
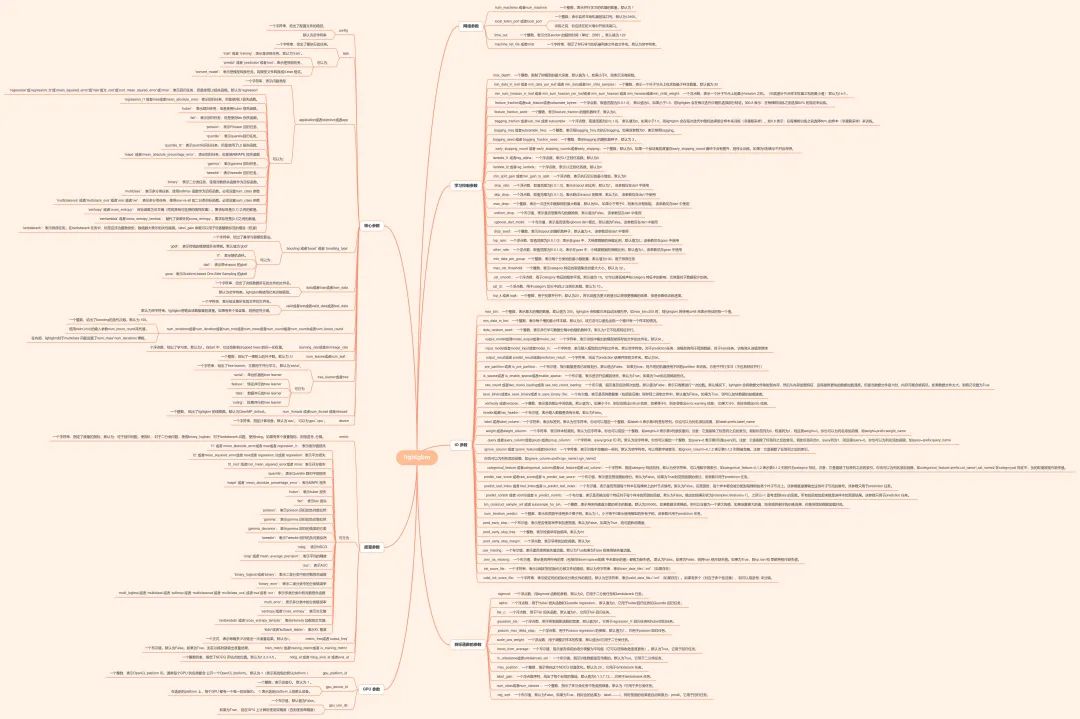
?100天搞定機器學(xué)習(xí)|Day63 徹底掌握 LightGBM
↓↓↓點擊關(guān)注,回復(fù)資料,10個G的驚喜
100天搞定機器學(xué)習(xí)|Day60 遇事不決,XGBoost
100天搞定機器學(xué)習(xí)|Day61 手算+可視化,終于徹底理解了 XGBoost
LightGBM
LightGBM 全稱為輕量的梯度提升機(Light Gradient Boosting Machine),由微軟于2017年開源出來的一款SOTA Boosting算法框架。
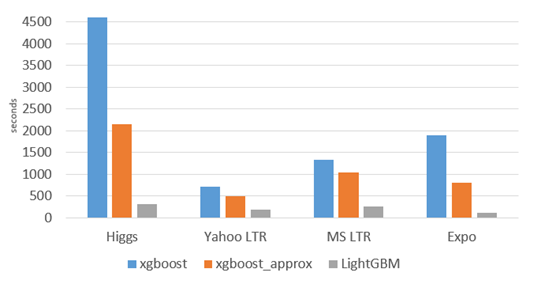
LightGBM 跟XGBoost一樣,也是 GBDT 算法框架的一種工程實現(xiàn),不過更加快速和高效:
更快的訓(xùn)練效率 低內(nèi)存使用 更高的準(zhǔn)確率 支持并行化學(xué)習(xí) 可處理大規(guī)模數(shù)據(jù) 支持直接使用category特征
LightGBM 模型原理
回顧一下XGBoost 構(gòu)建決策樹的算法基本思想:
首先,對所有特征都按照特征的數(shù)值進行預(yù)排序。
其次,在遍歷分割點的時候用O(#data)的代價找到一個特征上的最好分割點。
最后,找到一個特征的分割點后,將數(shù)據(jù)分裂成左右子節(jié)點。
這樣的預(yù)排序算法的優(yōu)點是:能精確地找到分割點。
缺點也很明顯:計算量巨大、內(nèi)存占用巨大、易產(chǎn)生過擬合
LightGBM 在 XGBoost 上主要有3方面的優(yōu)化:
1,Histogram算法:直方圖算法。
2,GOSS算法:基于梯度的單邊采樣算法。
3,EFB算法:互斥特征捆綁算法。
為方面理解,我們可以認為
LightGBM = XGBoost + Histogram + GOSS + EFB
