
超詳解!Transformer + self-attention
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號
重磅干貨,第一時間送達(dá)

最近剛開始閱讀transformer文獻(xiàn)感覺有一些晦澀,尤其是關(guān)于其中Q、K、V的理解,故在這里記錄自己的閱讀心得,供于分享交流
一、self-attention部分預(yù)熱
1.1 計算順序
首先了解NLP中self-attention計算順序:

1.2 計算公式詳解
有些突兀,不著急,接下來我們看看self-attention的公式長什么樣子:
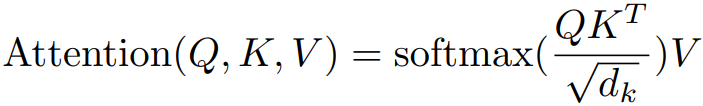 公式1
公式1此公式在論文《attention is all your need》中出現(xiàn),拋開Q、K、V與dk不看,則最開始的self-attention注意力計算公式為:
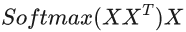 公式2
公式2兩公式對比可以發(fā)現(xiàn),Q、K、V都是由輸入詞X(詞向量)經(jīng)過某種變換所得,向量與轉(zhuǎn)置后的向量相乘,我們可以看做向量與轉(zhuǎn)置后得到的矩陣空間中每一個子向量做點(diǎn)積運(yùn)算,即向量內(nèi)積
值得注意的是:我們輸入的只是一串字符,這里要把每個詞轉(zhuǎn)成我們后續(xù)可以進(jìn)行操作的詞向量,需要進(jìn)行embedding操作,可以理解為把一個詞如love轉(zhuǎn)換為對應(yīng)的語義信息如【1, 3, 0, 5】,當(dāng)然為了獲取詞在輸入序列中的位置信息,我們在后續(xù)的transformer中增加了對應(yīng)詞的位置信息(positional encoding)
內(nèi)積(點(diǎn)乘)的幾何意義包括:
表征或計算兩個向量之間的夾角
a向量在b向量方向上的投影
兩向量相乘得一新的向量,即A*B=C,那么這個新的向量C就在一定個程度上代表向量A對向量B的投影度大小
換個角度思考,投影度大小即輸入序列中對應(yīng)詞與詞的相關(guān)度,投影度越大(夾角越小),意味著在一定程度上兩個詞之間的相關(guān)度越大(詞向量是文本形式的詞在高維空間(抽象化)的數(shù)值形式映射)
至此公式2中的X*X^T理解完畢,那么對它進(jìn)行softmax函數(shù)計算,即可得到我們想要的權(quán)重
值得注意的是:這里的權(quán)重過分關(guān)注于自身的位置,即對于X*X^T來說,最終的權(quán)重過分關(guān)注X對其他詞向量的注意力而在一定程度上忽略了其他詞,故在后續(xù)的transformer中作者采取了多頭注意力機(jī)制來彌補(bǔ)
同時softmax函數(shù)還很好的使得權(quán)重和為1,我們只需將得到的權(quán)重乘以原來的X,即可得到最終的輸出,這個輸出經(jīng)過了一次詞與詞之間相關(guān)度(也就是注意力)的計算,這也完成了一個self-attention的過程
現(xiàn)在讓我們回到公式1:
Q、K、V究竟是何方神圣?在上文部分有提到:Q、K、V都是由原X經(jīng)過某種變換所得到的,用圖來表示的話,可以用下面這張圖:
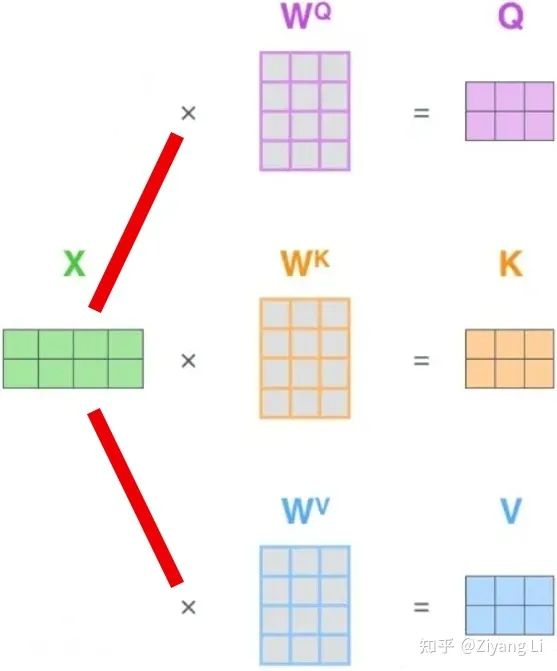
從圖中不難看出,輸入X乘以Q、K、V對應(yīng)的W權(quán)值矩陣,就可以得到我們想要的Q、K、V
注意:此處的Q、K、V僅局限于后續(xù)Encoder和Decoder在各自輸入部分的編碼過程,Encoder和Decoder之間交互的Q、K和V并非此(后文會進(jìn)行詳細(xì)介紹)
補(bǔ)充:最開始的W權(quán)值矩陣需要初始化,在后續(xù)BP的過程中,W的具體數(shù)值會不斷更新學(xué)習(xí),這樣做的好處不僅僅是可以提高模型的非線性程度,還能提高模型擬合能力,通過不斷學(xué)習(xí)讓注意力權(quán)值正確分布
公式中還在送入softmax前對權(quán)值矩陣乘以一個dk^(-1/2)(dk代表K的維度,同樣的有dq、dv),這樣做顯然是對原權(quán)值矩陣做了一次縮放,這樣做的意義是什么?
