
用戶行為分析模型實踐(一)—— 路徑分析模型
一、需求背景
在互聯(lián)網數(shù)據(jù)化運營實踐中,有一類數(shù)據(jù)分析應用是互聯(lián)網行業(yè)所獨有的——路徑分析。路徑分析應用是對特定頁面的上下游進行可視化展示并分析用戶在使用產品時的路徑分布情況。比如:當用戶使用某APP時,是怎樣從【首頁】進入【詳情頁】的,用戶從【首頁】分別進入【詳情頁】、【播放頁】、【下載頁】的比例是怎樣的,以及可以幫助我們分析用戶離開的節(jié)點是什么。
在場景對應到具體的技術方案設計上,我們將訪問數(shù)據(jù)根據(jù)session劃分,挖掘出用戶頻繁訪問的路徑;功能上允許用戶即時查看所選節(jié)點相關路徑,支持用戶自定義設置路徑的起點或終點,并支持按照業(yè)務新增用戶/活躍用戶查看不同目標人群在同一條行為路徑上的轉化結果分析,滿足精細化分析的需求。
1.1 應用場景
通常用戶在需要進行路徑分析的場景時關注的主要問題:
按轉換率從高至低排列在APP內用戶的主要路徑是什么;
用戶在離開預想的路徑后,實際走向是什么?
不同特征的用戶行為路徑有什么差異?
通過一個實際的業(yè)務場景我們可以看下路徑分析模型是如何解決此類問題的;
【業(yè)務場景】
分析“活躍用戶”到達目標落地頁[小視頻頁]的主要行為路徑(日數(shù)據(jù)量為十億級,要求計算結果產出時間1s左右)
【用戶操作】
選擇起始/結束頁面,添加篩選條件“用戶”;
選擇類型“訪問次數(shù)”/“會話次數(shù)”;
點擊查詢,即時產出結果。
二、基本概念
在進行具體的數(shù)據(jù)模型和工程架構設計前,先介紹一些基礎概念,幫助大家更好的理解本文。
2.1 路徑分析
路徑分析是常用的數(shù)據(jù)挖據(jù)方法之一, 主要用于分析用戶在使用產品時的路徑分布情況,挖掘出用戶的頻繁訪問路徑。與漏斗功能一樣,路徑分析會探索用戶在您的網站或應用上逗留的過程中采取的各項步驟,但路徑分析可隨機對多條路徑進行研究,而不僅僅是分析一條預先設定的路徑。
2.2 Session和Session Time
不同于WEB應用中的Session,在數(shù)據(jù)分析中的Session會話,是指在指定的時間段內在網站上發(fā)生的一系列互動。本模型中的Session Time的含義是,當兩個行為間隔時間超過Session Time,我們便認為這兩個行為不屬于同一條路徑。
2.3 桑基圖
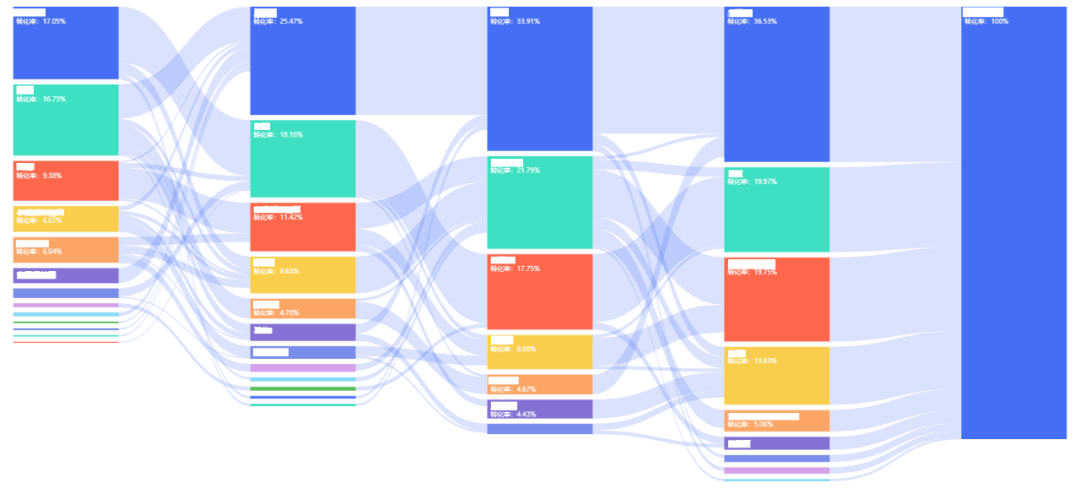
桑基圖(Sankey diagram),即桑基能量分流圖,也叫桑基能量平衡圖。它是一種特定類型的流程圖,圖中延伸的分支的寬度對應數(shù)據(jù)流量的大小。如圖4.1-1所示,每條邊表示上一節(jié)點到該節(jié)點的流量。一個完整的桑基圖包括以下幾個內容:節(jié)點數(shù)據(jù)及節(jié)點轉化率(下圖紅框部分)、邊數(shù)據(jù)及邊轉化率(下圖黑框部分)。轉化率的計算詳見【3.5. 轉化率計算】。
2.4 鄰接表
構造桑基圖可以簡化為一個圖的壓縮存儲問題。圖通常由幾個部分組成:
邊(edge)
點(vertex)
權重(weight)
度(degree)
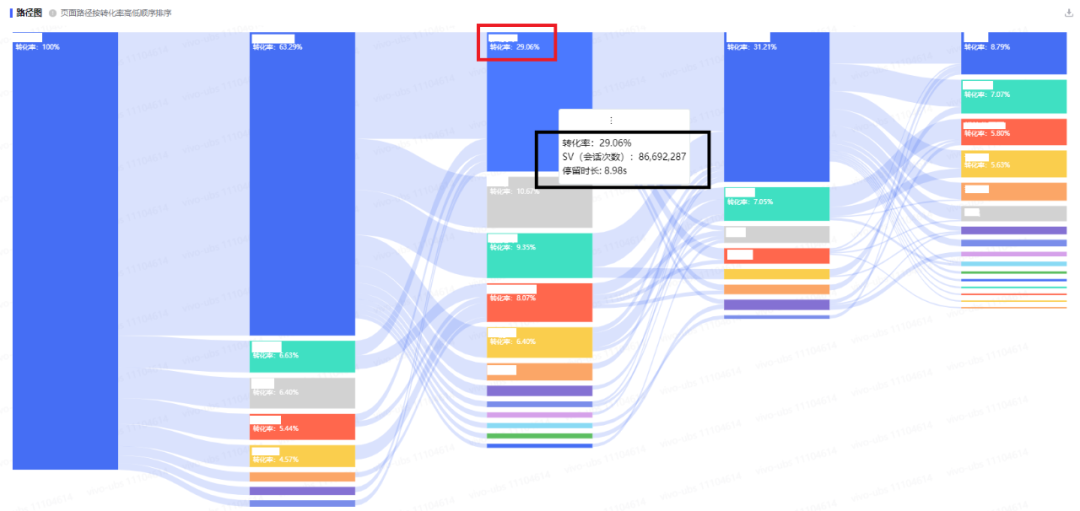
本模型中,我們采用鄰接表進行存儲。鄰接表是一種常用的圖壓縮存儲結構,借助鏈表來保存圖中的節(jié)點和邊而忽略各節(jié)點之間不存在的邊,從而對矩陣進行壓縮。鄰接表的構造如下:
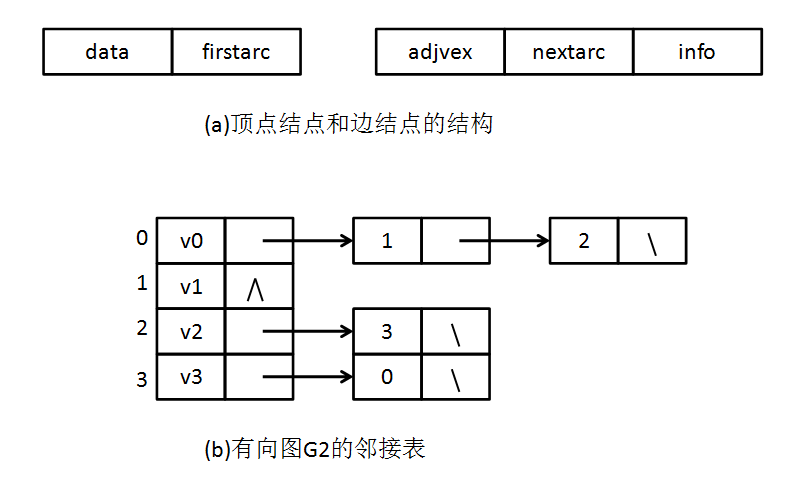
(a)中,左側為頂點節(jié)點,包含頂點數(shù)據(jù)及指向第一條邊的指針;右側為邊節(jié)點,包含該邊的權重、出入度等邊信息以及指向下一條邊的指針。一個完整的鄰接表類似于Hashmap的結構,如圖(b),左側是一個順序表,保存的是(a)中的邊節(jié)點;每個邊節(jié)點對應一個鏈表存儲與該節(jié)點相連接的邊。頁面路徑模型中,為了適應模型的需要,我們對頂點節(jié)點和邊節(jié)點結構做了改造,詳情請見【4.1】節(jié)。
2.5 樹的剪枝
剪枝是樹的構造中一個重要的步驟,指刪去一些不重要的節(jié)點來降低計算或搜索的復雜度。頁面路徑模型中,我們在剪枝環(huán)節(jié)對原始數(shù)據(jù)構造的樹進行修整,去掉不符合條件的分支,來保證樹中每條根節(jié)點到葉節(jié)點路徑的完整性。
2.6 PV和SV
PV即Page View,訪問次數(shù),本模型中指的是一段時間內訪問的次數(shù);SV即Session View,會話次數(shù),本模型中指出現(xiàn)過該訪問路徑的會話數(shù)。如,有路徑一:A → B → C → D → A → B和路徑二:A → B → D,那么,A → B的PV為2+1=3,SV為1+1=2。
三、 數(shù)據(jù)模型設計
本節(jié)將介紹數(shù)據(jù)模型的設計,包括數(shù)據(jù)流向、路徑劃分、ps/sv計算以及最終得到的桑基圖中路徑的轉化率計算。
3.1 整體數(shù)據(jù)流向
數(shù)據(jù)來源于統(tǒng)一的數(shù)據(jù)倉庫,通過Spark計算后寫入Clickhouse,并用Hive進行冷備份。數(shù)據(jù)流向圖見圖3.1-1。
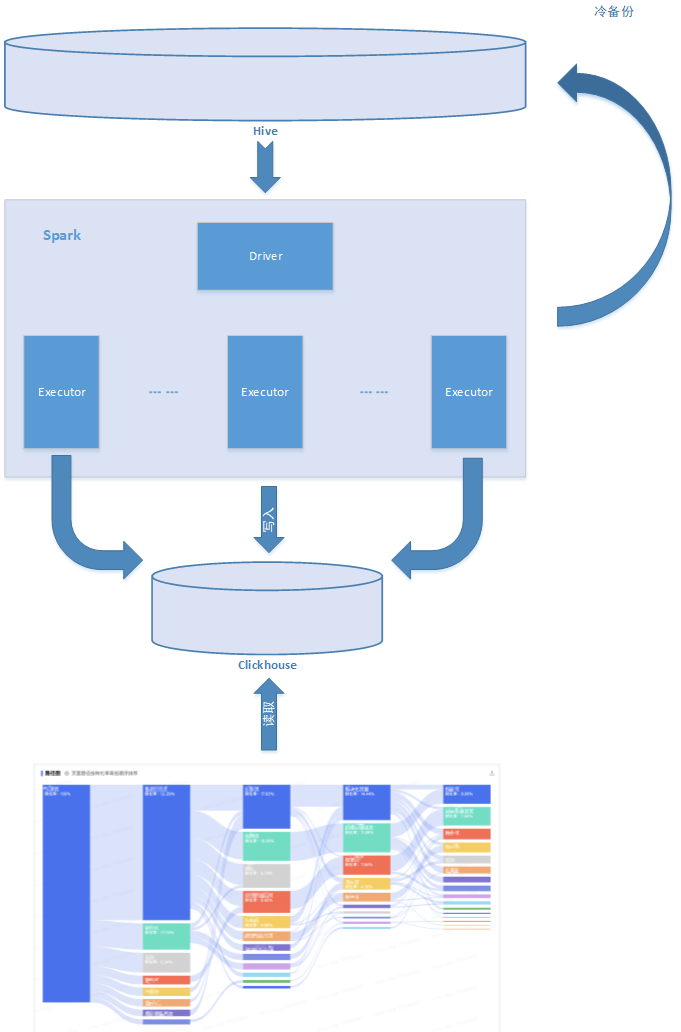
圖3.1-1
3.2 技術選型
Clickhouse不是本文的重點,在此不詳細描述,僅簡要說明選擇Clickhouse的原因。
選擇的原因是在于,Clickhouse是列式存儲,速度極快。看下數(shù)據(jù)量級和查詢速度(截止到本文撰寫的日期):
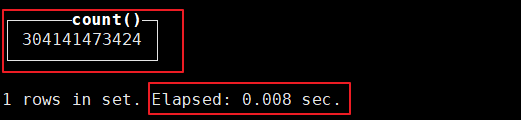
圖3.2-1
最后得到的千億數(shù)據(jù)查詢速度是這樣,
圖3.2-2
3.3 數(shù)據(jù)建模
3.3.1 獲取頁面信息,劃分session
頁面路徑模型基于各種事件id切割獲取到對應的頁面id,來進行頁面路徑分析。Session的概念可見第2.2節(jié),這里不再贅述。目前我們使用更加靈活的Session劃分,使得用戶可以查詢到在各種時間粒度(5,10,15,30,60分鐘)的Session會話下,用戶的頁面轉化信息。
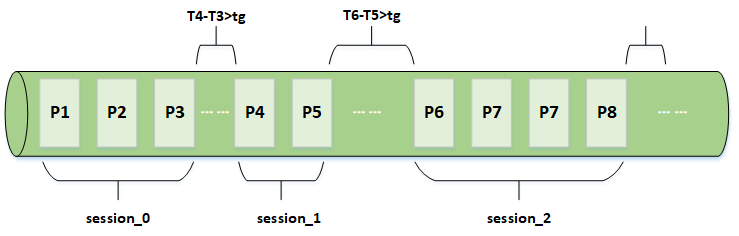
假設有用戶a和用戶b,a用戶當天發(fā)生的行為事件分別為 E1, E2, E3... , 對應的頁面分別為P1, P2, P3... ,事件發(fā)生的時間分別為T1, T2, T3... ,選定的session間隔為tg。如圖所示T4-T3>tg,所以P1,P2,P3被劃分到了第一個Session,P4,P5被劃分到了第二個Session,同理P6及后面的頁面也被劃分到了新的Session。
偽代碼實現(xiàn)如下:
def splitPageSessions(timeSeq: Seq[Long], events: Seq[String], interval: Int)(implicit separator: String): Array[Array[Array[String]]] = {// 參數(shù)中的events是事件集合,timeSeq是相應的事件發(fā)生時間的集合if (events.contains(separator))throw new IllegalArgumentException("Separator should't be in events.")if (events.length != timeSeq.length)throw new Exception("Events and timeSeq not in equal length.")val timeBuf = ArrayBuffer[String](timeSeq.head.toString) // 存儲含有session分隔標識的時間集合val eventBuf = ArrayBuffer[String](events.head) // 存儲含有session分隔標識的事件集合if (timeSeq.length >= 2) {events.indices.tail.foreach { i =>if (timeSeq(i) - timeSeq(i - 1) > interval * 60000) { // 如果兩個事件的發(fā)生時間間隔超過設置的時間間隔,則添加分隔符作為后面劃分session的標識timeBuf += separator;eventBuf += separator}timeBuf += timeSeq(i).toString;eventBuf += events(i)}}val tb = timeBuf.mkString(",").split(s",\\$separator,").map(_.split(",")) // 把集合通過標識符劃分成為各個session下的時間集合val eb = eventBuf.mkString(",").split(s",\\$separator,").map(_.split(",")) // 把集合通過標識符劃分成為各個session下的事件集合tb.zip(eb).map(t => Array(t._1, t._2)) // 把session中的事件和發(fā)生時間對應zip到一起,并把元組修改成數(shù)組類型,方便后續(xù)處理}
3.3.2 相鄰頁面去重
不同的事件可能對應同一頁面,臨近的相同頁面需要被過濾掉,所以劃分session之后需要做的就是相鄰頁面去重。

圖3.3-2
相鄰頁面去重后得到的結果是這樣

圖3.3-3
3.3.3 獲取每個頁面的前/后四級頁面
然后對上述數(shù)據(jù)進行窗口函數(shù)分析,獲取每個session中每個頁面的前后四級頁面,其中sid是根據(jù)用戶標識ID和session號拼接而成,比如,針對上述的用戶a的第一個session 0會生成如下的7條記錄,圖中的page列為當前頁面,空頁面用-1表示
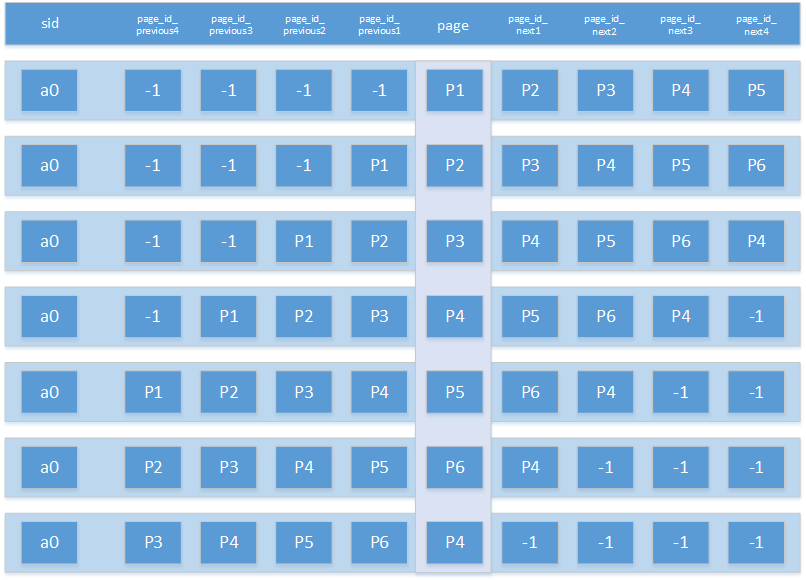
圖3.3-4
計算剩下的,會得到一共7+7+6+4+5=29條記錄。得到全部記錄如下
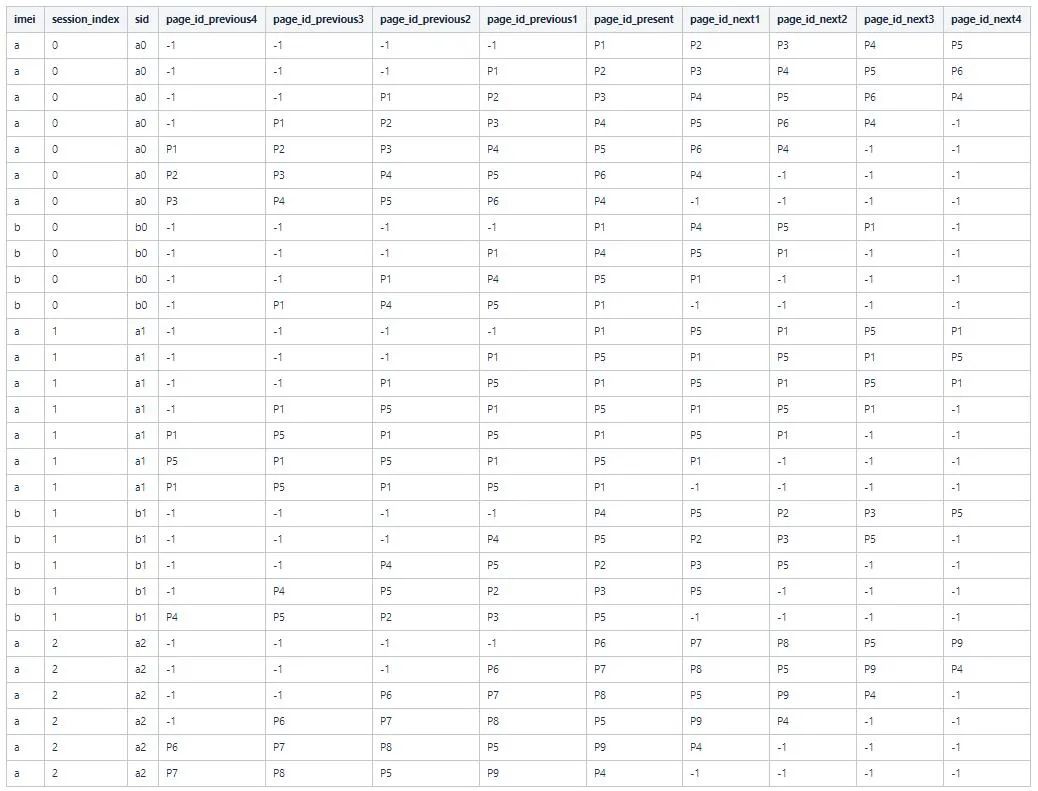
3.3.4 統(tǒng)計正負向路徑的pv/sv
取page和page_id_previous1, page_id_previous2, page_id_previous3 ,page_id_previous4得到負向五級路徑(path_direction為2),取page和page_id_next1, page_id_next2, page_id_next3, page_id_next4得到正向五級路徑(path_direction為1),分別計算路徑的pv和sv(按照sid去重),得到如下數(shù)據(jù)dfSessions,
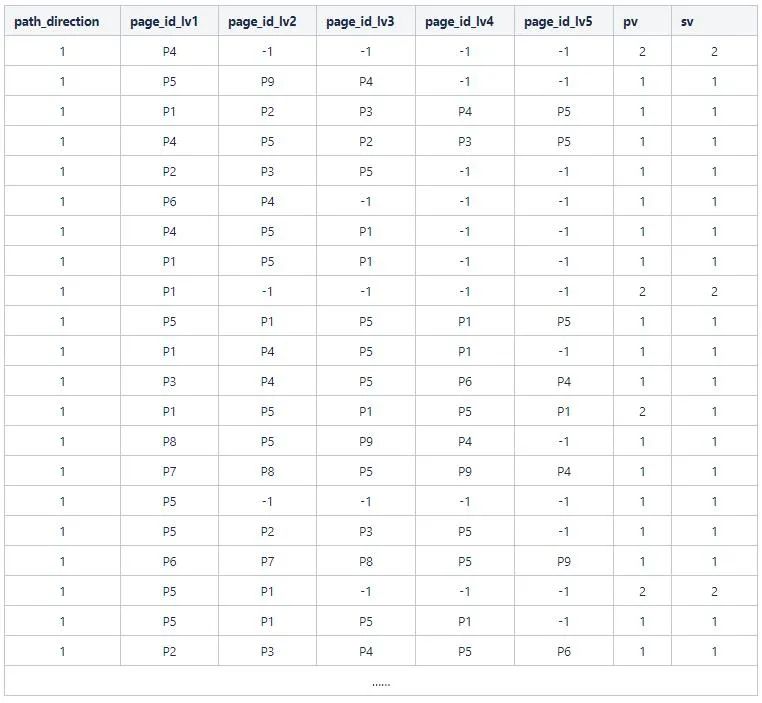
直接看上面的數(shù)據(jù)可能比較茫然,所以這里拆出兩條數(shù)據(jù)示例,第一條結果數(shù)據(jù)

圖3.3-4
這是一條正向的(path_direction為1)路徑結果數(shù)據(jù),在下圖中就是從左到右的路徑,對應的兩個路徑如下

圖3.3-5
第二條結果數(shù)據(jù)

圖3.3-6
也是一條正向的路徑結果數(shù)據(jù),其中pv為2,對應的兩個路徑如下,sv為1的原因是這兩條路徑的sid一致,都是用戶a在S1會話中產生的路徑

圖3.3-7
3.3.5 統(tǒng)計計算各級路徑的pv/sv
然后根據(jù)dfSessions數(shù)據(jù),按照page_id_lv1分組計算pv和sv的和,得到一級路徑的pv和sv,一級路徑特殊地會把path_direction設置為0
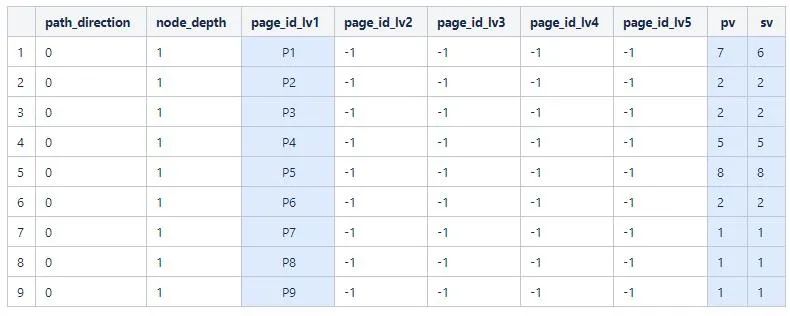
然后類似地分別計算二三四五級路徑的pv和sv,合并所有結果得到如下
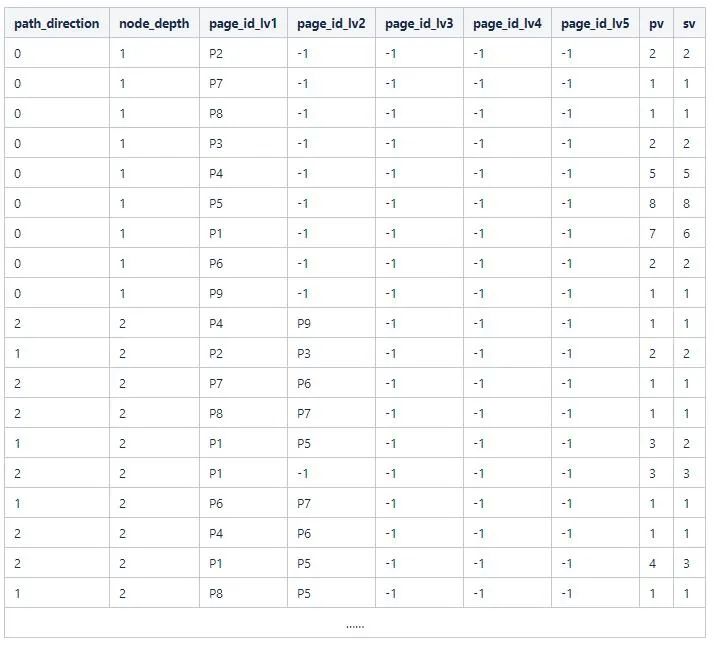