Hitogram算法的作用是減少候選分裂點數(shù)量 GOSS算法的作用是減少樣本的數(shù)量 EFB算法的作用是減少特征的數(shù)量
訓(xùn)練復(fù)雜度 = 樹的棵數(shù)??每棵樹上葉子的數(shù)量??生成每片葉子的復(fù)雜度
生成一片葉子的復(fù)雜度 = 特征數(shù)量??候選分裂點數(shù)量??樣本的數(shù)量
通過這3個算法的引入,LightGBM生成一片葉子需要的復(fù)雜度大大降低了,從而極大節(jié)約了計算時間。
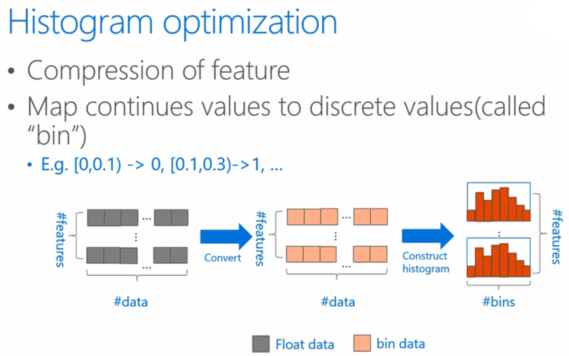
直方圖
直方圖算法是把連續(xù)特征離散化為 k 個整數(shù),也是采用了分箱的思想,不同的是直方圖算法根據(jù)特征所在的 bin 對其進行梯度累加和個數(shù)統(tǒng)計。
在遍歷數(shù)據(jù)的時候,根據(jù)離散化后的值作為索引在直方圖中累積統(tǒng)計量,當(dāng)遍歷一次數(shù)據(jù)后,直方圖累積了需要的統(tǒng)計量,然后根據(jù)直方圖的離散值,遍歷尋找最優(yōu)的分裂點。
下例對比 xgboost 的預(yù)排序,可以更形象地理解直方圖算法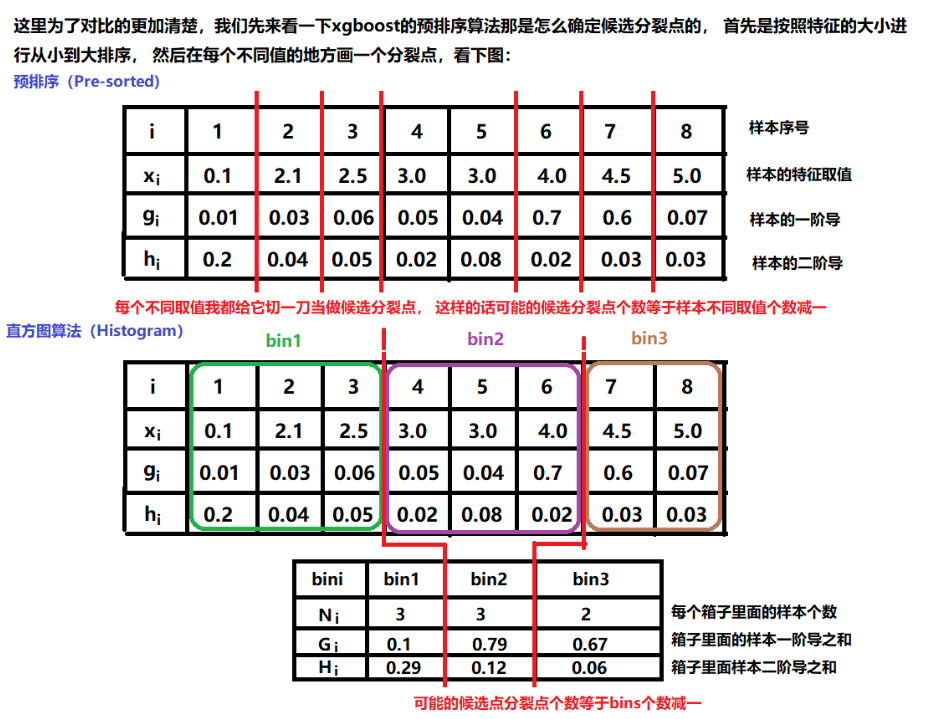
直方圖做差
LightGBM 另一個優(yōu)化是直方圖做差加速,一個葉子的直方圖可以由它的父親節(jié)點的直方圖與它兄弟的直方圖做差得到。
利用這個方法,LightGBM可以在構(gòu)造一個葉子的直方圖后,僅需遍歷直方圖的k個桶,無需遍歷該葉子上的所有數(shù)據(jù),在速度上可以提升一倍。

Histogram算法并不完美,由于特征被離散化,找到的并不是精確的分割點,所以會對結(jié)果產(chǎn)生影響。但在不同的數(shù)據(jù)集上的結(jié)果表明,離散化的分割點對最終的精度影響并不是很大,甚至有時候會更好一點。原因是決策樹本來就是弱模型,分割點是不是精確并不是太重要;較粗的分割點也有正則化的效果,可以有效地防止過擬合;即使單棵樹的訓(xùn)練誤差比精確分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下沒有太大的影響。
GOSS算法
GOSS是一種在減少數(shù)據(jù)量和保證精度上平衡的算法。
GOSS是通過區(qū)分不同梯度的實例,保留較大梯度實例同時對較小梯度隨機采樣的方式減少計算量,從而達到提升效率的目的。
為了抵消對數(shù)據(jù)分布的影響,計算信息增益的時候,GOSS對小梯度的數(shù)據(jù)引入常量乘數(shù)。GOSS首先根據(jù)數(shù)據(jù)的梯度絕對值排序,選取top a個實例。然后在剩余的數(shù)據(jù)中隨機采樣b個實例。接著計算信息增益時為采樣出的小梯度數(shù)據(jù)乘以(1-a)/b,這樣算法就會更關(guān)注訓(xùn)練不足的實例,而不會過多改變原數(shù)據(jù)集的分布。
 GOSS的算法步驟如下:
GOSS的算法步驟如下:
1、根據(jù)數(shù)據(jù)的梯度絕對值將訓(xùn)練降序排序。
2、保留top a個數(shù)據(jù)實例,作為樣本A。
3、對于剩下的(1-a)%數(shù)據(jù),隨機抽取b*100%的數(shù)據(jù)作為樣本B。
4、計算信息增益的時候,放大樣本B中的梯度(1-a)/b倍
EFB算法
EFB是通過特征捆綁的方式減少特征維度(其實是降維技術(shù))的方式,來提升計算效率。
通常被捆綁的特征都是互斥的(一個特征值為零,一個特征值不為零),這樣兩個特征捆綁起來才不會丟失信息。
如果兩個特征并不是完全互斥(部分情況下兩個特征都是非零值),可以用一個指標(biāo)對特征不互斥程度進行衡量,稱之為沖突比率,當(dāng)這個值較小時,我們可以選擇把不完全互斥的兩個特征捆綁,而不影響最后的精度。
EFB算法的關(guān)鍵點有兩個:
1、如何判定哪些特征可以進行捆綁?
2、特征如何捆綁?捆綁之后的特征值如何計算?
如何判定哪些特征可以捆綁?
EFB 算法利用特征和特征間的關(guān)系構(gòu)造一個加權(quán)無向圖,并將其轉(zhuǎn)換為圖著色算法。圖著色是個 NP-Hard 問題,故采用貪婪算法得到近似解,具體步驟如下:
構(gòu)造一個加權(quán)無向圖,頂點是特征,邊的權(quán)重是兩個特征的總沖突值,即兩個特征上同時不為0的樣本個數(shù)
根據(jù)節(jié)點的度進行降序排序,度越大,表示與其他特征的沖突越大
對于每一個特征,通過遍歷已有的特征簇(沒有則新建一個),如果該特征加入到特征簇中的沖突值不超過某個閾值,則將該特征加入到該簇中。如果該特征不能加入任何一個已有的特征簇,則新建一個簇,并加入該特征。
EFB 算法允許特征并不完全互斥來增加特征捆綁的數(shù)量,在具體計算的時候需要設(shè)置一個最大互斥率指標(biāo)γ,一般情況下這個指標(biāo)設(shè)置會相對較小,此時算法的精度和效率之間會有一個最優(yōu)值。
Greedy bundle 算法的偽代碼如下:

上面的過程存在一個缺點:在特征數(shù)量特征多的時候,第一步建立加權(quán)無向圖會影響效率,此時可以直接統(tǒng)計特征之間非零樣本的個數(shù),因為非零值越多,互斥的概率會越大。
特征如何捆綁?
Merge Exclusive Features 算法將 bundle 中的特征合并為新的特征,合并的關(guān)鍵是原有的不同特征值在構(gòu)建后的 bundle 中仍能夠識別。
由于基于直方圖的方法存儲的是離散的 bin 而不是連續(xù)的數(shù)值,因此可以通過添加偏移的方法將不同的 bin 值設(shè)定為不同的區(qū)間。
舉個例子:特征 A 和特征 B 可以實現(xiàn)特征捆綁,A 特征的原始取值區(qū)間是 [0,10) ,B 特征的原始取值是[0,20)。如果直接進行特征值的相加,那么 5 這個值我們不能分清它是出自特征 A 還是特征 B。此時可以給特征 B 加一個偏移量 10 將取值區(qū)間轉(zhuǎn)換成 [10,30),這時進行特征捆綁就可以分清來源。
MEF 特征合并算法的偽代碼如下:

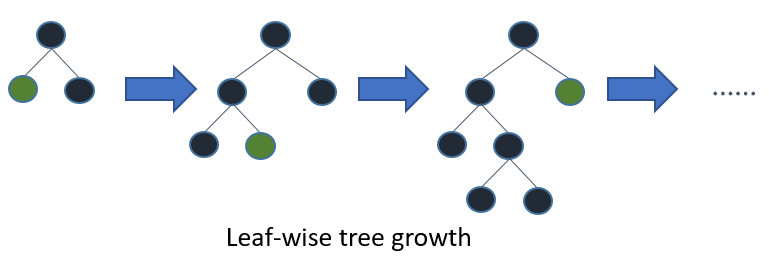
leaf-wise
在Histogram算法之上,LightGBM進行進一步的優(yōu)化。首先它拋棄了大多數(shù)GBDT工具使用的按層生長 (level-wise)的決策樹生長策略,而使用了帶有深度限制的按葉子生長 (leaf-wise)算法。
leaft-wise 的做法是在當(dāng)前所有葉子節(jié)點中選擇分裂收益最大的節(jié)點進行分裂,如此遞歸進行,很明顯 leaf-wise 這種做法容易過擬合,因為容易陷入比較高的深度中,因此需要對最大深度做限制,從而避免過擬合。

LightGBM 極簡實例
LightGBM兩種使用方式,區(qū)別不大
1、原生形式使用LightGBM
import?LightGBM?as?lgb
2、Sklearn接口形式使用LightGBM
from?LightGBM?import?LGBMRegressor
下面代碼為 Sklearn 接口形式 LightGBM 具體用法,雖說是極簡,但完全涵蓋模型應(yīng)用的全部過程。
from?LightGBM?import?LGBMRegressor
from?sklearn.metrics?import?mean_squared_error
from?sklearn.model_selection?import?GridSearchCV
from?sklearn.datasets?import?load_iris
from?sklearn.model_selection?import?train_test_split
from?sklearn.externals?import?joblib
#?加載數(shù)據(jù)
iris?=?load_iris()
data?=?iris.data
target?=?iris.target
#?劃分訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)
X_train,?X_test,?y_train,?y_test?=?train_test_split(data,?target,?test_size=0.2)
#?模型訓(xùn)練
gbm?=?LGBMRegressor(objective='regression',?num_leaves=31,?learning_rate=0.05,?n_estimators=20)
gbm.fit(X_train,?y_train,?eval_set=[(X_test,?y_test)],?eval_metric='l1',?early_stopping_rounds=5)
#?模型存儲
joblib.dump(gbm,?'loan_model.pkl')
#?模型加載
gbm?=?joblib.load('loan_model.pkl')
#?模型預(yù)測
y_pred?=?gbm.predict(X_test,?num_iteration=gbm.best_iteration_)
#?模型評估
print('The?rmse?of?prediction?is:',?mean_squared_error(y_test,?y_pred)?**?0.5)
#?特征重要度
print('Feature?importances:',?list(gbm.feature_importances_))
#?網(wǎng)格搜索,參數(shù)優(yōu)化
estimator?=?LGBMRegressor(num_leaves=31)
param_grid?=?{
????'learning_rate':?[0.01,?0.1,?1],
????'n_estimators':?[20,?40]
}
gbm?=?GridSearchCV(estimator,?param_grid)
gbm.fit(X_train,?y_train)
print('Best?parameters?found?by?grid?search?are:',?gbm.best_params_)
LightGBM調(diào)參小技巧
LightGBM 參數(shù)很多,但是最常用的不多:
num_leaves:控制了葉節(jié)點的數(shù)目,控制樹模型復(fù)雜度的主要參數(shù)。 max_depth, default=-1, type=int,樹的最大深度限制,防止過擬合 min_data_in_leaf, default=20, type=int, 葉子節(jié)點最小樣本數(shù),防止過擬合 feature_fraction, default=1.0, type=double, 0.0 < feature_fraction < 1.0,隨機選擇特征比例,加速訓(xùn)練及防止過擬合 feature_fraction_seed, default=2, type=int,隨機種子數(shù),保證每次能夠隨機選擇樣本的一致性 bagging_fraction, default=1.0, type=double, 類似隨機森林,每次不重采樣選取數(shù)據(jù) lambda_l1, default=0, type=double, L1正則 lambda_l2, default=0, type=double, L2正則 min_split_gain, default=0, type=double, 最小切分的信息增益值 top_rate, default=0.2, type=double,大梯度樹的保留比例 other_rate, default=0.1, type=int,小梯度樹的保留比例 min_data_per_group, default=100, type=int,每個分類組的最小數(shù)據(jù)量 max_cat_threshold, default=32, type=int,分類特征的最大閾值
針對更快的訓(xùn)練速度:
通過設(shè)置 bagging_fraction 和 bagging_freq 參數(shù)來使用 bagging 方法 通過設(shè)置 feature_fraction 參數(shù)來使用特征的子抽樣 使用較小的 max_bin 使用 save_binary 在未來的學(xué)習(xí)過程對數(shù)據(jù)加載進行加速
獲取更好的準(zhǔn)確率:
使用較大的 max_bin (學(xué)習(xí)速度可能變慢) 使用較小的 learning_rate 和較大的 num_iterations 使用較大的 num_leaves (可能導(dǎo)致過擬合) 使用更大的訓(xùn)練數(shù)據(jù) 嘗試 dart
緩解過擬合:
使用較小的 max_bin 使用較小的 num_leaves 使用 min_data_in_leaf 和 min_sum_hessian_in_leaf 通過設(shè)置 bagging_fraction 和 bagging_freq 來使用 bagging 通過設(shè)置 feature_fraction 來使用特征子抽樣 使用更大的訓(xùn)練數(shù)據(jù) 使用 lambda_l1, lambda_l2 和 min_gain_to_split 來使用正則 嘗試 max_depth 來避免生成過深的樹
總結(jié)
最后做個總結(jié),也是面試中最常被問到的:
xgboost和LightGBM的區(qū)別和適用場景?
(1)xgboost采用的是level-wise的分裂策略,而lightGBM采用了leaf-wise的策略,區(qū)別是xgboost對每一層所有節(jié)點做無差別分裂,可能有些節(jié)點的增益非常小,對結(jié)果影響不大,但是xgboost也進行了分裂,帶來了務(wù)必要的開銷。leaft-wise的做法是在當(dāng)前所有葉子節(jié)點中選擇分裂收益最大的節(jié)點進行分裂,如此遞歸進行,很明顯leaf-wise這種做法容易過擬合,因為容易陷入比較高的深度中,因此需要對最大深度做限制,從而避免過擬合。
(2)LightGBM使用了基于histogram的決策樹算法,這一點不同與xgboost中的 exact 算法,histogram算法在內(nèi)存和計算代價上都有不小優(yōu)勢。
1)內(nèi)存上優(yōu)勢:很明顯,直方圖算法的內(nèi)存消耗為(#data* #features * 1Bytes)(因為對特征分桶后只需保存特征離散化之后的值),而xgboost的exact算法內(nèi)存消耗為:(2 * #data * #features* 4Bytes),因為xgboost既要保存原始feature的值,也要保存這個值的順序索引,這些值需要32位的浮點數(shù)來保存。
2)計算上的優(yōu)勢,預(yù)排序算法在選擇好分裂特征計算分裂收益時需要遍歷所有樣本的特征值,時間為(#data),而直方圖算法只需要遍歷桶就行了,時間為(#bin)
(3)直方圖做差加速,一個子節(jié)點的直方圖可以通過父節(jié)點的直方圖減去兄弟節(jié)點的直方圖得到,從而加速計算。
(4)LightGBM支持直接輸入categorical 的feature,在對離散特征分裂時,每個取值都當(dāng)作一個桶,分裂時的增益算的是”是否屬于某個category“的gain。類似于one-hot編碼。
(5)xgboost在每一層都動態(tài)構(gòu)建直方圖,因為xgboost的直方圖算法不是針對某個特定的feature,而是所有feature共享一個直方圖(每個樣本的權(quán)重是二階導(dǎo)),所以每一層都要重新構(gòu)建直方圖,而LightGBM中對每個特征都有一個直方圖,所以構(gòu)建一次直方圖就夠了。
其適用場景根據(jù)實際項目和兩種算法的優(yōu)點進行選擇。
reference
https://mp.weixin.qq.com/s/i_pHsnwK738d9TTfXOkK8A
https://LightGBM.apachecn.org/#/docs/6
https://mp.weixin.qq.com/s/iPX0PwRnNMmouNfc6OA7SA
https://www.biaodianfu.com/LightGBM.html
http://www.mianshigee.com/question/12398exk/
https://www.cnblogs.com/chenxiangzhen/p/10894306.html
https://www.kaggle.com/prashant111/LightGBM-classifier-in-python
推薦閱讀
用Python學(xué)線性代數(shù):自動擬合數(shù)據(jù)分布 Python 用一行代碼搞事情,機器學(xué)習(xí)通吃 Github 上最大的開源算法庫,還能學(xué)機器學(xué)習(xí)! JupyterLab 這插件太強了,Excel靈魂附體 終于把 jupyter notebook 玩明白了 一個超好用的 Python 標(biāo)準(zhǔn)庫,666? 幾百本編程中文書籍(含Python)持續(xù)更新