
如何用「邏輯回歸」構建金融評分卡模型?(上)
市面上關于lr?的書籍和文章大部分的講解都是針對?lr一些基本理論或者一些推導公式。掌握這些還遠遠不夠,要想讓lr發(fā)揮其最大效果,必須要有一套科學的、嚴密的數(shù)據(jù)預處理流程。
和市面上對lr算法的講解不同,本文將以金融評分卡模型為例,講解一整套lr配套的數(shù)據(jù)處理流程,包括數(shù)據(jù)獲取,EDA (探索性數(shù)據(jù)分析),數(shù)據(jù)預處理,到變量篩選,lr模型的開發(fā)和評估,生成評分卡模型。希望大家在閱讀本篇文章之后能夠輕松駕馭lr算法。
1. 評分卡模型的背景知識
風控顧名思義就是風險控制,指風險管理者采取各種措施和方法,消滅或減少風險事件發(fā)生的各種可能性,或風險事件發(fā)生時造成的損失。
信用評分卡模型是最常見的金融風控手段之一,它是指根據(jù)客戶的各種屬性和行為數(shù)據(jù),利用一定的信用評分模型,對客戶進行信用評分,據(jù)此決定是否給予授信以及授信的額度和利率,從而識別和減少在金融交易中存在的交易風險。
評分卡模型在不同的業(yè)務階段體現(xiàn)的方式和功能也不一樣。按照借貸用戶的借貸時間,評分卡模型可以劃分為以下三種:
貸前:申請評分卡(Application score card),又稱為A卡
貸中:行為評分卡(Behavior score card),又稱為B卡
貸后:催收評分卡(Collection score card),又稱為C卡
以下為評分卡模型的示意圖:
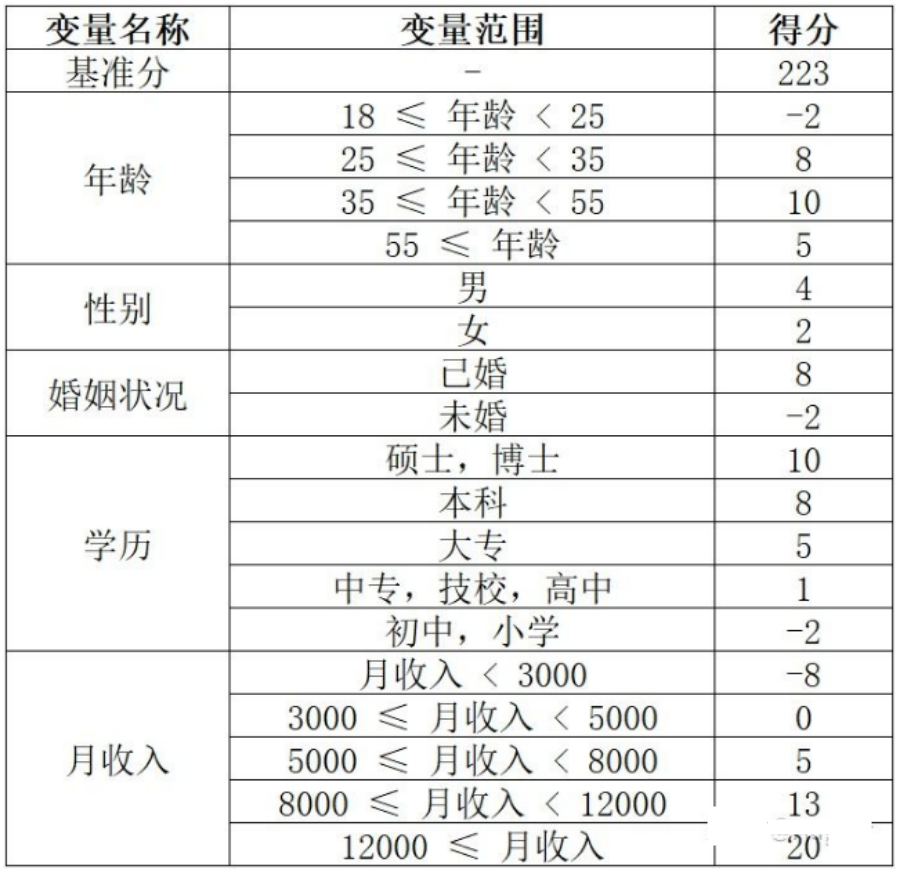
那么怎么利用評分卡對用戶進行評分呢?一個用戶總的評分等于基準分加上對客戶各個屬性的評分。以上面的評分卡為例:
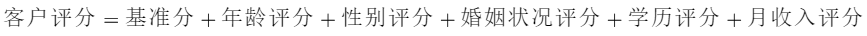
舉個例子某客戶年齡為27歲,性別為男,婚姻狀況為已婚,學歷為本科,月收入為10000,那么他的評分為:
Q1:?請計算以上評分卡模型的最低分和最高分
最低分為基準分與每個字段最低分相加:
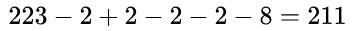
最高分為基準分與每個字段最高分相加:
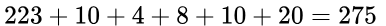
以上我們基本了解了評分卡模型的具體用法,看到以上評分卡案例之后,相信很多人肯定會有以下三個疑問:
用戶的屬性有千千萬萬個維度,而評分卡模型所選用的字段在30個以下,那么怎樣挑選這些字段呢?
評分法卡模型采用的是對每個字段的分段進行評分,那么怎樣對評分卡進行有效分段呢?
最關鍵的,也是大家最關心的問題是怎樣對字段的每個分段進行評分呢?這個評分是怎么來的?
2.評分卡模型的開發(fā)
1.總體流程介紹
信用評分卡的開發(fā)有一套科學的、嚴密的流程,包括數(shù)據(jù)獲取,EDA,數(shù)據(jù)預處理,到變量篩選,lr模型的開發(fā)和評估,生成評分卡模型以及布置上線和模型監(jiān)測。典型的開發(fā)流程如下圖所示:
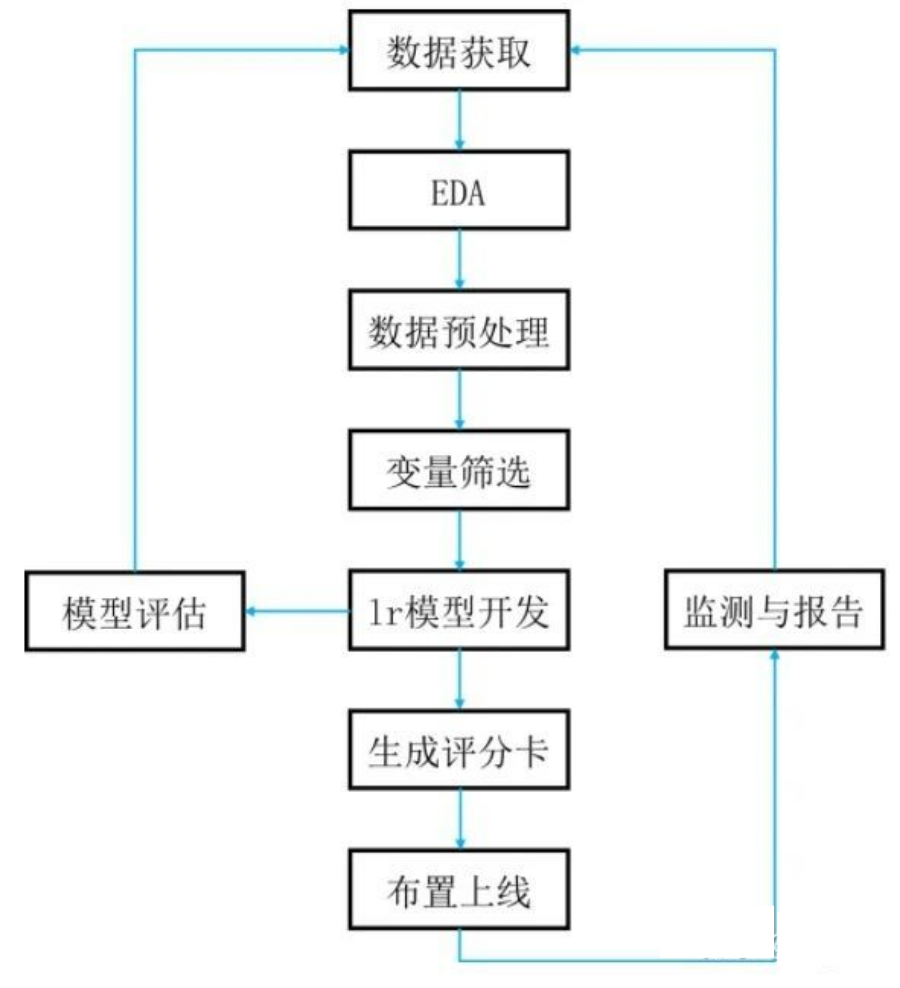
本文僅介紹線下評分卡模型的開發(fā),即數(shù)據(jù)獲取,EDA, 數(shù)據(jù)預處理,變量篩選,lr模型開發(fā),模型評估和生成評分卡。
2.數(shù)據(jù)獲取
數(shù)據(jù)的獲取途徑主要有兩個:
金融機構自身字段:例用戶的年齡,戶籍,性別,收入,負債比,在本機構的借款和還款行為等
第三方機構的數(shù)據(jù):如用戶在其他機構的借貸行為,用戶的消費行為數(shù)據(jù)等
3.EDA(探索性數(shù)據(jù)分析)
該步驟主要是獲取數(shù)據(jù)的大概情況,例如每個字段的缺失值情況、異常值情況、平均值、中位數(shù)、最大值、最小值、分布情況等。以便制定合理的數(shù)據(jù)預處理方案。
4.數(shù)據(jù)預處理
數(shù)據(jù)預處理主要包括數(shù)據(jù)清洗,變量分箱和 WOE 編碼三個步驟。
4.1數(shù)據(jù)清洗
數(shù)據(jù)清洗主要是對原始數(shù)據(jù)中臟數(shù)據(jù),缺失值,異常值進行處理。關于對缺失值和異常值的處理,我們采用的方法非常簡單粗暴,即刪除缺失率超過某一閾值(閾值自行設定,可以為30%,50%,90%等)的變量,將剩余變量中的缺失值和異常值作為一種狀態(tài) 。
4.2變量分箱
在這里我們回答第二個問題評分卡是怎樣對變量進行分段的,評分卡模型通過對變量進行分箱來實現(xiàn)變量的分段。那么什么是分箱呢?以下為分箱的定義:
對連續(xù)變量進行分段離散化
將多狀態(tài)的離散變量進行合并,減少離散變量的狀態(tài)數(shù)
