
SQL重要知識(shí)點(diǎn)梳理!清晰!
數(shù)據(jù)庫(kù)的話我只對(duì)MySQL有些熟悉,因此我們以MySQL為主進(jìn)行知識(shí)點(diǎn)的整理。
MySQL知識(shí)點(diǎn)學(xué)習(xí)的開源教程:
https://github.com/datawhalechina/team-learning-sql/
由于作者水平的限制和可能的整理疏漏,有錯(cuò)誤和不足的地方煩請(qǐng)指出。
MySQL數(shù)據(jù)庫(kù)-基礎(chǔ)知識(shí)
1.說(shuō)說(shuō)主鍵、外鍵、超鍵、候選鍵的差別并舉例
超鍵(super key): 在關(guān)系中能唯一標(biāo)識(shí)元組的屬性集稱為關(guān)系模式的超鍵。 候選鍵(candidate key): 不含有多余屬性的超鍵稱為候選鍵。也就是在候選鍵中,若再刪除屬性,就不是鍵了! 主鍵(primary key): 用戶選作元組標(biāo)識(shí)的一個(gè)候選鍵程序主鍵。 外鍵(foreign key):如果關(guān)系模式R中屬性K是其它模式的主鍵,那么k在模式R中稱為外鍵。
舉個(gè)例子,對(duì)于 學(xué)生信息(學(xué)號(hào) 身份證號(hào) 性別 年齡 身高 體重 宿舍號(hào))和 宿舍信息(宿舍號(hào) 樓號(hào)):
超鍵:只要含有“學(xué)號(hào)”或者“身份證號(hào)”兩個(gè)屬性的集合就叫超鍵,例如R1(學(xué)號(hào) 性別)、R2(身份證號(hào) 身高)、R3(學(xué)號(hào) 身份證號(hào))等等都可以稱為超鍵! 候選鍵:不含有多余的屬性的超鍵,比如(學(xué)號(hào))、(身份證號(hào))都是候選鍵,又比如R1中學(xué)號(hào)這一個(gè)屬性就可以唯一標(biāo)識(shí)元組了,而有沒(méi)有性別這一屬性對(duì)是否唯一標(biāo)識(shí)元組沒(méi)有任何的影響! 主鍵:就是用戶從很多候選鍵選出來(lái)的一個(gè)鍵就是主鍵,比如你要求學(xué)號(hào)是主鍵,那么身份證號(hào)就不可以是主鍵了! 外鍵:宿舍號(hào)就是學(xué)生信息表的外鍵。
2.為什么一般用自增列作為主鍵?
如果表使用自增主鍵,那么每次插入新的記錄,記錄就會(huì)順序添加到當(dāng)前索引節(jié)點(diǎn)的后續(xù)位置,當(dāng)一頁(yè)寫滿,就會(huì)自動(dòng)開辟一個(gè)新的頁(yè)。 如果使用非自增主鍵(如果身份證號(hào)或?qū)W號(hào)等),由于每次插入主鍵的值近似于隨機(jī),因此每次新記錄都要被插到現(xiàn)有索引頁(yè)的中間某個(gè)位置,此時(shí)MySQL不得不為了將新記錄插到合適位置而移動(dòng)數(shù)據(jù),這增加了很多開銷,同時(shí)會(huì)增加大量的碎片。
3.觸發(fā)器的作用?
安全性,可以基于數(shù)據(jù)庫(kù)的值使用戶具有操作數(shù)據(jù)庫(kù)的某種權(quán)利。 審計(jì),可以跟蹤用戶對(duì)數(shù)據(jù)庫(kù)的操作。 實(shí)現(xiàn)復(fù)雜的非標(biāo)準(zhǔn)的數(shù)據(jù)庫(kù)相關(guān)完整性規(guī)則,觸發(fā)器可以對(duì)數(shù)據(jù)庫(kù)中相關(guān)的表進(jìn)行連環(huán)更新。 觸發(fā)器能夠拒絕或回退那些破壞相關(guān)完整性的變化,取消試圖進(jìn)行數(shù)據(jù)更新的事務(wù)。當(dāng)插入一個(gè)與其主鍵不匹配的外部鍵時(shí),這種觸發(fā)器會(huì)起作用。
4.什么是存儲(chǔ)過(guò)程??jī)?yōu)缺點(diǎn)是什么?與函數(shù)的區(qū)別是什么?
存儲(chǔ)過(guò)程是一個(gè)預(yù)編譯的SQL語(yǔ)句,優(yōu)點(diǎn)是允許模塊化的設(shè)計(jì),就是說(shuō)只需創(chuàng)建一次,以后在該程序中就可以調(diào)用多次。
優(yōu)點(diǎn):
存儲(chǔ)過(guò)程是預(yù)編譯過(guò)的,執(zhí)行效率高。 存儲(chǔ)過(guò)程的代碼直接存放于數(shù)據(jù)庫(kù)中,通過(guò)存儲(chǔ)過(guò)程名直接調(diào)用,減少網(wǎng)絡(luò)通訊。 安全性高,執(zhí)行存儲(chǔ)過(guò)程需要有一定權(quán)限的用戶。 存儲(chǔ)過(guò)程可以重復(fù)使用,可減少工作量冗余。
缺點(diǎn):移植性差
與函數(shù)的區(qū)別:
存儲(chǔ)過(guò)程用戶在數(shù)據(jù)庫(kù)中完成特定操作或者任務(wù)(如插入,刪除等),函數(shù)用于返回特定的數(shù)據(jù)。 存儲(chǔ)過(guò)程聲明用procedure,函數(shù)用function。 存儲(chǔ)過(guò)程不需要返回類型,函數(shù)必須要返回類型。 存儲(chǔ)過(guò)程可作為獨(dú)立的pl-sql執(zhí)行,函數(shù)不能作為獨(dú)立的plsql執(zhí)行,必須作為表達(dá)式的一部分。 存儲(chǔ)過(guò)程只能通過(guò)out和in/out來(lái)返回值,函數(shù)除了可以使用out,in/out以外,還可以使用return返回值。 sql語(yǔ)句(DML或SELECT)中不可用調(diào)用存儲(chǔ)過(guò)程,而函數(shù)可以。
5.什么是視圖,優(yōu)缺點(diǎn)是什么?
視圖:是一種虛擬的表,具有和物理表相同的功能。可以對(duì)視圖進(jìn)行增,改,查,操作,試圖通常是有一個(gè)表或者多個(gè)表的行或列的子集。對(duì)視圖的修改會(huì)影響基本表。
優(yōu)點(diǎn):
對(duì)數(shù)據(jù)庫(kù)的訪問(wèn),因?yàn)橐晥D可以有選擇性的選取數(shù)據(jù)庫(kù)里的一部分。 用戶通過(guò)簡(jiǎn)單的查詢可以從復(fù)雜查詢中得到結(jié)果。 維護(hù)數(shù)據(jù)的獨(dú)立性,試圖可從多個(gè)表檢索數(shù)據(jù)。 對(duì)于相同的數(shù)據(jù)可產(chǎn)生不同的視圖。
缺點(diǎn):
查詢視圖時(shí),必須把視圖的查詢轉(zhuǎn)化成對(duì)基本表的查詢,如果這個(gè)視圖是由一個(gè)復(fù)雜的多表查詢所定義,那么,那么就無(wú)法更改數(shù)據(jù)。
6.說(shuō)說(shuō)drop、truncate、 delete區(qū)別
drop直接刪掉表。 truncate刪除表中數(shù)據(jù),再插入時(shí)自增長(zhǎng)id又從1開始。 delete刪除表中數(shù)據(jù),可以加where字句。
7.什么是臨時(shí)表,臨時(shí)表什么時(shí)候刪除?
臨時(shí)表可以手動(dòng)刪除:
DROP TEMPORARY TABLE IF TEXITS temp_tb
臨時(shí)表只在當(dāng)前連接可見,當(dāng)關(guān)閉連接時(shí),MySQL會(huì)自動(dòng)刪除表并釋放所有空間。因此在不同的連接中可以創(chuàng)建同名的臨時(shí)表,并且操作屬于本連接的臨時(shí)表。創(chuàng)建臨時(shí)表的語(yǔ)法與創(chuàng)建表語(yǔ)法類似,不同之處是增加關(guān)鍵字TEMPORARY:
CREATE TEMPORARY TABLE tmp_table (
NAME VARCHAR (10) NOT NULL,
time date NOT NULL
);
select * from tmp_table;
8.關(guān)系型數(shù)據(jù)庫(kù)和非關(guān)系型數(shù)據(jù)庫(kù)的優(yōu)劣?
非關(guān)系型數(shù)據(jù)庫(kù)以redis為例,NOSQL是基于鍵值對(duì)的,而且不需要經(jīng)過(guò)SQL層的解析,所以性能高,查詢速度快。同時(shí)由于是鍵值對(duì),數(shù)據(jù)之間沒(méi)有耦合,容易水平擴(kuò)展。
關(guān)系數(shù)據(jù)庫(kù):使用SQL語(yǔ)句方便在多個(gè)表之間做復(fù)雜查詢,同時(shí)有較好的事務(wù)支持,支持對(duì)安全性有一定要求的數(shù)據(jù)訪問(wèn)。
9.什么是數(shù)據(jù)庫(kù)范式?
第一范式:(確保每列保持原子性)所有字段值都是不可分解的原子值。 第二范式:(確保表中的每列都和主鍵相關(guān))在一個(gè)數(shù)據(jù)庫(kù)表中,一個(gè)表中只能保存一種數(shù)據(jù),不可以把多種數(shù)據(jù)保存在同一張數(shù)據(jù)庫(kù)表中,數(shù)據(jù)表里的非主屬性都要和這個(gè)數(shù)據(jù)表的候選鍵有完全依賴關(guān)系。 第三范式:(確保每列都和主鍵列直接相關(guān),而不是間接相關(guān)) 數(shù)據(jù)表中的每一列數(shù)據(jù)都和主鍵直接相關(guān),而不能間接相關(guān)。 第四范式:要求把同一表內(nèi)的多對(duì)多關(guān)系刪除。 第五范式:從最終結(jié)構(gòu)重新建立原始結(jié)構(gòu)。
需要注意的是,遵循數(shù)據(jù)庫(kù)范式會(huì)一定程度影響數(shù)據(jù)庫(kù)的查詢效率,因此會(huì)存在反范式的優(yōu)化。
10.什么是 內(nèi)連接、外連接、交叉連接、笛卡爾積等?
內(nèi)連接: 只連接匹配的行。 左外連接: 包含左邊表的全部行(不管右邊的表中是否存在與它們匹配的行),以及右邊表中全部匹配的行。 右外連接: 包含右邊表的全部行(不管左邊的表中是否存在與它們匹配的行),以及左邊表中全部匹配的行。 全外連接: 包含左、右兩個(gè)表的全部行,不管另外一邊的表中是否存在與它們匹配的行。 交叉連接: 生成笛卡爾積-它不使用任何匹配或者選取條件,而是直接將一個(gè)數(shù)據(jù)源中的每個(gè)行與另一個(gè)數(shù)據(jù)源的每個(gè)行都一一匹配。
11.varchar和char的區(qū)別?
char的長(zhǎng)度是不可變的,而varchar的長(zhǎng)度是可變的。 char的存取速度還是要比varchar要快得多,因?yàn)槠溟L(zhǎng)度固定,方便程序的存儲(chǔ)與查找。 char的存儲(chǔ)方式是:對(duì)英文字符(ASCII)占用1個(gè)字節(jié),對(duì)一個(gè)漢字占用兩個(gè)字節(jié)。varchar的存儲(chǔ)方式是:對(duì)每個(gè)英文字符占用2個(gè)字節(jié),漢字也占用2個(gè)字節(jié)。
12.說(shuō)說(shuō)like % - 的區(qū)別
%百分號(hào)通配符:表示任何字符出現(xiàn)任意次數(shù)(可以是0次)。 下劃線通配符:表示只能匹配單個(gè)字符,不能多也不能少,就是一個(gè)字符。 like操作符: LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配進(jìn)行比較。
13.索引、索引的作用和索引的優(yōu)缺點(diǎn)是什么,什么樣的字段適合建索引?
數(shù)據(jù)庫(kù)索引,是數(shù)據(jù)庫(kù)管理系統(tǒng)中一個(gè)排序的數(shù)據(jù)結(jié)構(gòu),索引的實(shí)現(xiàn)通常使用B樹及其變種B+樹。在數(shù)據(jù)之外,數(shù)據(jù)庫(kù)系統(tǒng)還維護(hù)著滿足特定查找算法的數(shù)據(jù)結(jié)構(gòu),這些數(shù)據(jù)結(jié)構(gòu)以某種方式引用(指向)數(shù)據(jù),這樣就可以在這些數(shù)據(jù)結(jié)構(gòu)上實(shí)現(xiàn)高級(jí)查找算法。這種數(shù)據(jù)結(jié)構(gòu),就是索引。
索引的作用:協(xié)助快速查詢、更新數(shù)據(jù)庫(kù)表中數(shù)據(jù)。
索引的優(yōu)點(diǎn):
索引可以保證數(shù)據(jù)每一行的唯一性 加快數(shù)據(jù)的檢索速度
缺點(diǎn):
創(chuàng)建和維護(hù)索引需要時(shí)間 索引需要占用物理空間,增加空間成本 對(duì)數(shù)據(jù)進(jìn)行增、刪、改的時(shí)候需要?jiǎng)討B(tài)維護(hù)
唯一的,不為空的,經(jīng)常被查詢的字段適合建立索引
14.B+樹的索引和Hash索引的區(qū)別?
hash索引是鍵值對(duì)的索引,檢索效率非常高;B+樹索引需要從根節(jié)點(diǎn)到枝節(jié)點(diǎn)索引,最后才能訪問(wèn)到數(shù)據(jù)。
為什么不都用Hash索引而使用B+樹索引?
Hash索引僅僅能滿足"=","IN"和""查詢,不能使用范圍查詢,hash是索引也不能用來(lái)做排序操作,hash的索引不能利用部分索引鍵查詢。
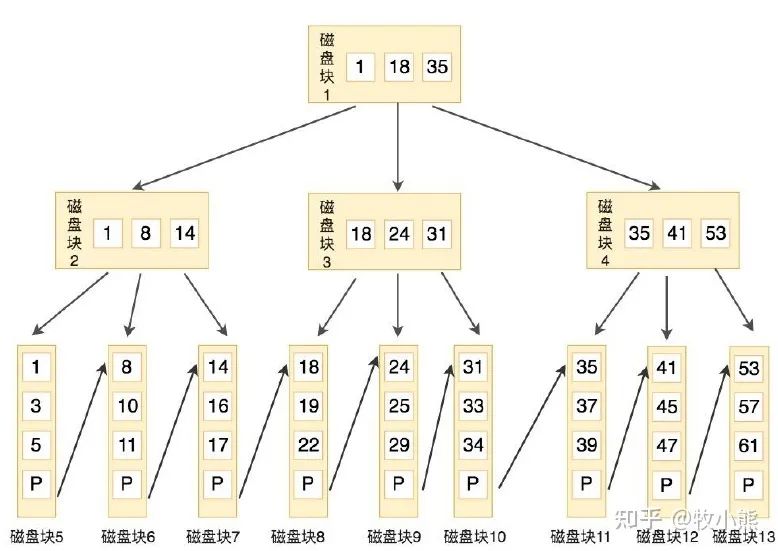
15.B樹和B+樹的區(qū)別,為什么MySQL會(huì)用B+樹?
