
「Python數據分析系列」數據科學基本介紹
作者 | Joel Grus
譯者 | cloverErna
校對 | gongyouliu
編輯 | auroral-L
第一章 數據科學基本介紹
1.1數據的崛起
1.2什么是數據科學
1.3激勵假設:DataSciencester
1.3.1尋找關鍵聯系人
1.3.2你可能知道的數據科學家
1.3.3工資和工作年限
1.3.4付費賬戶
1.3.5感興趣的主題
1.3.6展望
1.1 數據的崛起
生活中,數據無處不在。網站會記錄每個用戶的每次點擊。智能手機會記錄你每時每刻的位置和速度。“量化自我的人”戴著智能計步器記錄自己的心率、運動習慣、飲食習慣和睡眠模式。智能汽車記錄駕駛習慣,智能家居記錄生活習慣,智能購物設備記錄購買習慣。互聯網本就是一幅巨大的知識圖譜,其中包括(除此之外)有無數交叉引用的百科全書,如電影、音樂、體育賽事、彈球機、表情包、雞尾酒等特定領域的數據庫,以及很多政府部門發(fā)布的不計其數的統(tǒng)計數據(其中一些還挺真實的) 充斥在你的頭腦中。
在這些數據中隱藏著無數問題的答案,有些問題甚至無人提及。我們將在本書中學習如何找到這些答案。
1.2 什么是數據科學
有一個笑話說,數據科學家是計算機科學家中的統(tǒng)計學家,也是統(tǒng)計學家中的計算機科學家。(哈哈,好像并不好笑。)事實上,一些數據科學家從實際的角度看就是統(tǒng)計學家,而其他數據科學家則與軟件工程師沒什么區(qū)別。有些數據科學家是機器學習專家,有些數據科學家則在機器學習方面知之甚少。有些數據科學家是博士,出版過令人印象深刻的學術作品,而有些數據科學家卻從未閱讀過學術論文(這有點尷尬)。所以說,無論如何定義數據科學,你都會發(fā)現有些數據科學從業(yè)者與那些定義完全不相稱。
盡管如此,這并不能阻止我們嘗試定義數據科學家。我們會說數據科學家是從凌亂的數據中提取有用信息的人。今天,世界各地有無數人在此領域耕耘。
例如,交友網站 OkCupid 要求其會員回答成百上千個問題,以便為他們找到最合適的交友對象。但它也會分析這些聽起來無害的問題,比如你可以從某人回答的問題中得出他/她有多可能在第一次約會時和你上床。
Facebook 要求你填寫家鄉(xiāng)位置和居住位置的信息,表面上是為了讓你的朋友更容易找到你并與你聯系,但它也會分析這些位置,以研究全球移民模式以及各個橄欖球隊的粉絲群的分布情況。
大型零售商 Target 會跟蹤你線上和線下的購買習慣和互動習慣。它使用這些數據預測哪些顧客懷孕了,以便更好地向她們推銷母嬰商品。
2012年,奧巴馬的競選團隊雇用了數十名數據科學家,他們通過數據挖掘和實驗的方式來識別需要額外關注的選民,選擇最佳的針對特定捐助者的籌款呼吁和方案,并將投票努力集中在最有可能有用的地方。在2016年,特朗普的競選活動測試了令人震驚的各種在線廣告,并分析了這些數據,以找出哪些是有效的,哪些是無效的。
現在,如果你開始覺得上面的例子枯燥,那么讓我們看一些更有意義的善舉:一些數據科學家偶爾會利用他們的技能提高政府的工作效率,幫助無家可歸者,并改善公共健康等。當然,如果你能想出提高廣告點擊率的好方法,這同樣會對你的職業(yè)生涯有幫助。
1.3 激勵假設:DataSciencester
恭喜!你剛剛被聘請來領導 DataSciencester 的數據科學工作。DataSciencester 是數據科學家的社交網絡。
雖然是為數據科學家服務,但 DataSciencester 從未真正實踐數據科學工作。(公正地說,DataSciencester 從未真正構建自己的產品。)這是你的工作!在本書中,我們將通過解決在工作中遇到的實際問題來學習數據科學的概念。我們有時會研究用戶直接提供的數據,有時會研究用戶與網站交互生成的數據,有時甚至會研究我們自己設計的實驗所產生的數據。
由于 DataSciencester 具有強大的原創(chuàng)精神,因此我們將從頭開始構建自己的工具。完成這些工作后,你會對數據科學的基礎知識有一個非常深刻的理解。你能將這項技能應用于更有前景的公司,或者著手解決任何有趣的問題。
歡迎加入 DataSciencester,祝你好運!(星期五可以穿牛仔褲上班,衛(wèi)生間在大廳的右邊。)
1.3.1 尋找關鍵聯系人
這是你在DataSciencester工作的第一天,網絡部副總有一堆關于用戶的問題沒有解決。以前他都沒有能討教的人,現在你來了,他很高興。
具體來說,他希望你確定誰是數據科學家中的“關鍵聯系人”。為此,他為你提供了整個DataSciencester用戶網絡的數據。(在實際工作中,人們通常不會向你提供所需的數據。第9章專門討論了獲取數據的方法。)
這是些什么樣的數據呢?它是一個用戶信息列表,每一行都由包含用戶ID(即id,一串數字)和用戶名稱(即name)的字典(dict)組成:
users = [{ "id": 0, "name": "Hero" },{ "id": 1, "name": "Dunn" },{ "id": 2, "name": "Sue" },{ "id": 3, "name": "Chi" },{ "id": 4, "name": "Thor" },{ "id": 5, "name": "Clive" },{ "id": 6, "name": "Hicks" },{ "id": 7, "name": "Devin" },{ "id": 8, "name": "Kate" },{ "id": 9, "name": "Klein" }]
他還為你提供了“朋友關系”的數據,這是由一對對 ID 組成的列表:

例如,元組 (0, 1) 表示 id 為 0 的數據科學家 Hero 和 id 為 1 的數據科學家 Dunn 是朋友。用戶關系網絡見圖 1-1。
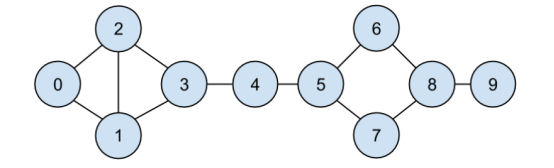
將朋友關系表示為元組(pairs)的列表并不是最簡單的表示方法。如果要找到用戶1的所有朋友,你必須迭代每個元組對以尋找哪個包含1。如果你有很多元組對,則會需要很長時間。
相反,讓我們創(chuàng)建一個dict,其中鍵(key)是用戶id,對應的值(value)是朋友id的列表。(dict的查詢效率非常高。)
我們仍需要查看每一對元組來創(chuàng)建 dict,但只需執(zhí)行一次,之后我們將可以方便地查找:

現在 dict 中有了朋友關系的列表,我們可以輕松地根據圖中內容來提問,例如:“每個用戶平均擁有多少個朋友?”
首先通過對所有用戶的朋友列表長度求和,來找到連接總數:


然后將其除以用戶數:

這樣,如果我們找到擁有最多朋友的用戶,就找到了擁有最多聯系人的用戶。
由于用戶不多,因此我們也能很容易地按照用戶朋友數量從多到少將他們排序:

我們剛剛所做事情的一種解讀是,識別人際關系網絡中心節(jié)點的一種方法。事實上,我們剛剛計算的是度中心性(degree centrality),這是一種網絡度量(見圖 1-2)。
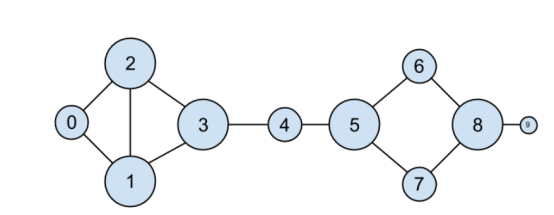
度中心性很容易計算,但它并不總能給出理想或期望的結果。例如,在 DataSciencester 網絡中,Thor(id 為 4)只有 2 個朋友,而 Dunn(id 為 1)有3個。然而,在網絡關系圖上,直覺上認為Thor應該更具中心性。在第22章中,我們將更詳細地研究網絡,并探討更復雜的中心性概念,這些概念可能與我們的直覺一致,也可能不一致。
1.3.2 你可能知道的數據科學家
當你正在填寫新員工入職表時,人力部副總走到你桌旁。他希望鼓勵會員之間建立更多聯系,因此要求你設計一個“你可能知道的數據科學家”的提示函數。
你的第一直覺是用戶可能知道他們朋友的朋友。因此你寫了一些代碼,依次迭代計算每個用戶的朋友信息,并收集其朋友的朋友的信息:

當我們對 user[0](Hero)調用這個函數時,它的結果如下所示:

這個列表中用戶 0 出現了兩次,因為 Hero 確實是他的兩個朋友的朋友。雖然用戶 1 和用戶 2 已經是 Hero 的朋友,但這個列表中還是包括了用戶 1 和用戶 2。因為 Chi 可通過兩個不同的朋友聯系到,所以 3 也出現了兩次:

有趣的是,人們能通過多種方式成為朋友的朋友。受此啟發(fā),或許我們可以換一種數(count)共同朋友的方式來試著解決這個問題。我們應該排除已成為朋友的用戶:

這個結果正確地說明 Chi(id 為 3)與 Hero(id 為 0)有兩個共同的朋友,但與 Clive(id 為 5)只有一個共同的朋友。
作為一名數據科學家,你知道你可能也喜歡結交擁有共同興趣的用戶。(這是展示數據科學的“專業(yè)技能”的一個很好的例子。)在問了一圈人之后,你開始處理數據,設計出如下列表,其中每個元素都是成對的數據 (user_id, interest):

例如,Hero(id 為 0)與 Klein(id 為 9)沒有任何共同的朋友,但他們對 Java 和大數據都感興趣。
構建一個函數來查找具有特定興趣的用戶很容易:

這非常有效,但上面的算法每次搜索都需要遍歷整個興趣列表。如果用戶很多或用戶的興趣很多(或者我們只是想多進行一些搜索),則最好建立一個從興趣到用戶的索引:
另一個從用戶到興趣的索引:

現在很容易找到與給定用戶擁有最多共同興趣的用戶。
1.迭代用戶的興趣。
2.對于每個興趣,迭代尋找具有該興趣的其他用戶。
3.記錄每個用戶在每次迭代中出現的次數。
代碼如下所示:
然后,結合共同的朋友和共同的興趣,我們可以建立一個更全面的“你可能知道的數據科學家”的特征。第23章將繼續(xù)探討這類應用。
1.3.3 工資和工作年限
你準備去吃午飯時,公共關系部副總問你,是否可以提供一些有關數據科學家收入的有趣信息。工資數據相當敏感,因此他設法為你提供了一個匿名數據集,其中包含每個用戶的工資(salary,以美元為單位)和作為數據科學家的工作年限(tenure,以年為單位):

第一步自然是繪制數據的散點圖(第 3 章將介紹如何實現),你可以在圖 1-3 中看到結果。
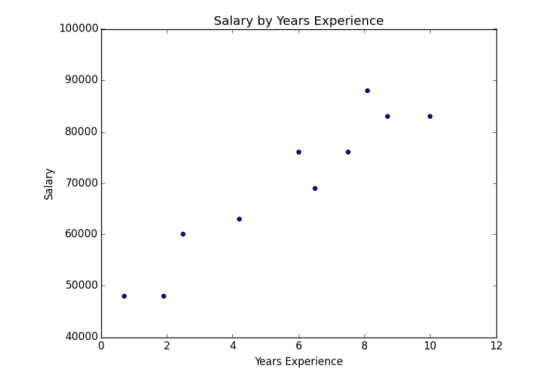
顯然,經驗豐富的人往往收入更高。怎么才能把這變成一個有趣的事實呢?第一個想法是查看每個任期的平均工資:

事實證明這并不是特別有說服力,因為任意兩個用戶的工作年限都不同,這意味著我們只是報告了用戶的個人工資狀況:

可能把工作年限分組以后會更有意義:

然后可以將每個組對應的工資合并在一起:
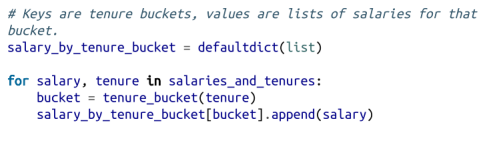
最后計算每組的平均工資:


這個結果看起來更有趣:

現在你可以說:“擁有 5 年以上工作經驗的數據科學家比新人收入高 65% !”
但是,我們是以非常隨意的方式分組的。我們原本希望說明的是多一年工作經驗對平均工資的影響。除了發(fā)現一個更有趣的現象外,這使我們能夠對不知道的工資做出預測。第 14 章將探討這個想法。
1.3.4 付費賬戶
當你回到辦公桌前,收益部副總正在等你。他希望更好地了解哪些用戶會為賬戶付款,哪些用戶不會。(他知道用戶的名字,但這不是特別有用。)
你注意到多年經驗與付費賬戶之間似乎存在某種對應關系:
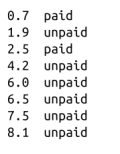
工作經驗很少和工作經驗豐富的用戶傾向于付費,而有一些工作經驗的用戶則不會。因此,如果你想創(chuàng)建一個模型——即使這些數據不足以建立模型——你可能會嘗試將工作經驗很少和工作經驗豐富的用戶預測為“付費”,而將有一些經驗的用戶預測為“不付費”:

當然,我們會持續(xù)關注這個人工經驗模型。
隨著更多數據(和更多數學知識)的引入,我們可以建立一個模型,根據用戶的工作年限預測他付費的可能性。第16章將研究這類問題。
1.3.5 感興趣的主題
當你正準備結束第一天的工作時,內容策略部副總來向你要數據,他想了解用戶最感興趣的主題,以便可以相應地規(guī)劃他的博客日歷。你已擁有來自朋友推薦項目的原始數據:


找到最受歡迎的興趣的一種簡單(并不是特別令人興奮)的方法是計算興趣詞匯的個數:
1.小寫每個興趣(因為不同的用戶可能不會小寫他們的興趣);
2.將其分成單詞;
3.數結果。
代碼如下所示:

這樣可以輕松列出多次出現的單詞:

它給出了你期望的結果(除非你期望“scikit-learn”被分成兩個單詞,那樣就不會得到預期的結果了):

第21章將介紹從數據中提取主題的更復雜的方法。
1.3.6 展望
第一天非常成功!你一定很累,趕緊在有人繼續(xù)問問題之前回家吧。晚上好好休息,明天要參加新員工入職培訓。(是的,在入職培訓前,你已工作了一整天。明天去人力資源部報到吧。)
相關閱讀: