
有手就會(huì)-用MNIST訓(xùn)練一個(gè)CNN模型并識(shí)別自己手寫數(shù)字
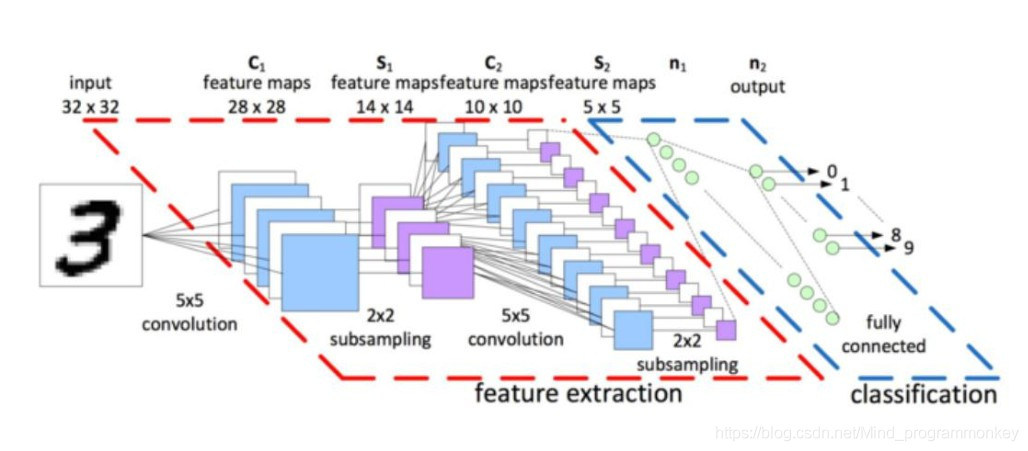
大家好,我是小伍哥,今天我們學(xué)點(diǎn)視覺的東西。很多人學(xué)圖片算法的時(shí)候,MNIST手寫數(shù)字識(shí)別都是第一個(gè)練手的項(xiàng)目,其實(shí)干跑也沒啥意思,我們今天訓(xùn)練一個(gè)模型用來識(shí)別自己的手寫數(shù)字,看看能不能實(shí)現(xiàn),這樣學(xué)起來更有參與感點(diǎn),也更實(shí)用,過程介紹也比較詳細(xì),適合初學(xué)者。
一、CNN模型構(gòu)建
from keras import layersfrom keras import modelsmodel = models.Sequential()model.add(layers.Conv2D(32, (3, 3),activation='relu',input_shape=(28, 28, 1)))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.Flatten())model.add(layers.Dropout(0.25))model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10, activation='softmax'))# 十個(gè)分類
卷積神經(jīng)網(wǎng)絡(luò)接收形狀為(image_height, image_width, image_channels)的輸入張量(不包括批量維度)。本例中設(shè)置卷積神經(jīng)網(wǎng)絡(luò)處理大小為(28, 28, 1) 的輸入張量,這正是MNIST 圖像的格式。我們向第一層傳入?yún)?shù)input_shape=(28, 28, 1) 來完成此設(shè)置。我們來看一下目前卷積神經(jīng)網(wǎng)絡(luò)的架構(gòu)。
model.summary()Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param #=================================================================conv2d (Conv2D) (None, 26, 26, 32) 320_________________________________________________________________max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0_________________________________________________________________conv2d_1 (Conv2D) (None, 11, 11, 64) 18496_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0_________________________________________________________________conv2d_2 (Conv2D) (None, 3, 3, 64) 36928_________________________________________________________________flatten (Flatten) (None, 576) 0_________________________________________________________________dropout (Dropout) (None, 576) 0_________________________________________________________________dense (Dense) (None, 64) 36928_________________________________________________________________dense_1 (Dense) (None, 10) 650=================================================================Total params: 93,322Trainable params: 93,322Non-trainable params: 0_________________________________________________________________
這里需要理解其中的具體結(jié)構(gòu),比如參數(shù)個(gè)數(shù)18496,這個(gè)的算法是(3*3*32+1)*64 得來的,這里需要充分的理解什么事參數(shù),什么事偏置。每個(gè)卷積核單元就是一個(gè)訓(xùn)練參數(shù),3*3的就有9個(gè),上一層有32個(gè)深度,需要32個(gè)3*3的卷積核,卷積乘完了還需要加一個(gè)偏置。所以有了上面的參數(shù)個(gè)數(shù)。
二、圖片下載與查看
第一步我們需要獲取訓(xùn)練數(shù)據(jù),mnist這個(gè)數(shù)據(jù)集,已經(jīng)內(nèi)置到Keras包里了,直接下載就可以,具體的代碼如下。
from keras.datasets import mnistfrom keras.utils import to_categoricalfrom keras import datasets# 加載數(shù)據(jù)集(train_images,train_labels), (test_images,test_labels) = mnist.load_data()‘’‘我們可以看到下載的進(jìn)度Using TensorFlow backend.Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz540672/11490434 [>.............................] - ETA: 9:00‘’‘# 訓(xùn)練集有60000個(gè)樣本train_images.shape(60000, 28, 28)# 測(cè)試集有10000個(gè)樣本test_images.shape(10000, 28, 28)train_images[1].shape(28, 28)# 看看一個(gè)數(shù)字的像素點(diǎn)長(zhǎng)啥樣,選取了部分train_images[1]array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0],[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0],[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0],[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0],[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 51, 159, 253, 159, 50, 0, 0, 0, 0, 0, 0,0, 0],····]]#可以看看內(nèi)置的所有數(shù)據(jù)集print(dir(datasets))['absolute_import', 'boston_housing', 'cifar', 'cifar10', 'cifar100','fashion_mnist', 'imdb', 'mnist', 'reuters']
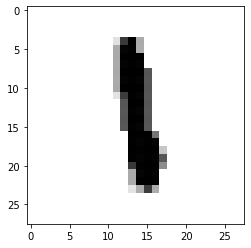
把矩陣打印出來看看,第200個(gè),是數(shù)字1
import matplotlib.pyplot as pltplt.imshow(train_images[200] , cmap=plt.cm.binary)plt.show()
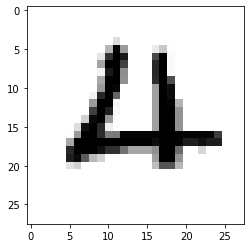
第1220個(gè),是數(shù)字4
plt.imshow(train_images[1220] , cmap=plt.cm.binary)plt.show()
三、模型訓(xùn)練&準(zhǔn)確率評(píng)估
我們開始訓(xùn)練模型,第一步是要調(diào)整圖片的格式,通道1,并除以255歸一化,將像素值轉(zhuǎn)換到0-1之間,方便反向傳播數(shù)據(jù)的更新。
train_images = train_images.reshape((60000, 28, 28, 1))train_images = train_images.astype('float32') / 255train_labels = to_categorical(train_labels)test_images = test_images.reshape((10000, 28, 28, 1))test_images = test_images.astype('float32') / 255test_labels = to_categorical(test_labels)model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])model.fit(train_images,train_labels,epochs=5,???????????batch_size=64)
訓(xùn)練完成了,我們?cè)跍y(cè)試集上測(cè)試下模型的準(zhǔn)確率,可以看到,這么一個(gè)簡(jiǎn)單的模型,我們的準(zhǔn)確率就達(dá)到了99.14%,深度學(xué)習(xí)還是非常強(qiáng)大的
test_loss, test_acc = model.evaluate(test_images, test_labels)test_acc0.9914000034332275
看看預(yù)測(cè)的到底準(zhǔn)不準(zhǔn)呢,我們看看預(yù)測(cè)的細(xì)節(jié)
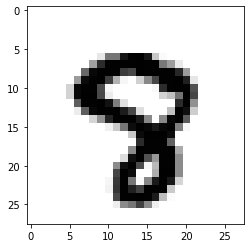
import numpy as npimport matplotlib.pyplot as plty_pred = model.predict(test_images)pred = np.argmax(y_pred, axis=1)#看看第2990個(gè)數(shù)字是啥,我們預(yù)測(cè)的是8,看看圖片也是8,挺準(zhǔn)的steps = 2990print('pred: ',pred[steps])pred: 8plt.imshow(test_images[steps] , cmap=plt.cm.binary)plt.show()
四、預(yù)測(cè)自己的手寫數(shù)字
在測(cè)試集效果好,那在實(shí)際應(yīng)用中到底好不好呢,我們自己手寫幾個(gè)測(cè)試下,模型訓(xùn)練好了就可以保存著以后用了,預(yù)測(cè)的時(shí)候直接加載就行,如果預(yù)測(cè)樣本沒有發(fā)生比較大的變化,那訓(xùn)練好的模型理論上可以一直使用,大概的預(yù)測(cè)過程如下:

根據(jù)上面的訓(xùn)練,模型的準(zhǔn)確率還挺高得,但是實(shí)際有沒有用呢,還需要用自己的數(shù)據(jù)進(jìn)行測(cè)試,打開自己在畫圖板或者在筆記本上隨便寫幾個(gè)數(shù)字,然后單個(gè)截圖保存后進(jìn)行預(yù)測(cè)。
分別截圖后保存成img3、img4、img5......,下面進(jìn)行預(yù)處理,處理成和模型訓(xùn)練一樣的數(shù)據(jù)才能預(yù)測(cè)。
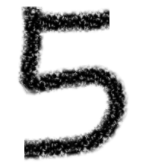
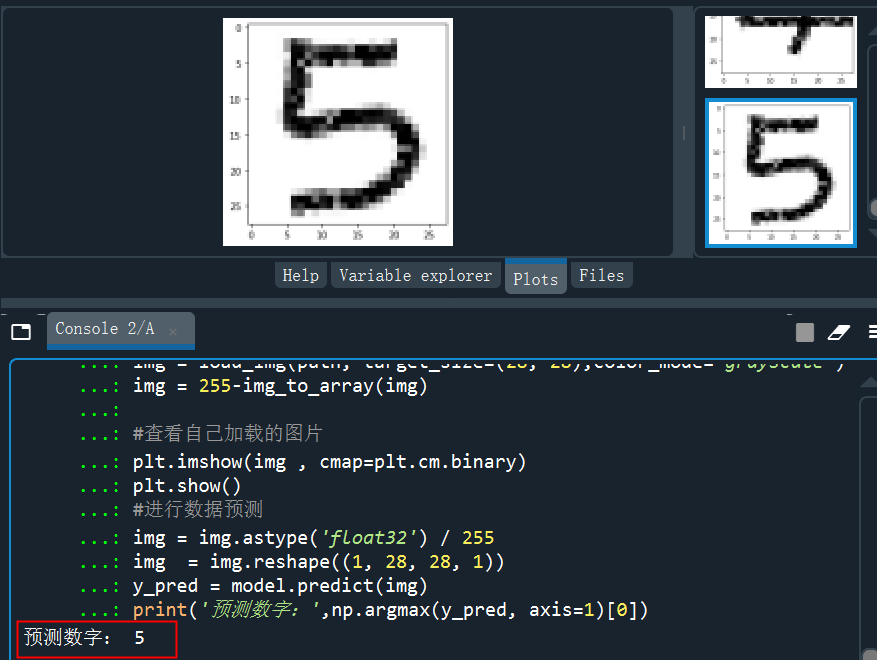
from keras.preprocessing.image import load_img,img_to_arrayimport matplotlib.pyplot as pltimport numpy as np#讀取圖片、調(diào)整圖片大小,轉(zhuǎn)換成灰度 help(load_img)path = 'C:/Users/伍正祥/Desktop/img5.jpg'img = load_img(path, target_size=(28, 28),color_mode="grayscale")#255-為了調(diào)成白底,系統(tǒng)灰度轉(zhuǎn)換自動(dòng)給處理成黑底了,所以做個(gè)反轉(zhuǎn)img = 255-img_to_array(img)#查看自己加載的圖片plt.imshow(img , cmap=plt.cm.binary)plt.show()#圖片形狀調(diào)整,需要調(diào)整到和訓(xùn)練集一樣的格式img = img.astype('float32')/255img = img.reshape((1, 28, 28, 1))#進(jìn)行圖片進(jìn)行預(yù)測(cè)y_pred = model.predict(img)print('預(yù)測(cè)數(shù)字:',np.argmax(y_pred, axis=1)[0]print('預(yù)測(cè)概率:',y_pred)
讀取5的的手寫圖片并進(jìn)行預(yù)測(cè),可以看到預(yù)測(cè)的結(jié)果為5.
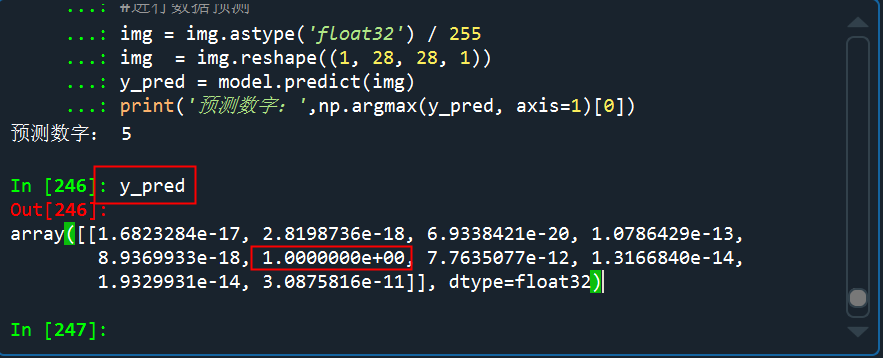
看看預(yù)測(cè)的概率分布,是5的概率幾乎接近于1
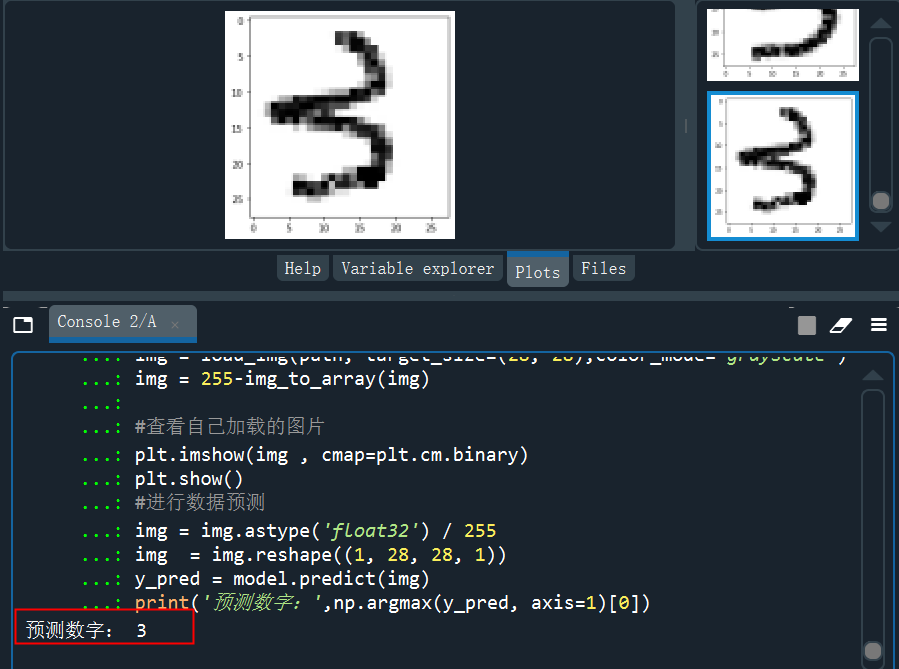
讀取3的的手寫圖片并預(yù)測(cè)
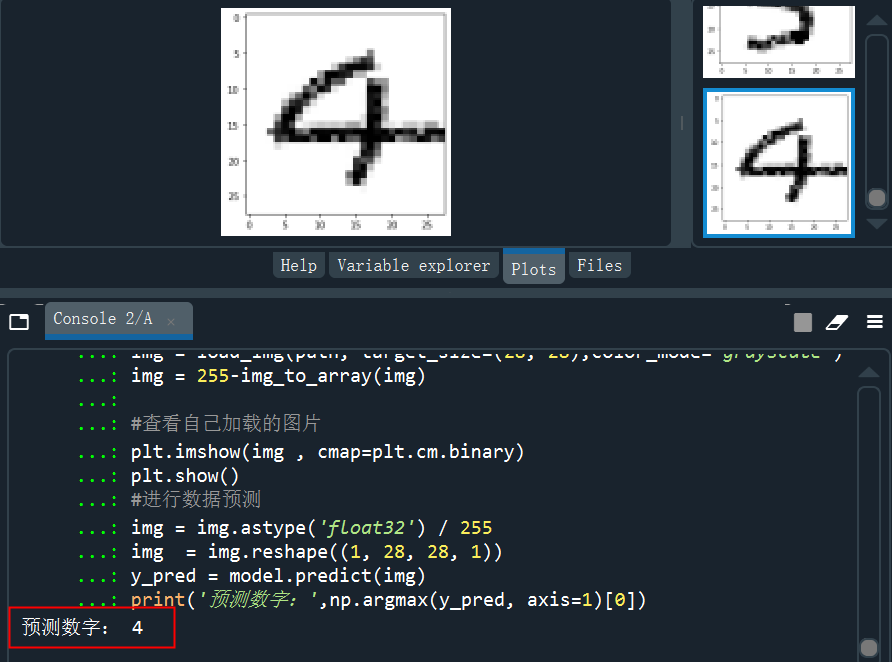
讀取4的的手寫圖片并預(yù)測(cè)
從測(cè)試的結(jié)果來看,預(yù)測(cè)效果還是非常不錯(cuò)的,多試幾次,也有預(yù)測(cè)錯(cuò)的,但是錯(cuò)的概率比較小。網(wǎng)絡(luò)結(jié)構(gòu)比較簡(jiǎn)單,如果對(duì)于接觸的不多的同學(xué),理解卷積還是比較困難的。特別是每一層的具體細(xì)節(jié)以及參數(shù)個(gè)數(shù)等,大家可以多看看一些可視化CNN的文章,充分理解。
···? END? ···
往期精彩:
風(fēng)控難題之無監(jiān)督風(fēng)險(xiǎn)感知:腦力、想象力、第六感、黑洞、星座、面相···
情侶、基友、渣男和狗-基于時(shí)空關(guān)聯(lián)規(guī)則的影子賬戶挖掘
情侶、基友、渣男和狗-基于SynchroTrap+LPA算法的團(tuán)伙賬戶挖掘
孤立森林,一個(gè)通過XJB亂分進(jìn)行異常檢測(cè)的算法
風(fēng)控策略的自動(dòng)化生成-利用決策樹分分鐘生成上千條策略
關(guān)聯(lián)規(guī)則-策略挖掘中必不可少的算法
異常檢測(cè)算法之(HBOS)-Histogram-based Outlier Score