如果我們在計算X*X^T完畢后,矩陣中元素的方差很大,這就會使得softmax的分布變得極其陡峭,從而影響梯度穩(wěn)定計算,此時我們進(jìn)行一次縮放,再將方差縮放到1,softmax的分布變得平緩穩(wěn)定起來,進(jìn)而在之后的訓(xùn)練過程中保持梯度穩(wěn)定。
至此self-attention的部分已經(jīng)講解完畢,接下來我們回到transformer中,一起來庖丁解牛。
二、Transformer部分
2.1 整體結(jié)構(gòu)
首先來縱觀transformer整體結(jié)構(gòu)(左半部分是encode,右半部分是decode):
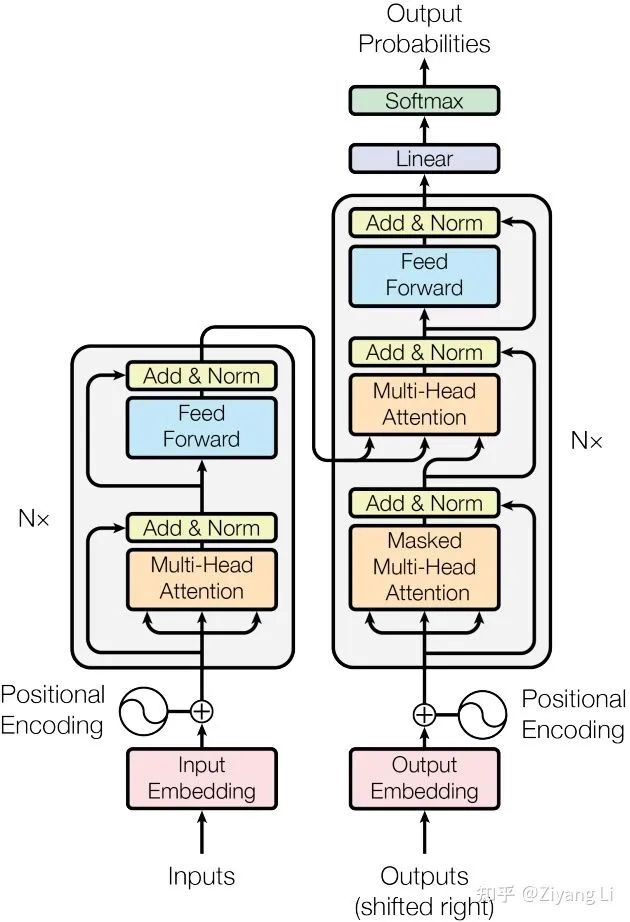 Transformer模型結(jié)構(gòu)
Transformer模型結(jié)構(gòu)2.2 encoder
首先分析左半部分,從下往上看inputs即為我們輸入的字符串序列,此時在計算前我們要對輸入序列進(jìn)行如圖所示的Input Embedding,此處即為上文self-attention中的語義信息轉(zhuǎn)換,把輸入的每個詞轉(zhuǎn)換為對應(yīng)的詞向量
同時transformer在embedding部分增加了位置編碼,其位置計算公式為:
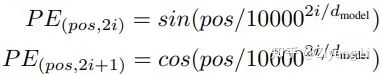
pos 指當(dāng)前詞在句子中的位置, 是指向量中每個值的 下標(biāo)(索引);不難看出在偶數(shù)位置,使用正弦編碼,在奇數(shù)位置,使用余弦編碼;最終輸出我們想要的位置向量
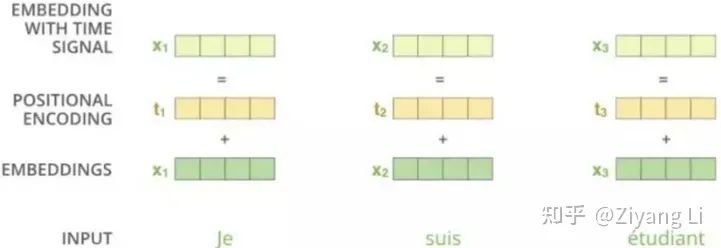
此處可以用一張圖來表示:
接著回到transformer模型結(jié)構(gòu)圖,從左半部分繼續(xù)向上看,來到了Encoder部分,左側(cè)有一個 ×N 即多個encode疊加,右側(cè)同理
順著線路向上看,輸入的一條路(一個詞向量)分成三路(分別對應(yīng)Q、K、V)進(jìn)入了Multi-Head Attention層,同時輸入的一條路增加了一個殘差連接,通過簡單的Add操作與Multi-Head Attention層相作用,同時在進(jìn)入下一層前還進(jìn)行BN層歸一化
2.3 Multi-Head Attention層
那么接下來我們就一起解析Multi-Head Attention層,其具體結(jié)構(gòu)如下:
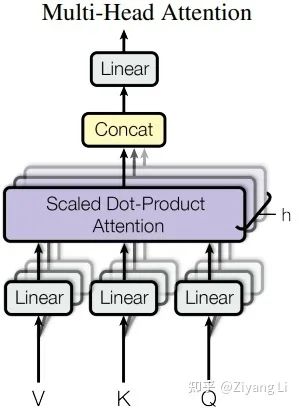
從圖中可以看出Q、K、V首先經(jīng)過了一個Linear層做線性變換,接著進(jìn)入到了Scaled Dot-Product Attention層,接下來我們對Scaled Dot-Product Attention層展開詳細(xì)分析:
對于Linear的理解,拿文中的話來說就是作者發(fā)現(xiàn)將Q、K、V經(jīng)過一個線性層的學(xué)習(xí)是非常有益的
2.4 Scaled Dot-Product Attention層
先上圖:
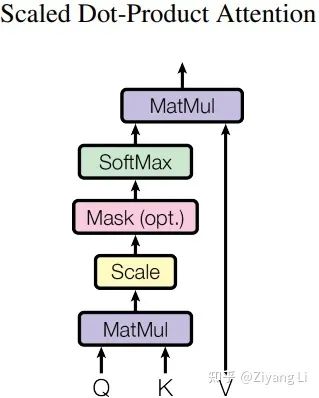
從下往上看,Q和K經(jīng)過MatMul層做矩陣相乘(即上文self-attention部分提到的X*X^T),接著來到Scale層進(jìn)行維度縮放(即上文self-attention部分提到的乘以dk^(-1/2))(注意這里的Mask是后續(xù)在decder部分需要使用的操作,encoder部分并沒有,此層在這里跳過)。最終我們經(jīng)過softmax得到的權(quán)值矩陣與V相乘,得到最終的輸出。接著回到Multi-Head Attention圖,我們可以看到在最終Linear輸出前有h次同樣的操作,那么這個h就對應(yīng)著標(biāo)題“多頭”,h是幾個頭就是幾個。
為什么要這樣操作呢?
論文中提到這樣的好處是可以允許模型在不同的表示子空間里學(xué)習(xí)到相關(guān)的信息。換個方式理解,我們可以類比CNN中同時使用多個濾波器的作用,我們想讓模型學(xué)習(xí)全方位、多層次、多角度的信息,學(xué)習(xí)更豐富的信息特征,就要使用多頭來完成。舉個例子來說,我們在閱讀文獻(xiàn)的時候,總是對文獻(xiàn)的摘要注意頗多,同時我們還對文獻(xiàn)中的實(shí)驗(yàn)數(shù)據(jù)、實(shí)驗(yàn)結(jié)論想要有所了解,一般到最后才是文獻(xiàn)的方法部分以及一些公式,這么一套流程下來我們對文獻(xiàn)整體有了更豐富的掌握,那么“多頭”即可類比于此(盡管有些許勉強(qiáng))。
在Multi-Head Attention層得到最終的輸出結(jié)果后,我們來到了Feed Forward層(見圖4),同時還有一個一樣的殘差連接與層歸一化處理。那么Feed Forward層的作用是什么呢?
細(xì)讀文章可以發(fā)現(xiàn),所謂Feed Forward即一個普通MLP結(jié)構(gòu),即全連接1 -> Relu -> dropout -> 全連接2,拿文中的公式表述為:
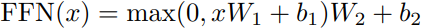
添加這一層的目的也是為了增加模型的非線性表達(dá)能力,提高模型擬合程度。
2.5 decoder
至此左半部分的encode講解完畢,第N個encoder輸出的K、V與decode部分進(jìn)行交互,但我們先從decoder部分的下方輸入開始看起(這里再把圖拿過來):
從下往上看,Outputs是我們模型上一次的預(yù)測結(jié)果+shifted right,關(guān)于shifted right的講解我們放在文末。輸入的序列經(jīng)過了和左半部分同樣的操作,即語義信息編碼+位置信息編碼,但在分成三路后進(jìn)入的卻是一個Masked Multi-Head Attention,比左半部分多了一個Mask,那么接下來我們就詳細(xì)分析一下這個Mask的具體內(nèi)容:
2.6 Mask
transformer的注意力計算我們已經(jīng)熟悉,需要注意的是在訓(xùn)練階段中,Decoder部分輸入的數(shù)據(jù)是一整句,句中包含了等待被預(yù)測的后續(xù)的序列信息,我們不希望這樣的情況發(fā)生,所以加入Mask操作來把那些不希望出現(xiàn)的信息掩蓋
那么如何實(shí)現(xiàn)Mask?
只需要初始化一個下三角矩陣為0,上三角元素均為負(fù)無窮的矩陣加到注意力矩陣上,因?yàn)樽⒁饬π枰?jīng)過softmax進(jìn)行歸一化,其中e^-? ?為0,因此可以將未來信息抹去。
?為0,因此可以將未來信息抹去。

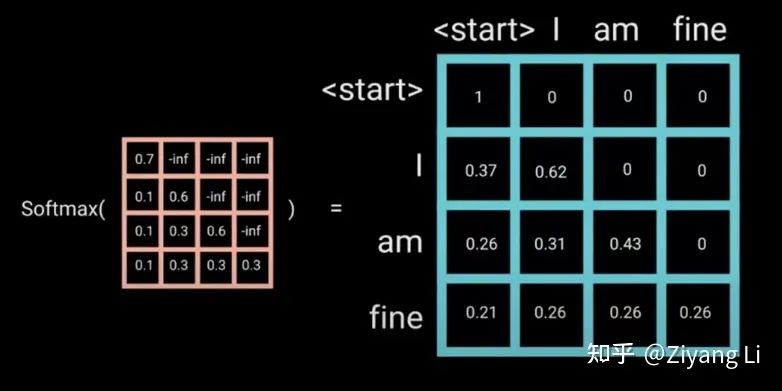
Masked Multi-Head Attention層的輸出經(jīng)過add&BN后與encoder部分輸入的K、V交匯在一起,來到了一個和左半部分一樣的Multi-Head Attention + Feed Forward層,decoder部分同樣重復(fù)迭代N次,最終送入Linear層做最后的softmax計算,輸出我們的預(yù)測值。
2.7 關(guān)于decoder的輸入(包括shifted right)講解:
一般訓(xùn)練階段的Decoder第一次輸入為起始符 + Positional Encoding,也可能是其他特殊的Token,目的是為了預(yù)測目標(biāo)序列的第一個單詞是什么。

我們將原輸入序列中的對應(yīng)詞整體右移一位(shifted right),即得到了起始符+embedding的輸入,對上圖進(jìn)行更為詳細(xì)的描述,即:

由圖中可以看出上文所述“Outputs是我們模型上一次的預(yù)測結(jié)果+shifted right”
三、The end
后期會對transformer代碼進(jìn)行詳細(xì)的分析,筆者才學(xué)淺陋,初步接觸機(jī)器學(xué)習(xí),難免有諸多錯誤與遺漏,懇請廣大讀者不吝指教!
https://arxiv.org/pdf/1706.03762.pdf
推薦閱讀
解讀:為什么要做特征歸一化/標(biāo)準(zhǔn)化?
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營維護(hù)的號,大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識,歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!