
【機(jī)器學(xué)習(xí)】數(shù)據(jù)不平衡問題都怎么解?
作者?|?Chilia????
整理?|?NewBeeNLP
一是數(shù)據(jù)的類別本來就不平衡,比如在廣告CTR預(yù)估中,可能90%的廣告都不會(huì)被點(diǎn)擊,只有一少部分被點(diǎn)擊; 二是由于誤分類cost的不對(duì)稱性(asymmetric cost),例如把non-spam 分成spam的代價(jià)要遠(yuǎn)大于把spam分成non-spam。
在這篇文章中,我將介紹兩大類方法:一是通過采樣而改變數(shù)據(jù)集,二是修改訓(xùn)練策略。
1. 從數(shù)據(jù)層面解決 – 重采樣 (Resampling)
1.1 隨機(jī)欠采樣(Random Under-Sampling)
通過隨機(jī)刪除多數(shù)類別的樣本來平衡類別分布。
好處:
當(dāng)訓(xùn)練數(shù)據(jù)集很大時(shí),可以通過減少訓(xùn)練數(shù)據(jù)樣本的數(shù)量來幫助改善運(yùn)行時(shí)間和存儲(chǔ)問題
缺點(diǎn):
丟棄可能有用的信息 隨機(jī)欠采樣選擇的樣本可能是有偏差的樣本, 它不會(huì)是整體分布的準(zhǔn)確代表。因此,可能導(dǎo)致實(shí)際在測(cè)試集上的結(jié)果不準(zhǔn)確
1.2 隨機(jī)重采樣(Random Over-Sampling)
通過「隨機(jī)重復(fù)取少數(shù)類別的樣本」來平衡類別分布。
好處
與欠采樣不同,此方法不會(huì)導(dǎo)致信息丟失。此方法優(yōu)于隨機(jī)欠采樣
缺點(diǎn)
重復(fù)取少數(shù)類別的樣本,因此增加了過擬合的可能性。
1.3 Ensemble 采樣
類似bagging的思想,有多個(gè)基學(xué)習(xí)器,每個(gè)基學(xué)習(xí)器都抽取一部分majority class,并且使用全部的minority class。這樣,每個(gè)majority樣本都能夠被利用上,不會(huì)有信息的損失。
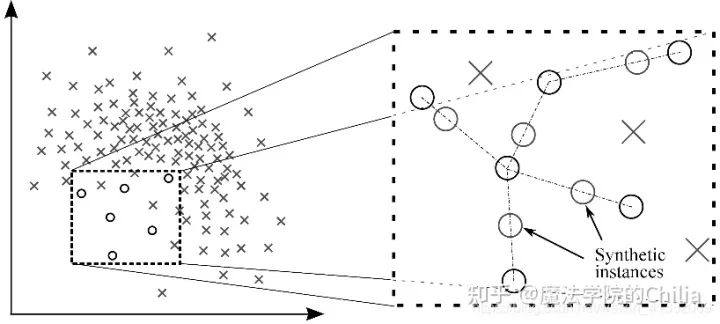
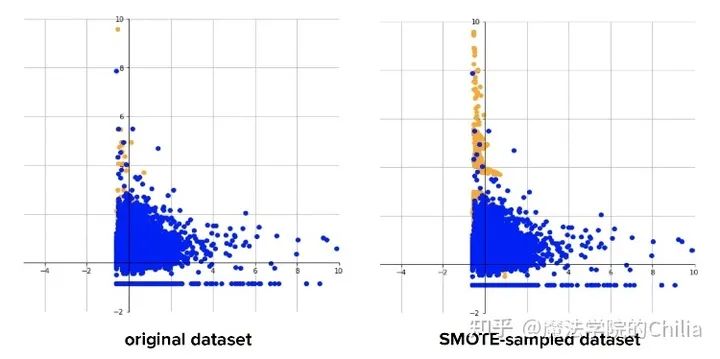
1.4 合成少數(shù)類過采樣技術(shù) (Synthetic Minority Over-sampling Technique, SMOTE)
此方法用來解決直接復(fù)制少數(shù)類樣本導(dǎo)致的過擬合問題。SMOTE算法的基本思想是對(duì)少數(shù)類樣本進(jìn)行分析并根據(jù)少數(shù)類樣本人工合成新樣本添加到數(shù)據(jù)集中。
該算法的模擬過程采用了KNN技術(shù),模擬生成新樣本的步驟如下:
計(jì)算出每個(gè)少數(shù)類樣本的K個(gè)近鄰; 從K個(gè)近鄰中隨機(jī)挑選N個(gè)樣本進(jìn)行隨機(jī)線性插值,從而構(gòu)造新的少數(shù)類樣本; 將新樣本與原數(shù)據(jù)合成,產(chǎn)生新的訓(xùn)練集;
2 從算法層面解決
2.1 改變loss的權(quán)重
重采樣方法改變了數(shù)據(jù)集,可能導(dǎo)致數(shù)據(jù)集變得太大,或者丟棄了一些信息。所以,有沒有一種方法能夠從算法層面解決類別不平衡問題呢?
實(shí)際上,可以通過改變loss的方法來實(shí)現(xiàn)。對(duì)分類器的小類樣本數(shù)據(jù)增加loss權(quán)值,降低大類樣本的權(quán)值,從而使得分類器將重點(diǎn)集中在小類樣本身上。具體做法就是,在訓(xùn)練分類器時(shí),若分類器將小類樣本分錯(cuò)時(shí)額外增加分類器一個(gè)小類樣本分錯(cuò)代價(jià),這個(gè)額外的代價(jià)可以使得分類器更加“關(guān)心”小類樣本。
2.2 boosting 方法
在boosting方法中,分類器每一步會(huì)關(guān)心上一步分錯(cuò)的那些樣本,這樣分類器就會(huì)越來越關(guān)心少數(shù)類樣本,把它們的權(quán)值提高。久而久之,就能夠?qū)⑸贁?shù)樣本正確分類了。
三句話不離本行
在搜索、推薦、廣告的實(shí)際場(chǎng)景下,怎么選擇正負(fù)樣本也是大有講究。
對(duì)于召回階段,一般初始的訓(xùn)練集是只有正樣本的。什么樣的樣本被選作正樣本,這個(gè)標(biāo)準(zhǔn)在每個(gè)公司都不一樣。
例如,facebook在其最新的文章 Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook中提到,他們選擇正樣本標(biāo)準(zhǔn)十分嚴(yán)格:對(duì)于一個(gè)query,只有當(dāng)用戶點(diǎn)擊了一個(gè)product,進(jìn)去和賣家聊天,賣家還回復(fù)了,這才算一個(gè)正樣本。
但是在其另外一篇文章Embedding-based Retrieval in Facebook Search中卻提到,其實(shí)可以把用戶點(diǎn)擊的商品都算作正樣本。這是因?yàn)槠鋵?shí)召回可以看作排序階段的一個(gè)近似,我們只需要快速的把和query相關(guān)的物品都拿出來。
那么召回階段的負(fù)樣本怎么來呢?在實(shí)際的數(shù)據(jù)流場(chǎng)景中,一般是用in-batch采樣,但是這樣有一個(gè)問題:越熱門的商品,越容易出現(xiàn)在batch中,所以越容易成為負(fù)樣本。這樣,就對(duì)熱門商品施加了不必要的懲罰。
為了解決這個(gè)問題,Google在Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations一文中提出streaming frequency estimation方法。其實(shí)還有一些負(fù)采樣方法,比如難負(fù)例采樣。還可以把in-batch采樣與隨機(jī)負(fù)采樣相結(jié)合。這里的門道很多,之后會(huì)專門出專題介紹。
對(duì)于排序階段,一般都是多目標(biāo)預(yù)測(cè),目標(biāo)有是否點(diǎn)擊、是否關(guān)注、是否購(gòu)買、觀看時(shí)長(zhǎng)、評(píng)分等等(engagement & satisfaction),負(fù)樣本就是那些曝光未點(diǎn)擊的,由于曝光的商品本來就比較少了(相對(duì)召回階段而言),所以數(shù)據(jù)不平衡沒有那么嚴(yán)重。
本文參考:
哥倫比亞大學(xué)2021fall COMS 4995課件
-?END?-
往期精彩回顧 本站qq群955171419,加入微信群請(qǐng)掃碼: