一個(gè)難點(diǎn),在平臺(tái)側(cè)和社區(qū)以后都要持續(xù)補(bǔ)齊。在問題定位方面,SQL翻譯成Flink job之后,它的運(yùn)行是一個(gè)整體,如果SQL非常復(fù)雜,其中的某一步或者是某一部分的邏輯不符合預(yù)期,復(fù)現(xiàn)這個(gè)問題就非常困難,因?yàn)楸旧碓诹魃蠌?fù)現(xiàn)問題都很困難,如果想分段去復(fù)現(xiàn),更是難上加難,所以后續(xù)也是需要不斷補(bǔ)齊能力,僅在內(nèi)核側(cè)做起來并不容易。
在難點(diǎn)方面,Stream SQL發(fā)展比較晚,針對(duì)它的標(biāo)準(zhǔn)比較少。擴(kuò)展一個(gè)SQL時(shí),其實(shí)我們不想去擴(kuò)展很多跟平臺(tái)或版本相關(guān)的SQL方言,因?yàn)檫@樣會(huì)帶來版本升級(jí)或平臺(tái)遷移的負(fù)擔(dān),所以在擴(kuò)展當(dāng)前的Flink SQL時(shí),我們還是希望遵循一些標(biāo)準(zhǔn),如果是SQL的標(biāo)準(zhǔn),那是最好的。另外是在語(yǔ)義方面,因?yàn)镾tream上的語(yǔ)義相對(duì)于Batch復(fù)雜很多,而且它有自己的一些特殊語(yǔ)義,比如窗口或排序,在流上和在批上實(shí)現(xiàn)這個(gè)能力,復(fù)雜程度完全不一樣,在流上會(huì)復(fù)雜特別多。
在性能優(yōu)化方面,要注意流上一些特有的特性。比如Retract機(jī)制,比如Flink自己也是一個(gè)帶State的操作,所以在優(yōu)化的時(shí)候都要結(jié)合State進(jìn)行,包括State交互和設(shè)計(jì)方案都要考慮。另外是在性能優(yōu)化的時(shí)候,現(xiàn)在整個(gè)執(zhí)行計(jì)劃轉(zhuǎn)變都是通過RBO的方式,如果要更準(zhǔn)確,其實(shí)通過CBO的方式會(huì)更貼切,但是在流上的統(tǒng)計(jì)信息收集和在批上完全不一樣,而且即使收集到了最新的統(tǒng)計(jì)信息,如果想去優(yōu)化當(dāng)前這一條SQL,有可能改變了當(dāng)前DAG的拓?fù)鋱D,有可能就沒辦法從原來的狀態(tài)恢復(fù),這些問題都是我們后續(xù)要解決的。
四、Flink SQL的優(yōu)化與擴(kuò)展
接下來展開我們?cè)贔link SQL上做的擴(kuò)展與優(yōu)化工作,其實(shí)優(yōu)化工作的方向是和前面業(yè)務(wù)的痛點(diǎn)一一對(duì)應(yīng)。
首先在擴(kuò)展語(yǔ)法方面,再?gòu)?qiáng)調(diào)一下,我們?cè)跀U(kuò)展語(yǔ)法的時(shí)候并不希望開發(fā)一些跟平臺(tái)或版本相關(guān)的方言,這樣會(huì)為后續(xù)的維護(hù)帶來非常大的負(fù)擔(dān),所以擴(kuò)展語(yǔ)法時(shí)還是會(huì)找一些和現(xiàn)有的SQL標(biāo)準(zhǔn)相符的SQL語(yǔ)法,比如現(xiàn)在的Windowing Table-valued Function,另一個(gè)是流與維表Join,也是遵循了標(biāo)準(zhǔn)SQL的寫法。在功能方面也是補(bǔ)齊我們的SQL和Data Stream之間的差距,目前包括我們的增量窗口、增強(qiáng)的Tumble窗口,還有可以指定任意字段作為時(shí)間屬性字段被窗口使用等功能。在性能方面我們也做了較多的工作,接下來要講的是Retraction優(yōu)化還有UDX函數(shù)內(nèi)聯(lián)優(yōu)化,比如一個(gè)UDX被調(diào)用多次,F(xiàn)link會(huì)被執(zhí)行多次,如果我們做一個(gè)簡(jiǎn)單的優(yōu)化,可以拿第一次的執(zhí)行結(jié)果直接代入后面的UDX調(diào)用鏈里,減少性能的損耗。我們做了一個(gè)Bucket Join,對(duì)于流與維表Join有較大的優(yōu)化,它不需要把維表的數(shù)據(jù)全部加載到內(nèi)存,這也是非常有用的。還有一個(gè)是Local Key By,也是借鑒了MapReduce,減少在這個(gè)階段的數(shù)據(jù)流動(dòng)。
1. 新增Table-Valued Function語(yǔ)法
接下來是Table-Valued Function。原始需求是這樣的:如果想在兩個(gè)流做一個(gè)Join,同時(shí)這個(gè)Join是在相同窗口內(nèi)的數(shù)據(jù)完成Join的,應(yīng)該怎么做?按照社區(qū)當(dāng)前的寫法,可能需要先做一個(gè)Join,再做Group by。可以看到它有兩個(gè)問題,首先它的語(yǔ)義模糊不清,因?yàn)槿绻茸鯦oin再做Group by,無(wú)法保證在做Join的時(shí)候數(shù)據(jù)在同一個(gè)窗口內(nèi);另外一個(gè)是在Flink上進(jìn)行SQL翻譯時(shí),不管是Join還是Window Group by,都要涉及到狀態(tài)的操作,所以我們先做Join,再做Window,涉及到兩次的狀態(tài)操作,同時(shí)Join狀態(tài)的清理沒辦法隨著Window的銷毀而銷毀,也就是Join狀態(tài)必須通過Flink TTL的方式來清理,對(duì)于當(dāng)前這個(gè)需求,如果只需要對(duì)相同窗口內(nèi)的數(shù)據(jù)做Join,那應(yīng)該是這個(gè)窗口銷毀了,所有的狀態(tài)都要被銷毀,所以如果用社區(qū)的SQL去寫也有問題。
經(jīng)過一些調(diào)研,我們發(fā)現(xiàn)在SQL2016里面有一個(gè)叫Table-Valued Function的語(yǔ)法,我們和calcite社區(qū)一起把Table-Valued Function進(jìn)行了落地,目前1.23版本之上已經(jīng)支持這個(gè)語(yǔ)法,而且我們內(nèi)部也把它實(shí)現(xiàn)到了Flink里。差異顯而易見,原來比如要寫一個(gè)Window,它會(huì)把這個(gè)Window信息放到Group字段里,但是通過這個(gè)語(yǔ)法我們把Window信息放到了From Source這一層,從這個(gè)SQL來看,它更貼近于標(biāo)準(zhǔn)SQL或者說批的這種寫法更適合具有數(shù)據(jù)分析背景的人員來理解。

再看下面的Logic Plan,它在下面進(jìn)行TableScan的時(shí)候,往上有一個(gè)TableFunctionScan,在轉(zhuǎn)變之后它加了兩個(gè)字段:Window start和Window Node,經(jīng)過這個(gè)Rel Node轉(zhuǎn)換后它的原始數(shù)據(jù)會(huì)被加上兩列,來表示這個(gè)數(shù)據(jù)是屬于哪個(gè)窗口。有了這個(gè)標(biāo)記后,我們要在流上再做這種Join就比較簡(jiǎn)單了——先描述兩個(gè)流屬于哪個(gè)窗口,直接再做Join,因?yàn)楸旧硭窃趦?nèi)部實(shí)現(xiàn)的,不需要去寫累贅的語(yǔ)法,所以如果想實(shí)現(xiàn)這個(gè)需求,就是非常簡(jiǎn)潔的一個(gè)語(yǔ)法,先構(gòu)造兩個(gè)具有Window窗口的Source,直接做Join就好。同時(shí)在多流上我們不僅僅實(shí)現(xiàn)了Join,而且在狀態(tài)操作中把Join和Window算子兩個(gè)的狀態(tài)操作合在一起,提升了執(zhí)行性能,我們還在流上支持交并差的操作。

針對(duì)這個(gè)語(yǔ)法我們還擴(kuò)展了很多其他非常有用的功能。第一是改寫了當(dāng)前Flink Group Window的寫法,改寫后更貼切標(biāo)準(zhǔn)SQL針對(duì)Group Window的寫法,原來的Group Window是要把Window信息放到Group字段里,但現(xiàn)在我們直接把Window信息放到Table里,意味著Table的Source已經(jīng)分了窗口,理解起來更直接。同時(shí)因?yàn)門able-Valued Function已經(jīng)把數(shù)據(jù)劃分了窗口,所以直接在當(dāng)前語(yǔ)法上實(shí)現(xiàn)窗口內(nèi)排序或者Top N輸出,這個(gè)語(yǔ)法也就顯得更加自然和容易。

我們最近也做了一個(gè)擴(kuò)展:自定義的Table-Valued Function,這個(gè)功能被非常多用戶提及,可以實(shí)現(xiàn)對(duì)于Source表M列轉(zhuǎn)N列的操作,意味著如果Source階段若只有兩列,下面計(jì)算的時(shí)候需要三列,那直接自定義一個(gè)Table-Valued Function就可以完成這個(gè)操作,而用現(xiàn)在的Flink SQL是完全做不到的。

2. 新增窗口類型
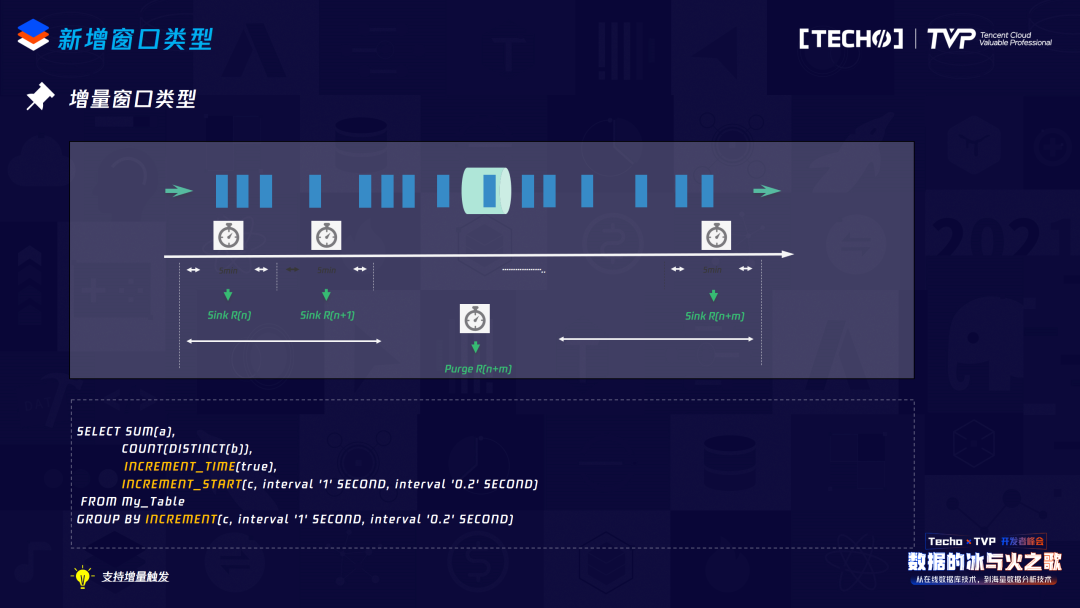
接下來是新增的兩個(gè)窗口類型,在實(shí)際生產(chǎn)過程中非常有用。一個(gè)叫增量窗口,它的需求背景非常直觀,比如要統(tǒng)計(jì)當(dāng)前某一個(gè)網(wǎng)頁(yè)一天內(nèi)的PV曲線,對(duì)于普通的Table Window,數(shù)據(jù)要發(fā)送到下游來描繪這個(gè)曲線,而必須等到整個(gè)窗口觸發(fā)之后才能收到數(shù)據(jù),因此曲線無(wú)法被描繪。其實(shí)它的實(shí)現(xiàn)機(jī)制也比較簡(jiǎn)單,我們可以自定義一個(gè)trigger,如果這個(gè)trigger到達(dá)了在SQL里定義的interval限制,就直接可以把當(dāng)前的Window State直接發(fā)送到下游,下游會(huì)接收到多次的數(shù)據(jù)來描繪當(dāng)前的PV曲線。在實(shí)際的生產(chǎn)過程中,我們又遇到了用戶提到的一個(gè)比較有用的功能:增量觸發(fā)。因?yàn)樵诤芏嗲闆r下,有些Group Key很長(zhǎng)一段時(shí)間內(nèi)當(dāng)前這個(gè)窗口和上一個(gè)窗口的觸發(fā)值是不變的,如果每一次都把這個(gè)數(shù)據(jù)觸發(fā)到下游,對(duì)下游的壓力也比較大,所以我們?cè)黾恿薒azy trigger,即當(dāng)前窗口的值如果不變,不需要往下游發(fā)送這個(gè)數(shù)據(jù),以減少下游的數(shù)據(jù)接收壓力。
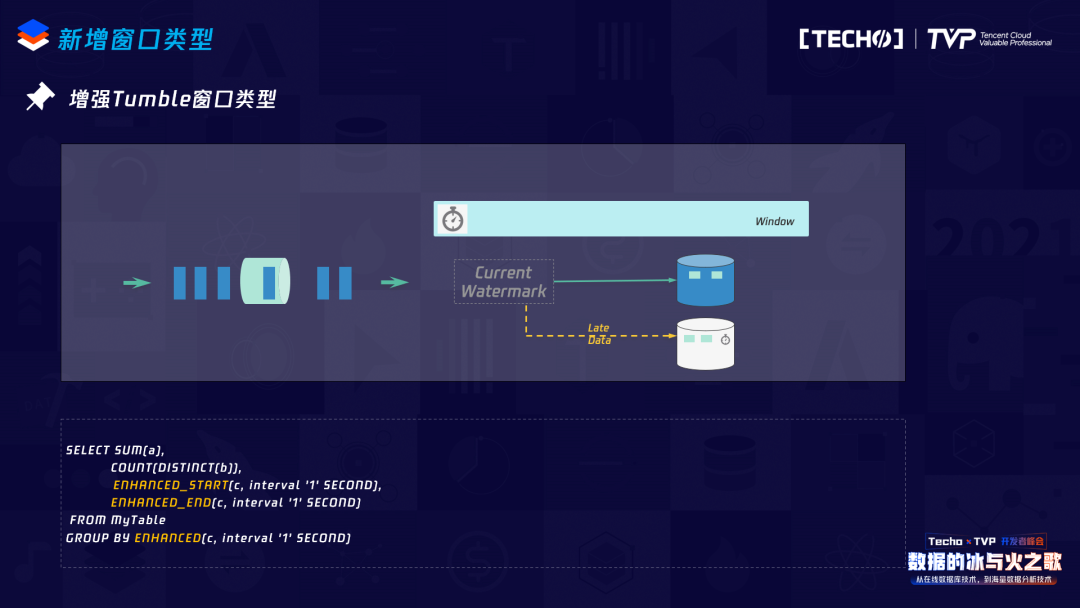
另外是增強(qiáng)Tumble窗口類型。用Data Stream寫過Flink job的同學(xué)應(yīng)該都知道,如果需要處理遲到數(shù)據(jù),我們可能要定義一個(gè)Side output,如果在SQL上想用Tumble Window去處理這個(gè)遲到數(shù)據(jù),目前的Tumble Window無(wú)法指定這個(gè)數(shù)據(jù)的輸出,所以我們?cè)黾恿艘粋€(gè)新的窗口類型,實(shí)現(xiàn)的機(jī)制不復(fù)雜,比如來的遲到數(shù)據(jù)會(huì)被放到另外一個(gè)State里面,我們會(huì)定義一個(gè)trigger,trigger的長(zhǎng)度就是當(dāng)前Tumble Window的長(zhǎng)度,即并不是來一條數(shù)據(jù)就往下游發(fā)送一條,而是經(jīng)過一段時(shí)間的匯聚,之后將這個(gè)匯聚的結(jié)果再發(fā)送到下游,這樣不僅能夠接收遲到的數(shù)據(jù),而且還能夠減少下游接收數(shù)據(jù)的壓力。這里有一點(diǎn)需要指出的:使用這個(gè)Window,對(duì)于下游來講如果是類似于K/V的HBase,要注意后面的遲到數(shù)據(jù)可能覆蓋前面的數(shù)據(jù),對(duì)于遲到數(shù)據(jù)一定是累加的,一旦覆蓋,整個(gè)結(jié)果就錯(cuò)了。
3. 回撤流性能優(yōu)化
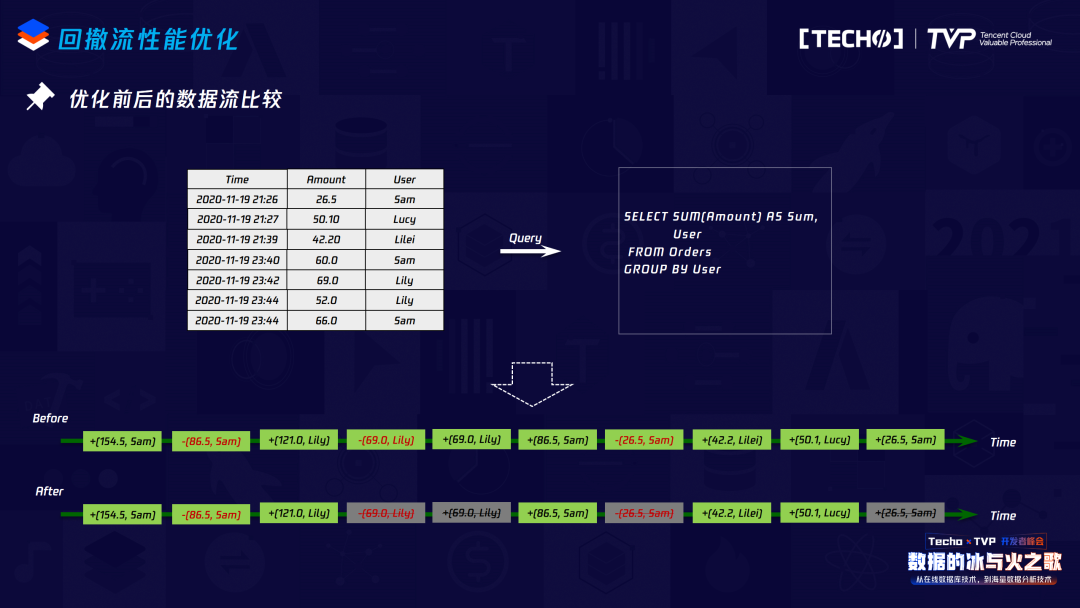
接下來是回撤流的機(jī)制,在Flink里如果寫一個(gè)SQL要保證整個(gè)邏輯的正確性,那回撤流是非常有用的。比如這個(gè)例子,它有兩層Group by,如果沒有回撤流機(jī)制,結(jié)果是錯(cuò)的。這個(gè)回撤流的作用是什么?在流上來一條數(shù)據(jù)都要向下游發(fā)送它的更新結(jié)果數(shù)據(jù),如果上游不停地來相同的Group key并向下游發(fā)送,更新結(jié)果覆蓋了之前的結(jié)果,那到了下游拿這個(gè)結(jié)果去更新就會(huì)出錯(cuò),所以像兩層Group by場(chǎng)景,應(yīng)該是要先把原來發(fā)送到下游的數(shù)據(jù)回撤,同時(shí)發(fā)送新的計(jì)算結(jié)果,具體的做法是在原始數(shù)據(jù)里加一個(gè)標(biāo)志,比如一個(gè)減號(hào),這個(gè)減號(hào)就告訴下游:“刪掉這個(gè)數(shù)據(jù),接下來我會(huì)送給你一個(gè)新的數(shù)據(jù),那才是當(dāng)前對(duì)Group key更新的結(jié)果。”
目前Flink的實(shí)現(xiàn)過程中,可以看到最壞的情況,是整個(gè)下游接收的數(shù)據(jù)應(yīng)該是原始數(shù)據(jù)的兩倍,在我們的優(yōu)化過程中發(fā)現(xiàn)完全沒有必要每來一條數(shù)據(jù)就向下游發(fā)送一條,因?yàn)檫@都要涉及State操作,而且如果Group by key較多,用Rocks DB作為state backend,Rocks DB會(huì)涉及IO的操作,性能得不到很好的保證,所以我們把它進(jìn)行CACHE或者說整個(gè)邏輯正確化的改寫。