因?yàn)闀?huì)MySQL分庫(kù)分表,領(lǐng)導(dǎo)給我升職了

1 Sharding
把數(shù)據(jù)庫(kù)橫向擴(kuò)展到多個(gè)物理節(jié)點(diǎn)的一種有效方式,主要是為了突破數(shù)據(jù)庫(kù)單機(jī)服務(wù)器的 I/O 瓶頸,解決數(shù)據(jù)庫(kù)擴(kuò)展問題。
Sharding可簡(jiǎn)單定義為將大數(shù)據(jù)庫(kù)分布到多個(gè)物理節(jié)點(diǎn)上的一個(gè)分區(qū)方案。每一個(gè)分區(qū)包含數(shù)據(jù)庫(kù)的某一部分,稱為一個(gè)shard,分區(qū)方式可以是任意的,并不局限于傳統(tǒng)的水平分區(qū)和垂直分區(qū)。
一個(gè)shard可以包含多個(gè)表的內(nèi)容甚至可以包含多個(gè)數(shù)據(jù)庫(kù)實(shí)例中的內(nèi)容。每個(gè)shard被放置在一個(gè)數(shù)據(jù)庫(kù)服務(wù)器上。一個(gè)數(shù)據(jù)庫(kù)服務(wù)器可以處理一個(gè)或多個(gè)shard的數(shù)據(jù)。系統(tǒng)中需要有服務(wù)器進(jìn)行查詢路由轉(zhuǎn)發(fā),負(fù)責(zé)將查詢轉(zhuǎn)發(fā)到包含該查詢所訪問數(shù)據(jù)的shard或shards節(jié)點(diǎn)上去執(zhí)行。
2 垂直切分/水平切分
2.1 MySQL的擴(kuò)展方案
Scale Out 水平擴(kuò)展
一般對(duì)數(shù)據(jù)中心應(yīng)用,添加更多機(jī)器時(shí),應(yīng)用仍可很好利用這些資源提升自己的效率從而達(dá)到很好的擴(kuò)展性Scale Up 垂直擴(kuò)展
一般對(duì)單臺(tái)機(jī)器,Scale Up指當(dāng)某個(gè)計(jì)算節(jié)點(diǎn)添加更多的CPU Cores,存儲(chǔ)設(shè)備,使用更大的內(nèi)存時(shí),應(yīng)用可以很充分的利用這些資源來提升自己的效率從而達(dá)到很好的擴(kuò)展性
2.2 MySQL的Sharding策略
垂直切分:按功能模塊拆分,以解決
表與表之間的I/O競(jìng)爭(zhēng)
e.g. 將原來的老訂單庫(kù),切分為基礎(chǔ)訂單庫(kù)和訂單流程庫(kù)。數(shù)據(jù)庫(kù)之間的表結(jié)構(gòu)不同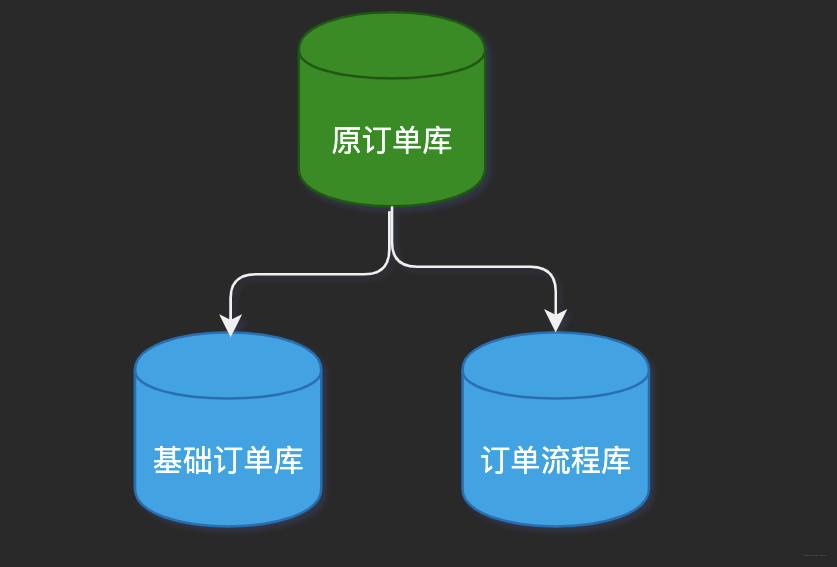
水平切分:將
同個(gè)表的數(shù)據(jù)分塊,保存至不同的數(shù)據(jù)庫(kù)
以解決單表中數(shù)據(jù)量增長(zhǎng)壓力。這些數(shù)據(jù)庫(kù)中的表結(jié)構(gòu)完全相同
2.3 表結(jié)構(gòu)設(shè)計(jì)案例
垂直切分
大字段
單獨(dú)將大字段建在另外的表中,提高基礎(chǔ)表的訪問性能,原則上在性能關(guān)鍵的應(yīng)用中應(yīng)當(dāng)避免數(shù)據(jù)庫(kù)的大字段按用途
例如企業(yè)物料屬性,可以按照基本屬性、銷售屬性、采購(gòu)屬性、生產(chǎn)制造屬性、財(cái)務(wù)會(huì)計(jì)屬性等用途垂直切分按訪問頻率
例如電子商務(wù)、Web 2.0系統(tǒng)中,如果用戶屬性設(shè)置非常多,可以將基本、使用頻繁的屬性和不常用的屬性垂直切分開
水平切分
比如在線電子商務(wù)網(wǎng)站,訂單表數(shù)據(jù)量過大,按照年度、月度水平切分
網(wǎng)站注冊(cè)用戶、在線活躍用戶過多,按照用戶ID范圍等方式,將相關(guān)用戶以及該用戶緊密關(guān)聯(lián)的表做水平切分
論壇的置頂帖,因?yàn)樯婕暗椒猪?yè)問題,每頁(yè)都需顯示置頂貼,這種情況可以把置頂貼水平切分開來,避免取置頂帖子時(shí)從所有帖子的表中讀取
3 分表和分區(qū)
分表:把一張表分成多個(gè)小表;
分區(qū):把一張表的數(shù)據(jù)分成N多個(gè)區(qū)塊,這些區(qū)塊可以在同一個(gè)磁盤上,也可以在不同的磁盤上。
3.1 分表和分區(qū)的區(qū)別
實(shí)現(xiàn)方式
MySQL的一張表分成多表后,每個(gè)小表都是完整的一張表,都對(duì)應(yīng)三個(gè)文件(MyISAM引擎:.MYD數(shù)據(jù)文件,.MYI索引文件,.frm表結(jié)構(gòu)文件)
數(shù)據(jù)處理
分表后數(shù)據(jù)都存放在分表里,總表只是個(gè)外殼,存取數(shù)據(jù)發(fā)生在一個(gè)個(gè)的分表里
分區(qū)則不存在分表的概念,分區(qū)只不過把存放數(shù)據(jù)的文件分成許多小塊,分區(qū)后的表還是一張表,數(shù)據(jù)處理還是自己完成。
性能
分表后,單表的并發(fā)能力提高了,磁盤I/O性能也提高了。
分表的關(guān)鍵是存取數(shù)據(jù)時(shí),如何提高 MySQL并發(fā)能力
分區(qū)突破了磁盤I/O瓶頸,想提高磁盤的讀寫能力,來增加MySQL性能
實(shí)現(xiàn)成本
分表的方法有很多,用merge來分表,是最簡(jiǎn)單的一種。
這種方式和分區(qū)難易度差不多,并且對(duì)程序代碼透明,如果用其他分表方式就比分區(qū)麻煩
分區(qū)實(shí)現(xiàn)比較簡(jiǎn)單,建立分區(qū)表,跟建平常的表沒區(qū)別,并且對(duì)代碼端透明
3.2 分區(qū)適用場(chǎng)景
一張表的查詢速度慢到影響使用
表中的數(shù)據(jù)是分段的
對(duì)數(shù)據(jù)的操作往往只涉及一部分?jǐn)?shù)據(jù),而不是所有的數(shù)據(jù)
3.3 分表適用場(chǎng)景
一張表的查詢速度慢到影響使用
頻繁插入或連接查詢時(shí),速度變慢
分表的實(shí)現(xiàn)需要業(yè)務(wù)結(jié)合實(shí)現(xiàn)和遷移,較為復(fù)雜
4 分庫(kù)
分表能解決單表數(shù)據(jù)量過大帶來的查詢效率下降問題,但無法給數(shù)據(jù)庫(kù)的并發(fā)處理能力帶來質(zhì)的提升。面對(duì)高并發(fā)的讀寫訪問,當(dāng)數(shù)據(jù)庫(kù)主服務(wù)器無法承載寫壓力,不管如何擴(kuò)展從服務(wù)器,都沒有意義了。
換個(gè)思路,對(duì)數(shù)據(jù)庫(kù)進(jìn)行拆分,提高數(shù)據(jù)庫(kù)寫性能,即分庫(kù)。
4.1 分庫(kù)的解決方案
一個(gè)MySQL實(shí)例中的多個(gè)數(shù)據(jù)庫(kù)拆到不同MySQL實(shí)例中:
缺陷
有的節(jié)點(diǎn)還是無法承受寫壓力。
4.1.1 查詢切分
將key和庫(kù)的映射關(guān)系單獨(dú)記錄在一個(gè)數(shù)據(jù)庫(kù)。
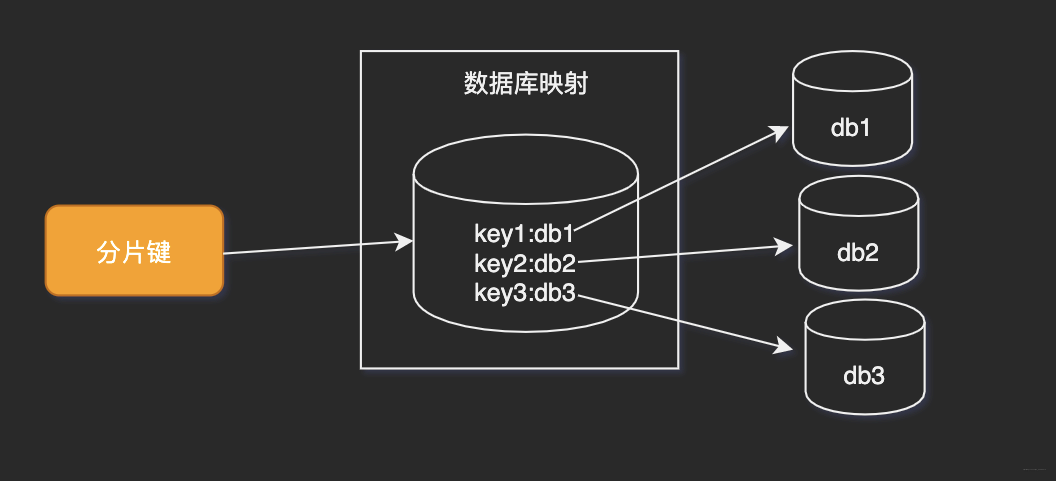
優(yōu)點(diǎn)
key和庫(kù)的映射算法可以隨便自定義缺點(diǎn)
引入了額外的單點(diǎn)
4.1.2 范圍切分
按照時(shí)間區(qū)間或ID區(qū)間切分。
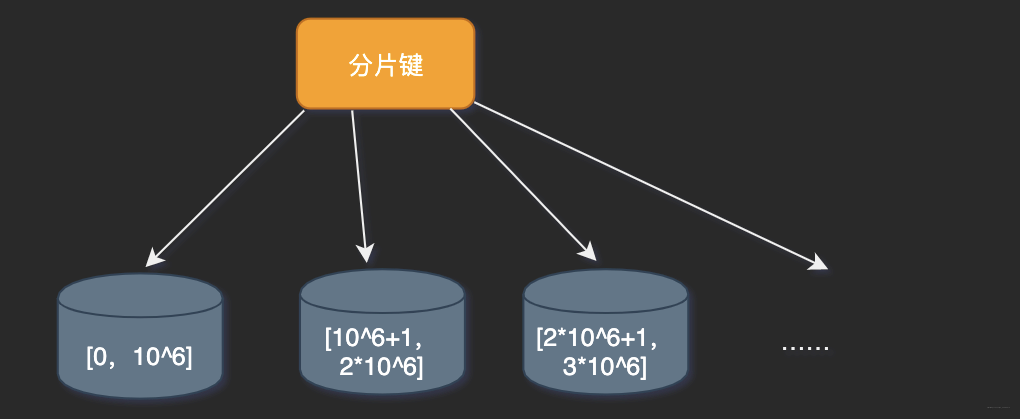
優(yōu)點(diǎn)
單表容量可控,水平擴(kuò)展很方便。缺點(diǎn)
無法解決集中寫入的瓶頸問題。
4.1.3 Hash切分(重點(diǎn))
一般都是采用hash切分。
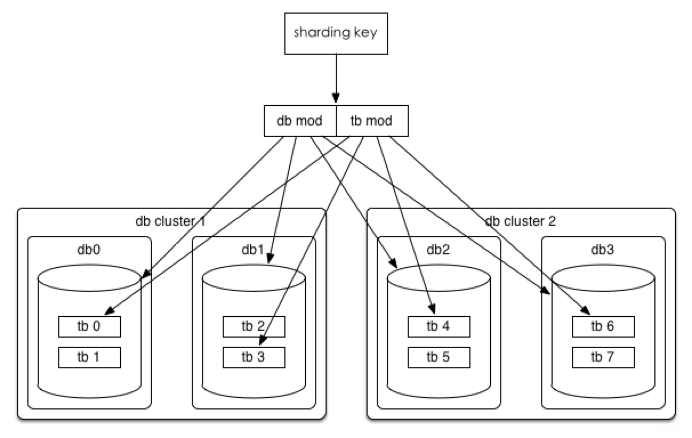
數(shù)據(jù)水平切分后我們希望是一勞永逸或者是易于水平擴(kuò)展的,所以推薦采用mod 2^n這種一致性Hash。
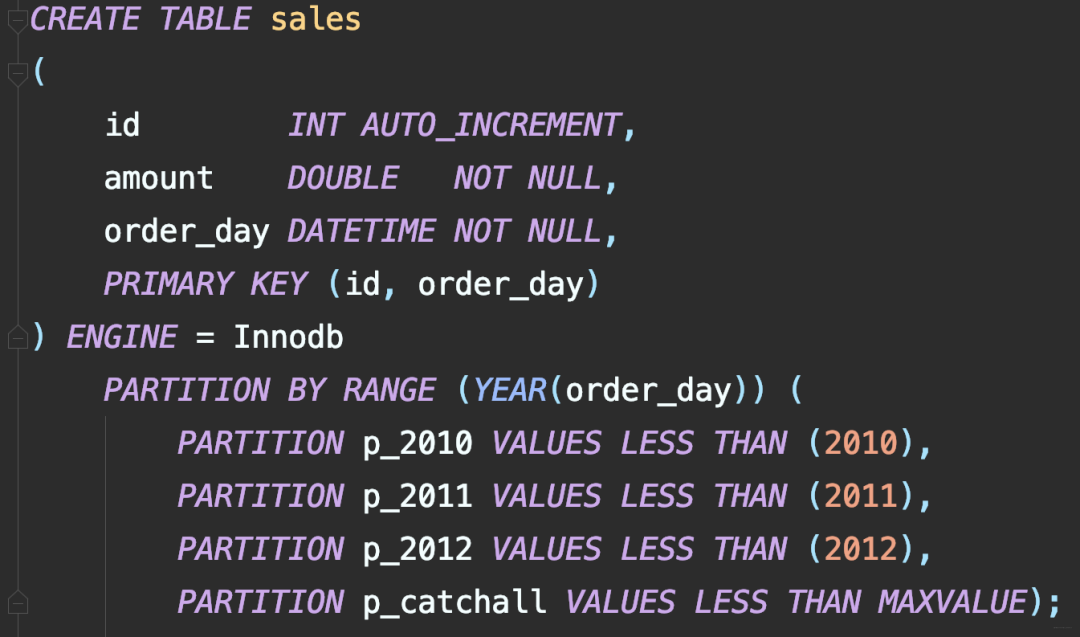
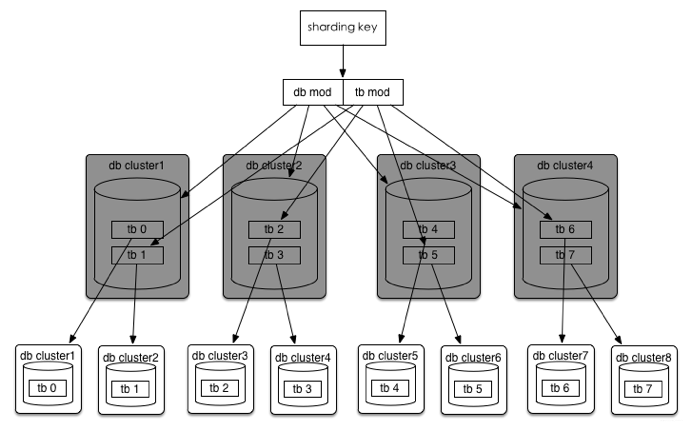
比如一個(gè)訂單庫(kù),分庫(kù)分表方案是32*32,即通過UserId后四位mod 32分到32個(gè)庫(kù)中,同時(shí)再將UserId后四位Div 32 Mod 32將每個(gè)庫(kù)分為32個(gè)表,共計(jì)分為1024張表。
線上部署情況為8個(gè)集群(主從),每個(gè)集群4個(gè)庫(kù)。
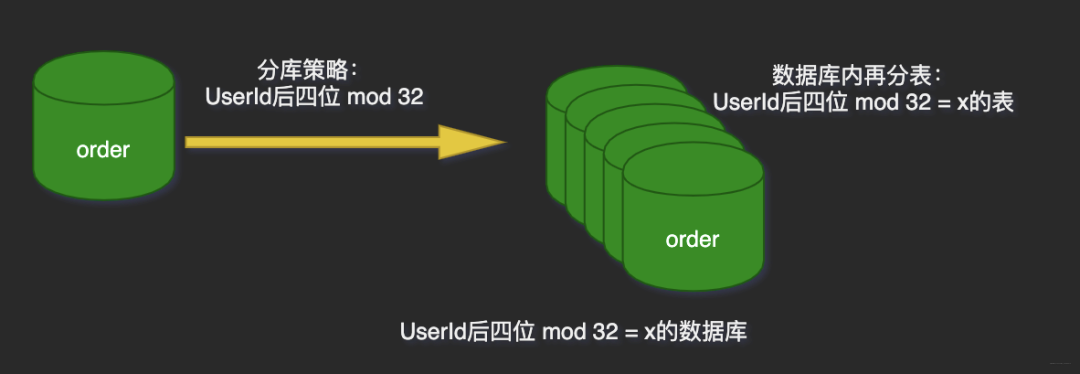
為什么說這易于水平擴(kuò)展?分析如下場(chǎng)景:
數(shù)據(jù)庫(kù)性能達(dá)到瓶頸
現(xiàn)有規(guī)則不變,可直接擴(kuò)展到32個(gè)數(shù)據(jù)庫(kù)集群。
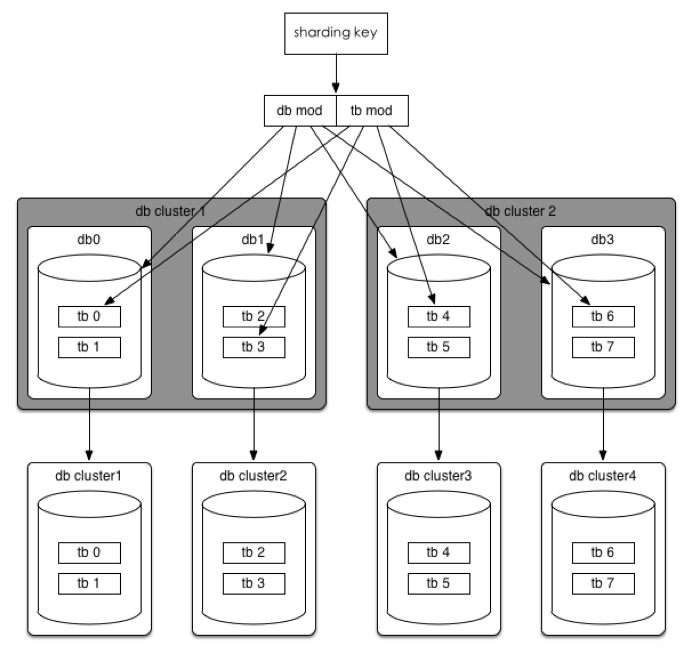
如果32個(gè)集群也無法滿足需求,那么將分庫(kù)分表規(guī)則調(diào)整為(322^n)(32?2^n),可以達(dá)到最多1024個(gè)集群。
單表容量達(dá)到瓶頸
或1024都無法滿足。
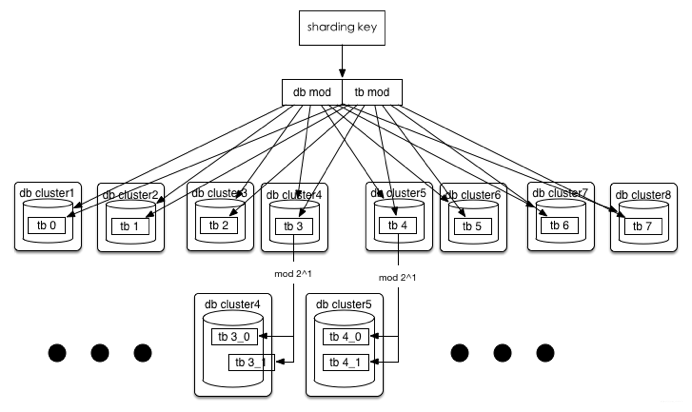
假如單表都突破200G,2001024=200T
沒關(guān)系,32 (32 * 2^n),這時(shí)分庫(kù)規(guī)則不變,單庫(kù)里的表再裂變,當(dāng)然,在目前訂單這種規(guī)則下(用userId后四位 mod)還是有極限的,因?yàn)橹挥兴奈唬宰疃嗖?192個(gè)表。
選擇分片鍵
盡量避免跨分區(qū)查詢的發(fā)生(無法完全避免)
盡量使各個(gè)分片中的數(shù)據(jù)平均
如何存儲(chǔ)無需分片的表
每個(gè)分片中存儲(chǔ)一份相同的數(shù)據(jù)
對(duì)于數(shù)據(jù)量不大且并不經(jīng)常被更新的字典類表,經(jīng)常需要和分區(qū)表一起關(guān)聯(lián)查詢,每個(gè)分片中存儲(chǔ)一份冗余的數(shù)據(jù)可以更好提高查詢效率,維護(hù)其一致性就很重要了。使用額外的節(jié)點(diǎn)統(tǒng)一存儲(chǔ)
沒有冗余問題,但是查詢效率較差,需要匯總在節(jié)點(diǎn)上部署分片
每個(gè)分片使用單一數(shù)據(jù)庫(kù),并且數(shù)據(jù)庫(kù)名也相同
結(jié)構(gòu)也保持相同,和單一節(jié)點(diǎn)時(shí)的一致將多個(gè)分片表存儲(chǔ)在一個(gè)數(shù)據(jù)庫(kù)中,并在表名上加入分片號(hào)后綴
在一個(gè)節(jié)點(diǎn)中部署多個(gè)數(shù)據(jù)庫(kù),每個(gè)數(shù)據(jù)庫(kù)包含一個(gè)切片
5 分庫(kù)分表后的難題
全局唯一ID生成方案
方案很多,主流的如下:
數(shù)據(jù)庫(kù)自增ID
使用
auto_increment_incrementauto_increment_offset
系統(tǒng)變量讓MySQL以期望的值和偏移量來增加auto_increment列的值。
優(yōu)點(diǎn)
最簡(jiǎn)單,不依賴于某節(jié)點(diǎn),較普遍采用但需要非常仔細(xì)的配置服務(wù)器哦!缺點(diǎn)
單點(diǎn)風(fēng)險(xiǎn)、單機(jī)性能瓶頸。不適用于一個(gè)節(jié)點(diǎn)包含多個(gè)分區(qū)表的場(chǎng)景。
數(shù)據(jù)庫(kù)集群并設(shè)置相應(yīng)步長(zhǎng)(Flickr方案)
在一個(gè)全局?jǐn)?shù)據(jù)庫(kù)節(jié)點(diǎn)中創(chuàng)建一個(gè)包含auto_increment列的表,應(yīng)用通過該表生成唯一數(shù)字。
優(yōu)點(diǎn)
高可用、ID較簡(jiǎn)潔。缺點(diǎn)
需要單獨(dú)的數(shù)據(jù)庫(kù)集群。
Redis等緩存NoSQL服務(wù)
避免了MySQL性能低的問題。
Snowflake(雪花算法)
優(yōu)點(diǎn)
高性能高可用、易拓展。缺點(diǎn)
需要獨(dú)立的集群以及ZK。各種GUID、Random算法
優(yōu)點(diǎn)
簡(jiǎn)單。缺點(diǎn)
生成ID較長(zhǎng),且有重復(fù)幾率。業(yè)務(wù)字段(美團(tuán)的實(shí)踐方案)
為減少運(yùn)營(yíng)成本并減少額外風(fēng)險(xiǎn),美團(tuán)排除了所有需要獨(dú)立集群的方案,采用了帶有業(yè)務(wù)屬性的方案:
時(shí)間戳+用戶標(biāo)識(shí)碼+隨機(jī)數(shù)
優(yōu)點(diǎn):
方便、成本低
基本無重復(fù)的可能
自帶分庫(kù)規(guī)則,這里的用戶標(biāo)識(shí)碼即為
userID的后四位,在查詢場(chǎng)景,只需訂單號(hào)即可匹配到相應(yīng)庫(kù)表而無需用戶ID,只取四位是希望訂單號(hào)盡可能短,評(píng)估后四位已足。可排序,因?yàn)闀r(shí)間戳在最前
缺點(diǎn)
長(zhǎng)度稍長(zhǎng),性能要比int/bigint的稍差。
事務(wù)
分庫(kù)分表后,由于數(shù)據(jù)存到了不同庫(kù),數(shù)據(jù)庫(kù)事務(wù)管理出現(xiàn)困難。如果依賴數(shù)據(jù)庫(kù)本身的分布式事務(wù)管理功能去執(zhí)行事務(wù),將付出高昂的性能代價(jià);如果由應(yīng)用程序去協(xié)助控制,形成程序邏輯上的事務(wù),又會(huì)造成編程方面的負(fù)擔(dān)。
解決方案
比如美團(tuán),是將整個(gè)訂單領(lǐng)域聚合體切分,維度一致,所以對(duì)聚合體的事務(wù)是支持的。
跨庫(kù)跨表的join問題
分庫(kù)分表之后,難免會(huì)將原本邏輯關(guān)聯(lián)性很強(qiáng)的數(shù)據(jù)劃分到不同的表、不同的庫(kù)上,這時(shí),表的關(guān)聯(lián)操作將受到限制,我們無法join位于不同分庫(kù)的表,也無法join分表粒度不同的表,結(jié)果原本一次詢能夠完成的業(yè)務(wù),可能需要多次查詢才能完成。
解決方案
垂直切分后,就跟join說拜拜了;水平切分后,查詢的條件一定要在切分的維度內(nèi)。
比如查詢具體某個(gè)用戶下的訂單等;
禁止不帶切分的維度的查詢,即使中間件可以支持這種查詢,可以在內(nèi)存中組裝,但是這種需求往往不應(yīng)該在在線庫(kù)查詢,或者可以通過其他方法轉(zhuǎn)換到切分的維度來實(shí)現(xiàn)。
額外的數(shù)據(jù)管理和運(yùn)算壓力
額外的數(shù)據(jù)管理負(fù)擔(dān),最顯而易見的就是數(shù)據(jù)的定位問題和數(shù)據(jù)的增刪改查的重復(fù)執(zhí)行問題,這些都可以通過應(yīng)用程序解決,但必然引起額外的邏輯運(yùn)算。
例如,對(duì)于一個(gè)記錄用戶成績(jī)的用戶數(shù)據(jù)表userTable,業(yè)務(wù)要求查出成績(jī)最好的100位,在進(jìn)行分表前,只需一個(gè)order by即可。但分表后,將需要n個(gè)order by語句,分別查出每一個(gè)分表前100名用戶數(shù)據(jù),然后再對(duì)這些數(shù)據(jù)進(jìn)行合并計(jì)算,才能得出結(jié)果。
總結(jié)
并非所有表都需要水平拆分,要看增長(zhǎng)的類型和速度,水平拆分是大招,拆分后會(huì)增加開發(fā)的復(fù)雜度,不到萬不得已不使用。
拆分維度的選擇很重要,要盡可能在解決拆分前問題的基礎(chǔ)上,便于開發(fā)。
參考
https://tech.meituan.com/2016/11/18/dianping-order-db-sharding.html