3.4 數(shù)據(jù)寫入
通過Spark分析計算的結果數(shù)據(jù)需要寫入Clickhouse來線上服務,寫入Hive來作為數(shù)據(jù)冷備份,可以進行Clickhouse的數(shù)據(jù)恢復。
Clickhouse表使用的是分布式(Distributed)表結構,分布式表本身不存儲任何數(shù)據(jù),而是作為數(shù)據(jù)分片的透明代理,自動路由到數(shù)據(jù)到集群中的各個節(jié)點,所以分布式表引擎需要配合其他數(shù)據(jù)表引擎一起使用。用戶路徑分析模型的表數(shù)據(jù)被存儲在集群的各個分片中,分片方式使用隨機分片,在這里涉及到了Clickhouse的數(shù)據(jù)寫入,我們展開講解下。
有關于這一點,在模型初期我們使用的是寫分布式表的方式來寫入數(shù)據(jù),具體的寫入流程如下所示:
客戶端和集群中的A節(jié)點建立jdbc連接,并通過HTTP的POST請求寫入數(shù)據(jù);
A分片在收到數(shù)據(jù)之后會做兩件事情,第一,根據(jù)分片規(guī)則劃分數(shù)據(jù),第二,將屬于當前分片的數(shù)據(jù)寫入自己的本地表;
A分片將屬于遠端分片的數(shù)據(jù)以分區(qū)為單位,寫入目錄下臨時bin文件,命名規(guī)則如:/database@host:port/[increase_num].bin;
A分片嘗試和遠端分片建立連接;
會有另一組監(jiān)聽任務監(jiān)聽上面產生的臨時bin文件,并將這些數(shù)據(jù)發(fā)送到遠端分片,每份數(shù)據(jù)單線程發(fā)送;
遠端分片接收數(shù)據(jù)并且寫入本地表;
A分片確認完成寫入。
通過以上過程可以看出,Distributed表負責所有分片的數(shù)據(jù)寫入工作,所以建立jdbc連接的節(jié)點的出入流量會峰值極高,會產生以下幾個問題:
單臺節(jié)點的負載過高,主要體現(xiàn)在內存、網卡出入流量和TCP連接等待數(shù)量等,機器健康程度很差;
當業(yè)務增長后更多的模型會接入Clickhouse做OLAP,意味著更大的數(shù)據(jù)量,以當前的方式來繼續(xù)寫入的必然會造成單臺機器宕機,在當前沒有做高可用的狀況下,單臺機器的宕機會造成整個集群的不可用;
后續(xù)一定會做ck集群的高可用,使用可靠性更高的ReplicatedMergeTree,使用這種引擎在寫入數(shù)據(jù)的時候,也會因為寫分布式表而出現(xiàn)數(shù)據(jù)不一致的情況。
針對于此數(shù)據(jù)端做了DNS輪詢寫本地表的改造,經過改造之后:
用于JDBC連接的機器的TCP連接等待數(shù)由90下降到25,降低了72%以上;
用于JDBC連接的機器的入流量峰值由645M/s降低到76M/s,降低了88%以上;
用于JDBC連接的機器因分發(fā)數(shù)據(jù)而造成的出流量約為92M/s,改造后這部分出流量清零。
另外,在Distributed表負責向遠端分片寫入數(shù)據(jù)的時候,有異步寫和同步寫兩種方式,異步寫的話會在Distributed表寫完本地分片之后就會返回寫入成功信息,如果是同步寫,會在所有分片都寫入完成才返回成功信息,默認的情況是異步寫,我們可以通過修改參數(shù)來控制同步寫的等待超時時間。
def splitPageSessions(timeSeq: Seq[Long], events: Seq[String], interval: Int)(implicit separator: String): Array[Array[Array[String]]] = {// 參數(shù)中的events是事件集合,timeSeq是相應的事件發(fā)生時間的集合if (events.contains(separator))throw new IllegalArgumentException("Separator should't be in events.")if (events.length != timeSeq.length)throw new Exception("Events and timeSeq not in equal length.")val timeBuf = ArrayBuffer[String](timeSeq.head.toString) // 存儲含有session分隔標識的時間集合val eventBuf = ArrayBuffer[String](events.head) // 存儲含有session分隔標識的事件集合if (timeSeq.length >= 2) {events.indices.tail.foreach { i =>if (timeSeq(i) - timeSeq(i - 1) > interval * 60000) { // 如果兩個事件的發(fā)生時間間隔超過設置的時間間隔,則添加分隔符作為后面劃分session的標識timeBuf += separator;eventBuf += separator}timeBuf += timeSeq(i).toString;eventBuf += events(i)}}val tb = timeBuf.mkString(",").split(s",\\$separator,").map(_.split(",")) // 把集合通過標識符劃分成為各個session下的時間集合val eb = eventBuf.mkString(",").split(s",\\$separator,").map(_.split(",")) // 把集合通過標識符劃分成為各個session下的事件集合tb.zip(eb).map(t => Array(t._1, t._2)) // 把session中的事件和發(fā)生時間對應zip到一起,并把元組修改成數(shù)組類型,方便后續(xù)處理}
3.5 轉化率計算
在前端頁面選擇相應的維度,選中起始頁面:
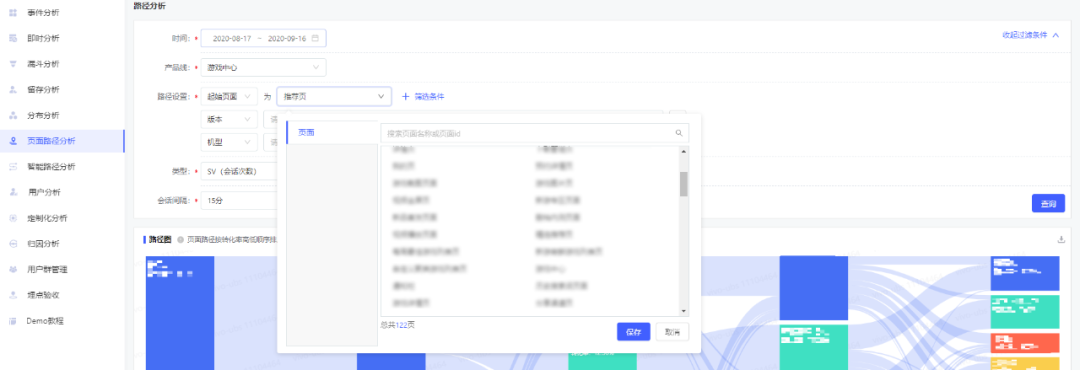
后端會在Clickhouse中查詢,
選定節(jié)點深度(node_depth)為1和一級頁面(page_id_lv1)是選定頁面的數(shù)據(jù),得到一級頁面及其sv/pv,
選定節(jié)點深度(node_depth)為2和一級頁面(page_id_lv1)是選定頁面的數(shù)據(jù),按照sv/pv倒序取前10,得到二級頁面及其sv/pv,
選定節(jié)點深度(node_depth)為2和一級頁面(page_id_lv1)是選定頁面的數(shù)據(jù),按照sv/pv倒序取前20,得到三級頁面及其sv/pv,
選定節(jié)點深度(node_depth)為2和一級頁面(page_id_lv1)是選定頁面的數(shù)據(jù),按照sv/pv倒序取前30,得到四級頁面及其sv/pv,
選定節(jié)點深度(node_depth)為2和一級頁面(page_id_lv1)是選定頁面的數(shù)據(jù),按照sv/pv倒序取前50,得到五級頁面及其sv/pv,
轉化率計算規(guī)則:
頁面轉化率:
假設有路徑 A-B-C,A-D-C,A-B-D-C,其中ABCD分別是四個不同頁面
計算三級頁面C的轉化率:
(所有節(jié)點深度為3的路徑中三級頁面是C的路徑的pv/sv和)÷(一級頁面的pv/sv)
路徑轉化率
假設有A-B-C,A-D-C,A-B-D-C,其中ABCD分別是四個不同頁面
計算A-B-C路徑中B-C的轉化率:
(A-B-C這條路徑的pv/sv)÷(所有節(jié)點深度為3的路徑中二級頁面是B的路徑的pv/sv和)
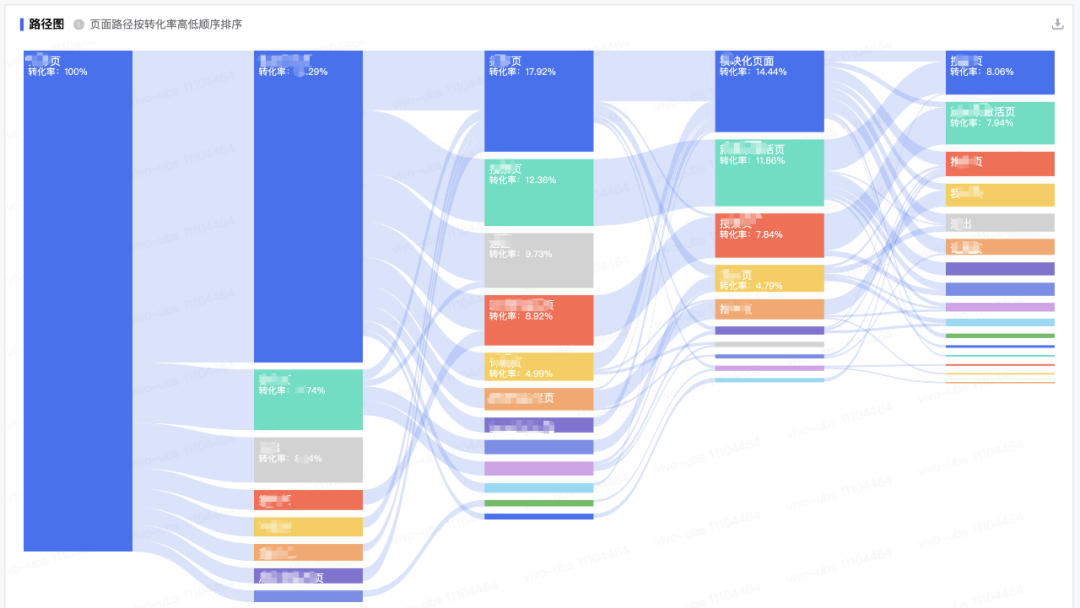
四、工程端架構設計
本節(jié)將講解工程端的處理架構,包括幾個方面:桑基圖的構造、路徑合并以及轉化率計算、剪枝。
4.1 桑基圖的構造
從上述原型圖可以看到,我們需要構造桑基圖,對于工程端而言就是需要構造帶權路徑樹。
簡化一下上圖,就可以將需求轉化為構造帶權樹的鄰接表。如下左圖就是我們的鄰接表設計。左側順序列表存儲的是各個節(jié)點(Vertex),包含節(jié)點名稱(name)、節(jié)點代碼(code)等節(jié)點信息和一個指向邊(Edge)列表的指針;每個節(jié)點(Vertex)指向一個邊(Edge)鏈表,每條邊保存的是當前邊的權重、端點信息以及指向同節(jié)點下一條邊的指針。
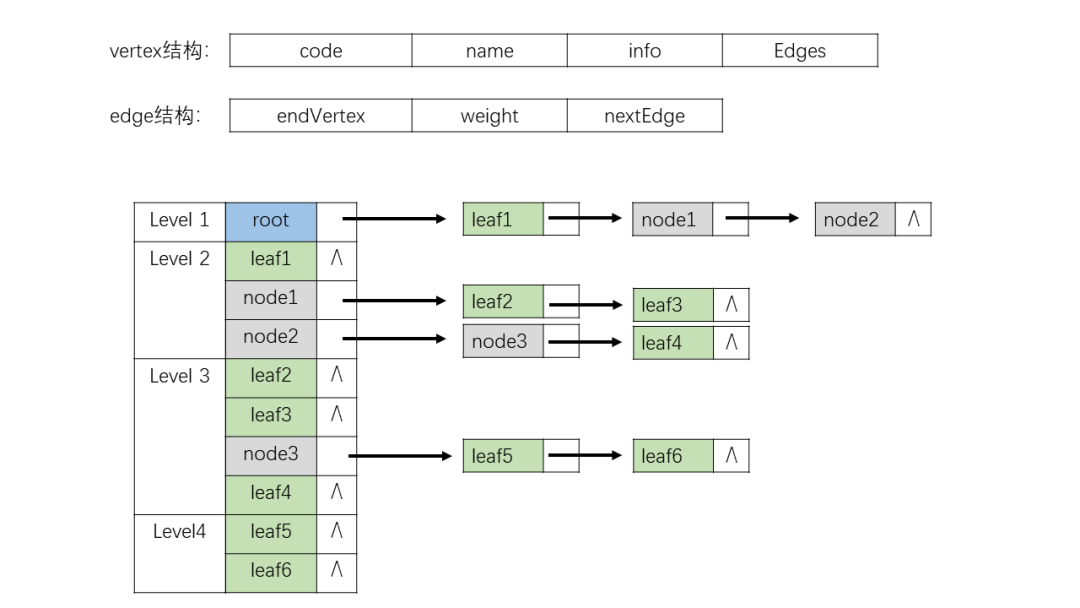
圖4.1-2
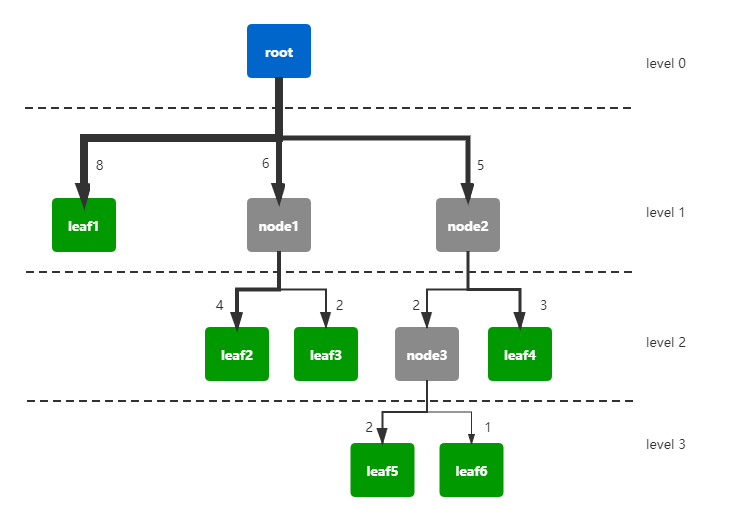
圖4.1-3
圖4.1-2就是我們在模型中使用到的鄰接表。這里在2.4中描述的鄰接表上做了一些改動。在我們的桑基圖中,不同層級會出現(xiàn)相同名稱不同轉化率的節(jié)點,這些節(jié)點作為路徑的一環(huán),并不能按照名稱被看作重復節(jié)點,不構成環(huán)路。如果整個桑基圖用一個鄰接表表示,那么這類節(jié)點將被當作相同節(jié)點,使得圖像當中出現(xiàn)環(huán)路。因此,我們將桑基圖按照層級劃分,每兩級用一個鄰接表表示,如圖4.1-2,Level 1表示層級1的節(jié)點和指向層級2的邊、Level 2表示層級2的節(jié)點指向層級3的邊,以此類推。
4.2 路徑的定義
首先,我們先回顧一下桑基圖:
圖4.2-1
觀察上圖可以發(fā)現(xiàn),我們需要計算四個數(shù)據(jù):每個節(jié)點的pv/sv、每個節(jié)點的轉化率、節(jié)點間的pv/sv、節(jié)點間的轉化率。那么下面我們給出這幾個數(shù)據(jù)的定義:
節(jié)點pv/sv = 當前節(jié)點在當前層次中的pv/sv總和
節(jié)點轉化率 = ( 節(jié)點pv/sv ) / ( 路徑起始節(jié)點pv/sv )
節(jié)點間pv/sv = 上一級節(jié)點流向當前節(jié)點的pv/sv
節(jié)點間轉化率 = ( 節(jié)點間pv/sv ) / ( 上一級節(jié)點pv/sv )
再來看下存儲在Clickhouse中的路徑數(shù)據(jù)。先來看看表結構:
(`node_depth` Int8 COMMENT '節(jié)點深度,共5個層級深度,枚舉值1-2-3-4-5' CODEC(T64, LZ4HC(0)),`page_id_lv1` String COMMENT '一級頁面,起始頁面' CODEC(LZ4HC(0)),`page_id_lv2` String COMMENT '二級頁面' CODEC(LZ4HC(0)),`page_id_lv3` String COMMENT '三級頁面' CODEC(LZ4HC(0)),`page_id_lv4` String COMMENT '四級頁面' CODEC(LZ4HC(0)),`page_id_lv5` String COMMENT '五級頁面' CODEC(LZ4HC(0)))
上述為路徑表中比較重要的幾個字段,分別表示節(jié)點深度和各級節(jié)點。表中的數(shù)據(jù)包含了完整路徑和中間路徑。完整路徑指的是:路徑從起點到退出、從起點到達指定終點,超出5層的路徑當作5層路徑來處理。中間路徑是指數(shù)據(jù)計算過程中產生的中間數(shù)據(jù),并不能作為一條完整的路徑。
路徑數(shù)據(jù):
(1)完整路徑


(2)不完整路徑

那么我們需要從數(shù)據(jù)中篩選出完整路徑,并將路徑數(shù)據(jù)組織成樹狀結構。
4.3 設計實現(xiàn)
4.3.1 整體框架
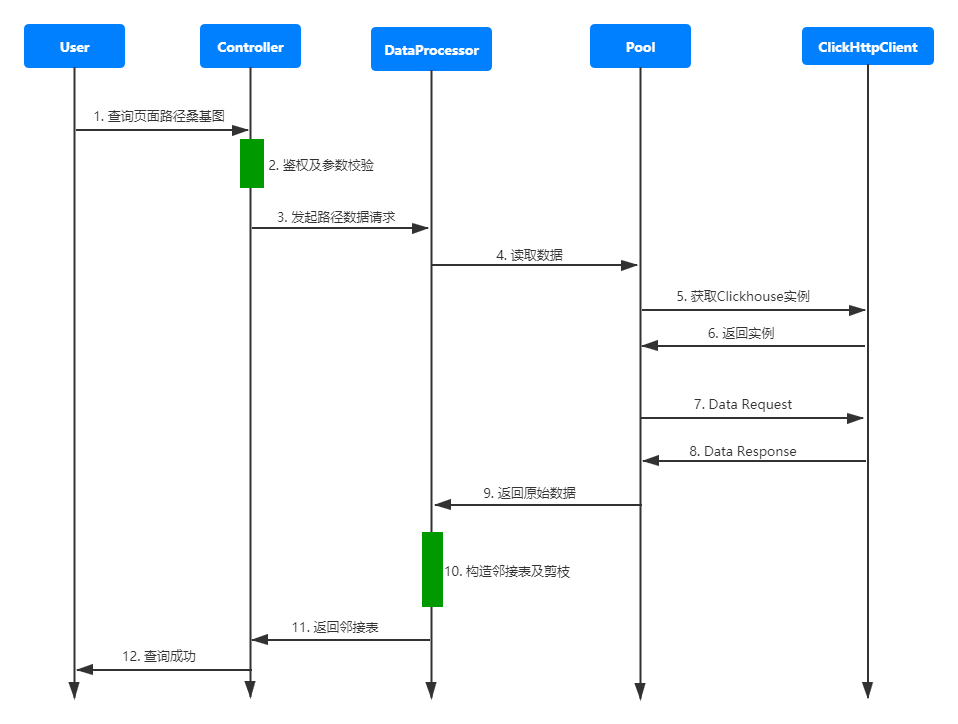
圖4.3-1
后端整體實現(xiàn)思路很明確,主要步驟就是讀取數(shù)據(jù)、構造鄰接表和剪枝。那么要怎么實現(xiàn)完整/非完整路徑的篩選呢?我們通過service層剪枝來過濾掉不完整的路徑。以下是描述整個流程的偽代碼:
// 1-1: 分層讀取原始數(shù)據(jù)// 1-1-1: 分層構造Clickhouse Sqlfor( int depth = 1; depth <= MAX_DEPTH; depth ++){sql.append(select records where node_depth = depth)}// 1-1-2: 讀取數(shù)據(jù)clickPool.getClient();records = clickPool.getResponse(sql);// 2-1: 獲取節(jié)點之間的父子、子父關系(雙向edge構造)findFatherAndSonRelation(records);findSonAndFathRelation(records);// 3-1: 剪枝// 3-1-1: 清除孤立節(jié)點for(int depth = 2; depth <= MAX_DEPTH; depth ++){while(hasNode()){node = getNode();if node does not have father in level depth-1:cut out node;}}// 3-1-2: 過濾不完整路徑for(int depth = MAX_DEPTH - 1; depth >= 1; depth --){cut out this path;}// 3-2: 構造鄰接表while(node.hasNext()){sumVal = calculate the sum of pv/sv of this node until this level;edgeDetails = get the details of edges connected to this node and the end point connected to the edges;sortEdgesByEndPoint(edgeDetails);path = new Path(sumVal, edgeDetails);}
4.3.2 Clickhouse連接池
頁面路徑中我們引入了ClickHouse,其特點在這里不再贅述。我們使用一個簡單的Http連接池連接ClickHouse Server。連接池結構如下:
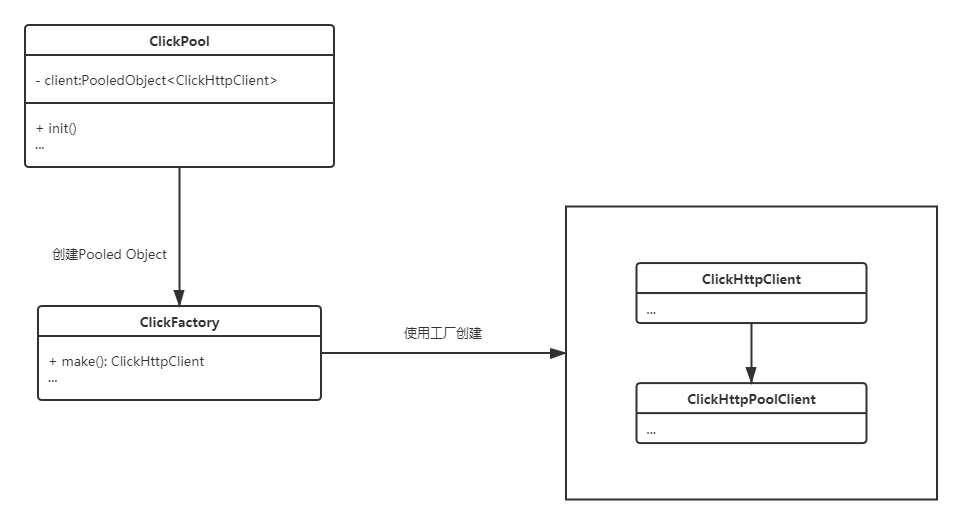
圖4.3-2
4.3.3 數(shù)據(jù)讀取
如2中描述的,我們需要讀取數(shù)據(jù)中的完整路徑。
(`node_depth` Int8 COMMENT '節(jié)點深度,枚舉值',`page_id_lv1` String COMMENT '一級頁面,起始頁面',`page_id_lv2` String COMMENT '二級頁面',`page_id_lv3` String COMMENT '三級頁面',`page_id_lv4` String COMMENT '四級頁面',`page_id_lv5` String COMMENT '五級頁面',`val` Int64 COMMENT '全量數(shù)據(jù)value')
在上述表結構中可以看到,寫入數(shù)據(jù)庫的路徑已經是經過一級篩選,深度≤5的路徑。我們需要在此基礎上再將完整路徑和不完整路徑區(qū)分開,根據(jù)需要根據(jù)node_depth和page_id_lvn來判斷是否為完整路徑并計算每個節(jié)點的value。
完整路徑判斷條件:
node_depth=n, page_id_lvn=pageId (n < MAX_DEPTH)
node_depth=n, page_id_lvn=pageId || page_id_lvn=EXIT_NODE (n = MAX_DEPTH)
完整路徑的條件我們已經知道了,那么讀取路徑時有兩種方案。方案一:直接根據(jù)上述條件進行篩選來獲取完整路徑,由于Clickhouse及后端性能的限制,取數(shù)時必須limit;方案二:逐層讀取,可以計算全量數(shù)據(jù),但是無法保證取出準確數(shù)量的路徑。
通過觀察發(fā)現(xiàn),數(shù)據(jù)中會存在重復路徑,并且假設有兩條路徑:
A → B → C → D → EXIT_NODE
A → B → E → D → EXIT_NODE
當有以上兩條路徑時,需要計算每個節(jié)點的value。而在實際數(shù)據(jù)中,我們只能通過不完整路徑來獲取當前節(jié)點的value。因此,方案一不適用。
那么方案二就可以通過以下偽代碼逐層讀取:
for(depth = 1; depth <= MAX_DEPTH; depth++){selectnode_depth as nodeDepth,...,sum(sv) as valfromtable_namewhere...AND (toInt16OrNull(pageId1) = 45)AND (node_depth = depth)...group bynode_depth,pageId1,pageId2,...ORDER BY...LIMIT...}
讀取出的數(shù)據(jù)如下:
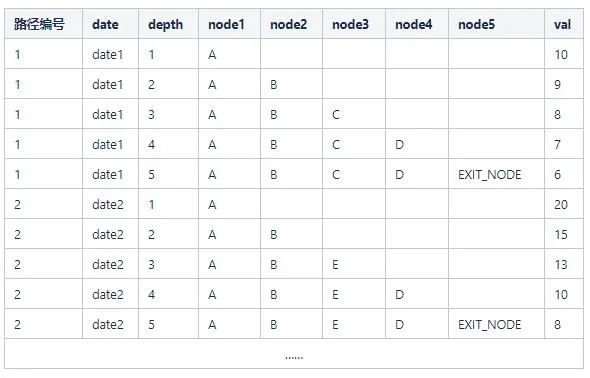
那么,node1_A_val = 10+20,node2_B_val = 9+15 以此類推。
4.3.4 剪枝
根據(jù)4.3.3,在取數(shù)階段我們會分層取出所有原始數(shù)據(jù),而原始數(shù)據(jù)中包含了完整和非完整路徑。如下圖是直接根據(jù)原始數(shù)據(jù)構造的樹(原始樹)。按照我們對完整路徑的定義:路徑深度達到5且結束節(jié)點為退出或其它節(jié)點;路徑深度未達到5且結束節(jié)點為退出。可見,圖中標紅的部分(node4_lv1 → node3_lv2)是一條不完整路徑。
另外,原始樹中還會出現(xiàn)孤立節(jié)點(綠色節(jié)點node4_lv2)。這是由于在取數(shù)階段,我們會對數(shù)據(jù)進行分層排序再取出,這樣一來無法保證每層數(shù)據(jù)的關聯(lián)性。因此,node4_lv2節(jié)點在lv2層排序靠前,而其前驅、后繼節(jié)點排序靠后無法選中,從而導致孤立節(jié)點產生。
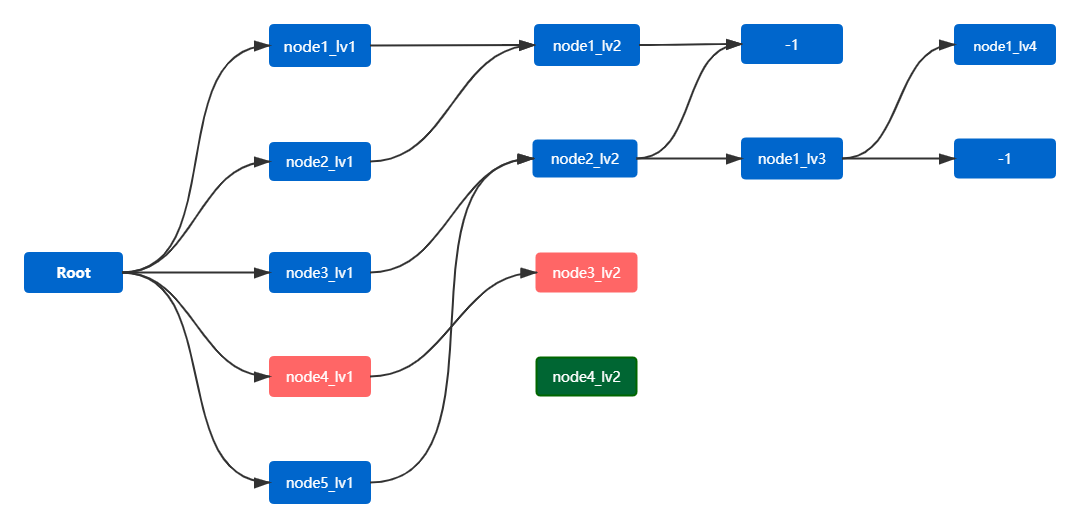
圖4.3-3
因此,在我們取出原始數(shù)據(jù)集后,還需要進行過濾才能獲取我們真正需要的路徑。
在模型中,我們通過剪枝來實現(xiàn)這一過濾操作。
// 清除孤立節(jié)點for(int depth = 2; depth <= MAX_DEPTH; depth ++){while(hasNode()){node = getNode();if node does not have any father and son: // [1]cut out node;}}// 過濾不完整路徑for(int depth = MAX_DEPTH - 1; depth >= 1; depth --){cut out this path; // [2]}
在前述的步驟中,我們已經獲取了雙向edge列表(父子關系和子父關系列表)。因此在上述偽代碼[1]中,借助edge列表即可快速查找當前節(jié)點的前驅和后繼,從而判斷當前節(jié)點是否為孤立節(jié)點。
同樣,我們利用edge列表對不完整路徑進行裁剪。對于不完整路徑,剪枝時只需要關心深度不足MAX_DEPTH且最后節(jié)點不為EXIT_NODE的路徑。那么在上述偽代碼[2]中,我們只需要判斷當前層的節(jié)點是否存在順序邊(父子關系)即可,若不存在,則清除當前節(jié)點。
五、寫在最后
基于平臺化查詢中查詢時間短、需要可視化的要求,并結合現(xiàn)有的存儲計算資源以及具體需求,我們在實現(xiàn)中將路徑數(shù)據(jù)進行枚舉后分為兩次進行合并,第一次是同一天內對相同路徑進行合并,第二次是在日期區(qū)間內對路徑進行匯總。本文希望能為路徑分析提供參考,在使用時還需結合各業(yè)務自身的特性進行合理設計,更好地服務于業(yè)務。
方案中涉及到的Clickhouse在這里不詳細介紹,感興趣的同學可以去深入了解,歡迎和筆者一起探討學習。