
【機(jī)器學(xué)習(xí)】漫談特征縮放
作者: 時(shí)晴
說(shuō)起"煉丹"最耗時(shí)的幾件事,首先就能想到的就是數(shù)據(jù)清洗,特征工程,還有調(diào)參.特征工程真的是老生常談了,但是特征工程又是最重要的一環(huán),這一步做不好怎么調(diào)參也沒(méi)用.在特征工程中,做特征縮放是非常重要的,如下圖所示:
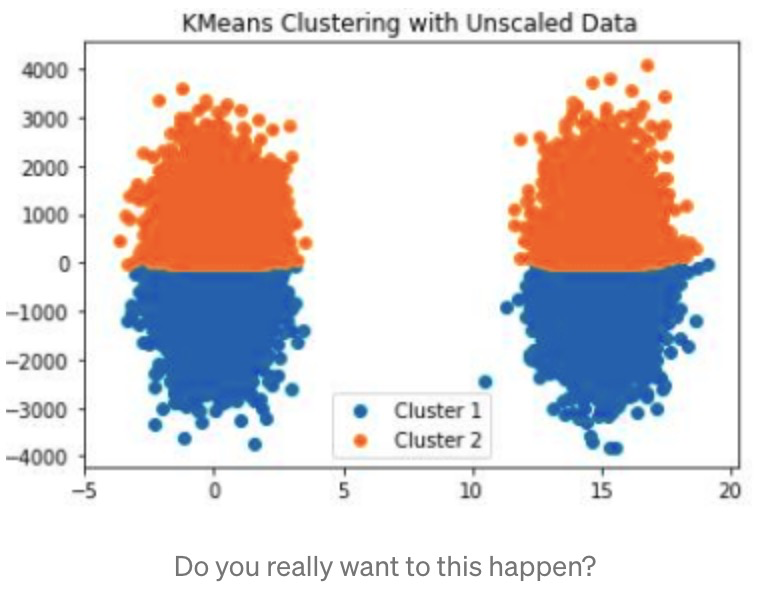
我們可以看到,在沒(méi)做特征縮放前,用kmeans跑出的聚類結(jié)果就如圖所示,以y=0為分界線,上面是一類,下面是一類,相當(dāng)?shù)碾x譜.主要原因就是y值的取值范圍很大,從-4000~4000,而x軸只有-5~20,熟悉kmeans算法都清楚該算法中距離度量用的是歐式距離,因此x軸的數(shù)值就變得無(wú)關(guān)緊要.所以數(shù)據(jù)預(yù)處理沒(méi)做好,很多模型都將不生效.值得注意的是,scaling在數(shù)據(jù)預(yù)處理中并不是強(qiáng)制的,習(xí)慣用樹(shù)模型的朋友們也很清楚對(duì)樹(shù)模型而言,scaling對(duì)效果毫無(wú)影響.但是對(duì)于一些對(duì)距離敏感的算法影響就比較大了,如KNN,SVM,PCA,NN等.
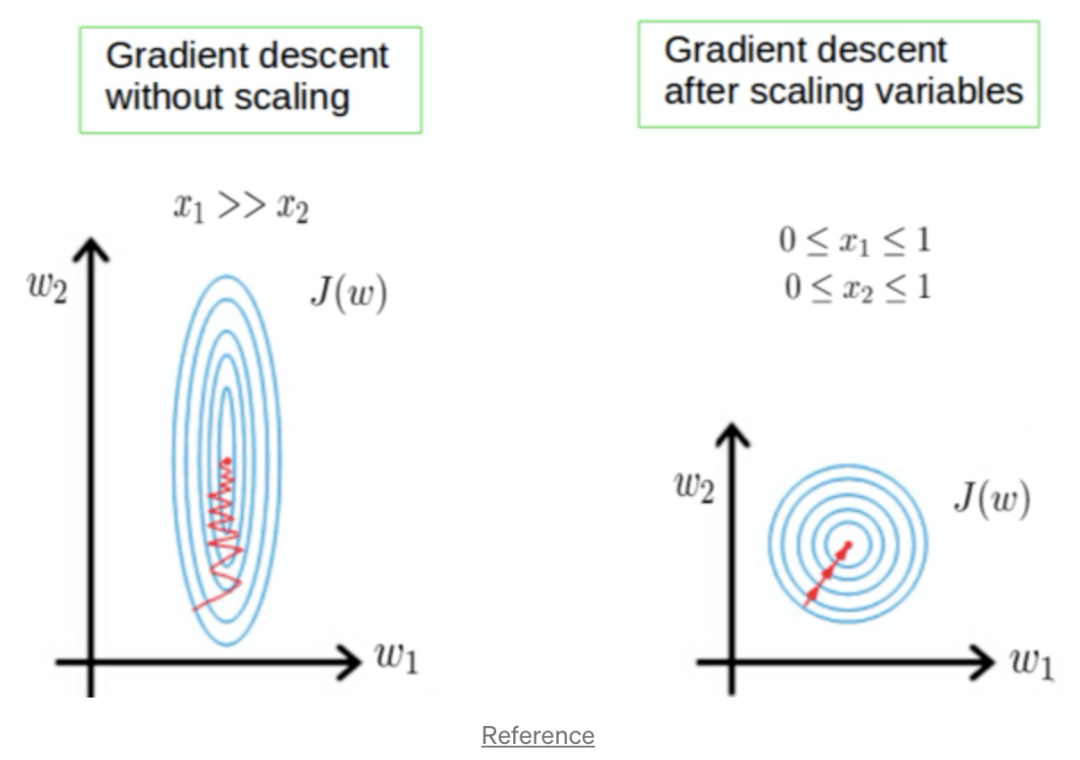
Scaling的目的很簡(jiǎn)單,一方面是使得每列特征“范圍”更接近,另一方面是讓計(jì)算變得更加簡(jiǎn)單,如梯度下降在特征縮放后,將縮放的更快,效果更好,所以對(duì)于線性回歸,邏輯回歸,NN都需要做特征縮放:
特征縮放有很多種,我們介紹最常見(jiàn)的4種:
StandardScaler
RobustScaler
MinMaxScaler
MaxAbsScaler
1、StandardScaler
這種scale方法大家最熟悉了,通過(guò)減去均值再除以方差進(jìn)行標(biāo)準(zhǔn)化.需要注意的是異常值對(duì)于這種scale方法的傷害是毀滅性的,因?yàn)楫惓V涤绊懢?如果你的數(shù)據(jù)是正太分布或接近正太分布,并且沒(méi)有特別異常的值,可以使用該方法進(jìn)行縮放.
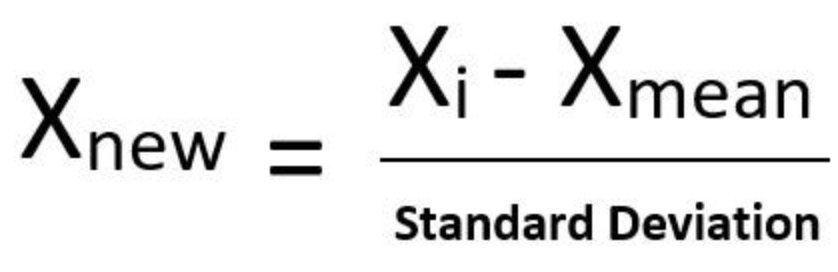
from sklearn.preprocessing import StandardScalerfrom sklearn.preprocessing import StandardScalerdf_scale = StandardScaler().fit_transform(df)
讓我們看下該縮放方法,對(duì)有偏態(tài)分布的數(shù)據(jù)會(huì)產(chǎn)生什么影響.
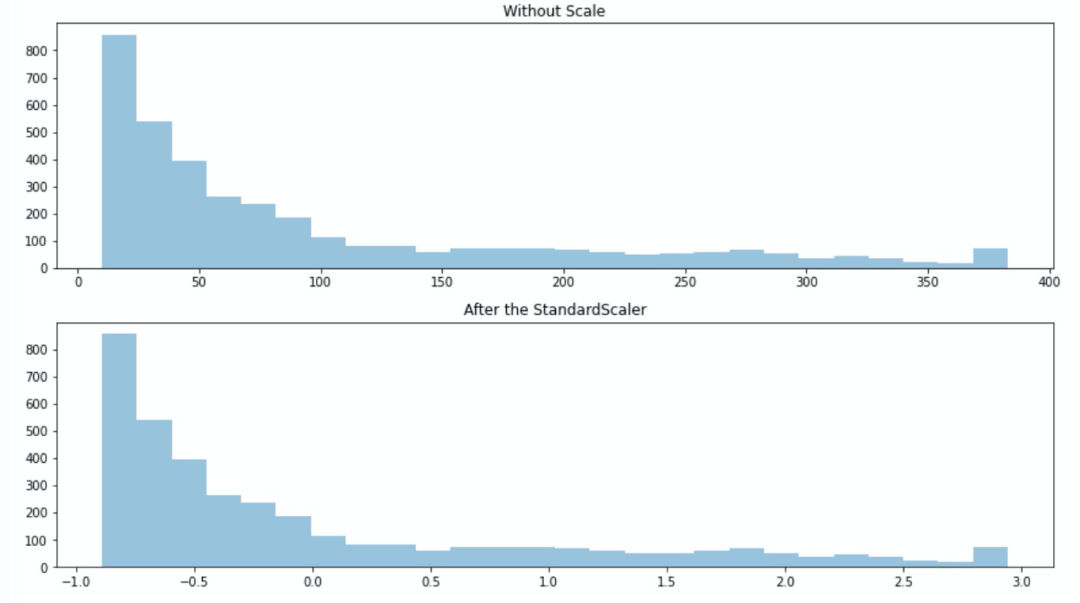
我們發(fā)現(xiàn),對(duì)偏態(tài)分布的數(shù)據(jù)縮放后并沒(méi)有改變其分布.我們對(duì)數(shù)據(jù)做次log再縮放呢?
from sklearn.preprocessing import StandardScalerimport numpy as npdf_log = np.log(df)df_scale = StandardScaler().fit_transform(df_log)
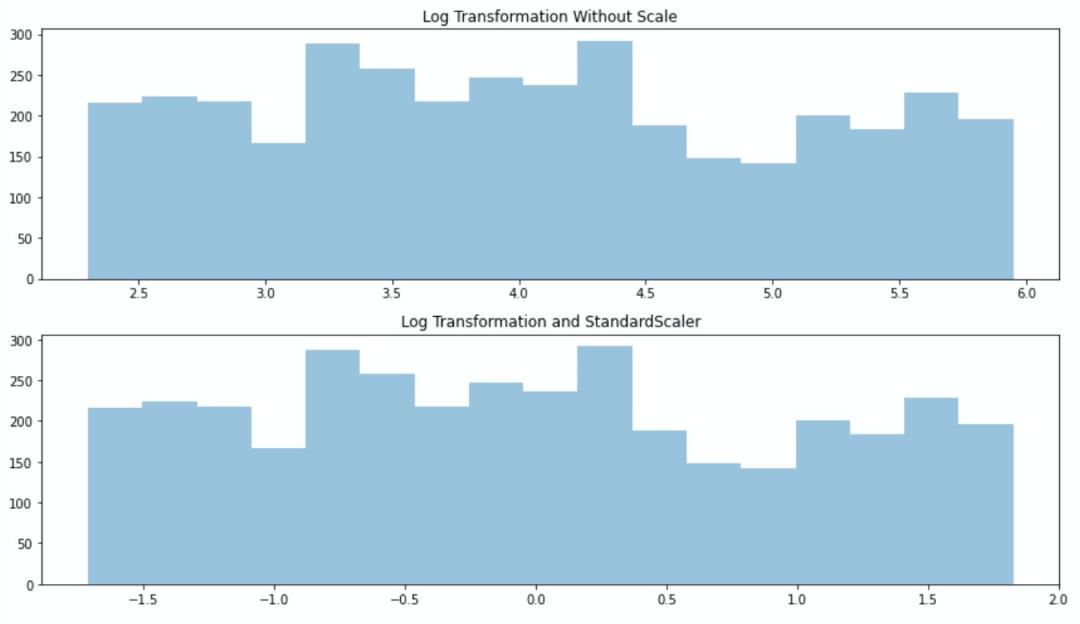
我們發(fā)現(xiàn)log使得數(shù)據(jù)接近正態(tài)分布,StandardScaler使得數(shù)據(jù)變成了標(biāo)準(zhǔn)正態(tài)分布,這種方法往往表現(xiàn)的更好并且降低了異常值的影響.
2、RobustScaler
from sklearn.preprocessing import RobustScalerRobustScaler是基于中位數(shù)的縮放方法,具體是減去中位數(shù)再除以第3分位數(shù)和第一分位數(shù)之間的差值.如下所示:
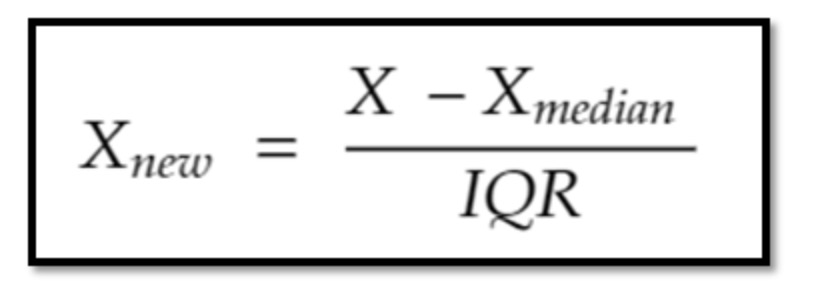
因?yàn)樵摽s放方法用了分位點(diǎn)的差值,所以它降低了異常值的影響,如果你發(fā)現(xiàn)數(shù)據(jù)有異常值,并且懶得去修正它們,就用這種縮放方法吧.我們對(duì)比下異常值對(duì)StandardScaler和RobustScaler的影響.
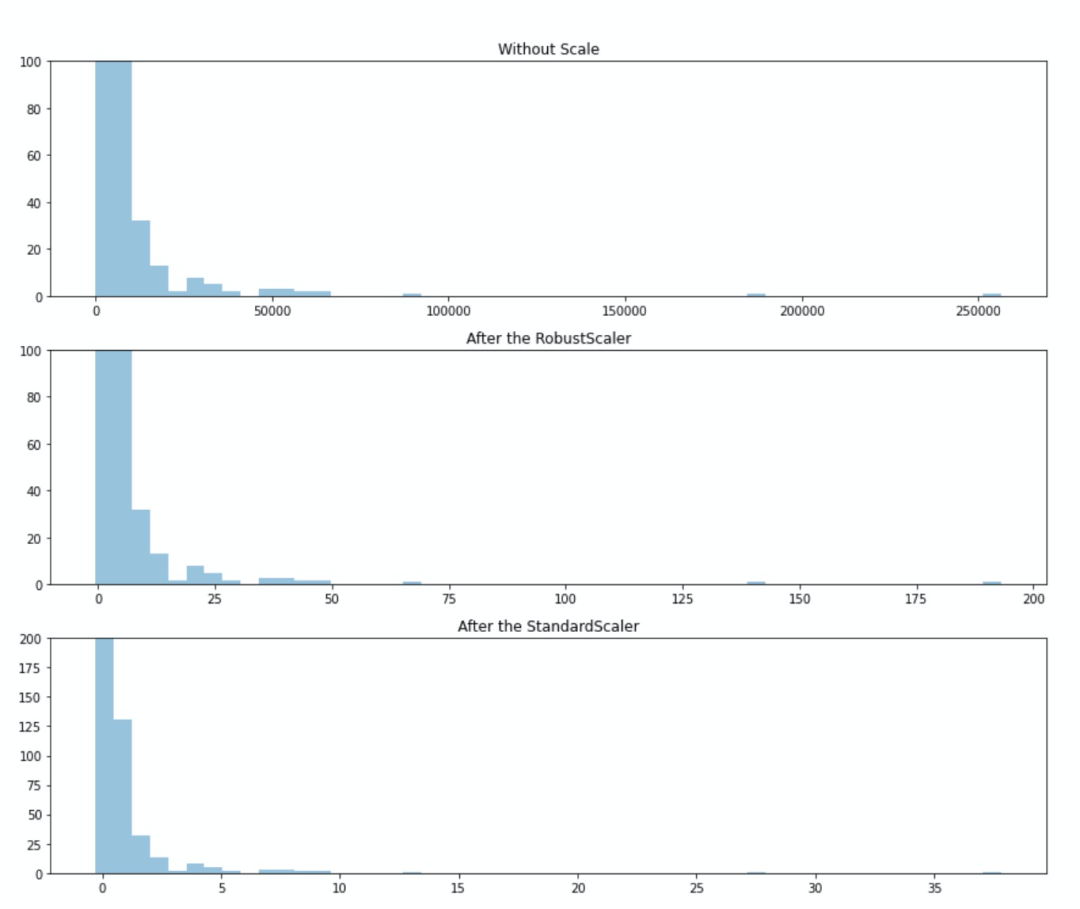
我們很容易發(fā)現(xiàn)StandardScaler使得異常值更接近均值了,但是在RobustScaler后,異常值還是顯得比較異常.
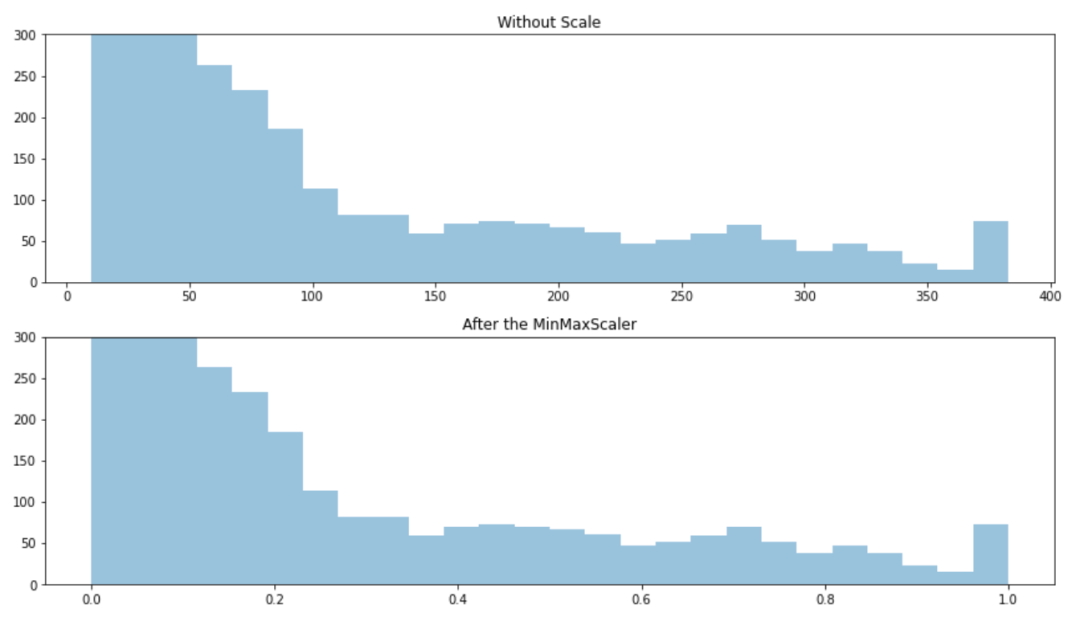
3、MinMaxScaler
from sklearn.preprocessing import MinMaxScalerMinMaxScaler使得數(shù)據(jù)縮放到0~1之間,縮放由最小值和最大值決定,因此會(huì)受到異常值影響.并且對(duì)新出現(xiàn)的最大最小值并不友好.
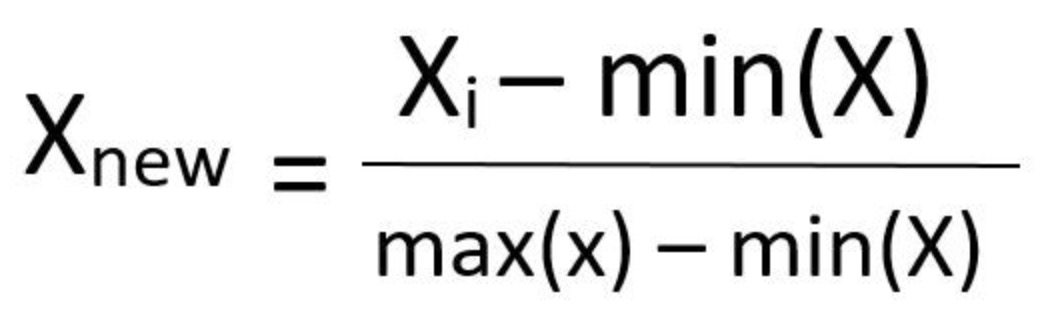
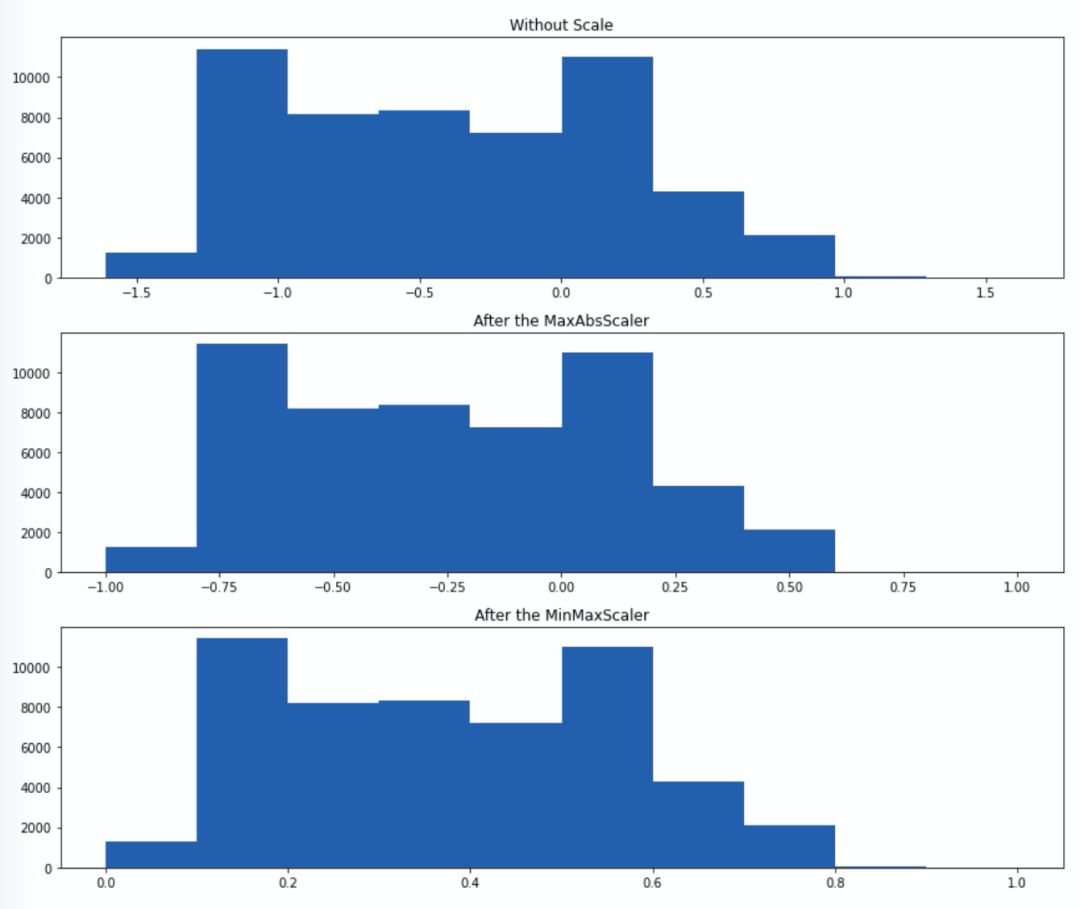
4、MaxAbsScaler
from sklearn.preprocessing import MaxAbsScaler該縮放方法不會(huì)破壞數(shù)據(jù)的稀疏性,也不會(huì)改變數(shù)據(jù)的分布,僅僅把數(shù)據(jù)縮放到了-1~1之間.MaxAbsScaler就是讓每個(gè)數(shù)據(jù)Xi/|Xmax|,值得注意的是,該方法對(duì)異常值也相當(dāng)敏感.
總結(jié)一下:
StandardScaler: 不適用于有異常值的數(shù)據(jù);使得均值為0.
RobustScaler: 適用于有異常值的數(shù)據(jù).
MinMaxScaler: 不適用于有異常值的數(shù)據(jù);使得數(shù)據(jù)縮放到0~1.
MaxAbsScaler: 不適用于有異常值的數(shù)據(jù);使得數(shù)據(jù)縮放到-1~1.
往期精彩回顧 本站qq群851320808,加入微信群請(qǐng)掃碼: