
ICML 2021 (Long Oral) | 深入研究不平衡回歸問題
點擊上方“程序員大白”,選擇“星標”公眾號
重磅干貨,第一時間送達


導讀
本文介紹了一篇被ICML2021接收的工作:Long oral presentation:Delving into Deep Imbalanced Regression。該工作推廣了傳統(tǒng)不平衡分類問題的范式,將數(shù)據不平衡問題從離散值域推廣到連續(xù)域。

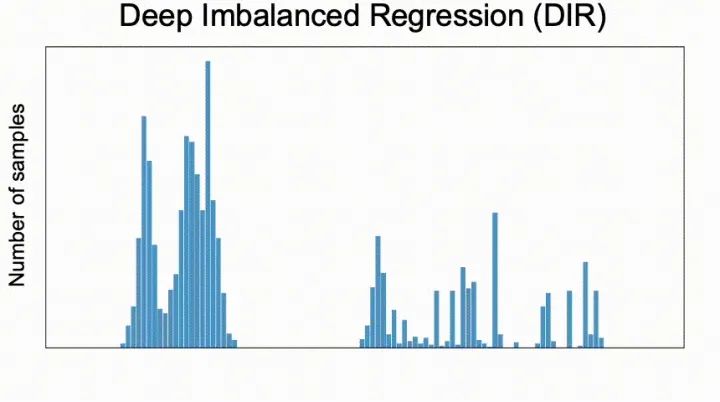
我們提出了一個新的任務,稱為深度不平衡回歸(Deep Imbalanced Regression,簡寫為DIR)。DIR任務定義為從具有連續(xù)目標的不平衡數(shù)據中學習,并能泛化到整個目標范圍; 我們同時提出了針對不平衡回歸的新的方法,標簽分布平滑(label distribution smoothing, LDS)和特征分布平滑(feature distribution smoothing, FDS),以解決具有連續(xù)目標的不平衡數(shù)據的學習問題; 最后我們建立了五個新的DIR數(shù)據集,涵蓋了computer vision,NLP,和healthcare上的不平衡回歸任務,來方便未來在不平衡數(shù)據上的研究。
1. 研究背景與動機
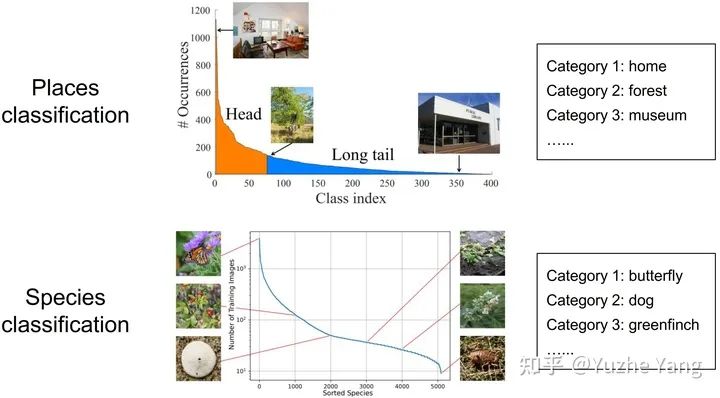

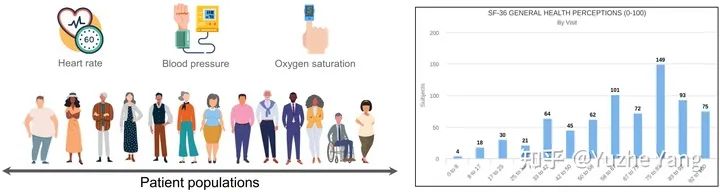
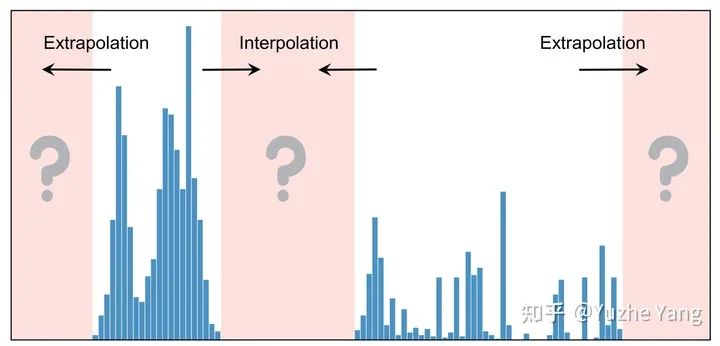
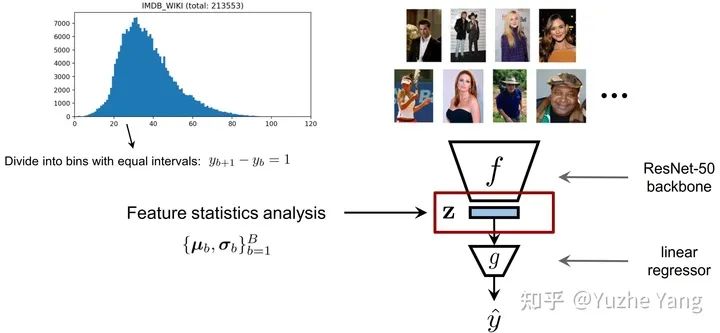
2. 不平衡回歸的難點與挑戰(zhàn)
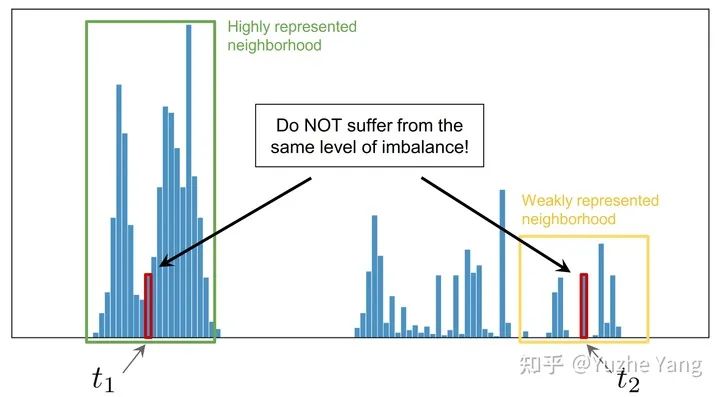
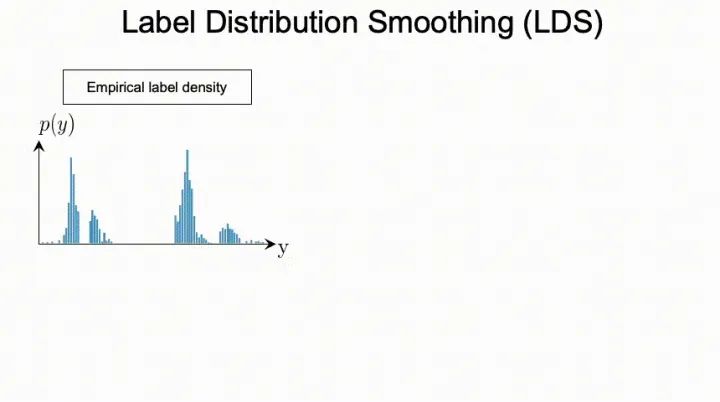
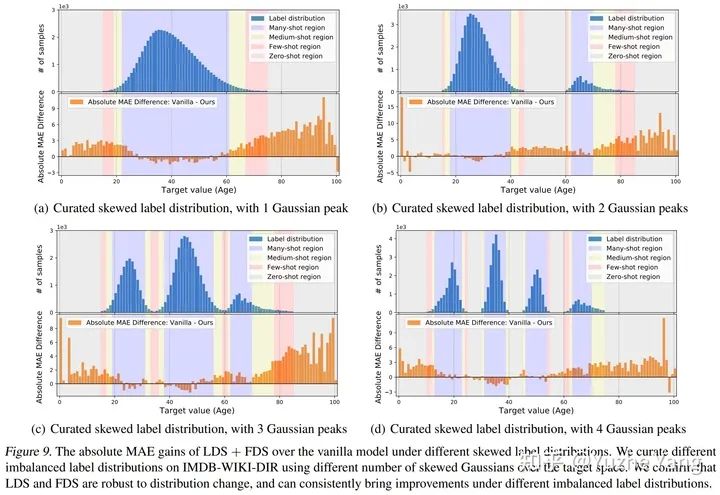
3. 標簽分布平滑(LDS)
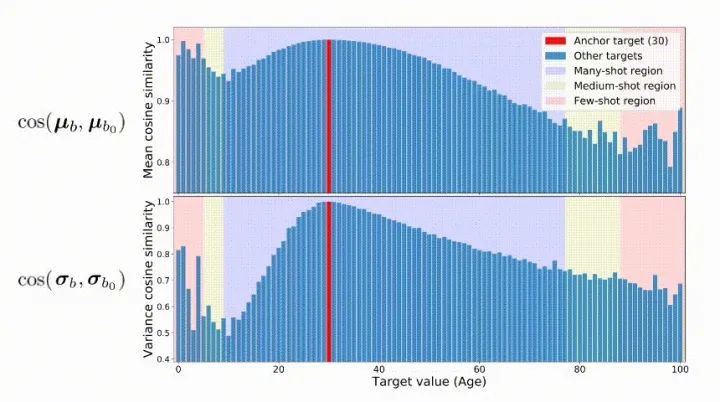
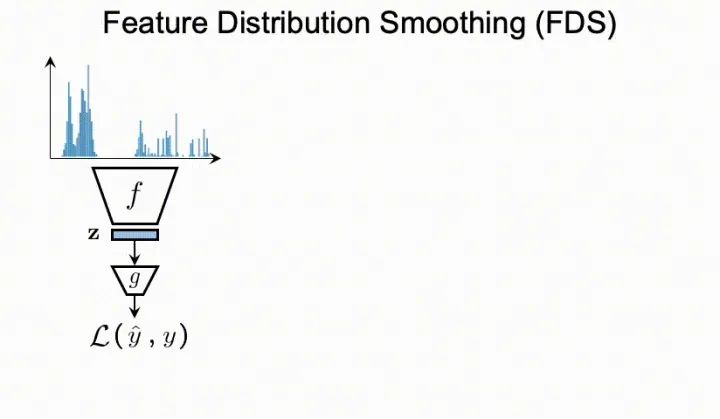
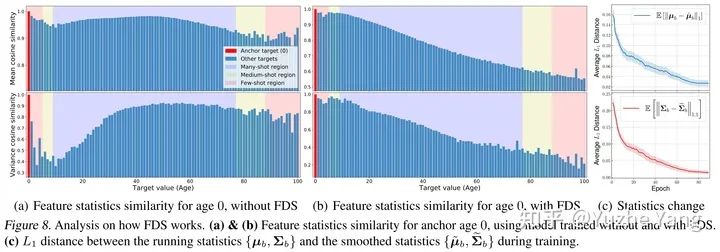
4. 特征分布平滑(FDS)
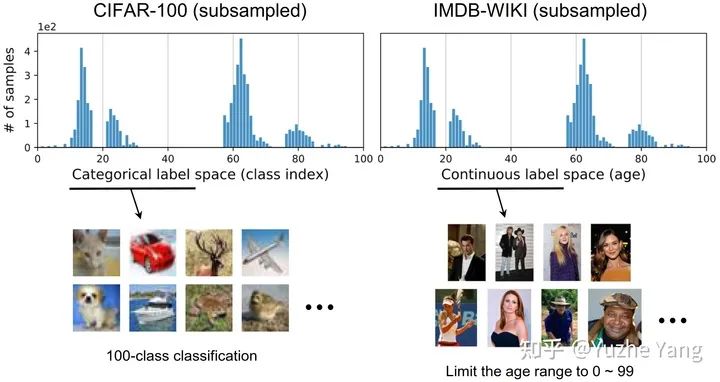
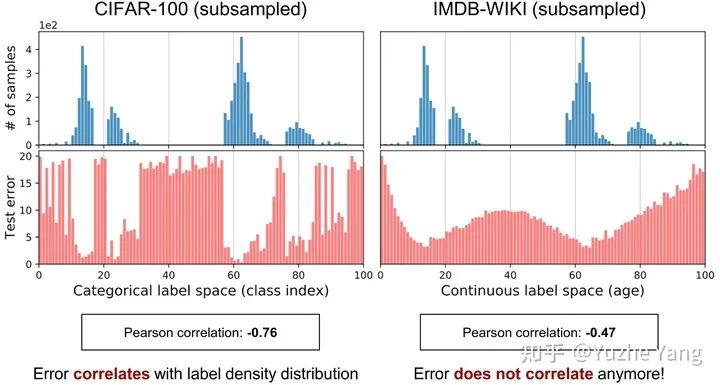
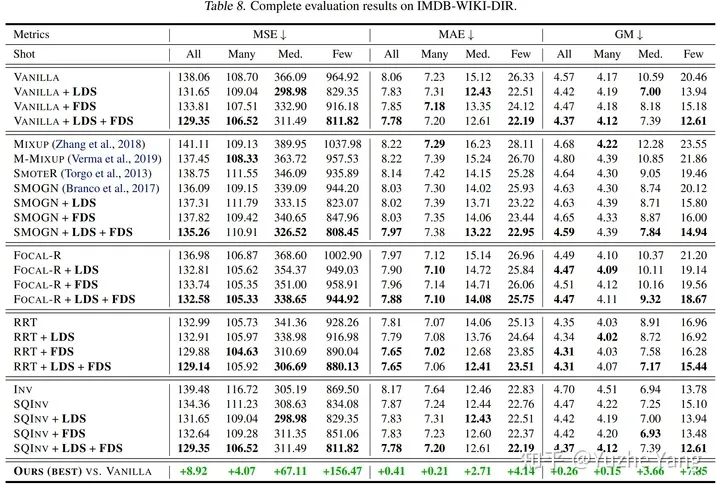
5. 基準DIR數(shù)據集及實驗分析
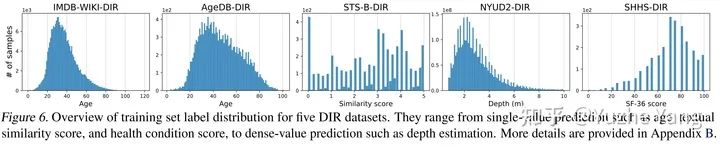
IMDB-WIKI-DIR(vision, age): 從包含人面部的圖像來推斷估計相應的年齡。基于IMDB-WIKI[9]數(shù)據集,我們手動構建了驗證集和測試集,使其保持了分布的平衡。 AgeDB-DIR(vision, age): 同樣是根據單個輸入圖像進行年齡估算,基于AgeDB[11]數(shù)據集。注意到與IMDB-WIKI-DIR相比,即使兩個數(shù)據集是完全相同的task,他們的標簽分布的不平衡也不相同。 NYUD2-DIR(vision, depth): 除了single value的prediction, 我們還基于NYU2數(shù)據集[12]構建了進行depth estimation的DIR任務,是一個dense value prediction的任務。我們構建了NYUD2-DIR數(shù)據集來進行不平衡回歸的評估。 STS-B-DIR(NLP, text similarity score): 我們還在NLP領域中構建了一個叫STS-B-DIR的DIR benchmark,基于STS-B數(shù)據集[13]。他的任務是推斷兩個輸入句子之間的語義文本的相似度得分。這個相似度分數(shù)是連續(xù)的,范圍是0到5,并且分布不平衡。 SHHS-DIR(Healthcare, health condition score): 最后,我們在healthcare領域也構建了一個DIR的benchmark,叫做 SHHS-DIR,基于SHHS數(shù)據集[14]。這項任務是推斷一個人的總體健康評分,該評分在0到100之間連續(xù)分布,評分越高則健康狀況越好。網絡的輸入是每個患者在一整晚睡眠過程中的高維PSG信號,包括ECG心電信號,EEG腦電信號,以及他的呼吸信號。很明顯可以看到,總體健康分數(shù)的分布也是極度不平衡的,并存在一定的target value是沒有數(shù)據的。
6. 結語
參考
本文亮點總結
推薦閱讀
國產小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網站和786名女主播起訴了
關于程序員大白
程序員大白是一群哈工大,東北大學,西湖大學和上海交通大學的碩士博士運營維護的號,大家樂于分享高質量文章,喜歡總結知識,歡迎關注[程序員大白],大家一起學習進步!
評論
圖片
表情