
2021-視頻監(jiān)控中的多目標(biāo)跟蹤綜述
點擊下方“AI算法與圖像處理”,一起進步!
重磅干貨,第一時間送達
前言?本文來自一篇2021的論文,論文簡要回顧了現(xiàn)有的SOTA模型和MOT算法、對多目標(biāo)跟蹤中的深度學(xué)習(xí)進行了討論、介紹了評估方面的指標(biāo)、數(shù)據(jù)集和基準結(jié)果,最后給出了結(jié)論。

視頻監(jiān)控中的多目標(biāo)跟蹤(MTT)是一項重要而富有挑戰(zhàn)性的任務(wù),由于其在各個領(lǐng)域的潛在應(yīng)用而引起了研究人員的廣泛關(guān)注。多目標(biāo)跟蹤任務(wù)需要在每幀中單獨定位目標(biāo),這仍然是一個巨大的挑戰(zhàn),因為目標(biāo)的外觀會立即發(fā)生變化,并且會出現(xiàn)極端的遮擋。除此之外,多目標(biāo)跟蹤框架需要執(zhí)行多個任務(wù),即目標(biāo)檢測、軌跡估計、幀間關(guān)聯(lián)和重新識別。已經(jīng)提出了各種方法,并做出了一些假設(shè),以將問題約束在特定問題的上下文中。本文對利用深度學(xué)習(xí)表征能力的MTT模型進行了綜述。
多目標(biāo)跟蹤分為目標(biāo)檢測和跟蹤兩個主要任務(wù)。為了區(qū)分組內(nèi)對象,MTT算法將唯一ID與在特定時間內(nèi)保持特定于該對象的每個檢測到的對象相關(guān)聯(lián)。然后利用這些ID來生成被跟蹤對象的運動軌跡。檢測通常由預(yù)先訓(xùn)練的檢測器提供,親和力模型提供檢測和方法之間的估計;優(yōu)化關(guān)聯(lián)
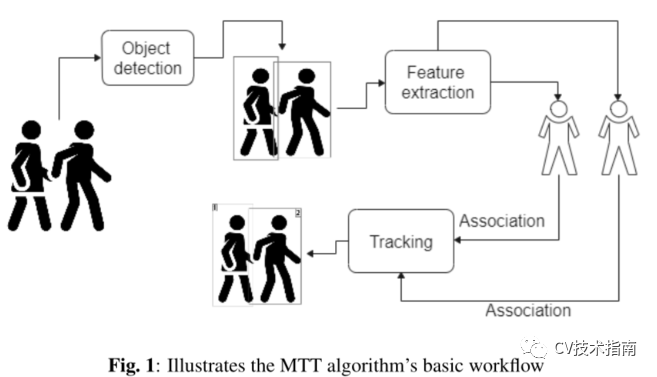
目標(biāo)檢測的精度決定了目標(biāo)跟蹤系統(tǒng)的有效性。MTT模型的精度受比例變化、頻繁的id切換、旋轉(zhuǎn)、光照變化等因素的影響很大。圖1顯示了MTT算法的輸出。此外,多目標(biāo)跟蹤系統(tǒng)中存在背景雜波、后移、航跡初始化和終止等復(fù)雜任務(wù)。為了克服這些問題,研究人員利用深度神經(jīng)網(wǎng)絡(luò),提出了多種策略。
MTT算法的分類
根據(jù)對象的初始化方式,MOT實現(xiàn)可分為基于檢測(DBT)或無檢測跟蹤(Detection free tracking,?DFT)。然而,MTT模型是圍繞基于檢測的訓(xùn)練進行標(biāo)準化的,其中檢測(識別幀中的對象)是作為預(yù)跟蹤步驟來檢索的。由于DBT中需要一個目標(biāo)檢測器來識別目標(biāo),因此性能在很大程度上取決于檢測器的質(zhì)量,因此選擇一個檢測框架是至關(guān)重要的。
無檢測跟蹤(DFT)
檢測器的輸出通常被用作跟蹤器的輸入,跟蹤器的輸出被提供給運動預(yù)測算法,該算法預(yù)測物體在接下來的幾秒鐘內(nèi)將移動到哪里。然而,在無檢測跟蹤中,情況并非如此。基于DFT的模型要求必須在第一幀中手動初始化固定數(shù)量的對象,然后必須在隨后的幀中對這些對象進行定位。
DFT是一項困難的任務(wù),因為關(guān)于要跟蹤的對象的信息有限,而且這些信息不清楚。結(jié)果,初始邊界框僅與背景中的感興趣對象近似,并且對象的外觀可能隨著時間的推移而急劇改變。
在線跟蹤(Online tracking)
在線跟蹤算法,也稱為順序跟蹤,根據(jù)過去和現(xiàn)在的信息生成對當(dāng)前幀的預(yù)測。這種類型的算法以分步方式處理幀。在一些應(yīng)用中,例如自動駕駛和機器人導(dǎo)航,這些信息是必不可少的。
批次跟蹤(Batch tracking)
為了確定給定幀中的對象身份,批次跟蹤(離線跟蹤)技術(shù)使用前一幀的信息。它們經(jīng)常使用全局數(shù)據(jù),從而提高了跟蹤質(zhì)量;但是,由于計算和內(nèi)存的限制,并不總是能夠一次處理所有幀。
深度學(xué)習(xí)算法
大多數(shù)算法共有的主要步驟如下:
目標(biāo)檢測(Object Detection)階段:通過分析輸入幀,使用邊界框在一系列幀中定位目標(biāo)。
運動預(yù)測(Motion Prediction)階段:分析檢測以提取外觀、運動或交互特征。
親和度(Affinity)計算階段:將提取的特征用于檢測對之間的相似度/距離計算。
關(guān)聯(lián)(Association)階段:通過向?qū)?yīng)于相同目標(biāo)的檢測提供相同的ID,在關(guān)聯(lián)中利用相似性/距離度量。
檢測階段
檢測階段主要用的是目標(biāo)檢測中的一些算法。
YOLO單卷積神經(jīng)網(wǎng)絡(luò)在一次評價中直接從全圖中預(yù)測多個bounding boxes和類概率,在全圖上訓(xùn)練并直接優(yōu)化檢測性能,同時學(xué)習(xí)目標(biāo)的泛化表示。然而,YOLO對邊界框預(yù)測施加了嚴格的空間約束,限制了模型可以預(yù)測的相鄰項目的數(shù)量。成群出現(xiàn)的小物件,如鳥類,對于此模型也同樣有問題。
faster R-CNN,一個由全深度CNN組成的單一統(tǒng)一對象識別網(wǎng)絡(luò),提高了檢測的準確性和效率,同時減少了計算開銷。該模型集成了一種在區(qū)域方案微調(diào)之間交替的訓(xùn)練方法,使得統(tǒng)一的、基于深度學(xué)習(xí)的目標(biāo)識別系統(tǒng)能夠以接近實時的幀率運行,然后在保持固定目標(biāo)的同時微調(diào)目標(biāo)檢測。
在某些監(jiān)視畫面中,遮擋是十分頻繁,以至于不可能像在人類的情況下那樣檢測對象的整個形狀。
為了解決這個問題,Khan等人提出了經(jīng)過訓(xùn)練僅檢測頭部位置的時間一致性模型(temporal consistency model)。同樣,一些技術(shù)也被探索到只跟蹤頭部位置,而不是整個身體形狀。
Bewley在EL29上提出了framework SORT,以利用基于CNN的檢測的力量,在MOT前景中,它在速度和準確性方面都取得了同類最好的性能,它專注于幀到幀的預(yù)測和關(guān)聯(lián)。通過將從聚合信道特征(Aggregated Channel Features, ACF)獲得的檢測替換為Faster RCNN計算的檢測,基于卡爾曼濾波器和匈牙利算法的體系結(jié)構(gòu),它變得能夠被評為性能最好的。在某些情況下,CNN在檢測步驟中被用于構(gòu)建目標(biāo)邊界框之外的其他目的。
對于多目標(biāo)(如汽車)的跟蹤,結(jié)合魯棒檢測和二分類器的新策略,對于多車輛的魯棒和精確識別,Min提出了升級的ViBe。當(dāng)ViBe算法被用來識別汽車時,CNN用它來消除假陽性。它能有效地抑制動態(tài)噪聲,并能快速去除鬼影和物體的殘留陰影。
運動預(yù)測(Motion Prediction)階段
深度模型用于研究諸如時間和空間注意圖或時間順序之類的MOT特征時,性能可以得到改善。一些基于端到端深度學(xué)習(xí)的模型,不僅可以提取外觀描述符的特征,還可以提取運動信息的特征。
Wang等人提出了最早在MOT管道中應(yīng)用DL的方法之一。該系統(tǒng)充分利用了單目標(biāo)跟蹤器的優(yōu)點,在不影響計算能力的前提下解決了由于遮擋造成的漂移問題;為了提高提取特征,網(wǎng)絡(luò)采用了兩層堆疊的編碼器,然后利用支持向量機計算親和度。目標(biāo)的可見性圖被學(xué)習(xí),然后被用來推斷空間注意圖,該空間注意圖隨后被用來對特征進行加權(quán)。此外,可見性貼圖還可用于估計遮擋狀態(tài)。這就是所謂的時間注意過程。
最常用的基于CNN的方法可進一步分為:用于特征提取的經(jīng)典CNN和siamese CNN。
經(jīng)典CNN
Kim等人聲稱多假設(shè)跟蹤(Multiple Hypotheses Tracking, MHT)技術(shù)與現(xiàn)有的視覺跟蹤視角是兼容的。現(xiàn)代基于檢測的跟蹤技術(shù)的進步和用于物體外觀的高效特征表示的發(fā)展為MHT過程提供了新的可能性。他們通過整合一個正則化的最小二乘框架來改進MHT,該框架用于在線訓(xùn)練每個跟蹤目標(biāo)的外觀模型。
Wojke等人提出了對SORT的改進,雖然在高幀率下獲得了較好的精度和精度,但產(chǎn)生了相對較多的單位移位。Wojke等人通過整合外觀運動信息對其進行了改進,通過將關(guān)聯(lián)度量替換為卷積神經(jīng)網(wǎng)絡(luò)(CNN),克服了這個問題。卷積神經(jīng)網(wǎng)絡(luò)經(jīng)過訓(xùn)練,可以在大規(guī)模的行人重識別數(shù)據(jù)集中區(qū)分行人。與SORT相比,升級的跟蹤系統(tǒng)有效地將身份翻轉(zhuǎn)的次數(shù)從1423次減少到781次。這減少了約45%,在保持實時速度的同時實現(xiàn)了具有競爭力的性能。
Siamese CNN
Siamese CNN已經(jīng)被證明在MOT中很有用,因為跟蹤階段的特征學(xué)習(xí)的目的是確定檢測和跟蹤之間的相似性。
Leal-taxe等人提出了一種兩階段匹配檢測方法的策略,為行人跟蹤中的目標(biāo)關(guān)聯(lián)挑戰(zhàn)提供了新的視角。在這種情況下,他們將CNN的概念應(yīng)用到多人跟蹤中,并提出學(xué)習(xí)兩個檢測是否屬于同一軌跡的判斷,以避免手動設(shè)計特征進行數(shù)據(jù)關(guān)聯(lián)。模型的學(xué)習(xí)框架分為兩個階段。
CNN在Siamese?結(jié)構(gòu)中進行預(yù)訓(xùn)練,以測量兩個大小相等的圖像區(qū)域的相似性,然后將CNN與收集到的特征進行合并以產(chǎn)生預(yù)測。通過將跟蹤問題描述為線性規(guī)劃,并將深度特征和運動信息與梯度增強方法相結(jié)合,它們很好地解決了跟蹤問題。
親和度(Affinity)計算階段
雖然一些實現(xiàn)使用深度學(xué)習(xí)模型來立即生成親和度分數(shù),而不需要特征之間的顯式距離度量,但仍然有其他方法通過對CNN獲得的特征應(yīng)用一些距離度量來計算跟蹤和檢測之間的親和度。
米蘭等人解決了神經(jīng)網(wǎng)絡(luò)環(huán)境中數(shù)據(jù)關(guān)聯(lián)和軌跡估計的難題。在線MOT任務(wù)中跟蹤目標(biāo)的狀態(tài)估計采用由觀測預(yù)測和更新組成的遞歸貝葉斯濾波器,該模型擴展了RNN對該過程進行建模,將目標(biāo)狀態(tài)、現(xiàn)有觀測及其對應(yīng)的匹配矩陣以及存在前景作為輸入輸入到網(wǎng)絡(luò)中。該模型輸出目標(biāo)的預(yù)測狀態(tài)和更新結(jié)果,以及判斷目標(biāo)是否終止的存在概率,取得了較好的跟蹤效果。
Chen等人建議計算采樣粒子和跟蹤目標(biāo)之間的親和力,而不是計算目標(biāo)和探測器之間的親和力。取而代之的是,使用與被跟蹤對象不一致的檢測來創(chuàng)建新的軌跡并恢復(fù)丟失的對象。盡管它是一個在線監(jiān)測算法,但在發(fā)表時,它能夠在MOT15上獲得最好的結(jié)果,既使用公共檢測,也使用私人檢測。
跟蹤/關(guān)聯(lián)階段
在一些MTT模型中已經(jīng)使用深度學(xué)習(xí)來改進關(guān)聯(lián)步驟。
Ma等人在擴大Siamese跟蹤器網(wǎng)絡(luò)時,采用了雙向GRU來決定在何處終止跟蹤器。對于每一次檢測,網(wǎng)絡(luò)提取軌跡特征并將其發(fā)送到雙向GRU網(wǎng)絡(luò),雙向GRU網(wǎng)絡(luò)的輸出在歐幾里德空間中短暫匯集以提供軌跡的整體特征。在跟蹤過程中,根據(jù)雙向GRU輸出之間的局部距離,生成子軌,然后將其拆分成小的子軌;最后,考慮到時間池全局方面的相似性,將這些子軌重新連接到長軌跡。在MOT16數(shù)據(jù)集上,此方法獲得的結(jié)果與最新SOTA水平相當(dāng)。
勒恩等人提出了一種使用多個深層RL(強化學(xué)習(xí)) 智能體完成關(guān)聯(lián)任務(wù)的協(xié)同實現(xiàn)方案。預(yù)測網(wǎng)絡(luò)和決策網(wǎng)絡(luò)是該模型的兩個關(guān)鍵組成部分。利用最新的跟蹤軌跡,CNN被用作預(yù)測網(wǎng)絡(luò),并被訓(xùn)練以預(yù)測新幀中的目標(biāo)運動。
其它方法
除了基于以上四個步驟的模型,還存在一些其它的方法。
Jiang等人利用Deep RL代理完成了bounding boxes回歸,提高了跟蹤算法的效率;采用VGG-16CNN進行外觀提取,提取的特征保存并使用目標(biāo)最近10次運動的歷史記錄,然后集成網(wǎng)絡(luò)預(yù)測bounding boxes運動、縮放以及終止動作等多種備選結(jié)果之一。在MOT15數(shù)據(jù)集上,在幾種最先進的MOT算法上使用這種bounding boxes回歸方法,提高了2到7個絕對MoTA點,使其在公共檢測方法中名列前茅。
Xiang等人部署MetricNet進行行人跟蹤,將親和力模型與貝葉斯濾波器得到的軌跡估計相結(jié)合。利用VGG-16CNN對目標(biāo)進行再識別訓(xùn)練,提取特征并進行bounding boxes回歸,運動模型分為兩部分,一部分以軌跡坐標(biāo)作為輸入,另一部分結(jié)合檢測框進行貝葉斯濾波,并在MOT16和MOT15上輸出目標(biāo)的更新位置,該算法在在線方法中分別獲得了最好的和次佳的得分。
無模型單目標(biāo)跟蹤(model free single object tacking) SOT算法的最新進展極大地推動了SOT在多目標(biāo)跟蹤(MOT)中的應(yīng)用,以提高恢復(fù)能力并減少對外部檢測器的依賴。另一方面,SOT算法通常被設(shè)計成將目標(biāo)與其周圍環(huán)境區(qū)分開來,當(dāng)目標(biāo)在空間上與類似的偽像混合時,它們經(jīng)常會遇到問題,就像在MOT中看到的那樣。
Chu等人提出了一種模型來解決魯棒性和消除對外部檢測器的依賴問題。他們在算法中使用了三種不同的CNN實現(xiàn)了一個模型。集成PafNet以區(qū)分背景和跟蹤對象。該部分對跟蹤目標(biāo)進行區(qū)分,另一個集成的CNN是卷積層,它決定了跟蹤模型是否需要刷新。使用支持向量機分類器和匈牙利技術(shù),使用非關(guān)聯(lián)檢測來從目標(biāo)遮擋中恢復(fù)。該算法在MOT15和MOT16數(shù)據(jù)集上進行了測試,第一種方法產(chǎn)生了最好的總體結(jié)果,第二種方法產(chǎn)生了在線方法中最好的結(jié)果。
評估指標(biāo)
最相關(guān)的是Classical metrics 和 CLEAR MOT metrics。
Classical metrics指出了算法可能遇到的缺陷,如多目標(biāo)跟蹤(MT)軌跡、多丟失(ML)軌跡、ID切換等。
CLEAR MOT metrics有MOTA(多對象跟蹤精度)和MOTP(多對象跟蹤精度)。MOTA將假陽性、假陰性和失配率合并為單個值,從而產(chǎn)生總體良好的跟蹤性能。盡管有一些缺陷和抱怨,但這是迄今為止使用最廣泛的評估方法。MOTP描述了使用邊界框重疊和/或距離測量來跟蹤對象的精確度。
基準數(shù)據(jù)集
基準數(shù)據(jù)集包括 MOTChallenger、KITTI、UADETRAC。
MOTChallest數(shù)據(jù)集是目前可用的最大、最完整的行人跟蹤數(shù)據(jù)集,為訓(xùn)練深度模型提供了更多的數(shù)據(jù)。MOT15是最初的MOT挑戰(zhàn)數(shù)據(jù)集,它的特點是視頻具有一系列屬性,模型需要更好地推廣這些屬性才能獲得好的結(jié)果。MOT16和MOT19是其他修改版本。
基準結(jié)果
如下為Gioele等人列出在MOT ChallengeMOT15數(shù)據(jù)集和MOT16數(shù)據(jù)集上測試的公開結(jié)果,這些數(shù)據(jù)集記錄自相應(yīng)的出版物,以便對本工作中提到的方法之間的結(jié)果進行清晰的比較。
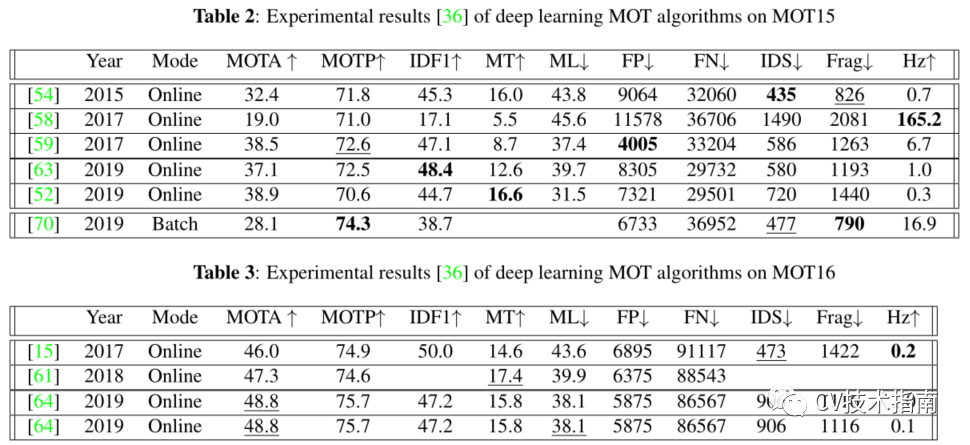
由于檢測質(zhì)量對性能有影響,因此將研究結(jié)果分為基于公共檢測的模型和基于私有檢測的模型。這些方法分為兩類:在線和離線。
發(fā)布的參考文檔的年份、其操作模式、MOTA、MOTP、IDF1、主要跟蹤(MT)和主要丟失(ML)指標(biāo),以百分比表示;假陽性(FP)、假陰性(FN)、ID開關(guān)(IDS)和碎片(Frag)的絕對數(shù);以每秒幀數(shù)(Hz)表示的算法速度。
對于每個度量,向上的箭頭(↑)表示更高的分數(shù),而向下的箭頭(↓)表示相反的分數(shù)。在運行相同模式(批處理/在線)的模型中強調(diào)最佳性能,并且每個統(tǒng)計數(shù)據(jù)都以粗體突出顯示。我們只在表2和表3中列出了從本綜述中訪問的模型獲得的結(jié)果。
在現(xiàn)實中,使用深度學(xué)習(xí)和具有在線處理模式的模型產(chǎn)生了最大的結(jié)果。然而,這可能是更加重視建立在線方法的結(jié)果,這在MOT深度學(xué)習(xí)研究社區(qū)中變得越來越流行。大量的碎片化是在線方法中經(jīng)常出現(xiàn)的問題,這在MOTA得分中沒有反映出來。當(dāng)遮擋或探測丟失時,在線算法不會向前看,不會重新識別丟失的目標(biāo),也不會插入視頻中丟失的軌跡片段。
結(jié)論
本文對利用深度學(xué)習(xí)解決MTT問題的方法進行了簡要的探索。這項研究討論了使用深度學(xué)習(xí)來解決MTT問題的四個步驟中的每一個步驟的解決方案,使SOTA的MOT技術(shù)的總數(shù)達到n。
對MOT算法的評估,包括評估措施和來自可訪問數(shù)據(jù)集的基準結(jié)果,進行了簡要的討論。單對象跟蹤器最近受益于將深度模型引入全局圖優(yōu)化算法,從而產(chǎn)生了高性能的在線跟蹤器;另一方面,批處理技術(shù)受益于將深度模型引入全局圖優(yōu)化算法。
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有美顏、三維視覺、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺回復(fù):c++,即可下載。歷經(jīng)十年考驗,最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR,即可下載1467篇CVPR?2020論文 和 CVPR 2021 最新論文
