
如何使用HiveSQL進行OLAP分析
點擊上方“數據管道”,選擇“置頂星標”公眾號
干貨福利,第一時間送達

在線分析處理(OLAP,Online Analytical Processing)是通過帶層次的維度和跨維度進行多維分析的,簡單理解為一種多維數據分析的方式,通過OLAP可以展示數據倉庫中數據的多維邏輯視圖。在多維分析中,數據是按照維度(觀察數據的角度)來表示的,比如商品、城市、客戶。而維通常按層次(層次維度)組織的,如城市、省、國家,再比如時間也是有層次的,如天、周、月、季度和年。不同的管理者可以從不同的維度(視角)去觀察這些數據,這些在多個不同維度上對數據進行綜合考察的手段就是通常所說的數據倉庫多維查詢,最常見的就如上卷(roll-up)和下鉆(drill-down)了,所謂上卷,指的是選定特定的數據范圍之后,對其進行匯總統(tǒng)計以獲取更高層次的信息。所謂下鉆,指的是選定特定的數據范圍之后,需要進一步查看細節(jié)的數據。從另一種意義上說,鉆取就是針對多維展現的數據,進一步探究其內部的組成和來源。值得注意的是,上卷和下鉆要求維度具有層級結構,即數倉中所說的層次維度。
如何實現數據的多維分析
Hive提供了多維數據分析的函數,如GROUPING SETS,GROUPING_ID,CUBE,ROLLUP,通過這些分析函數,可以輕而易舉的實現多維數據分析。下面將會通過一個案例來了解這些函數的具體含義以及該如何使用這些函數。注意:在hive中使用這些函數之前,要確保開啟了map端聚合,即set hive.map.aggr=true,否則會報如下錯誤:

簡單介紹
GROUPING SETS
在一個group by查詢中,通過該子句可以對不同維度或同一維度的不同層次進行聚合,簡單理解為一條sql可以實現多種不同的分組規(guī)則,用戶可以在該函數中傳入自己定義的多種分組字段,本質上等價于多個group by語句進行UNION,對于GROUPING SETS子句中的空白集'()'表示對總體進行聚集。
示例模板
--?使用GROUPING?SETS查詢
SELECT?a,
???????b,
???????SUM(c)
FROM?tab1
GROUP?BY?a,b
GROUPING?SETS?((a,b),?a,b,?());
--?與GROUP?BY等價關系
SELECT?a,?b,?SUM(?c?)?FROM?tab1?GROUP?BY?a,?b
UNION
SELECT?a,?null,?SUM(?c?)?FROM?tab1?GROUP?BY?a,?null
UNION
SELECT?null,?b,?SUM(?c?)?FROM?tab1?GROUP?BY?null,?b
UNION
SELECT?null,?null,?SUM(?c?)?FROM?tab1;
GROUPING__ID
當使用聚合時,有時候會出現數據本身為null值,很難區(qū)分究竟是數據列本身為null值還是聚合數據行為null,即無法區(qū)分查詢結果中的null值是屬于列本身的還是聚合的結果行,因此需要一種方法識別出列中的null值。grouping_id 函數就是此場景下的解決方案。注意該函數是有兩個下劃線。這個函數為每種聚合數據行生成唯一的組id。它的返回值看起來像整型數值,其實是字符串類型,這個值使用了位圖策略(bitvector,位向量),即它的二進制形式中的每一位表示對應列是否參與分組,如果某一列參與了分組,對應位就被置為1,否則為0。通過這種方式可以區(qū)分出數據本身中的null值。看到這是不是還是一頭霧水,沒關系,來看下面的示例:
--?創(chuàng)建表
create?table?test_grouping__id(id?int,amount?decimal(10,2));
--?插入數據
insert?into?table?test_grouping__id?values(1,null),(1,1),(2,2),(3,3),(3,null),(4,5);
--執(zhí)行查詢
SELECT?id,
???????amount,
???????grouping__id,
???????count(*)?cnt
FROM?test_grouping__id
GROUP?BY?id,
?????????amount
GROUPING?sets(id,(id,amount),())
ORDER?BY?grouping__id
查詢結果分析
查詢結果如下圖所示:綠色框表示未進行分組,即進行全局聚合,grouping_id等于0,表示沒有字段參與分組。藍色框表示按照id進行分組,對應的grouping_id為1,表示只有一個字段參與了分組。橘色的框表示按照id和amount兩個字段進行分組,grouping_id為3,即有兩個字段參與了分組,轉成十進制為2^0 + 2^1 ?= 3。
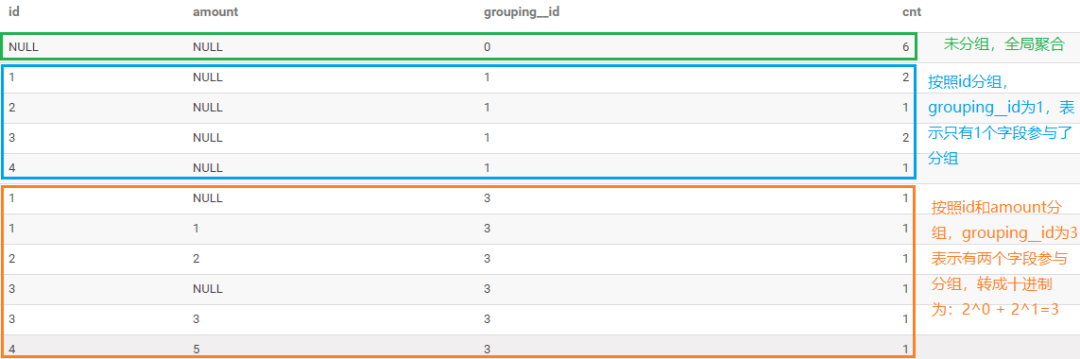
以上面為例,分組字段為id、amount,轉成二進制表示形式為:

ROLLUP
通用的語法為WITH ROLLUP,需要與group by一起用于在維的層次結構級別上計算聚合。功能為可以按照group by的分組字段進行組合,計算出不同分組的結果。注意對于分組字段的組合會與最左邊的字段為主。使用ROLLUP的GROUP BY a,b,c假定層次結構是“ a”向下鉆取到“ b”,“ b”向下鉆取到“ c”。則可以通過GROUP BY a,b,c,WITH ROLLUP進行實現,該語句等價于GROUP BY a,b,c GROUPING SETS((a,b,c),(a,b),(a),())。即使用WITH ROLLUP,首先會對全局聚合(不分組),然后會按GROUP BY字段組合,進行聚合,但是最左側的分組字段必須參與分組,比如a字段是最左側的字段,則a必定參與分組組合。
示例模板
--?使用WITH?ROLLUP查詢
SELECT?a,
???????b,
???????c
???????SUM(d)
FROM?tab1
GROUP?BY?a,b,c
WITH?ROLLUP
--?等價于下面的方式
SELECT?a,
???????b,
???????c,
???????SUM(d)
FROM?tab1
GROUP?BY?a,b,c
GROUPING?SETS?((a,b,c),?(a,b),?(a),());
CUBE
CUBE表示一個立方體,apache的kylin使用就是這種預計算方式。即會對給定的維度(分組字段)進行多種組合之后,形成不同分組規(guī)則的數據結果。一旦我們在一組維度上計算出CUBE,就可以得到這些維度上所有可能的聚合聚合結果。比如:GROUP BY a,b,c WITH CUBE,等價于GROUP BY a,b,c GROUPING SETS((a,b,c),(a,b),(b,c), (a,c),(a),(b),(c),())。
其實,可以將上面的情況抽象成排列組合的問題,即從分組字段集合(假設有n個字段)中隨意取出0~n個字段,那么會有多少中組合方式,如下面公式所示:
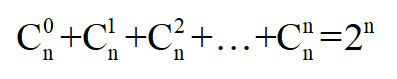
結合上面的例子,GROUP BY a,b,c WITH CUBE,那么所有的組合方式有:(a,b,c),(a,b),(b,c), (a,c),(a),(b),(c),(),一共有8種組合,即2^3 = 8。
示例模板
--?使用WITH?CUBE查詢
SELECT?a,
???????b,
???????c
???????SUM(d)
FROM?tab1
GROUP?BY?a,b,c
WITH?CUBE
--?等價于下面的方式
SELECT?a,
???????b,
???????c,
???????SUM(d)
FROM?tab1
GROUP?BY?a,b,c
GROUPING?SETS?((a,b,c),(a,b),(b,c),?(a,c),(a),(b),(c),());
使用案例
數據準備
有一份用戶行為數據集,包括用戶的所有行為(包括pv點擊、buy購買、cart加購、fav收藏),具體如下表所示:
| 字段名 | 列名稱 | 說明 |
|---|---|---|
| user_id | 用戶ID | 整數類型,用戶ID |
| item_id | 商品ID | 整數類型,商品ID |
| category_id | 商品類目ID | 整數類型,商品所屬類目ID |
| behavior | 行為類型 | 字符串,枚舉類型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| access_time | 時間戳 | 行為發(fā)生的時間戳,單位秒 |
--?創(chuàng)建表
CREATE?TABLE?user_behavior
?????????????(
????????????????user_id?int?,
????????????????item_id?int,
????????????????category_id?int,
????????????????behavior?string,
???????????????access_time?string
???????????????)
ROW?FORMAT?DELIMITED?FIELDS?TERMINATED?BY?',';
--?裝載數據
1,101,1,pv,1511658000
2,102,1,pv,1511658000
3,103,1,pv,1511658000
4,104,2,cart,1511659329
5,105,2,buy,1511659326
6,106,3,fav,1511659323
7,101,1,pv,1511658010
8,102,1,buy,1511658200
9,103,1,cart,1511658030
10,107,3,fav,1511659332
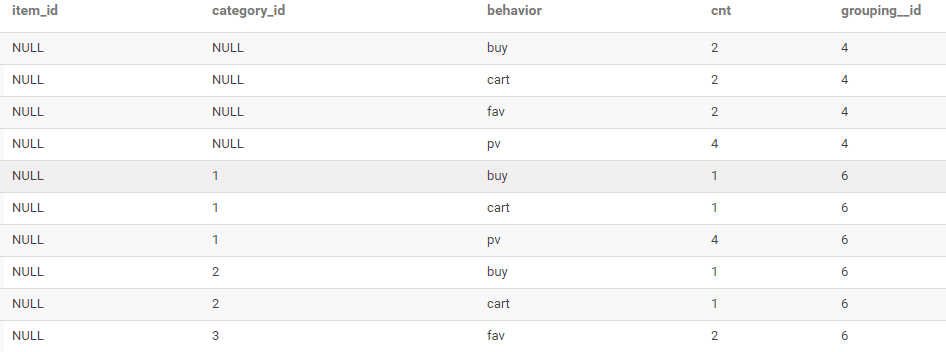
GROUPING SETS使用
--?查詢每種商品品類、每種用戶行為的訪問次數
--?查詢每種用戶行為的訪問次數
SELECT?
item_id,
category_id,
behavior,
COUNT(*)?AS?cnt,
GROUPING__ID?
FROM?user_behavior?
GROUP?BY?item_id,category_id,behavior?
GROUPING?SETS?((category_id,behavior),behavior)
ORDER?BY?GROUPING__ID;
結果如下:
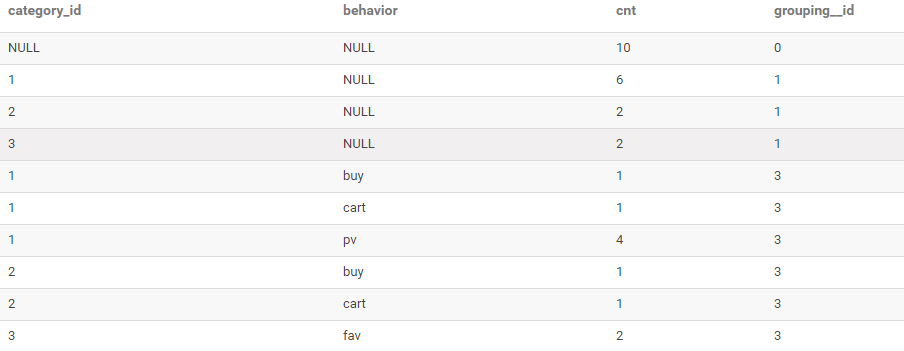
ROLLUP使用
--?查詢每種商品品類的訪問次數
--?查詢每種商品品類、每種用戶行為的次數
--?查詢用戶的總訪問次數
SELECT?
category_id,
behavior,
COUNT(*)?AS?cnt,
GROUPING__ID?
FROM?user_behavior?
GROUP?BY?category_id,behavior?
WITH?ROLLUP
ORDER?BY?GROUPING__ID;
結果如下:
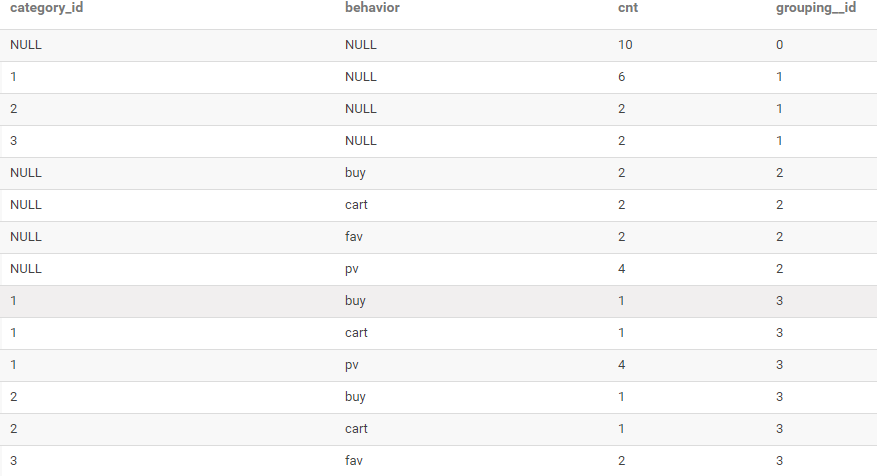
CUBE使用
--?查詢每種商品品類的訪問次數
--?查詢每種用戶行為的次數
--?查詢每種商品品類、每種用戶行為的次數
--?查詢用戶的總訪問次數
SELECT?
category_id,
behavior,
COUNT(*)?AS?cnt,
GROUPING__ID?
FROM?user_behavior?
GROUP?BY?category_id,behavior?
WITH?CUBE
ORDER?BY?GROUPING__ID;
結果如下:
總結
本文首先介紹了什么是OLAP,接著介紹Hive中提供的幾種OLAP分析的函數,并對每一種函數進行了詳細說明,并給出了相關的圖示解釋,最后以一個案例說明了這幾種函數的使用方式,可以進一步加深理解.