
CNN入門,用MNIST訓(xùn)練模型,并識別自己手寫數(shù)字

大家一般入門的時候,都會跑這個代碼,但是很少有人拿來識別自己的手寫體,今天我試了下,效果還挺好的。
原理不懂的,可以看看這個3D的可視化視頻。
一、構(gòu)建CNN模型
from keras import layersfrom keras import modelsmodel = models.Sequential()model.add(layers.Conv2D(32, (3, 3),activation='relu',input_shape=(28, 28, 1)))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.Flatten())model.add(layers.Dropout(0.25))model.add(layers.Dense(64, activation='relu'))model.add(layers.Dense(10,?activation='softmax'))
卷積神經(jīng)網(wǎng)絡(luò)接收形狀為(image_height, image_width, image_channels)的輸入張量(不包括批量維度)。本例中設(shè)置卷積神經(jīng)網(wǎng)絡(luò)處理大小為(28, 28, 1) 的輸入張量,這正是MNIST 圖像的格式。我們向第一層傳入?yún)?shù)input_shape=(28, 28, 1) 來完成此設(shè)置。我們來看一下目前卷積神經(jīng)網(wǎng)絡(luò)的架構(gòu)。
model.summary()Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param #=================================================================conv2d (Conv2D) (None, 26, 26, 32) 320_________________________________________________________________max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0_________________________________________________________________conv2d_1 (Conv2D) (None, 11, 11, 64) 18496_________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0_________________________________________________________________conv2d_2 (Conv2D) (None, 3, 3, 64) 36928_________________________________________________________________flatten (Flatten) (None, 576) 0_________________________________________________________________dropout (Dropout) (None, 576) 0_________________________________________________________________dense (Dense) (None, 64) 36928_________________________________________________________________dense_1 (Dense) (None, 10) 650=================================================================Total params: 93,322Trainable params: 93,322Non-trainable params: 0_________________________________________________________________
二、圖片下載與查看
from keras.datasets import mnistfrom keras.utils import to_categoricalfrom keras import datasets(train_images,train_labels), (test_images,test_labels) = mnist.load_data()dir(datasets)#可以看看內(nèi)置的所有數(shù)據(jù)集
查看圖片
import matplotlib.pyplot as pltplt.imshow(train_images[200] , cmap=plt.cm.binary)plt.show()
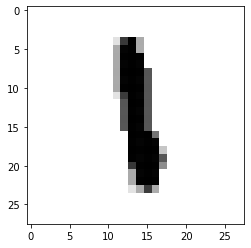
?
三、模型訓(xùn)練&準(zhǔn)確率評估
train_images = train_images.reshape((60000, 28, 28, 1))train_images = train_images.astype('float32') / 255train_labels = to_categorical(train_labels)test_images = test_images.reshape((10000, 28, 28, 1))test_images = test_images.astype('float32') / 255test_labels = to_categorical(test_labels)model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])model.fit(train_images, train_labels, epochs=5, batch_size=64)test_loss, test_acc = model.evaluate(test_images, test_labels)test_acc0.9914000034332275
#看看預(yù)測的到底準(zhǔn)不準(zhǔn)呢
y_pred = model.predict(test_images)import numpy as nppred = np.argmax(y_pred, axis=1)import matplotlib.pyplot as plt#看看第2990個數(shù)字是啥,我們預(yù)測的是8,看看圖片也是8,挺準(zhǔn)的steps = 2990print('pred: ',pred[steps])pred: 8plt.imshow(test_images[steps] , cmap=plt.cm.binary)plt.show()
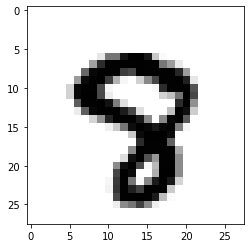
?
四、預(yù)測自己的手寫數(shù)字
模型訓(xùn)練好了,準(zhǔn)確率挺高,但是實際有沒有用,還需要用自己的數(shù)據(jù)進(jìn)行測試,打開自己在畫圖板里面隨便寫幾個數(shù)字,然后單個截圖保存后進(jìn)行預(yù)測。
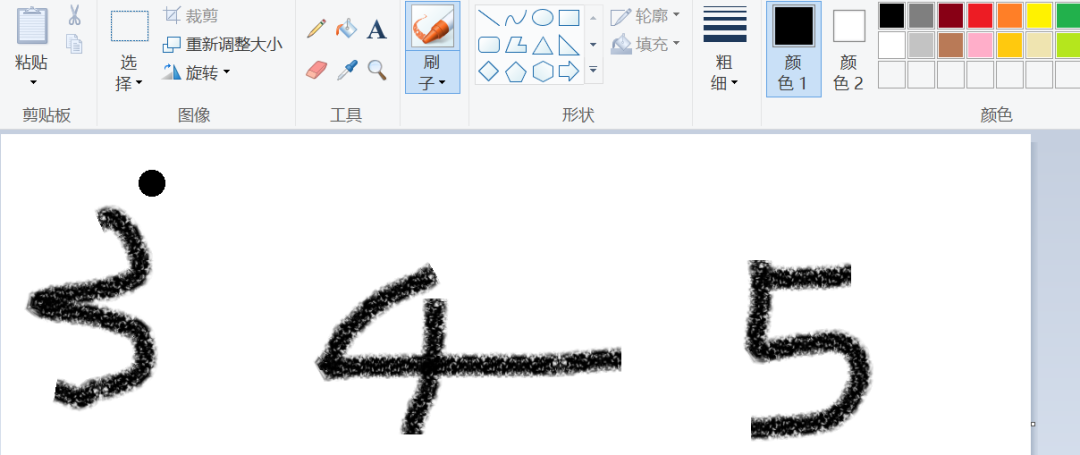
?
分別截圖后保存成img3、img4、img5......,下面進(jìn)行預(yù)處理,處理成和模型訓(xùn)練一樣的數(shù)據(jù)才能預(yù)測。
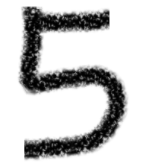
from keras.preprocessing.image import load_img,img_to_arrayimport matplotlib.pyplot as pltimport numpy as nppath = 'C:/Users/伍正祥/Desktop/img5.jpg'#讀取圖片、調(diào)整圖片大小,轉(zhuǎn)換成灰度 help(load_img)img = load_img(path, target_size=(28, 28),color_mode="grayscale")#255-為了調(diào)成白底,系統(tǒng)灰度轉(zhuǎn)換自動給處理成黑底了img = 255-img_to_array(img)#查看自己加載的圖片plt.imshow(img , cmap=plt.cm.binary)plt.show()#進(jìn)行數(shù)據(jù)預(yù)測img = img.astype('float32')/255img = img.reshape((1, 28, 28, 1))y_pred = model.predict(img)print('預(yù)測數(shù)字:',np.argmax(y_pred, axis=1)[0]
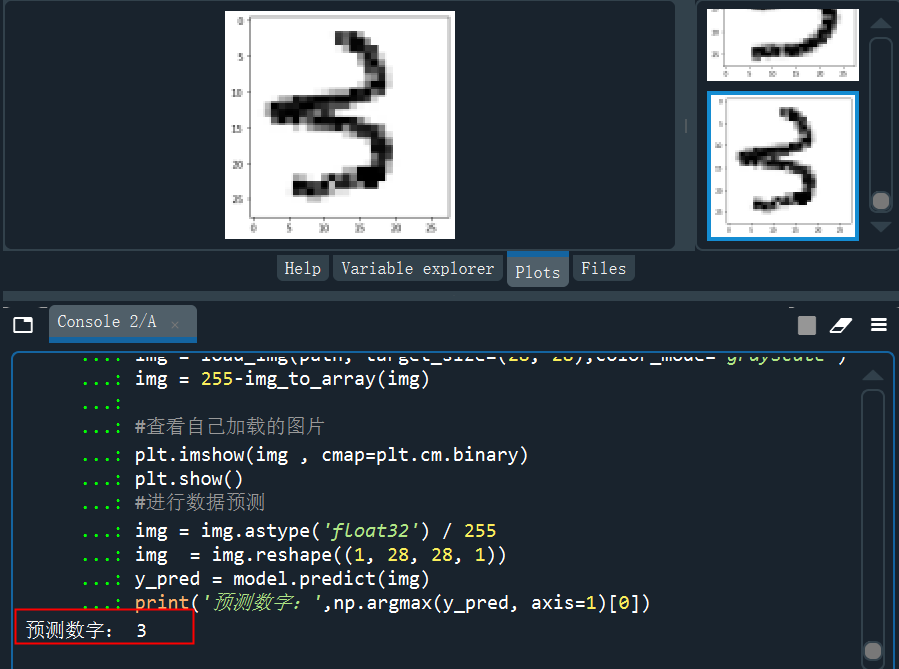
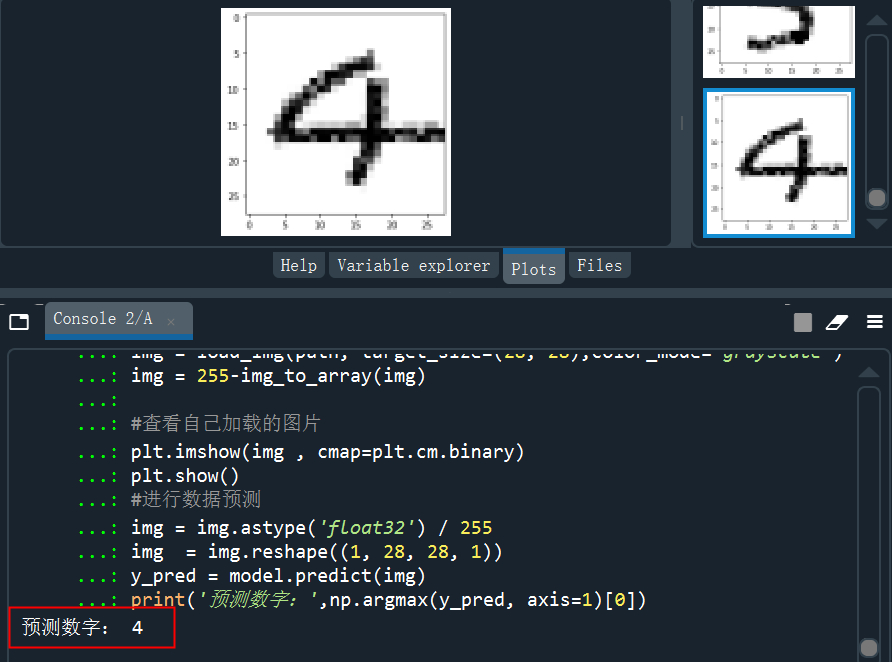
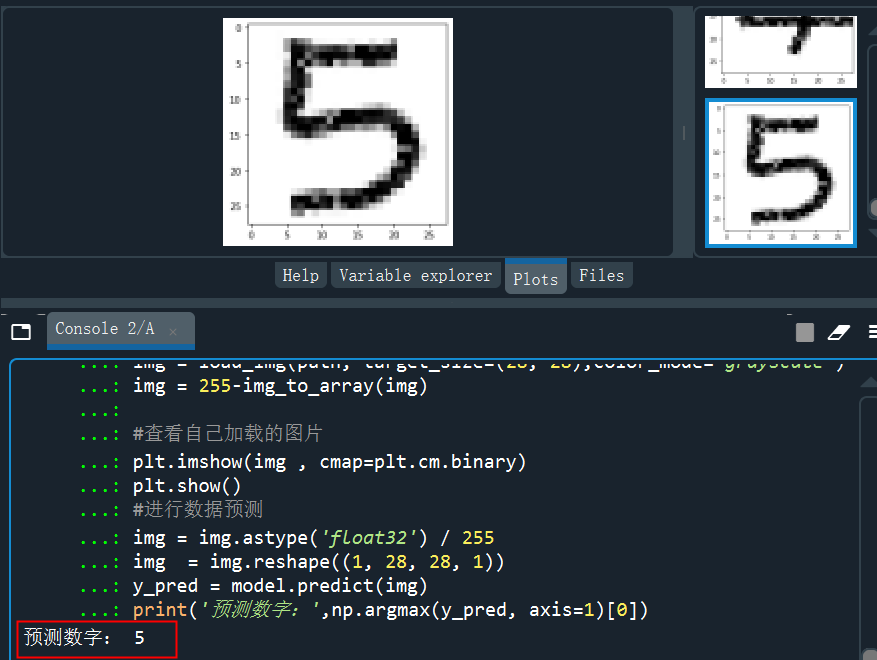
?
看看預(yù)測的概率分布,是5的概率幾乎接近于1
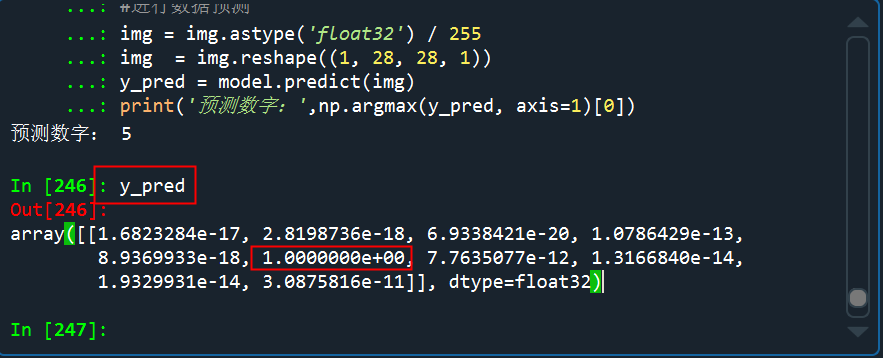
從測試的結(jié)果來看,預(yù)測效果還是非常不錯的,多試幾次,也有預(yù)測錯的,但是錯的概率比較小。
很多作業(yè)檢查的APP,其中也是用到了手寫體的識別,基本上原理估計也和這種差不多,只是對于作業(yè)的檢查,還需要進(jìn)行目標(biāo)檢測。
?
推薦閱讀:
刷爆網(wǎng)絡(luò)的動態(tài)條形圖,3行Python代碼就能搞定
Python初學(xué)者必須吃透這69個內(nèi)置函數(shù)!
長按加群,學(xué)習(xí)交流
↓掃描關(guān)注本號↓