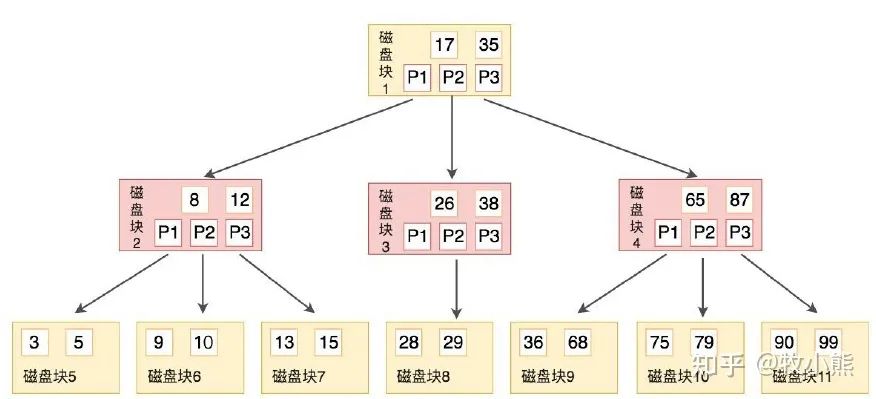
B樹,每個(gè)節(jié)點(diǎn)都存儲(chǔ)key和data,所有節(jié)點(diǎn)組成這棵樹,并且葉子節(jié)點(diǎn)指針為nul,葉子結(jié)點(diǎn)不包含任何關(guān)鍵字信息。
B+樹,所有的葉子結(jié)點(diǎn)中包含了全部關(guān)鍵字的信息,及指向含有這些關(guān)鍵字記錄的指針,且葉子結(jié)點(diǎn)本身依關(guān)鍵字的大小自小而大的順序鏈接,所有的非終端結(jié)點(diǎn)可以看成是索引部分,結(jié)點(diǎn)中僅含有其子樹根結(jié)點(diǎn)中最大(或最小)關(guān)鍵字。
為什么MySQL用B+樹呢?
B+ 樹查詢效率更穩(wěn)定(因?yàn)橐驗(yàn)锽+ 樹每次只有訪問(wèn)到葉子節(jié)點(diǎn)才能找到對(duì)應(yīng)的數(shù)據(jù) 而在 B 樹中 非葉子節(jié)點(diǎn)也會(huì)存儲(chǔ)數(shù)據(jù)) B+ 樹的查詢效率更高 (因?yàn)橥ǔ+ 樹比 B 樹更矮胖 階數(shù)更大 深度更低 查詢所需要的磁盤 I/O 也會(huì)更少 。同樣的磁盤頁(yè)大小 B+ 樹可以存儲(chǔ)更多的節(jié)點(diǎn)關(guān)鍵字) 對(duì)索引進(jìn)行范圍查詢時(shí) B+ 樹效率也更高(因?yàn)樗嘘P(guān)鍵字都出現(xiàn)在B+ 樹的葉子節(jié)點(diǎn)中 并通過(guò)有序鏈表進(jìn)行了鏈接 。而在 B 樹中則需要通過(guò)中序遍歷才能完成范圍查找 效率要低很多)
關(guān)于B+樹的索引可以參考五分鐘學(xué)算法的講解:【面試現(xiàn)場(chǎng)】為什么MySQL數(shù)據(jù)庫(kù)要用B+樹存儲(chǔ)索引?
MySQL數(shù)據(jù)庫(kù)-專業(yè)知識(shí)
16.Mysql中有哪幾種鎖?
行級(jí)鎖:鎖定力度小,發(fā)生鎖沖突概率低,實(shí)現(xiàn)并發(fā)度高,開銷大,加鎖慢,并發(fā)度高。 頁(yè)級(jí)鎖:加鎖時(shí)間比行鎖長(zhǎng),頁(yè)級(jí)鎖開銷介于表鎖和行鎖之間,會(huì)出現(xiàn)死鎖,并發(fā)度一般。 表級(jí)鎖:開銷小,加鎖快。
17.Mysql中默認(rèn)事務(wù)隔離級(jí)別是?
讀未提交(RU): 一個(gè)事務(wù)還沒(méi)提交時(shí), 它做的變更就能被別的事務(wù)看到。 讀提交(RC): 一個(gè)事務(wù)提交之后, 它做的變更才會(huì)被其他事務(wù)看到。 可重復(fù)讀(RR): 一個(gè)事務(wù)執(zhí)行過(guò)程中看到的數(shù)據(jù), 總是跟這個(gè)事務(wù)在啟動(dòng)時(shí)看到的數(shù)據(jù)是一致的。當(dāng)然在可重復(fù)讀隔離級(jí)別下, 未提交變更對(duì)其他事務(wù)也是不可見的。 串行化(S): 對(duì)于同一行記錄, 讀寫都會(huì)加鎖. 當(dāng)出現(xiàn)讀寫鎖沖突的時(shí)候, 后訪問(wèn)的事務(wù)必須等前一個(gè)事務(wù)執(zhí)行完成才能繼續(xù)執(zhí)行。
18.Mysql數(shù)據(jù)庫(kù)表類型有哪些?
MyISAM、InnoDB、HEAP、BOB,ARCHIVE,CSV等。
MyISAM:成熟、穩(wěn)定、易于管理,快速讀取。一些功能不支持(事務(wù)等),表級(jí)鎖。
InnoDB:支持事務(wù)、外鍵等特性、數(shù)據(jù)行鎖定。空間占用大,不支持全文索引等。
19.簡(jiǎn)述mysql的MVCC機(jī)制
MVCC是一種多版本并發(fā)控制機(jī)制,是MySQL的InnoDB存儲(chǔ)引擎實(shí)現(xiàn)隔離級(jí)別的一種具體方式,用于實(shí)現(xiàn)提交讀和可重復(fù)讀這兩種隔離級(jí)別。
MVCC實(shí)現(xiàn)原理。通過(guò)保存數(shù)據(jù)在某個(gè)時(shí)間點(diǎn)的快照來(lái)實(shí)現(xiàn)該機(jī)制,其在每行記錄后面保存兩個(gè)隱藏的列,分別保存這個(gè)行的創(chuàng)建版本號(hào)和刪除版本號(hào),然后Innodb的MVCC使用到的快照存儲(chǔ)在Undo日志中,該日志通過(guò)回滾指針把一個(gè)數(shù)據(jù)行所有快照連接起來(lái)。
20.簡(jiǎn)述MySQL 兩種常見存儲(chǔ)引擎:MyISAM與InnoDB
目前MySQL默認(rèn)的存儲(chǔ)引擎是InnoDB。
現(xiàn)在大多數(shù)時(shí)候我們使用的都是InnoDB,但是在某些情況下使用MyISAM更好,比如:MyISAM更適合讀密集的表,而InnoDB更適合寫密集的的表。在數(shù)據(jù)庫(kù)做主從分離的情況下,經(jīng)常選擇MyISAM作為主庫(kù)的存儲(chǔ)引擎。
二者的常見對(duì)比
count運(yùn)算上的區(qū)別:因?yàn)镸yISAM緩存有表meta-data(行數(shù)等),因此在做COUNT(*)時(shí)對(duì)于一個(gè)結(jié)構(gòu)很好的查詢是不需要消耗多少資源的。而對(duì)于InnoDB來(lái)說(shuō),則沒(méi)有這種緩存。 是否支持事務(wù)和崩潰后的安全恢復(fù):MyISAM 強(qiáng)調(diào)的是性能,每次查詢具有原子性,其執(zhí)行數(shù)度比InnoDB類型更快,但是不提供事務(wù)支持。但是InnoDB 提供事務(wù)支持事務(wù),外部鍵等高級(jí)數(shù)據(jù)庫(kù)功能。具有事務(wù)(commit)、回滾(rollback)和崩潰修復(fù)能力(crash recovery capabilities)的事務(wù)安全(transaction-safe (ACID compliant))型表。 是否支持外鍵:MyISAM不支持,而InnoDB支持。