
拒了16k的外包,來了國企!
大家好,我是二哥呀。
今天給大家分享一個二哥編程星球里的主題:一位球友,二線城市,去年拒了一家 16k 的外包,去了國企,不過薪資低一些。以為可以躺一躺,結(jié)果太“躺”了,不是核心業(yè)務組,每天的開發(fā)工作感覺賊無聊。

這。。。都是圍城啊(??)!
說實話,二線城市 16k,真的很香了。我見過阿里 P7 的回二線城市,也就 20k 多一點。球友后悔也是情有可原的。
事已至此,我只能勸這位球友先安下心,既來之則安之,國企的坑位不多了,你占一個就少一個。可能選擇去了外包,也會發(fā)現(xiàn)不如意,又開始后悔當初沒有選擇國企了。
至少國企穩(wěn)定,五險一金都是正常繳納的,就當帶薪學習了,自己平常有時間可以多琢磨一些副業(yè),比如說考研輔導啊、學學全棧做獨立開發(fā)者啊。等技術(shù)學扎實了,再往好的公司跳。
這些年,選擇國企的小伙伴是越來越多了,因為大家都想明白了,與其卷自己,真不如消費降級,別買貴的房,別買貴的車,玩好睡好就挺好(??)。
國企面經(jīng)
來,背個牛頓的名言警句吧,“如果我比別人看得更遠,那是因為我站在巨人的肩膀上”。因此,如果小伙伴們也想沖國企的話,可以多看看師兄師姐們的面經(jīng),省事省心省力啊。
截止到目前,《Java 面試指南》已經(jīng)收錄了 600 多份優(yōu)質(zhì)面經(jīng),我甚至覺得它有點資治通鑒的味道了,“讀史使人明智啊”,form 培根。
這次我們就以同學 1 的面經(jīng)為例,來看看如果你在面試中遇到這些題目的話,該如何作答,我們不求吊打面試官,但求和面試官極限拉扯和對線(??)。
先來看看這次的題目大綱(圍繞 Java 后端四大件展開,都是非常基礎的八股啊):
- sprinqmvc的流程
- String,StringBuffer,StringBuilder的區(qū)別
- mysql底層數(shù)據(jù)結(jié)構(gòu),說說B樹,B+樹區(qū)別
- hashmap底層數(shù)據(jù)結(jié)構(gòu),鏈表和紅黑樹的轉(zhuǎn)換,hashmap的長度
- 文本文件存儲是用字節(jié)流還是字符流,視頻文件是用字節(jié)流和字符流
接下來,我會給出詳細答案,參考星球嘉賓三分惡的面渣逆襲。
- 面渣逆襲在線版:https://javabetter.cn/sidebar/sanfene/nixi.html
- 面渣逆襲 PDF 版:https://t.zsxq.com/04FuZrRVf
內(nèi)容較長,撰寫硬核面經(jīng)不容易,建議大家先收藏起來,我會盡量用通俗易懂+手繪圖的方式,讓大家不僅能背會,還能理解和掌握。總之,是時候喊出我們那句大言不慚的口號了:讓天下沒有難背的八股 ??
01、說說 SpringMVC 的流程吧
Spring MVC 是基于模型-視圖-控制器的 Web 框架,它的工作流程也主要是圍繞著 Model、View、Controller 這三個組件展開的。
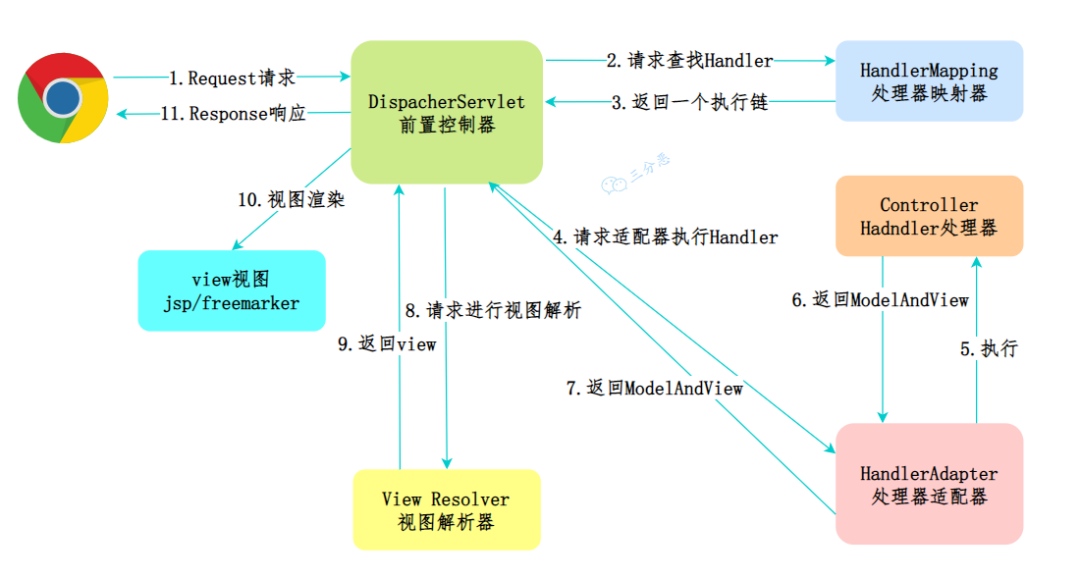 三分惡面渣逆襲:Spring MVC的工作流程
三分惡面渣逆襲:Spring MVC的工作流程
①、發(fā)起請求:客戶端通過 HTTP 協(xié)議向服務器發(fā)起請求。
②、前端控制器:這個請求會先到前端控制器 DispatcherServlet,它是整個流程的入口點,負責接收請求并將其分發(fā)給相應的處理器。
③、處理器映射:DispatcherServlet 調(diào)用 HandlerMapping 來確定哪個 Controller 應該處理這個請求。通常會根據(jù)請求的 URL 來確定。
④、處理器適配器:一旦找到目標 Controller,DispatcherServlet 會使用 HandlerAdapter 來調(diào)用 Controller 的處理方法。
⑤、執(zhí)行處理器:Controller 處理請求,處理完后返回一個 ModelAndView 對象,其中包含模型數(shù)據(jù)和邏輯視圖名。
⑥、視圖解析器:DispatcherServlet 接收到 ModelAndView 后,會使用 ViewResolver 來解析視圖名稱,找到具體的視圖頁面。
⑦、渲染視圖:視圖使用模型數(shù)據(jù)渲染頁面,生成最終的頁面內(nèi)容。
⑧、響應結(jié)果:DispatcherServlet 將視圖結(jié)果返回給客戶端。
Spring MVC 雖然整體流程復雜,但是實際開發(fā)中很簡單,大部分的組件不需要我們開發(fā)人員創(chuàng)建和管理,真正需要處理的只有 Controller 、View 、Model。
在前后端分離的情況下,步驟 ⑥、⑦、⑧ 會略有不同,后端通常只需要處理數(shù)據(jù),并將 JSON 格式的數(shù)據(jù)返回給前端就可以了,而不是返回完整的視圖頁面。
02、String,StringBuffer,StringBuilder的區(qū)別
String、StringBuilder和StringBuffer在 Java 中都是用于處理字符串的,它們之間的區(qū)別是,String 是不可變的,平常開發(fā)用得最多,當遇到大量字符串連接時,就用 StringBuilder,它不會生成很多新的對象,StringBuffer 和 StringBuilder 類似,但每個方法上都加了 synchronized 關鍵字,所以是線程安全的。
String
-
String類的對象是不可變的。也就是說,一旦一個String對象被創(chuàng)建,它所包含的字符串內(nèi)容是不可改變的。 - 每次對
String對象進行修改操作(如拼接、替換等)實際上都會生成一個新的String對象,而不是修改原有對象。這可能會導致內(nèi)存和性能開銷,尤其是在大量字符串操作的情況下。
StringBuilder
-
StringBuilder提供了一系列的方法來進行字符串的增刪改查操作,這些操作都是直接在原有字符串對象的底層數(shù)組上進行的,而不是生成新的 String 對象。 -
StringBuilder不是線程安全的。這意味著在沒有外部同步的情況下,它不適用于多線程環(huán)境。 - 相比于
String,在進行頻繁的字符串修改操作時,StringBuilder能提供更好的性能。Java 中的字符串連+操作其實就是通過StringBuilder實現(xiàn)的。
StringBuffer
StringBuffer和StringBuilder類似,但StringBuffer是線程安全的,方法前面都加了synchronized關鍵字。
使用場景總結(jié)
- String:適用于字符串內(nèi)容不經(jīng)常改變的場景。在使用字符串常量或進行少量的字符串操作時使用。
- StringBuilder:適用于單線程環(huán)境下需要頻繁修改字符串內(nèi)容的場景,比如在循環(huán)中拼接或修改字符串。
- StringBuffer:適用于多線程環(huán)境下需要頻繁修改字符串內(nèi)容的場景,保證了字符串操作的線程安全。
03、說說 MySQL 索引的底層數(shù)據(jù)結(jié)構(gòu),B 樹和 B+樹的區(qū)別
- 推薦閱讀:終于把B樹搞明白了
- 推薦閱讀:一篇文章講透MySQL為什么要用B+樹實現(xiàn)索引
MySQL 的默認存儲引擎是 InnoDB,它采用的是 B+樹索引,換句話說,InnoDB 的索引是基于 B+樹實現(xiàn)的。
那在說 B+樹之前,我先說一下 B 樹(B-tree)。
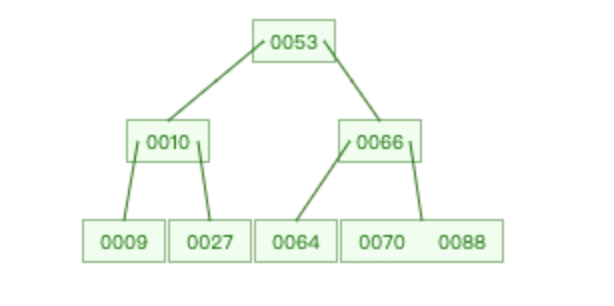
B 樹是一種自平衡的多路查找樹,和紅黑樹、二叉平衡樹不同,B 樹的每個節(jié)點可以有 m 個子節(jié)點,而紅黑樹和二叉平衡樹都只有 2 個。
換句話說,紅黑樹、二叉平衡樹是細高個,而 B 樹是矮胖子。
好,繼續(xù)。內(nèi)存和磁盤在進行 IO 讀寫的時候,有一個最小的邏輯單元,叫做頁(Page),頁的大小一般是 4KB。
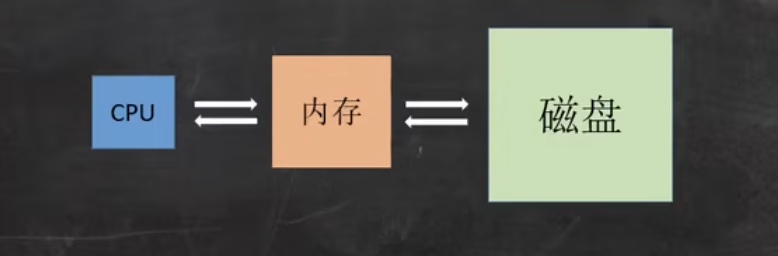
那為了提高讀寫效率,從磁盤往內(nèi)存中讀數(shù)據(jù)的時候,一次會讀取至少一頁的數(shù)據(jù),比如說讀取 2KB 的數(shù)據(jù),實際上會讀取 4KB 的數(shù)據(jù);讀取 5KB 的數(shù)據(jù),實際上會讀取 8KB 的數(shù)據(jù)。我們要盡量減少讀寫的次數(shù)。
因為讀的次數(shù)越多,效率就越低。就好比我們在工地上搬磚,一次搬 10 塊磚肯定比一次搬 1 塊磚的效率要高,反正我每次都搬 10 塊(??)。
對于紅黑樹、二叉平衡樹這種細高個來說,每次搬的磚少,因為力氣不夠嘛,那來回跑的次數(shù)就越多。
是這個道理吧,樹越高,意味著查找數(shù)據(jù)時就需要更多的磁盤 IO,因為每一層都可能需要從磁盤加載新的節(jié)點。
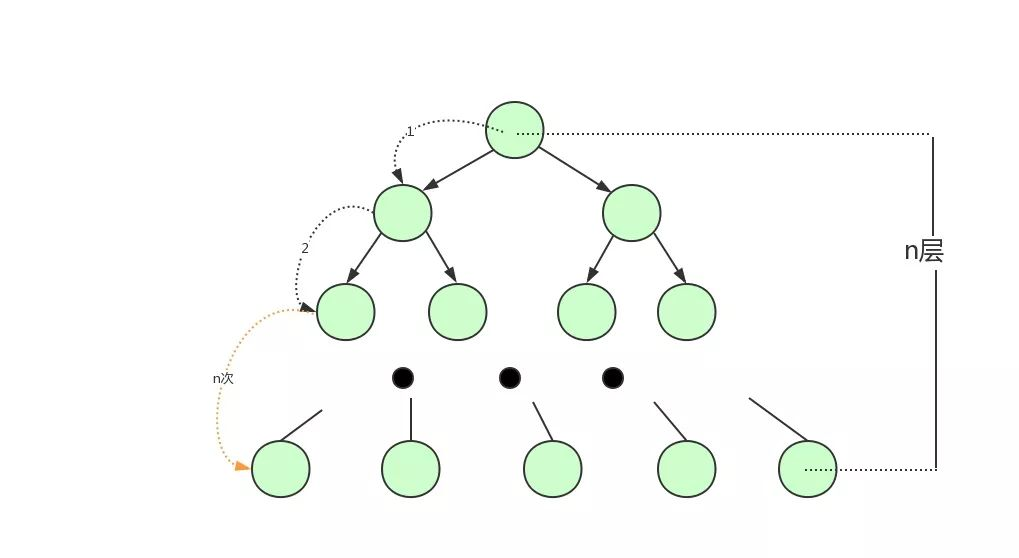 用戶1260737:二叉樹
用戶1260737:二叉樹
B 樹的節(jié)點大小通常與頁的大小對齊,這樣每次從磁盤加載一個節(jié)點時,可以正好是一個頁的大小。因為 B 樹的節(jié)點可以有多個子節(jié)點,可以填充更多的信息以達到一頁的大小。
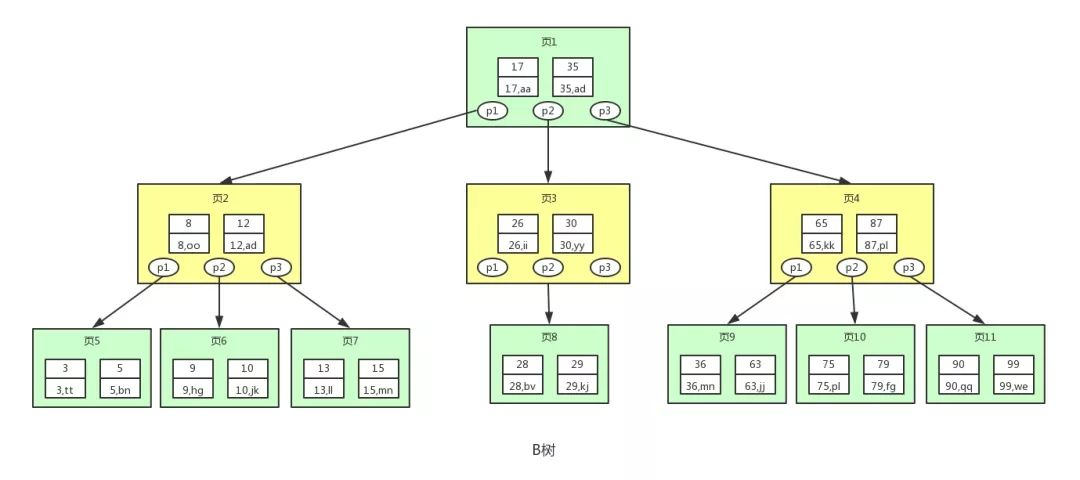 用戶1260737:B 樹
用戶1260737:B 樹
B 樹的一個節(jié)點通常包括三個部分:
- 鍵值:即表中的主鍵
- 指針:存儲子節(jié)點的信息
- 數(shù)據(jù):表記錄中除主鍵外的數(shù)據(jù)
不過,正所謂“禍兮福所倚,福兮禍所伏”,正是因為 B 樹的每個節(jié)點上都存了數(shù)據(jù),就導致每個節(jié)點能存儲的鍵值和指針變少了,因為每一頁的大小是固定的,對吧?
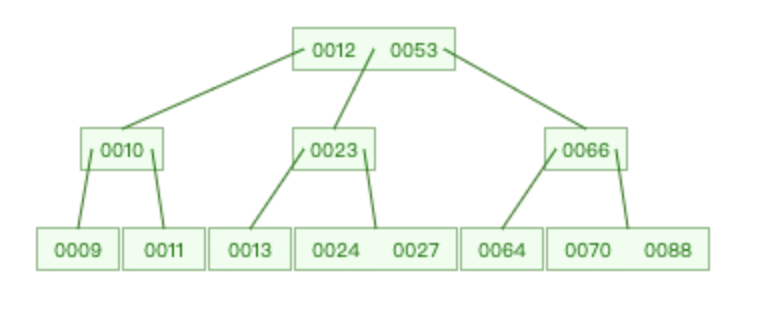
于是 B+樹就來了,B+樹的非葉子節(jié)點只存儲鍵值,不存儲數(shù)據(jù),而葉子節(jié)點存儲了所有的數(shù)據(jù),并且構(gòu)成了一個有序鏈表。
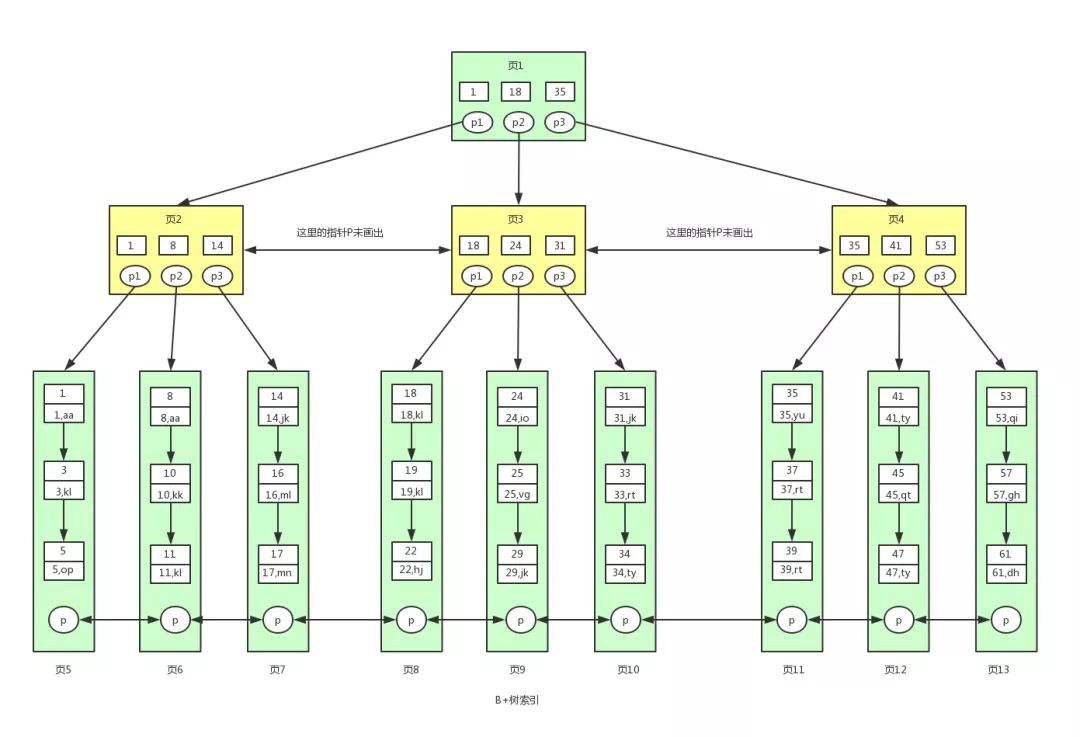 用戶1260737:B+樹
用戶1260737:B+樹
這樣做的好處是,非葉子節(jié)點上由于沒有存儲數(shù)據(jù),就可以存儲更多的鍵值對,樹就變得更加矮胖了,于是就更有勁了,每次搬的磚也就更多了(??)。
由此一來,查找數(shù)據(jù)進行的磁盤 IO 就更少了,查詢的效率也就更高了。
再加上葉子節(jié)點構(gòu)成了一個有序鏈表,范圍查詢時就可以直接通過葉子節(jié)點間的指針順序訪問整個查詢范圍內(nèi)的所有記錄,而無需對樹進行多次遍歷。
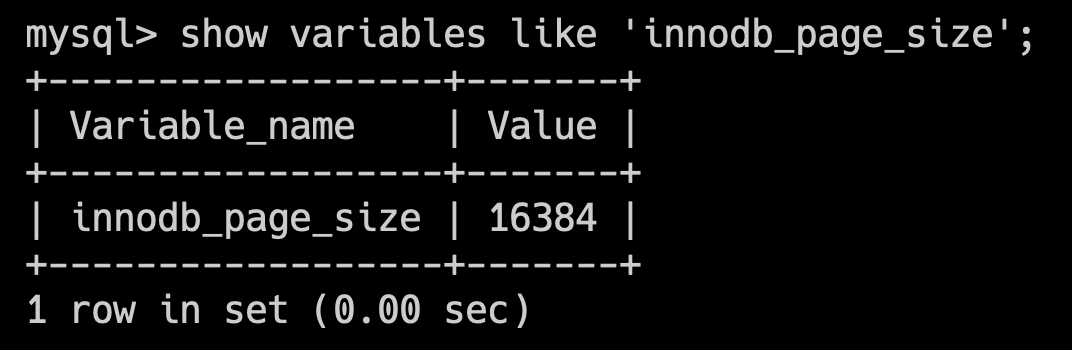
注:在 InnoDB 存儲引擎中,默認的頁大小是 16KB。可以通過 show variables like 'innodb_page_size'; 查看。
04、說說 HashMap 的底層數(shù)據(jù)結(jié)構(gòu),鏈表和紅黑樹的轉(zhuǎn)換,HashMap 的長度
JDK 8 中 HashMap 的數(shù)據(jù)結(jié)構(gòu)是數(shù)組+鏈表+紅黑樹。
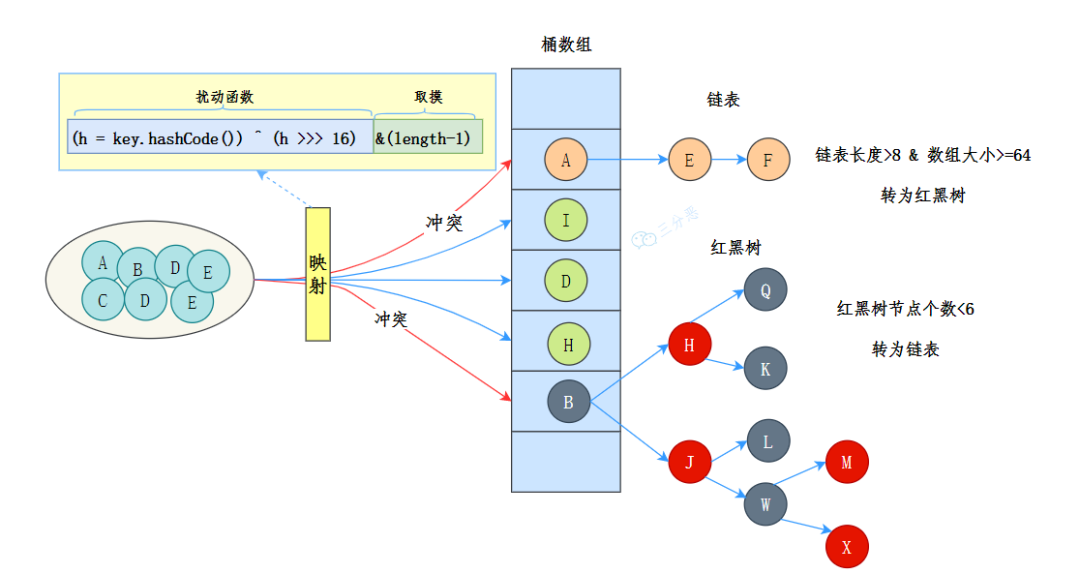 三分惡面渣逆襲:JDK 8 HashMap 數(shù)據(jù)結(jié)構(gòu)示意圖
三分惡面渣逆襲:JDK 8 HashMap 數(shù)據(jù)結(jié)構(gòu)示意圖
也就是說,HashMap 的底層數(shù)據(jù)結(jié)構(gòu)最主要的還是數(shù)組,當發(fā)生哈希沖突的時候就用鏈表來解決;不過,如果鏈表過長時,查詢效率會比較低,于是當鏈表的長度超過 8 時(數(shù)組的長度大于 64),鏈表就會轉(zhuǎn)換為紅黑樹。紅黑樹的查詢效率是 O(logn),比鏈表的 O(n) 要快。
HashMap 的初始容量是 16,隨著元素的不斷添加,HashMap 的容量(也就是數(shù)組大小)可能不足,于是就需要進行擴容,閾值是capacity * loadFactor,capacity 為容量,loadFactor 為負載因子,默認為 0.75。擴容后的數(shù)組大小是原來的 2 倍,然后把原來的元素重新計算哈希值,放到新的數(shù)組中。
05、文本存儲是字節(jié)流還是字符流,視頻文件呢?
在計算機中,文本和視頻都是按照字節(jié)存儲的,只是如果是文本文件的話,我們可以通過字符流的形式去讀取,這樣更方面的我們進行直接處理。
比如說我們需要在一個大文本文件中查找某個字符串,可以直接通過字符流來讀取判斷。
處理視頻文件時,通常使用字節(jié)流(如 Java 中的FileInputStream、FileOutputStream)來讀取或?qū)懭霐?shù)據(jù),并且會盡量使用緩沖流(如BufferedInputStream、BufferedOutputStream)來提高讀寫效率。
在技術(shù)派實戰(zhàn)項目項目中,對于文本,比如說文章和教程內(nèi)容,是直接存儲在數(shù)據(jù)庫中的,而對于視頻和圖片等大文件,是存儲在 OSS 中的。
因此,無論是文本文件還是視頻文件,它們在物理存儲層面都是以字節(jié)流的形式存在。區(qū)別在于,我們?nèi)绾瓮ㄟ^ Java 代碼來解釋和處理這些字節(jié)流:作為編碼后的字符還是作為二進制數(shù)據(jù)。
參考鏈接
- 1、星球嘉賓三分惡的面渣逆襲,可微信搜索三分惡關注他的公眾號:https://javabetter.cn/sidebar/sanfene/nixi.html
- 2、二哥的Java進階之路:https://javabetter.cn
- 3、PDF 版面渣逆襲:https://t.zsxq.com/04FuZrRVf
ending
一個人可以走得很快,但一群人才能走得更遠。二哥的編程星球已經(jīng)有 4800 多名球友加入了,如果你也需要一個良好的學習環(huán)境,戳鏈接 ?? 加入我們吧。這是一個編程學習指南 + Java 項目實戰(zhàn) + LeetCode 刷題的私密圈子,你可以閱讀星球?qū)凇⑾蚨缣釂枴湍阒贫▽W習計劃、和球友一起打卡成長。

兩個置頂帖「球友必看」和「知識圖譜」里已經(jīng)沉淀了非常多優(yōu)質(zhì)的學習資源,相信能幫助你走的更快、更穩(wěn)、更遠。
歡迎點擊左下角閱讀原文了解二哥的編程星球,這可能是你學習求職路上最有含金量的一次點擊。

最后,把二哥的座右銘送給大家:沒有什么使我停留——除了目的,縱然岸旁有玫瑰、有綠蔭、有寧靜的港灣,我是不系之舟。共勉 ??。