如果在Sink,其實(shí)也不需要每來一條數(shù)據(jù)就向下游發(fā)送一條,而且針對(duì)KV組件特別有用,KV組件本身是冪等的,不需要向下游發(fā)送Retract,直接支持Upsert,所以我們直接把新的Update信息發(fā)送給下游即可。
針對(duì)回撤流優(yōu)化的幾個(gè)實(shí)現(xiàn)方案,我列舉了比較有代表性的:
第一個(gè)是剛才SQL兩層Group by的場(chǎng)景,我們?cè)诘谝粚覩roup by向下游發(fā)送AGG結(jié)果時(shí),在上面進(jìn)行改寫:在中間加一個(gè)operator,做一個(gè)CACHE,這個(gè)CACHE也不是CACHE原始數(shù)據(jù),它會(huì)把數(shù)據(jù)進(jìn)行上面Window的操作,之后再發(fā)送給下游,這對(duì)于下游接收的數(shù)據(jù)量就會(huì)減少很多。
第二種場(chǎng)景是Sink場(chǎng)景,在Sink之前也可以做一個(gè)CACHE,這個(gè)CACHE保證之前的數(shù)據(jù)做累計(jì),向下游發(fā)送的時(shí)候并不是每來一條就發(fā)送一條,只有達(dá)到了這個(gè)CACHE的觸發(fā)條件,才會(huì)向下游發(fā)送數(shù)據(jù)。
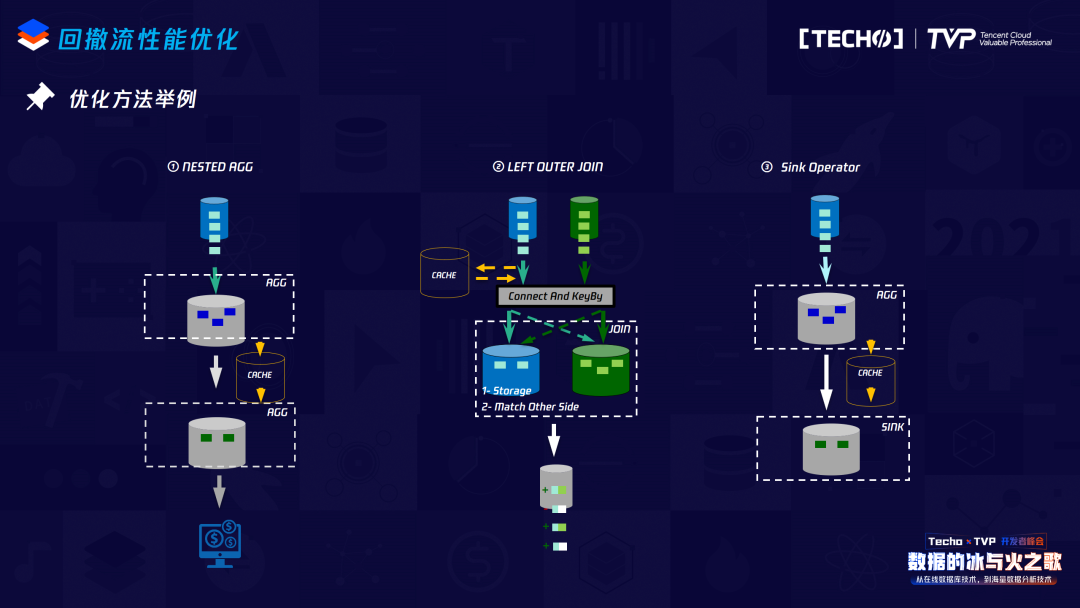
對(duì)于Outer Join的場(chǎng)景,會(huì)相對(duì)復(fù)雜一點(diǎn)。講Outer Join優(yōu)化之前,簡(jiǎn)單說明為什么這種Outer Join會(huì)產(chǎn)生回撤:因?yàn)樵诹魃献鰞蓚€(gè)流Join,如果是一個(gè)LEFT Join,左邊的數(shù)據(jù)先來,右邊的數(shù)據(jù)如果沒有匹配上,其實(shí)對(duì)于沒有匹配上的語(yǔ)義是有歧義的,到底是因?yàn)闆]有右邊的數(shù)據(jù),還是它遲到了?這些都需要做區(qū)分,所以為了保證Outer Join完整的語(yǔ)義,對(duì)于在Flink原始的實(shí)現(xiàn)方案,就需要首先向下游發(fā)送左邊的數(shù)據(jù)以左邊的流填充、右邊的數(shù)據(jù)以填充的那一條數(shù)據(jù)發(fā)送給下游,但此時(shí)如果又有右邊的數(shù)據(jù),Outer Join變成了Inner Join的邏輯,后面的數(shù)據(jù)又過來,首先要把前面發(fā)送給下游的這條數(shù)據(jù)回撤,同時(shí)向下游發(fā)送一條跟Inner Join一樣邏輯的數(shù)據(jù)。
經(jīng)過上面的分析,優(yōu)化思路也較直接。首先我們可以在左邊進(jìn)行一個(gè)CACHE,這個(gè)CACHE并不是無(wú)條件的,在CACHE之前先向右邊去做匹配的查詢,如果能匹配上,說明當(dāng)前對(duì)這條Join key是Inner Join的邏輯,它其實(shí)是不需要CACHE的,沒有必要犧牲實(shí)時(shí)處理的實(shí)時(shí)性來完成這個(gè)功能,直接向下游發(fā)送Inner Join的邏輯即可。如果右邊沒有數(shù)據(jù),就可以做一個(gè)有技術(shù)點(diǎn)設(shè)計(jì)的CACHE,比如在做相同key數(shù)據(jù)CACHE時(shí),不需要存儲(chǔ)所有的原始數(shù)據(jù),而是加一個(gè)字段表示當(dāng)前key相同的數(shù)據(jù),如果到達(dá)了觸發(fā)條件,就向下游發(fā)送跟這個(gè)相同的數(shù)據(jù)。同時(shí)如果左邊的數(shù)據(jù)跟右邊的數(shù)據(jù)匹配上了,對(duì)于相同的key,往后所有的數(shù)據(jù)沒有必要再做緩存,因?yàn)楫吘棺鲞@個(gè)CACHE是犧牲了一定的時(shí)效性而換來的。
來看優(yōu)化前后的結(jié)果對(duì)比,做完CACHE或Upset,向下游發(fā)送的數(shù)據(jù)量相對(duì)于沒有優(yōu)化之前減少很多,因?yàn)樽隽艘粋€(gè)合并。在內(nèi)部我們做了測(cè)試,如果CACHE的時(shí)間大小是兩分鐘,對(duì)于兩邊是100萬(wàn)條的數(shù)據(jù),同時(shí)下游是冪等組件,經(jīng)過優(yōu)化向下游接收的數(shù)據(jù)量有30倍的減少。如果是Inner Join,兩邊的數(shù)據(jù)量是完全隨機(jī)的,我們做了一個(gè)兩分鐘的CACHE,100萬(wàn)的數(shù)據(jù)有近20%的提升。
講師簡(jiǎn)介

杜立
騰訊大數(shù)據(jù)專家工程師
騰訊大數(shù)據(jù)專家工程師,Oceanus實(shí)時(shí)計(jì)算平臺(tái)研發(fā)負(fù)責(zé)人,2018年加入騰訊,一直從事于實(shí)時(shí)計(jì)算相關(guān)領(lǐng)域的研發(fā)工作,目前主要專注于騰訊云及內(nèi)部Flink SQL相關(guān)的擴(kuò)展與優(yōu)化,以及Oceanus產(chǎn)品化相關(guān)工作。
點(diǎn)擊觀看峰會(huì)的精彩總結(jié)視頻??
6月5日,Techo TVP 開發(fā)者峰會(huì) ServerlessDays China 2021,即將重磅來襲!
掃碼立即參會(huì)贏好禮??