常見的分箱類型有以下幾種,下面將一一講解:
1. 無監(jiān)督分箱
無監(jiān)督的分箱主要包括以下幾類:
等頻分箱:把自變量按從小到大的順序排列,根據(jù)自變量的個數(shù)等分為k部分,每部分作為一個分箱
等距分箱:把自變量按從小到大的順序排列,將自變量的取值范圍分為k個等距的區(qū)間,每個區(qū)間作為一個分箱
聚類分箱:用k-means聚類法將自變量聚為k類,但在聚類過程中需要保證分箱的有序性
由于無監(jiān)督分箱僅僅考慮了各個變量自身的數(shù)據(jù)結構,并沒有考慮自變量與目標變量之間的關系,因此無監(jiān)督分箱不一定會帶來模型性能的提升。
2. 有監(jiān)督分箱
包括 Split 分箱和 Merge 分箱。
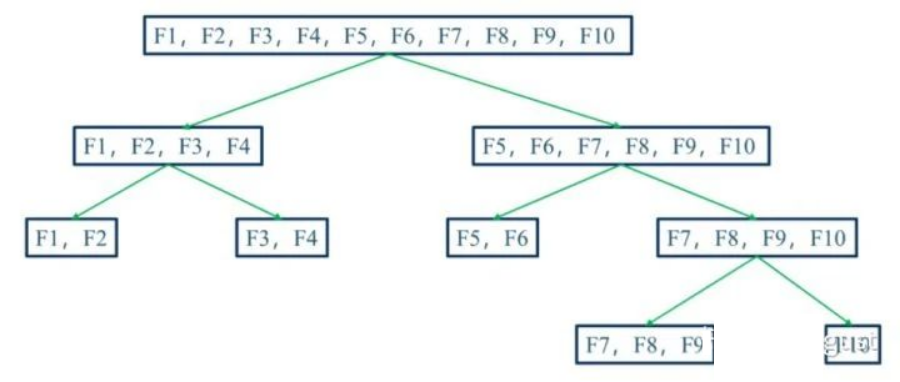
1)Split 分箱是一種自上而下(即基于分裂)的數(shù)據(jù)分段方法。如下圖所示,Split 分箱和決策樹比較相似,切分點的選擇指標主要有 entropy,gini 指數(shù)和 IV 值等。
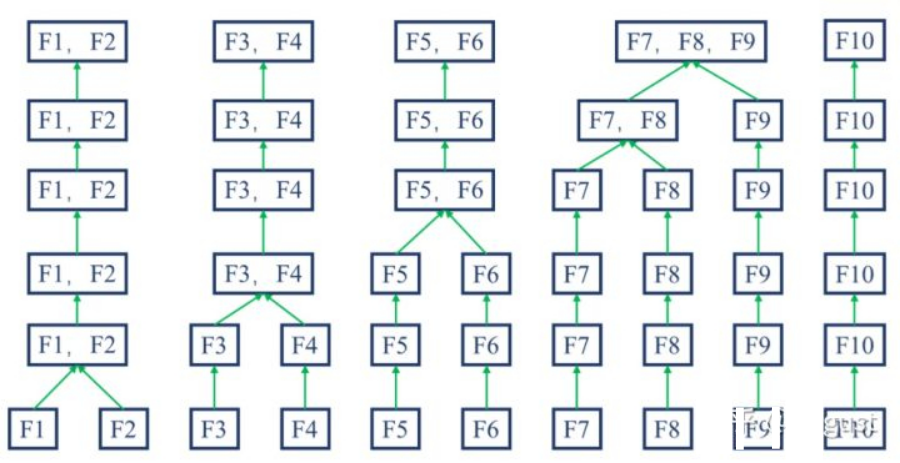
2)Merge 分箱,是一種自底向上(即基于合并)的數(shù)據(jù)離散化方法。如下圖所示為Merge 分箱的示意圖,Merge 分箱常見的類型為Chimerge分箱。
3)Chimerge 分箱是目前最流行的分箱方式之一,其基本思想是如果兩個相鄰的區(qū)間具有類似的類分布,則這兩個區(qū)間合并;否則,它們應保持分開。Chimerge通常采用卡方值來衡量兩相鄰區(qū)間的類分布情況。
3. Chimerge的具體算法如下
1)輸入:分箱的最大區(qū)間數(shù)n
2)初始化
連續(xù)值按升序排列,離散值先轉化為壞客戶的比率,然后再按升序排列
為了減少計算量,對于狀態(tài)數(shù)大于某一閾值 (建議為100) 的變量,利用等頻分箱進行粗分箱
若有缺失值,則缺失值單獨作為一個分箱
3)合并區(qū)間
計算每一對相鄰區(qū)間的卡方值
將卡方值最小的一對區(qū)間合并
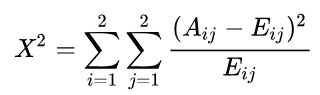

重復以上兩個步驟,直到分箱數(shù)量不大于n
4)分箱后處理
對于壞客戶比例為 0 或 1 的分箱進行合并 (一個分箱內(nèi)不能全為好客戶或者全為壞客戶)
對于分箱后某一箱樣本占比超過 95% 的箱子進行刪除
檢查缺失分箱的壞客戶比例是否和非缺失分箱相等,如果相等,進行合并
5)輸出:分箱后的數(shù)據(jù)和分箱區(qū)間
Q2:?一般一個評分卡模型的有效持續(xù)時間是 1個月左右甚至更長時間,中間也許會有一些客戶的數(shù)據(jù)發(fā)生變化,比如一個月之內(nèi)突然換工作,工資上漲等等,針對這種情況,我們該怎樣處理呢?
這里我們需要假設客戶在短期內(nèi)屬性變化不會太大,即使客戶的屬性變化,只要在同一分箱中,依然會給這個客戶相同的分數(shù)。舉例來說:對于工資我們可以劃分為5箱,即<3000, 3000-5000, 5000-8000, 8000-12000, >12000,假設一個客戶的工資為9000,在一個月內(nèi)工資上漲,那我們就假設這個客戶的工資上漲之后不會超過12000,也就是說依然在8000-12000分箱中。
這樣在考慮客戶工資變化的前提下,不會因為客戶工資的發(fā)生變化而變成了另外一個人,保證了模型的穩(wěn)定性。
Q3:上文說到將變量中的缺失值作為一種狀態(tài)是什么意思?
這里的意思是說讓缺失值單獨分為一箱。
Q4:比如年齡變量中出現(xiàn)“500歲”這種異常字段該怎樣處理?
對于年齡特征我們劃分為4段,即18-25, 25-35, 35-55, > 55,我們可以直接把500劃分到>55這一個分箱中。另外我們也可以通過一些手段檢測出異常值,將異常值單獨分為一箱。
總結一下特征分箱的優(yōu)勢:
特征分箱可以有效處理特征中的缺失值和異常值
特征分箱后,數(shù)據(jù)和模型會更穩(wěn)定
特征分箱可以簡化邏輯回歸模型,降低模型過擬合的風險,提高模型的泛化能力
將所有特征統(tǒng)一變換為類別型變量
分箱后變量才可以使用標準的評分卡格式,即對不同的分段進行評分
End. 作者:August 來源:知乎專欄 本文為轉載分享,如侵權請聯(lián)系后臺刪除