
【NLP】探索NLP模型可解釋性的7種姿勢
每次看badcase時,都會懷疑自己的能力,是我哪里做的不對嗎?這都學(xué)不會?

幸運(yùn)的話,會找到一批有共性的問題,再有針對性地加入訓(xùn)練數(shù)據(jù)或者改動模型解決。而不幸的話,就是這兒錯一個那兒錯一個,想改動都無從下手。
今天,就推薦一篇香儂科技出品的「NLP模型可解釋性綜述」,幫大家尋找模型預(yù)測結(jié)果的根據(jù)所在,從而更有針對性地進(jìn)行優(yōu)化。
論文:Interpreting Deep Learning Models in?Natural?Language?Processing:?A?Review

這篇文章描述的「可解釋性」,旨在理解模型為什么給出當(dāng)前的預(yù)測結(jié)果。從預(yù)測結(jié)果根據(jù)的出處來看,作者把可解釋性方法分為三類:
Training-based:從訓(xùn)練數(shù)據(jù)找根據(jù),比如某條訓(xùn)練樣本使得模型將當(dāng)前測試樣本預(yù)測為A類 Test-based:從測試數(shù)據(jù)本身找根據(jù),比如某個詞、某個片段 Hybrid-based:同時從訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)找根據(jù)
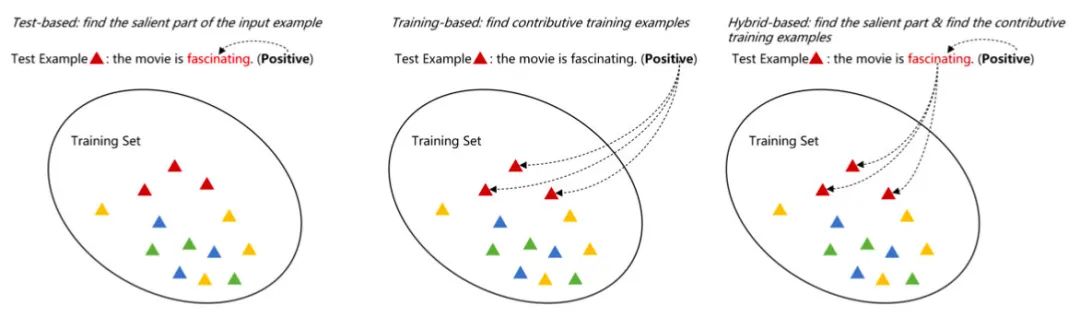
從可解釋性方法的使用來看,又可以分為兩種:
Joint methods:把負(fù)責(zé)可解釋性的模塊加入到模型中一起訓(xùn)練 Pos-hoc methods:在訓(xùn)練后加入可解釋性模塊
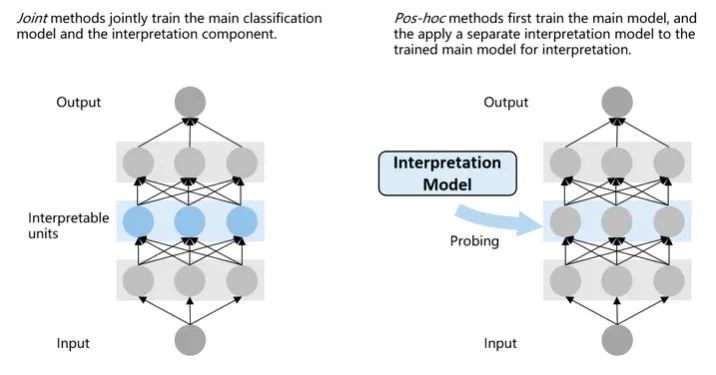
接下來的梳理主要以第一種分類體系為主線,不過作者也同時給出了每個方法的使用方式:
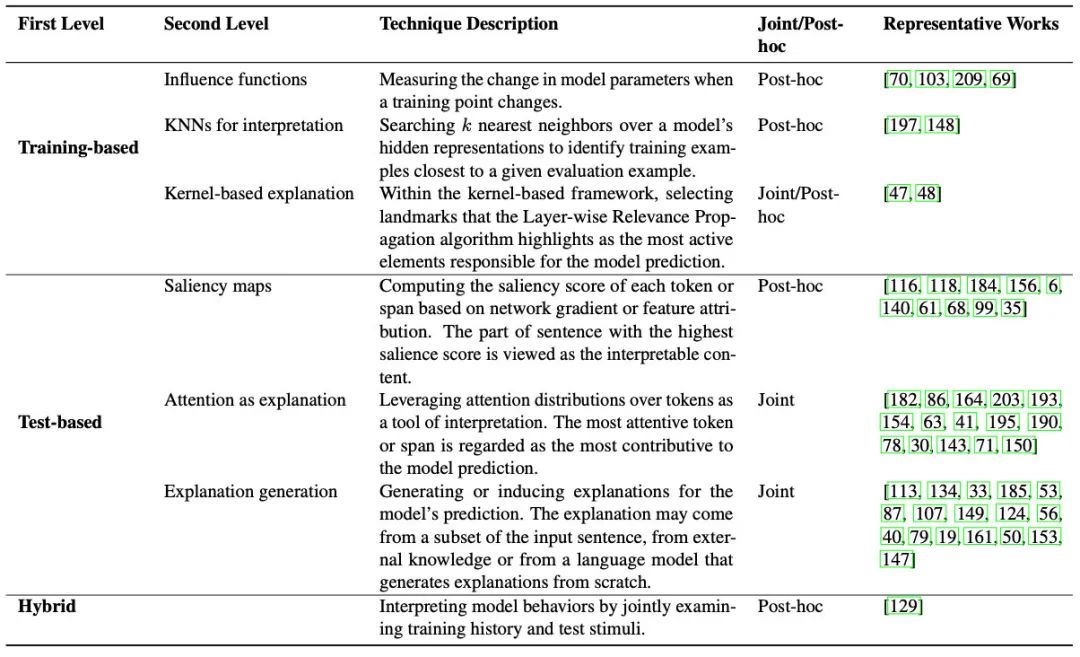
Training-based
Influence Functions
這類方法主要通過一個函數(shù),來衡量訓(xùn)練樣本z對于測試樣本x的影響。最naive的方法就是去掉z再訓(xùn)練一個模型,但這樣測完的時候就可以領(lǐng)盒飯走人了。不過我們有數(shù)學(xué)呀!于是在計算訓(xùn)練loss的時候,我們可以給樣本z的loss加一個擾動,然后就能計算出z對于模型權(quán)重的影響,再把x輸入進(jìn)去,就能計算出每個z對每個x的影響情況。
由于公式太復(fù)雜,我就不列出來殺大家的腦細(xì)胞了。其中有個問題是Hessian矩陣比較難算,對于深度模型簡直是災(zāi)難。于是又有學(xué)者提出了更簡單的方法:Turn over dropout。
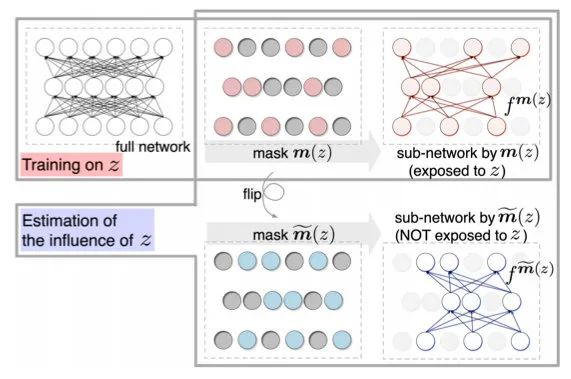
該方法的核心思想是,在訓(xùn)練完模型后,得到每個樣本的一個mask矩陣m(z),應(yīng)用mask之后可以分離出那些不受樣本z影響的神經(jīng)元。于是我們可以應(yīng)用矩陣得到兩個子網(wǎng)絡(luò),再輸入x后預(yù)測,就能計算出預(yù)測的diff。
KNNs Based Interpretation
基于KNN的方法旨在通過測試樣本的隱層表示找到相近的訓(xùn)練樣本。
這個方法理解起來就容易多了,而且很實用。比如我們在做分類任務(wù)時,有的測試樣本置信度沒那么高,這時就可以通過KNN的方法去找相近的TopK個訓(xùn)練樣本,根據(jù)它們的label分布來幫助預(yù)測:
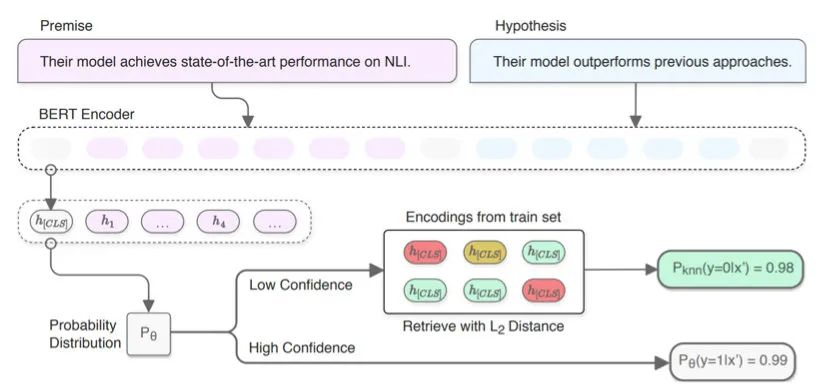
Kernel based Interpretation
這類方法比較老了,參考文獻(xiàn)都是18、19年的。具體做法是,先用核函數(shù)對預(yù)測樣本x和多個訓(xùn)練樣本l計算相似度K(x,l),之后把相似度矩陣投影成更高維的表示,再輸入神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)測。之后再利用LRP(Layerwise Relevance Propagation)反向計算每層、每個神經(jīng)元的相關(guān)性分?jǐn)?shù),傳導(dǎo)回訓(xùn)練樣本那一層就能知道每個樣本對測試數(shù)據(jù)的影響了。
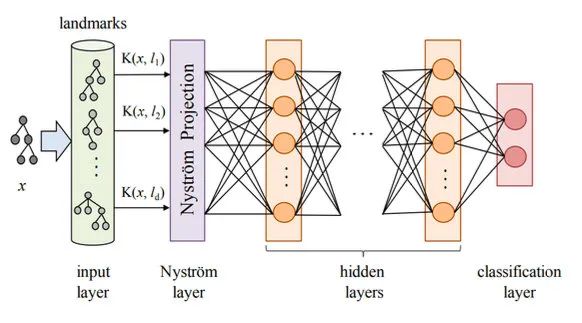
在訓(xùn)練時,Kernel和投影層都是一起訓(xùn)練的,所以這種方法既需要在訓(xùn)練時加入,又需要訓(xùn)練后的計算。
Test-based
Saliency-based Interpretation
這種方法的核心思想是利用一些metric計算測試樣本中token、spen的重要程度。作者列出了很多種可以用的metirc:

Attention-based Interpretation
這個相信大家都熟悉了,就是通過觀察attention矩陣來分析token的重要程度。
但有意思的事,作者也在參考文獻(xiàn)中發(fā)現(xiàn)了一些質(zhì)疑的聲音:Attention確實能給可解釋性提供幫助嗎?
在一篇19年的工作《Attention is not explanation》中,該作者提到,如果注意力權(quán)重真的能提供可解釋性,那它應(yīng)該具備兩個性質(zhì):
注意力權(quán)重應(yīng)該和基于特征的Saliency-based方法有很高的相關(guān)性 改變注意力權(quán)重會影響預(yù)測結(jié)果
但是之后,該作者通過一系列的實驗,證實attention不具備上述兩個性質(zhì)。所以直到現(xiàn)在(2021年11月),注意力機(jī)制是否能提供可解釋性這個問題還處于爭論之中。
不過該工作的實驗是基于BiLSTM+Attention的,仍然有很多基于BERT的實驗表明,注意力機(jī)制確實學(xué)到了不少的語言知識。
Explanation Generation
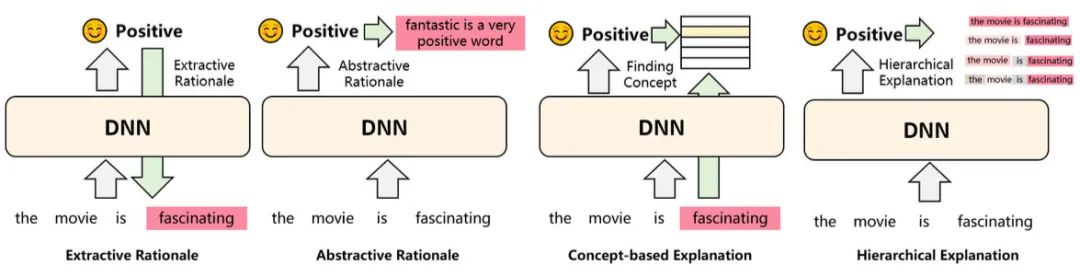
這個方法就有意思了,上述我們介紹的可解釋性方法,對于人類來說可讀性都比較弱。而這類方法就要求輸出對人類更友好的「解釋」。比如:
Extractive/Abstractive Rationale:通過抽取或者生成的方式,把樣本中對結(jié)果影響大的部分輸出出來 Concept-based:將預(yù)測樣本聯(lián)系到一些抽象概念上,比如在對餐廳的評價中,哪些詞語是形容口味的、環(huán)境的等等,相當(dāng)于給出了推理過程 Hierarchical:自底向上分別給句子的每個token、span打分,哪個片段是正向、哪個是負(fù)向,也相當(dāng)于給出了推理過程
總結(jié)
可解釋性算是一個沒那么熱的方向,首先是深度模型確實太復(fù)雜了、太隨機(jī)了,有時候自己想的一堆idea都沒用,一個bug反而有提升。到了解釋的時候全靠猜,可能是哪里分布不一致?或者是模型已經(jīng)足夠強(qiáng)了,我加的輸入知識它不需要?其次是大部分人都是結(jié)果導(dǎo)向,有時間研究不確定的可解釋性,不如花心思在指標(biāo)提升上。
要說可解釋性重不重要,那肯定是重要的。如果對模型的了解更深入,就可以避免一些高風(fēng)險的badcase。比如風(fēng)控領(lǐng)域,一個反動內(nèi)容可能會滅了一家公司,再比如醫(yī)療領(lǐng)域,一個錯誤的預(yù)測可能影響患者的生命。
論文的結(jié)尾,作者列出了很多的開放問題等待大家探索:
到底怎樣才算可解釋? 如何評估這些探究可解釋性的方法? 是為算法工程師提供解釋,還是為看到結(jié)果的用戶提供解釋? 目前的可解釋性方法大多研究分類任務(wù),而其他任務(wù)呢? 很多可解釋性方法提供的結(jié)果不一致 是否要犧牲性能獲取更高的可解釋性? 可解釋性方法如何應(yīng)用?它的價值有多少?
那么最后,深度模型是否真的可解釋?這個問題我也沒有想清楚,世上無法解釋的東西太多了。
往期精彩回顧 本站qq群554839127,加入微信群請掃碼: