
告別Heatmap!人體姿態(tài)估計(jì)表征新方法SimDR

極市導(dǎo)讀
?本文提出了一種姿態(tài)估計(jì)的解耦坐標(biāo)表征:SimDR,將關(guān)鍵點(diǎn)坐標(biāo)(x, y)用兩條獨(dú)立的、長(zhǎng)度等于或高于原圖片尺寸的一維向量進(jìn)行表征,在CNN-based和Transformer-based人體姿態(tài)估計(jì)模型上均取得了更好的表現(xiàn)。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿

論文筆記及思考:Human Pose Regression with Residual Log-likelihood Estimation(ICCV 2021 Oral)?
https://zhuanlan.zhihu.com/p/395521994
論文筆記TokenPose: Learning Keypoint Tokens for Human Pose Estimation(附pytorch導(dǎo)出onnx說明)
https://zhuanlan.zhihu.com/p/443243421
終于,在最近我刷到了這樣一篇論文,發(fā)出了大家共同的一個(gè)問題:對(duì)于姿態(tài)估計(jì)任務(wù)而言,2D高斯熱圖形式的特征表示真的是必要的嗎?
1. 簡(jiǎn)介
首先本文列舉了Heatmap-based方法飽受詬病的幾大罪狀:
在低分辨率圖片上掉點(diǎn)嚴(yán)重:對(duì)于HRNet-W48,當(dāng)輸入分辨率從256x256降到64x64,AP會(huì)從75.1掉到48.5 為了提升精度,需要多個(gè)上采樣層來將特征圖分辨率由低向高進(jìn)行恢復(fù):通常來說上采樣會(huì)使用轉(zhuǎn)置卷積來獲得更好的性能,但相應(yīng)的計(jì)算量也更大,骨干網(wǎng)絡(luò)輸出的特征圖原本通道數(shù)就已經(jīng)很高了,再上采樣帶來的開銷是非常龐大的 需要額外的后處理來減小尺度下降帶來的量化誤差:如DARK修正高斯分布,用argmax獲取平面上的極值點(diǎn)坐標(biāo)等
因此,本文發(fā)出疑問:用2D高斯熱圖表征來聯(lián)合編碼橫縱坐標(biāo)真的是維持高精度必要的嗎?
在過去一年中,Transformer模型在CV領(lǐng)域興起,涌現(xiàn)了一批不錯(cuò)的在姿態(tài)估計(jì)任務(wù)上的工作,如Tokenpose。盡管Tokenpose模型最終的輸出依然是heatmap形式,但在模型中間的特征表示卻是一維向量的形式(用一個(gè)token表征一個(gè)關(guān)鍵點(diǎn),具體細(xì)節(jié)可以看我之前的文章),最終通過一個(gè)MLP把一維向量映射到HxW維再reshape成2D,并沒有像傳統(tǒng)FCN那樣,在整個(gè)pipeline中維持2D特征圖結(jié)構(gòu)。這些工作說明,帶有顯式空間結(jié)構(gòu)的高斯熱圖表征可能并不是編碼位置信息所必需的。
于是,為了探索更高效的關(guān)鍵點(diǎn)表征方式,本文提出了一種姿態(tài)估計(jì)的解耦坐標(biāo)表征,Simple Disentagled coordinate Representation(SimDR),將關(guān)鍵點(diǎn)坐標(biāo)(x, y)用兩條獨(dú)立的、長(zhǎng)度等于或高于原圖片尺寸的一維向量進(jìn)行表征,在CNN-based和Transformer-based人體姿態(tài)估計(jì)模型上均取得了更好的表現(xiàn)。

2. SimDR
傳統(tǒng)的Heatmap-based方法通過2D高斯分布生成高斯熱圖作為標(biāo)簽,監(jiān)督模型輸出,通過L2 loss來進(jìn)行優(yōu)化。而這種方法下得到的Heatmap尺寸往往是小于圖片原尺寸的,因而最后通過argmax得到的坐標(biāo)放大回原圖,會(huì)承受不可避免的量化誤差。
坐標(biāo)編碼
在本文提出的方法中,關(guān)鍵點(diǎn)的x和y坐標(biāo)通過兩條獨(dú)立的一維向量來進(jìn)行表征,通過一個(gè)縮放因子k(>=1),得到的一維向量長(zhǎng)度也將大于等于圖片邊長(zhǎng)。對(duì)于第p個(gè)關(guān)鍵點(diǎn),其編碼后的坐標(biāo)將表示為:
縮放因子k的作用是將定位精度增強(qiáng)到比單個(gè)像素更小的級(jí)別
坐標(biāo)解碼
假設(shè)模型輸出兩條一維向量,很自然地,預(yù)測(cè)點(diǎn)的坐標(biāo)計(jì)算方法為:
即,一維向量上最大值點(diǎn)所在位置除以縮放因子還原到圖片尺度。
經(jīng)歷了lambda次下采樣的高斯熱圖,量化誤差級(jí)別為[0, lambda/2),而本文的方法級(jí)別為[0, 1/2k)。
網(wǎng)絡(luò)結(jié)構(gòu)
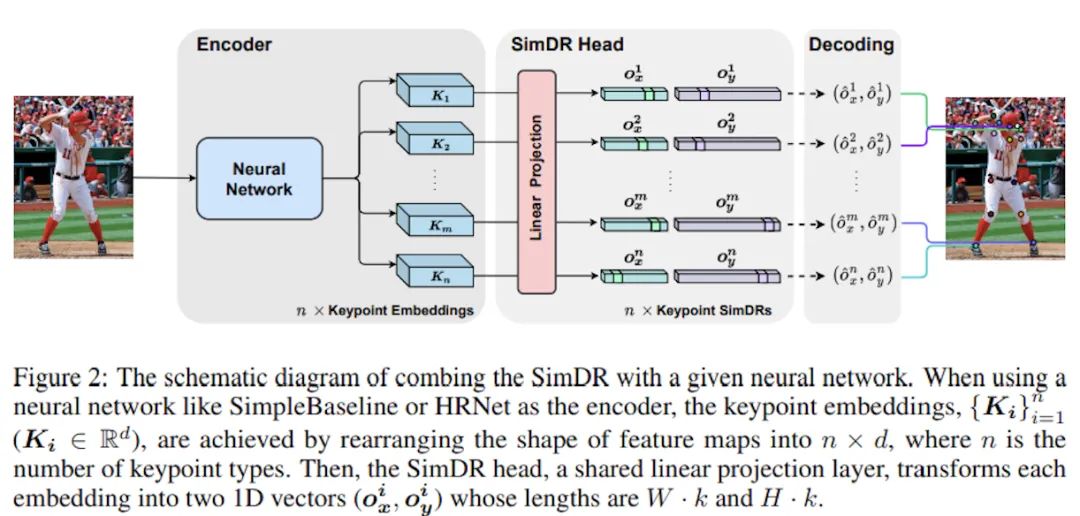
在清楚了原理后,SimDR的頭部結(jié)構(gòu)也就非常直觀了,n個(gè)關(guān)鍵點(diǎn)對(duì)應(yīng)n個(gè)embedding,也就是網(wǎng)絡(luò)輸出n條一維向量,再通過線性投影(MLP等)為n個(gè)SimDR表征。
具體地講,對(duì)于CNN-based模型,可以將輸出的特征圖拉直為d維的一維向量,再通過線性投影把d維升高到W*k維和H*k維。而對(duì)于Transformer-based模型,輸出則已經(jīng)是一維向量,同樣地進(jìn)行投影即可。
訓(xùn)練target和目標(biāo)函數(shù)
很自然地可以發(fā)現(xiàn),本文的方法將關(guān)鍵點(diǎn)定位問題轉(zhuǎn)化為了分類問題,因而目標(biāo)函數(shù)可以使用相較于L2(MSE) Loss 性質(zhì)更優(yōu)的分類loss,簡(jiǎn)單起見本文使用了交叉熵。
一點(diǎn)私貨:將定位問題轉(zhuǎn)化為分類問題其實(shí)之前已經(jīng)有大量的工作,比如Generalized Focal Loss工作中提出的Distribution Focal Loss,便是利用向量分布來表征bbox坐標(biāo)點(diǎn)的位置,在輕量和精度上均取得了優(yōu)異的成績(jī),也衍生出了有名的開源項(xiàng)目Nanodet。
更進(jìn)一步
上面所述的SimDR存在一個(gè)問題,即作為分類問題標(biāo)簽是one-hot的,除了正確的那一個(gè)點(diǎn)外其他錯(cuò)誤坐標(biāo)是平等,會(huì)受到同等的懲罰,但實(shí)際上模型預(yù)測(cè)的位置越接近正確坐標(biāo),受到的懲罰應(yīng)該越低才更合理。因此,本文進(jìn)一步提出了升級(jí)版SimDR,通過1D高斯分布來生成監(jiān)督信號(hào),使用KL散度作為損失函數(shù),計(jì)算目標(biāo)向量和預(yù)測(cè)向量的KL散度進(jìn)行訓(xùn)練:
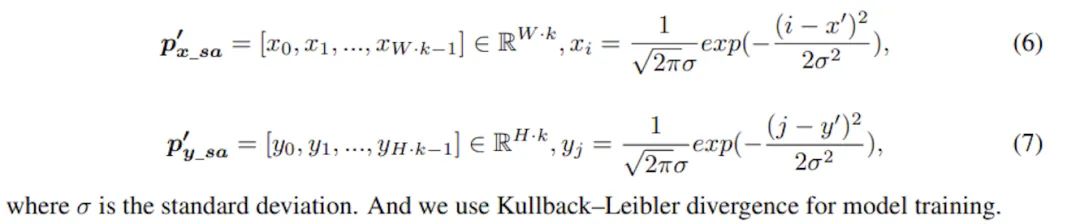
3. 實(shí)驗(yàn)
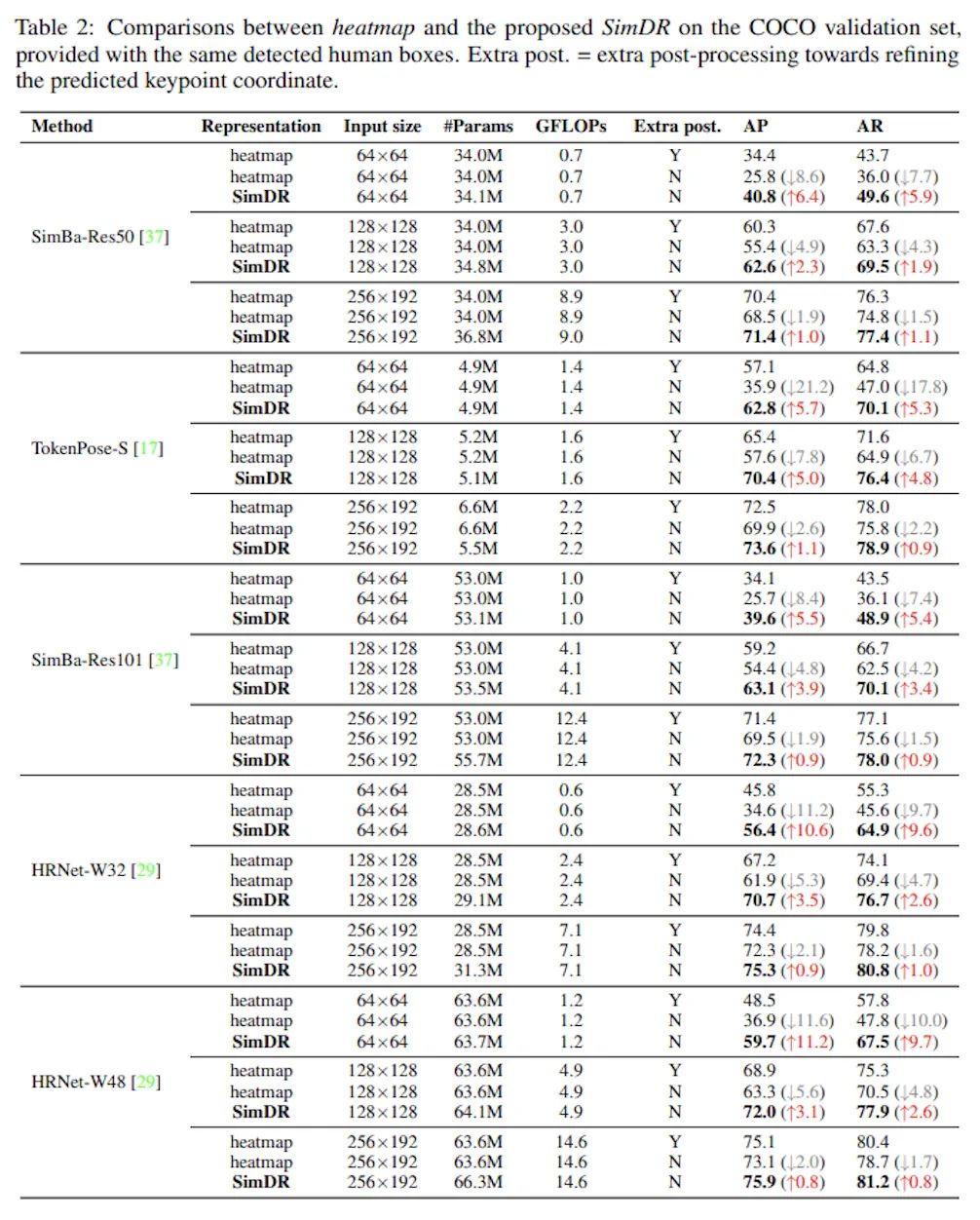
在COCO數(shù)據(jù)集上的實(shí)驗(yàn)對(duì)比可以看到,在小尺度(64x64)圖片輸入上Heatmap方法出現(xiàn)嚴(yán)重的掉點(diǎn)問題,哪怕是強(qiáng)如HRNet-W48作為backbone也難逃AP掉到50以下的厄運(yùn),而SimDR方法在更低計(jì)算量的情況下多了10.6個(gè)點(diǎn)的提升。
另一個(gè)值得注意的點(diǎn)是,Tokenpose作為Transformer-based方法,也是唯一一個(gè)在64x64圖片輸入上AP高于50的網(wǎng)絡(luò),由此可見Transformer的強(qiáng)大。而且這里的實(shí)驗(yàn)中使用的是Tokenpose-S網(wǎng)絡(luò),其特征提取層只由幾層卷積構(gòu)成,我有理由相信,如果換成Tokenpose-L等用HRNet做特征提取的結(jié)果會(huì)更加爆炸。
BTW,到這個(gè)時(shí)候我才注意到Tokenpose也是本文作者的工作,難怪如此緊跟時(shí)髦hhhh
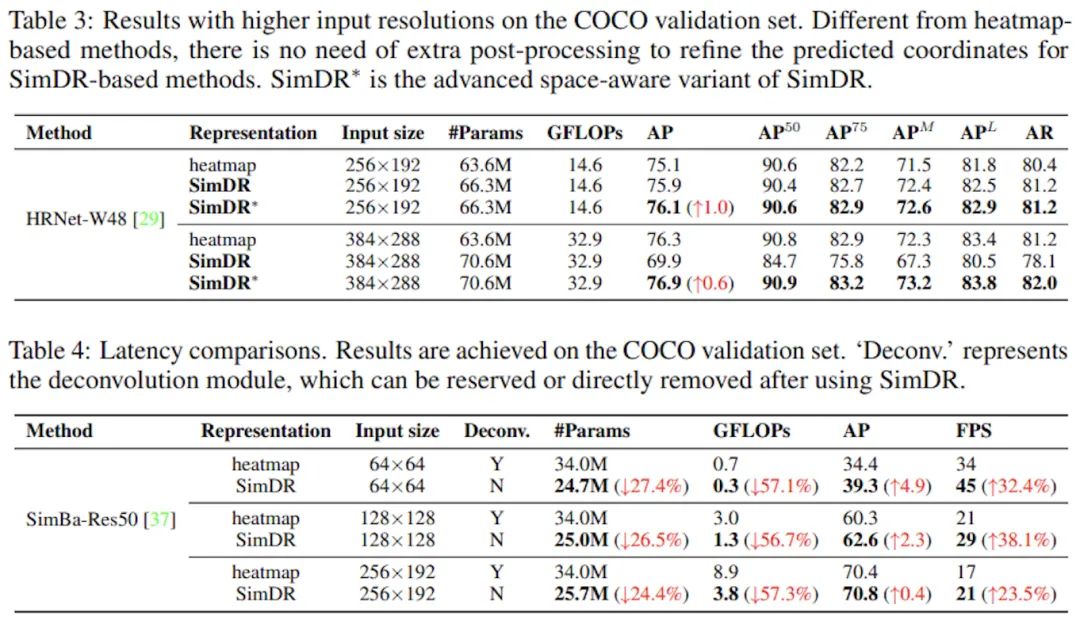
加強(qiáng)版SimDR的對(duì)比實(shí)驗(yàn)中可以看到,在較大尺度的圖片輸入上,SimDR也還有不錯(cuò)的表現(xiàn),但隨著圖片變大,Heatmap的收益也越來越高,在大尺度384x288上甚至超越了普通版SimDR。作者分析其中的原因在于,足夠大的輸入圖片會(huì)導(dǎo)致全連接層參數(shù)量過高,又因?yàn)閷?duì)錯(cuò)誤的懲罰一樣,因而模型出現(xiàn)了過擬合,因此采用加強(qiáng)版SimDR來訓(xùn)練是更好的選擇。
作者同時(shí)也表示,更加仔細(xì)地設(shè)計(jì)損失函數(shù)和監(jiān)督信號(hào)能將SimDR的性能邊界進(jìn)一步推進(jìn)。看到這一句時(shí)我瞬間想到了Tokenpose和RLE,跟這篇文章三者可以很輕松的結(jié)合起來,RLE+HRNetW48在COCO test-dev上取得的成績(jī)?yōu)?5.5AP,而本文使用加強(qiáng)版SimDR達(dá)到了76AP,之后我會(huì)實(shí)驗(yàn)一下三者的結(jié)合。
而在延遲方面,一維表征帶來的提升是巨大的,在中小尺度輸入上均能取得參數(shù)和精度上的優(yōu)勢(shì),同時(shí)免去了Heatmap-based方法所需要的繁瑣后處理和上采樣開銷,這些優(yōu)點(diǎn)對(duì)于輕量級(jí)模型和需要落地部署的實(shí)時(shí)應(yīng)用都是極其有利的,也是我一直以來關(guān)注的重點(diǎn)。
k值的選擇
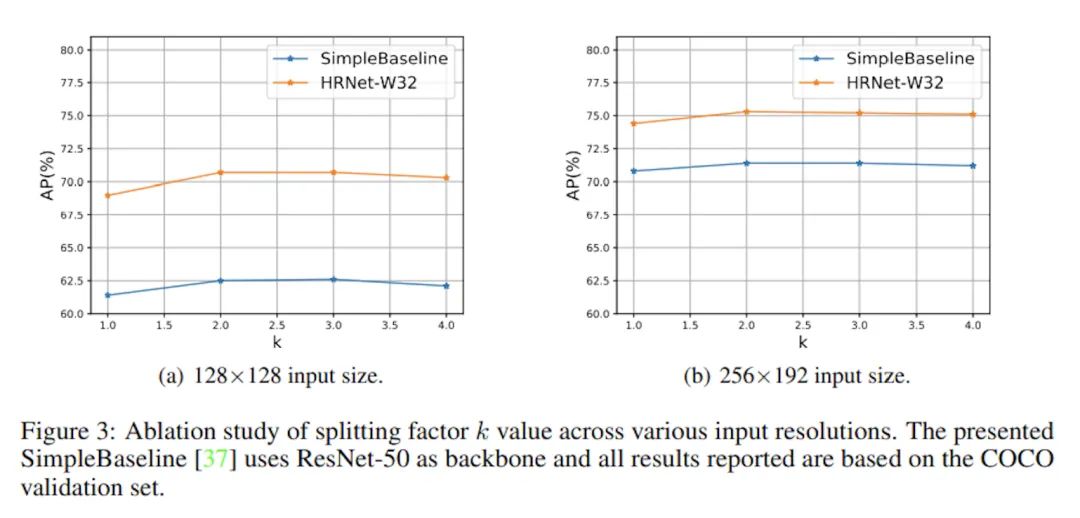
在兩個(gè)CNN-based模型上驗(yàn)證了不同k取值的表現(xiàn),總體而言k取2或3是足夠優(yōu)秀的,更大的k帶來的收益幾乎可以忽略不計(jì)了,并且為了避免過擬合的風(fēng)險(xiǎn),越大的輸入圖片應(yīng)該用越小的k。不過作為對(duì)超參數(shù)更敏感的Transformer,本文并沒有做相關(guān)的實(shí)驗(yàn),也許作為Tokenpose的作者可以也跑一下實(shí)驗(yàn)。
如果覺得有用,就請(qǐng)分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“transformer”獲取最新Transformer綜述論文下載~

#?極市平臺(tái)簽約作者#

Tau
知乎:鏡子
計(jì)算機(jī)視覺算法工程師
研究領(lǐng)域:姿態(tài)估計(jì)、輕量化模型、圖像檢索
持續(xù)學(xué)習(xí),樂于實(shí)驗(yàn)總結(jié),分享學(xué)術(shù)前沿,注重AI技術(shù)實(shí)用性和產(chǎn)品化
作品精選
吊打一切現(xiàn)有版本的YOLO!曠視重磅開源YOLOX:新一代目標(biāo)檢測(cè)性能速度擔(dān)當(dāng)!
圖像增強(qiáng)領(lǐng)域大突破!以1.66ms的速度處理4K圖像,港理工提出圖像自適應(yīng)的3DLUT
