
CV和NLP中的無監(jiān)督預(yù)訓(xùn)練(生成式BERT/iGPT和判別式SimCLR/SimCSE)

極市導(dǎo)讀
本文歸納了一下CV和NLP各自領(lǐng)域的生成式和判別式的代表作及設(shè)計(jì)思路。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
在之前的文章中講過unsupervised learning主要分為生成式和判別式,那么unsupervised pretrain自然也分為生成式和判別式。目前CV和NLP都出現(xiàn)了非常強(qiáng)大的無監(jiān)督預(yù)訓(xùn)練,并且在生成式和判別式都各有造詣,本文主要想歸納一下CV和NLP各自領(lǐng)域的生成式和判別式的代表作及設(shè)計(jì)思路。其中CV的生成式以iGPT為例,判別式以SimCLR為例;NLP的生成式以BERT為例,判別式以SimCSE為例。有意思的是,iGPT的靈感來源于BERT,而SimCSE的靈感來源于SimCLR,這充分展現(xiàn)了CV和NLP兩個方向相互哺育,相輔相成的景象。
BERT
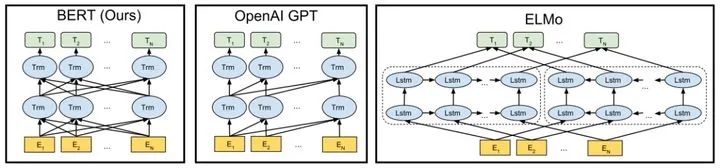
BERT之前主要有兩種主流的無監(jiān)督預(yù)訓(xùn)練方法:feature-based和fine-tuning。
feature-based方法
之前的ELMo無監(jiān)督預(yù)訓(xùn)練屬于feature-based的方法,先獨(dú)立訓(xùn)練從左到右和從右到左的LSTM,然后將兩部分輸出conate得到的features直接應(yīng)用于下游任務(wù)。
fine-tuning方法
GPT和BERT屬于fine-tuning方法,fine-tuning方法預(yù)訓(xùn)練的features不直接應(yīng)用于下游任務(wù),需要針對下游任務(wù)進(jìn)行fine-tuning。
GPT使用從左到右的單向Transformer進(jìn)行預(yù)訓(xùn)練,然后針對下游任務(wù)進(jìn)行fine-tuning。
BERT使用雙向Transformer進(jìn)行預(yù)訓(xùn)練,相較于GPT,更加充分的利用上下文信息,然后針對下游任務(wù)進(jìn)行fine-tuning。
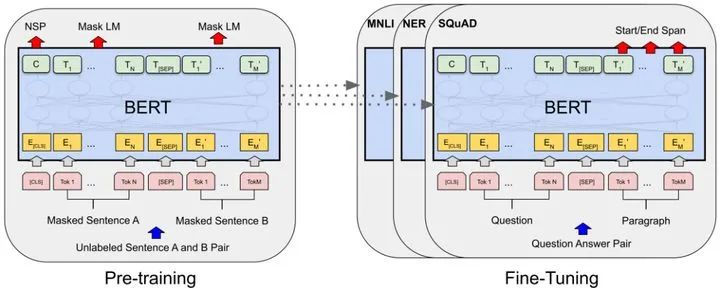
Input/Output Representations
為了BERT更好的應(yīng)用于下游任務(wù),BERT預(yù)訓(xùn)練的時(shí)候輸入可以模糊表示,比如既可以表示成單個句子也可以表示成一對句子(<Question,Answer>)。輸入的第一個token總是特指classification token [CLS],對應(yīng)的輸出位置用來做分類任務(wù)。一對句子作為輸入時(shí),表示成單個序列,通過特殊的token [SEP]來分開不同句子,并且對每個輸入token加上一個可學(xué)習(xí)的embedding來指示屬于句子A還是屬于句子B。如上面左圖所示,將input embedding表示為E,token [CLS]對應(yīng)的輸出向量是C,第i個input token的輸出是。
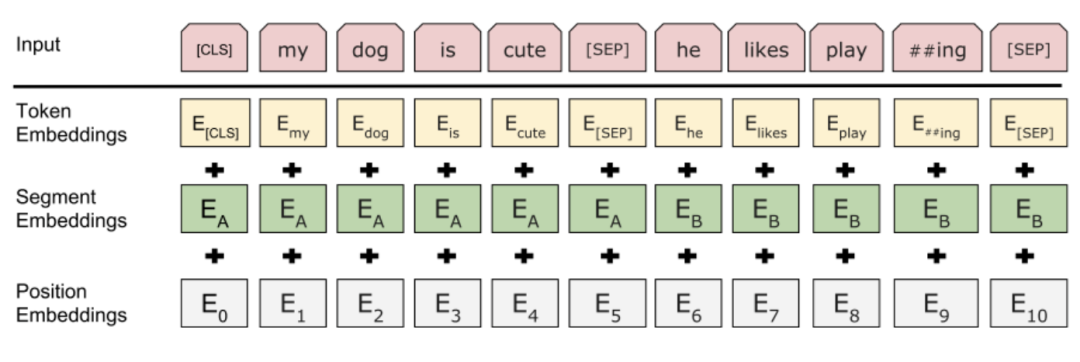
其中input embedding由Position Embeddings、Segment Embeddings和Token Embeddings三部分相加得到。Position Embeddings指示不同token的順序,Segment Embeddings指示不同token屬于哪個句子,Token Embeddings指示不同token的語義信息。
Pre-training BERT
BERT設(shè)計(jì)了兩種無監(jiān)督任務(wù)進(jìn)行預(yù)訓(xùn)練,可以更好的應(yīng)用到下游任務(wù)。
Task #1:Masked LM
為了訓(xùn)練一個深度雙向的Transformer,BERT以一定比例隨機(jī)mask掉一些輸入tokens,然后對這些masked tokens進(jìn)行預(yù)測,這個任務(wù)稱之為Masked LM(MLM),靈感來源于完形填空任務(wù),通過上下文預(yù)測masked的word是什么,最終BERT采用了隨機(jī)mask掉15%的輸入tokens。
雖然Masked LM任務(wù)可以獲得一個雙向的預(yù)訓(xùn)練模型,但是預(yù)訓(xùn)練和fine-tuning存在著gap,因?yàn)閒ine-tuning的時(shí)候,輸入是不存在[MASK]token的,為了緩解這種問題,實(shí)際訓(xùn)練的時(shí)候不總是采用[MASK] token來替換。其中[MASK] token有80%的概率被選中,random token有10%的概率被選中,還有10%的概率不改變token。
Task #2:Next Sentence Prediction(NSP)
很多下游任務(wù)是需要理解句子對之間的關(guān)系的,為了幫助下游任務(wù)更好的理解句子對之間的關(guān)系,BERT還設(shè)計(jì)了另一個預(yù)訓(xùn)練任務(wù)next sentence prediction(NSP)。具體的,選擇句子A和句子B作為預(yù)訓(xùn)練的輸入,有50%的概率B是A的下一個句子(標(biāo)記為IsNext),有50%的概率B不是A的下一個句子(標(biāo)記為NotNext),實(shí)際上就是一個二分類模型。如上面左圖所示,C被用于NSP任務(wù)進(jìn)行二分類。
iGPT
iGPT和BERT思路非常類似,只不過iGPT是在圖像上進(jìn)行的。
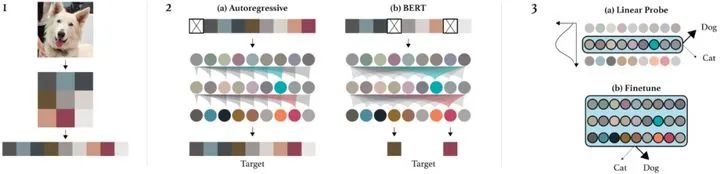
iGPT首先將輸入圖片resize然后reshape成1維序列。然后選擇兩種方法進(jìn)行預(yù)訓(xùn)練,其中Autoregressive的目標(biāo)是預(yù)測next pixel prediction(類似GPT單向模型),BERT的目標(biāo)是masked pixel prediction(類似BERT的MLM任務(wù))。最后,iGPT用linear probes(直接使用feature,類似feature-based的方法)或著fine-tuning兩種方法來評估學(xué)習(xí)到的特征。
iGPT可以通過圖像的上下文信息預(yù)測出masked的pixel,跟BERT有著異曲同工之妙。
看一下iGPT的生成效果,iGPT可以通過已知的上下文內(nèi)容對缺失部分進(jìn)行補(bǔ)充,看起來非常的邏輯自洽啊,tql

SimCLR
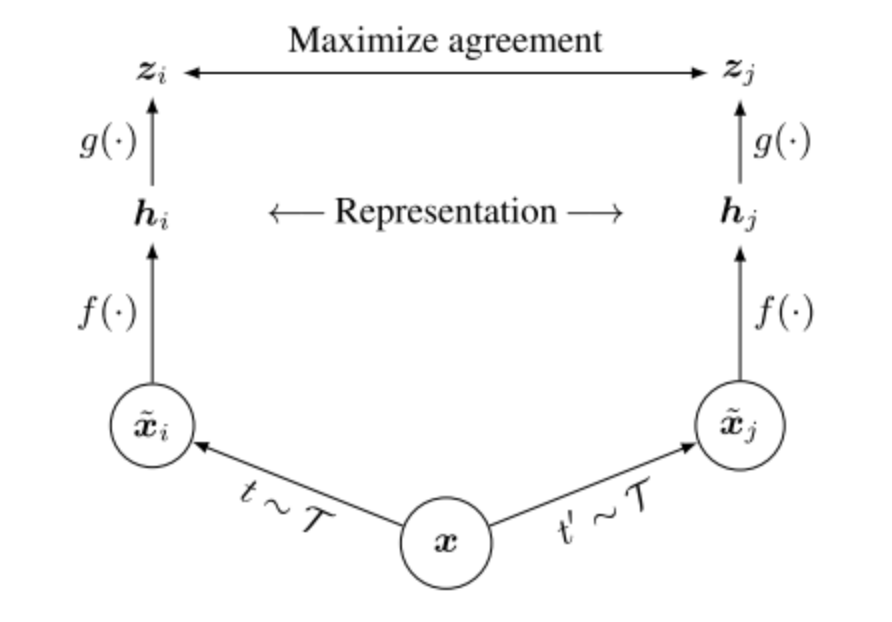
SimCLR是一種非常簡單直接的self-supervised方法。SimCLR框架流程如下:
1.對于每張輸入圖片隨機(jī)進(jìn)行數(shù)據(jù)增強(qiáng)得到兩個不同的views,同一張圖的兩個views可以認(rèn)為是positive pair。
2.每張輸入圖片的兩個views通過相同的encoder產(chǎn)生兩個表示向量。
3.每張輸入圖片的兩個表示向量通過相同的projection head產(chǎn)生兩個最終的向量。
4.最后對一個batch得到的最終向量進(jìn)行對比學(xué)習(xí),拉近positive pair,排斥negative pair。
對比學(xué)習(xí)的函數(shù)如下:
偽代碼如下:

一個batch有N個圖片,通過不同的數(shù)據(jù)增強(qiáng)產(chǎn)生2N個views,一個positive pair可以交換位置得到兩個loss,因此可以將一對positive pair的loss寫成positive pair交換位置的兩個loss之和的平均值,那么總的loss則是2N個views的loss的平均值。
SimCSE
看到計(jì)算機(jī)視覺的self-supervised大獲成功之后,自然語言處理也開始嘗試self-supervised。其中SimCSE的方法非常的簡單有效,在Sentence Embeddings的任務(wù)中大幅度超過之前的方法。
SimCSE名字應(yīng)該是借鑒了SimCLR。SimCSE提出了兩種方法,一種是Unsupervised SimCSE,另一種是Supervised SimCSE。
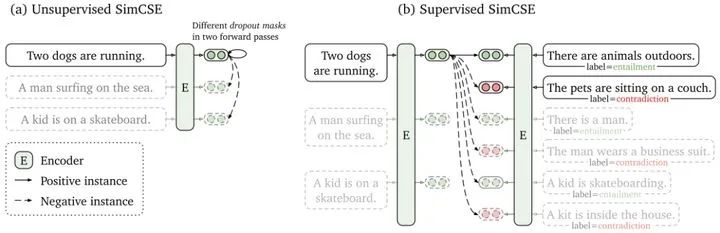
Unsupervised SimCSE的整體框架和SimCLR基本上保持一致。如圖(a)所示,將同一個句子通過兩種隨機(jī)的mask得到兩個postive pair(實(shí)線),不同句子的mask句子是negative pair(虛線),然后通過對比學(xué)習(xí)的方法,拉近positive pair,排斥negative pair。其中隨機(jī)mask句子其實(shí)就是句子的數(shù)據(jù)增強(qiáng),SimCSE實(shí)驗(yàn)發(fā)現(xiàn)隨機(jī)mask掉10%效果最好。
Supervised SimCSE的positive pair和negative pair是有標(biāo)注的。其中不同句子的entailment和contradiction都是negative pair,只有相同句子的entailment是positive pair。如圖(b)所示,第一個句子跟自己的entailment是positive pair(實(shí)線),跟其他句子的entailment/contradiction都是positive pair(虛線)。
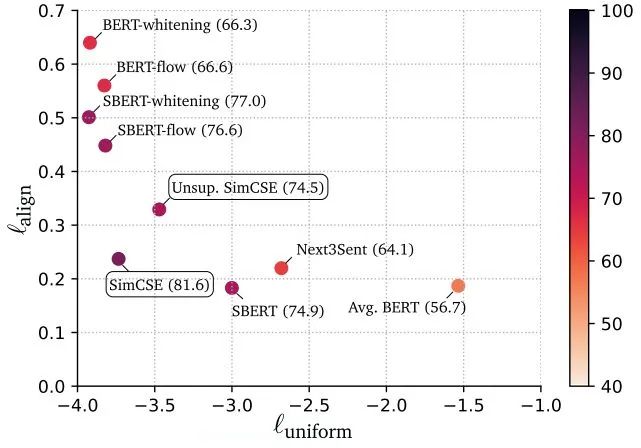
上圖align表示positive pair拉近的能力(越小越好),uniform表示negative pair排斥的能力(越小越好)。最終SimCSE可視化分析發(fā)現(xiàn),Unsup. SimCSE可以得到更好的align和uniform,SimCSE通過有標(biāo)注的監(jiān)督信號,可以進(jìn)一步的提升align和uniform。
另外,SimCSE還有各種消融實(shí)驗(yàn)和可視化分析,非常精彩,建議看原文細(xì)細(xì)品味
總結(jié)
下面引用lecun的一張圖,談一談對CV和NLP中無監(jiān)督預(yù)訓(xùn)練的看法
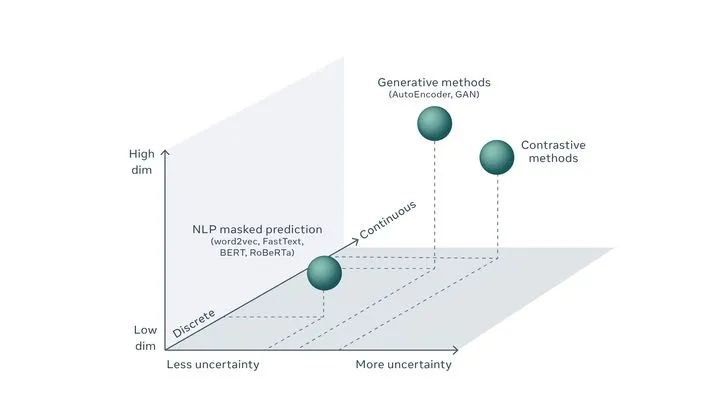
lecun通過Low dim -> High dim、Discrete -> Continuous和Less uncertainty -> More uncertainty三個維度來表示CV和NLP中不同無監(jiān)督方法的位置。文本是離散的,不確定性低,維度低;而圖像是連續(xù)的,不確定性高,維度高。模態(tài)的不同,導(dǎo)致了無監(jiān)督的處理方式上的不同。
NLP任務(wù)因?yàn)榇_定性更高,生成式無監(jiān)督預(yù)訓(xùn)練方法可以非常好進(jìn)行預(yù)測(如BERT),而由于CV任務(wù)不確定性更高,導(dǎo)致需要設(shè)計(jì)更自由靈活的方法,對比方法相比于生成方法自由度更高,可能更加適合CV任務(wù)作為無監(jiān)督預(yù)訓(xùn)練方法。
猜測未來NLP領(lǐng)域生成式和判別式會出現(xiàn)并存的局面,sentence級別任務(wù)傾向于使用判別式,word級別任務(wù)傾向于使用生成式。而CV領(lǐng)域判別式會占主導(dǎo)地位,一方面由于圖像是二維的,生成式計(jì)算量會更龐大,另一方面判別式的自由度會更高一些。
Reference
[1] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[2] Generative Pretraining from Pixels
[3] A Simple Framework for Contrastive Learning of Visual Representations
[4] SimCSE: Simple Contrastive Learning of Sentence Embeddings
[5] Self-supervised learning: The dark matter of intelligence (facebook.com)
本文亮點(diǎn)總結(jié)
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“83”獲取朱思語:基于深度學(xué)習(xí)的視覺稠密建圖和定位直播鏈接~

# CV技術(shù)社群邀請函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測-深圳)
即可申請加入極市目標(biāo)檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
