
理解關(guān)聯(lián)規(guī)則算法
一、基礎(chǔ)概念
1、算法概述
2、應(yīng)用場景
3、幾個概念

01)支持度


02)置信度



03)提升度
04)頻繁項(xiàng)集
如果一個項(xiàng)集是 非頻繁項(xiàng)集,那么它的所有超集也是非頻繁項(xiàng)集
{Battery} is infrequent → {Milk, Battery} is infrequent
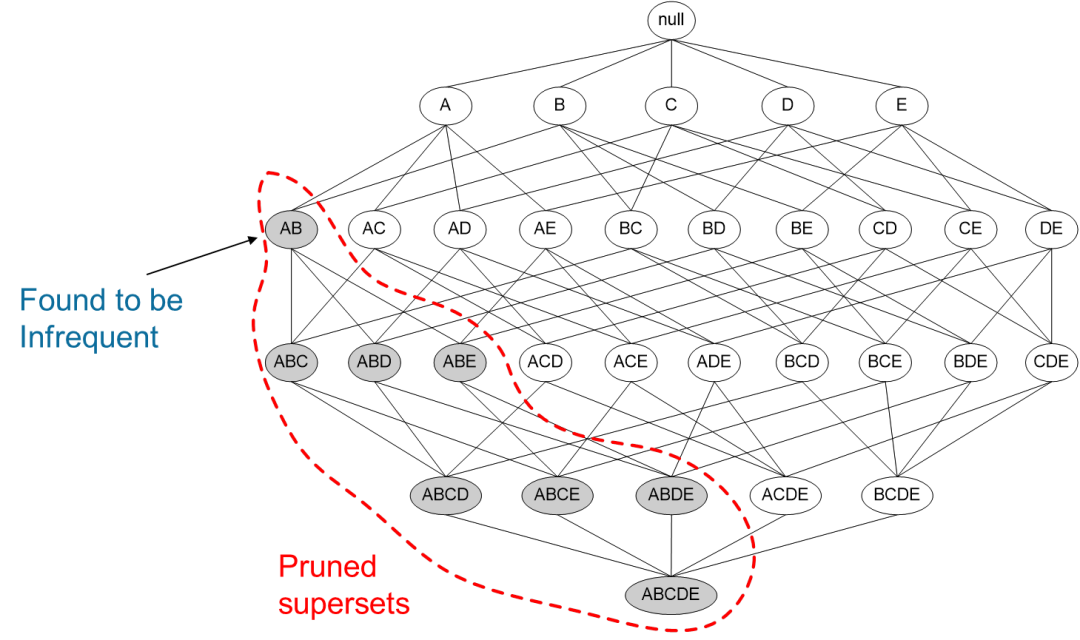
如圖所示,我們發(fā)現(xiàn){A,B}這個項(xiàng)集是非頻繁的,那么{A,B}這個項(xiàng)集的超集,{A,B,C},{A,B,D}等等也都是非頻繁的,這些就都可以忽略不去計(jì)算。
運(yùn)用Apriori算法的思想,我們就能去掉很多非頻繁的項(xiàng)集,大大簡化計(jì)算量。
二、算法介紹
這里用的是Python舉例,用的包是apriori,當(dāng)然R語言等其他語言,也有對應(yīng)的算法包,原來都是一樣的。
#包安裝pip install efficient-apriori#加載包from efficient_apriori import apriori# 構(gòu)造數(shù)據(jù)集data = [('牛奶','面包','尿不濕','啤酒','榴蓮'),('可樂','面包','尿不濕','啤酒','牛仔褲'),('牛奶','尿不濕','啤酒','雞蛋','咖啡'),('面包','牛奶','尿不濕','啤酒','睡衣'),('面包','牛奶','尿不濕','可樂','雞翅')]#挖掘頻繁項(xiàng)集和頻繁規(guī)則itemsets, rules = apriori(data, min_support=0.6, min_confidence=1)#頻繁項(xiàng)集print(itemsets){1: {('啤酒',): 4, ('尿不濕',): 5, ('牛奶',): 4, ('面包',): 4}, 2: {('啤酒', '尿不濕'): 4, ('啤酒', '牛奶'): 3, ('啤酒', '面包'): 3, ('尿不濕', '牛奶'): 4, ('尿不濕', '面包'): 4, ('牛奶', '面包'): 3}, 3: {('啤酒', '尿不濕', '牛奶'): 3, ('啤酒', '尿不濕', '面包'): 3, ('尿不濕', '牛奶', '面包'): 3}}itemsets[1] #滿足條件的一元組合{('啤酒',): 4, ('尿不濕',): 5, ('牛奶',): 4, ('面包',): 4}itemsets[2]#滿足條件的二元組合{('啤酒', '尿不濕'): 4,('啤酒', '牛奶'): 3,('啤酒', '面包'): 3,('尿不濕', '牛奶'): 4,('尿不濕', '面包'): 4,('牛奶', '面包'): 3}itemsets[3]#滿足條件的三元組合{('啤酒', '尿不濕', '牛奶'): 3, ('啤酒', '尿不濕', '面包'): 3, ('尿不濕', '牛奶', '面包'): 3}#頻繁規(guī)則print(rules)[{啤酒} -> {尿不濕}, {牛奶} -> {尿不濕}, {面包} -> {尿不濕}, {啤酒, 牛奶} -> {尿不濕}, {啤酒, 面包} -> {尿不濕}, {牛奶, 面包} -> {尿不濕}]
三、挖掘?qū)嵗?/span>
每個導(dǎo)演都有自己的偏好、比如周星馳有星女郎,張藝謀有謀女郎,且鞏俐經(jīng)常在張藝謀的電影里面出現(xiàn),因此,每個導(dǎo)演對演員的選擇都有一定的偏愛,我們以寧浩導(dǎo)演為例,分析下選擇演員的一些偏好,沒有找到公開的數(shù)據(jù)集,自己手動扒了一部分,大概如下,有些實(shí)在有點(diǎn)多,于是簡化下進(jìn)行分析

可以看到,我們一共扒了9部電影,計(jì)算的時候,支持度的時候,總數(shù)就是9.
#把電影數(shù)據(jù)轉(zhuǎn)換成列表data = [['葛優(yōu)','黃渤','范偉','鄧超','沈騰','張占義','王寶強(qiáng)','徐崢','閆妮','馬麗'],['黃渤','張譯','韓昊霖','杜江','葛優(yōu)','劉昊然','宋佳','王千源','任素汐','吳京'],['郭濤','劉樺','連晉','黃渤','徐崢','優(yōu)恵','羅蘭','王迅'],['黃渤','舒淇','王寶強(qiáng)','張藝興','于和偉','王迅','李勤勤','李又麟','寧浩','管虎','梁靜','徐崢','陳德森','張磊'],['黃渤','沈騰','湯姆·派福瑞','馬修·莫里森','徐崢','于和偉','雷佳音','劉樺','鄧飛','蔡明凱','王戈','凱特·納爾遜','王硯偉','呲路'],['徐崢','黃渤','余男','多布杰','王雙寶','巴多','楊新鳴','郭虹','陶虹','黃精一','趙虎','王輝'],['黃渤','戎祥','九孔','徐崢','王雙寶','巴多','董立范','高捷','馬少驊','王迅','劉剛','WorapojThuantanon','趙奔','李麒麟','姜志剛','王鷺','寧浩'],['黃渤','徐崢','袁泉','周冬雨','陶慧','岳小軍','沈騰','張儷','馬蘇','劉美含','王硯輝','焦俊艷','郭濤'],['雷佳音','陶虹','程媛媛','山崎敬一','郭濤','范偉','孫淳','劉樺','黃渤','岳小軍','傅亨','王文','楊新鳴']]
#算法應(yīng)用itemsets, rules = apriori(data, min_support=0.5, min_confidence=1)print(itemsets){1: {('徐崢',): 7, ('黃渤',): 9}, 2: {('徐崢', '黃渤'): 7}}print(rules)[{徐崢} -> {黃渤}]
通過上述分析可以看出:
在寧浩的電影中,用的最多的是黃渤和徐崢,黃渤9次,支持度100%,徐崢7次,支持度78%,('徐崢', '黃渤') 同時出現(xiàn)7次,置信度為100%,看來有徐崢,必有黃渤,真是寧浩必請的黃金搭檔。
當(dāng)然,這個數(shù)據(jù)量比較小,基本上肉眼也能看出來,這里只是提供一個分析案例,鞏固下基礎(chǔ)知識,大規(guī)模的數(shù)據(jù),人眼無法直接感知的時候,算法的挖掘與發(fā)現(xiàn),就顯得特別有意義了。
推薦閱讀:
Python中的高效迭代庫itertools,排列組合隨便求
萬字長文詳解|Python庫collections,讓你擊敗99%的Pythoner
Python初學(xué)者必須吃透這69個內(nèi)置函數(shù)!
↓掃描關(guān)注本號↓