
丹俠帝貌!英偉達(dá)用全新GPU引爆了AI
就像為追求畫(huà)質(zhì)極致體驗(yàn)而不斷升級(jí)自己顯卡的游戲玩家一樣,AI方向的從業(yè)者和愛(ài)好者也有屬于自己的狂歡節(jié)。
自從生成式人工智能席卷全球后,各家公司的模型比拼儼然變成了算力和數(shù)據(jù)競(jìng)爭(zhēng)。而浪潮中心的英偉達(dá)則備受矚目,就像這次GTC2024大會(huì)的演講主題一樣:“見(jiàn)證AI的變革時(shí)刻”。

看完這次會(huì)議,最驚訝的還是黃老板帶來(lái)的新GPU系列,只能說(shuō)是貧窮限制了自己的想象力
BlackWell——讓大模型坐上火箭
在一年前英偉達(dá)推出H100時(shí),其股價(jià)迎來(lái)了飆升,并迅速超過(guò)了亞馬遜。就在一年后的今天,英偉達(dá)再次放出大招——全新GPU系列BlackWell

從黃仁勛的描述來(lái)看,BlackWell GPU單個(gè)晶體管數(shù)量就達(dá)到2080億。對(duì)比H100的800億和A100的540億,有了巨大的提升,直接增加了5倍的AI表現(xiàn)和4倍的芯片內(nèi)存
展示中,英偉達(dá)還提供了兩種GPU形式,一種為B200,顧名思義就是將兩張B100合二為一,算力達(dá)到驚人的20petaFLOPS。

這里petaFLOPS指計(jì)算機(jī)每秒進(jìn)行一千萬(wàn)億次浮點(diǎn)運(yùn)算( ),相當(dāng)于現(xiàn)在一張B200就是20臺(tái)2008年的超級(jí)計(jì)算機(jī)Roadrunner。
更具創(chuàng)意性的是,英偉達(dá)將GB200與一張Grace CPU結(jié)合,構(gòu)成了一張“超級(jí)芯片”,算力達(dá)到40petaFLOPS,能加速大模型推理30倍,并且比H100降低25倍的能源開(kāi)銷。

可以說(shuō),GB200不僅降本,還增效,英偉達(dá)這次真的是想把AI往AGI上推動(dòng)了。
直播到這里,黃仁勛展示GB200時(shí)幾乎每放幾張圖,臺(tái)下都會(huì)響起掌聲,GPU不僅牽動(dòng)著臺(tái)下硅谷人的內(nèi)心,同樣也讓我期待:
既然Scaling Law(模型參數(shù)量越大越可能出現(xiàn)模型涌現(xiàn))被不斷實(shí)踐證明有效,那么在底層算力不斷跟進(jìn)的背景下,是否會(huì)有第二次涌現(xiàn)的機(jī)會(huì),即AGI的實(shí)現(xiàn)。
觀察英偉達(dá)產(chǎn)品算力發(fā)展時(shí)間線,幾乎一年算力就有近五倍的增長(zhǎng),如我們熟悉的3060等GPU是4年前的Ampere架構(gòu),目前主流的在線深度學(xué)習(xí)平臺(tái)Autodl、阿里云等提供的V100、A100等算力則是兩年前的Hopper架構(gòu),而現(xiàn)在的BlackWell架構(gòu)算力則是上一代近5倍。
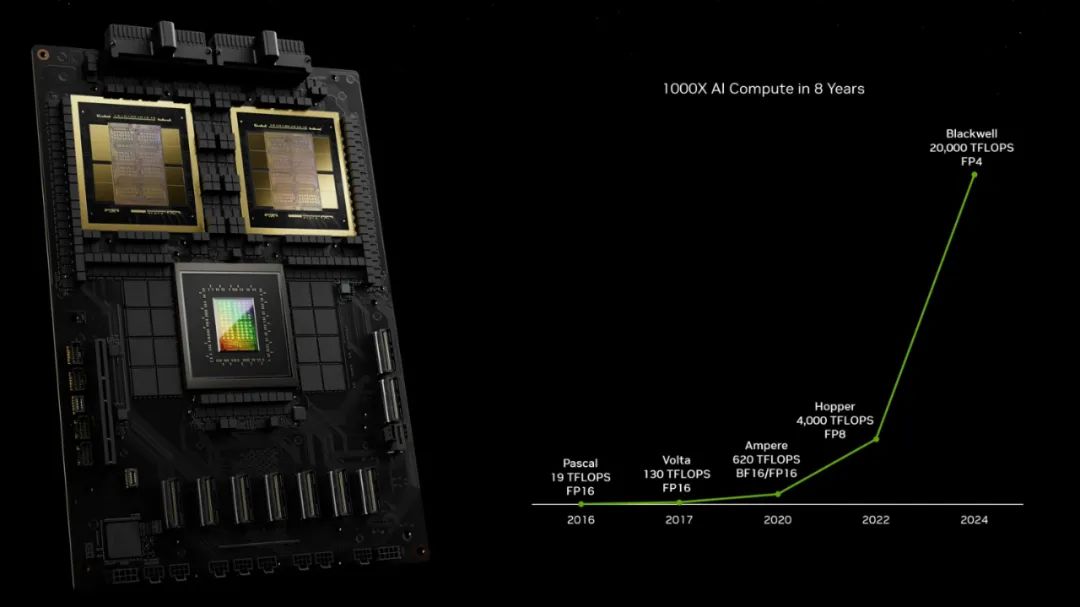
驚喜之余,也有些擔(dān)憂。就算是上一代的A100、H100也仍然在美國(guó)對(duì)華禁令之中,而現(xiàn)在BlackWell出來(lái),中美算力差距可能還會(huì)進(jìn)一步加大,
1/4能耗訓(xùn)練GPT4參數(shù)量模型
當(dāng)然,對(duì)不熟悉GPU計(jì)算的AI愛(ài)好者而言,最直接的展示算力方法當(dāng)然是拿經(jīng)典的GPT4來(lái)做例子了。
按目前透露的GPT4是8個(gè)2200億的MOE模型來(lái)看,總體有近1.8萬(wàn)億參數(shù),相當(dāng)于5.6個(gè)Grok1、10個(gè)GPT3.5、25.7個(gè)通義千問(wèn)1.5-70B。
在90天內(nèi)訓(xùn)練一個(gè)GPT4,Hopper系列模型需要8000個(gè)GPU的集群,消耗15MW的能量。而2000塊GB200,能在同樣的天數(shù)內(nèi),以1/4的能量消耗完成訓(xùn)練!
最后只能說(shuō),黃老板的確眼界著實(shí),不僅在GPU深耕多年并在生成式AI時(shí)代成為算力第一人,也同時(shí)在其他領(lǐng)域不斷布局,如會(huì)議中提到的生物領(lǐng)域BioNemo、氣象領(lǐng)域的CoreDiv以及機(jī)器人相關(guān)技術(shù)。
最后,以黃老板的一句幽默來(lái)結(jié)束吧
這個(gè),我不知道,100億美元吧。第二個(gè)是5億,之后就便宜了
