數(shù)據(jù)挖掘|利用Python實(shí)現(xiàn)常用的分類算法
01
數(shù)據(jù)分類
02
分類方法
03
OneR算法
04
代碼實(shí)現(xiàn)
from?sklearn.datasets?import?load_iris
import?numpy?as?np
dataset?=?load_iris()
x?=?dataset.data
y?=?dataset.target
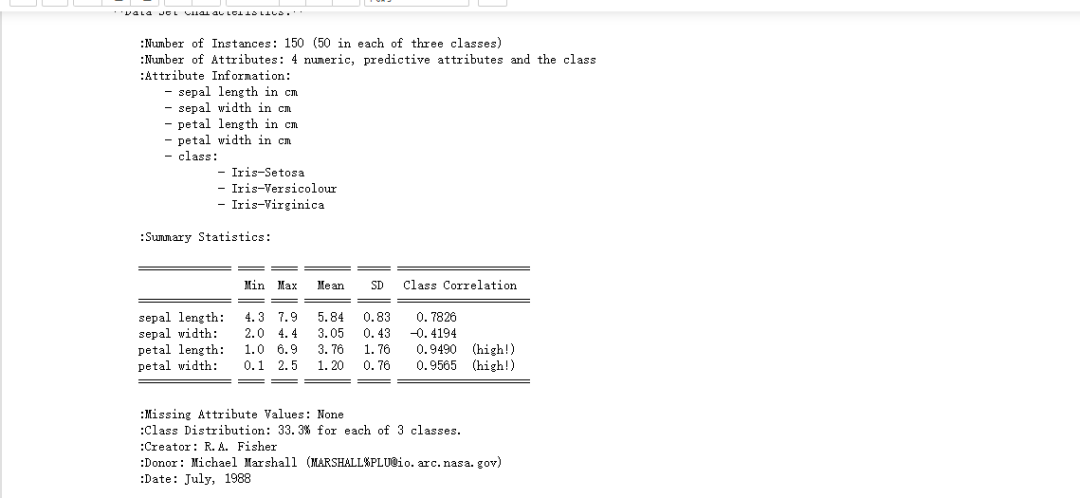
print(dataset.DESCR)
數(shù)據(jù)準(zhǔn)備: import?numpy?as?np
#?data?為特征值
data?=?dataset.data
#?target為分類類別
target?=?dataset.target
average_num?=?data.mean(axis?=?0)
data?=?np.array(data?>?average_num,dtype?=?"int")
#print(dataset)?????#?可以自己嘗試打印看看數(shù)據(jù)內(nèi)容
from?sklearn.model_selection?import?train_test_split
#?隨機(jī)獲得訓(xùn)練和測試集
def?get_train_and_predict_set():?
????#對應(yīng)的參數(shù)意義???data(待劃分樣本數(shù)據(jù))??target(樣本數(shù)據(jù)的結(jié)果)?random_state(設(shè)置隨機(jī)種子,默認(rèn)值為0?如果為0則的話每次隨機(jī)結(jié)果都不一樣,反之是一樣的)
????return?train_test_split(data,target,?random_state=14)
data_train,data_predict,target_train,target_predict?=?get_train_and_predict_set()
2、實(shí)現(xiàn)算法
我們之前就說到,我們是根據(jù)一個規(guī)則來實(shí)現(xiàn)分類的。首先我們先遍歷每個特征的取值,對每個特征的取值,統(tǒng)計(jì)它在不同的類別出現(xiàn)的次數(shù),然后找到最大值,并記錄它在其他類別中出現(xiàn)的次數(shù)(為了統(tǒng)計(jì)錯誤率)。
from?collections?import?defaultdict
from?operator?import?itemgetter
#定義函數(shù)訓(xùn)練特征
def?train_feature(data_train,target_train,index,value):
????"""
????????data_train:訓(xùn)練集特征
????????target_train:訓(xùn)練集類別
????????index:特征值的索引
??????? value :特征值
????"""
????count?=?defaultdict(int)
????for?sample,class_name?in?zip(data_train,target_train):
????????if(sample[index]?==value):
????????????count[class_name]?+=?1
???????#?進(jìn)行排序
????sort_class?=?sorted(count.items(),key=itemgetter(1),reverse?=?True)
????#?擁有該特征最多的類別
????max_class?=?sort_class[0][0]
????max_num?=?sort_class[0][1]
????all_num?=?0
????for?class_name,class_num?in?sort_class:
????????all_num?+=?class_num
#?????print("{}特征,值為{},錯誤數(shù)量為{}".format(index,value,all_num-max_num))
????#?錯誤率
????error?=?1?-?(max_num?/?all_num)
????#最后返回使用給定特征值得到的待預(yù)測個體的類別和錯誤率
????return?max_class,error對于某個特征,遍歷其每一個特征值,每次調(diào)用train_feature這個函數(shù)的時候,我們就可以得到預(yù)測的結(jié)果以及這個特征的最大錯誤率,也可以得到最好的特征以及類型,下面我們進(jìn)行函數(shù)的編寫:
def?train():
????errors?=?defaultdict(int)
????class_names?=?defaultdict(list)
????#?遍歷特征
????for?i?in?range(data_train.shape[1]):
???????#?遍歷特征值?
????????for?j?in?range(0,2):
????????????class_name,error?=?train_feature(data_train,target_train,i,j)
????????????errors[i]?+=?error
????????????class_names[i].append(class_name)????????????
????return?errors,class_names
errors,class_names?=?train()
#?進(jìn)行排序
sort_errors?=?sorted(errors.items(),key=itemgetter(1))
best_error?=?sort_errors[0]
best_feature?=?best_error[0]
best_class?=?class_names[best_feature]
print("最好的特征是{}".format(best_error[0]))
print(best_class)3、測試算法 #?進(jìn)行預(yù)測
def?predict(data_test,feature,best_class):
????return?np.array([best_class[int(data[feature])]?for?data?in?data_test])
result_predict?=?predict(data_predict,best_feature,best_class)
print("預(yù)測準(zhǔn)確度{}".format(np.mean(result_predict?==?target_predict)?*?100))
print("預(yù)測結(jié)果{}".format(result_predict))
我們可以發(fā)現(xiàn)預(yù)測的準(zhǔn)確度為65.79%,這個準(zhǔn)確度對于OneR算法來說已經(jīng)很高啦!到此OneR算法完成啦!再次強(qiáng)調(diào)歡迎大家的指導(dǎo)批評,謝謝!
參考文獻(xiàn):
https://github.com/xiaohuiduan/data_mining?
E?N?D
各位伙伴們好,詹帥本帥搭建了一個個人博客和小程序,匯集各種干貨和資源,也方便大家閱讀,感興趣的小伙伴請移步小程序體驗(yàn)一下哦!(歡迎提建議)
推薦閱讀
牛逼!Python常用數(shù)據(jù)類型的基本操作(長文系列第①篇)
牛逼!Python的判斷、循環(huán)和各種表達(dá)式(長文系列第②篇)