
深度學(xué)習(xí)中的人體姿態(tài)估計(jì)概述
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號
視覺/圖像重磅干貨,第一時(shí)間送達(dá)
前言?本文概述了多人姿態(tài)估計(jì)任務(wù),重點(diǎn)介紹了深度學(xué)習(xí)中的一些多人姿態(tài)估計(jì)方法,并簡要介紹了多人姿態(tài)估計(jì)的應(yīng)用場景。
作者:Bharath Raj
人體姿勢骨架以圖形格式表示人的方向。本質(zhì)上,它是一組可以連接起來描述人的姿勢的坐標(biāo)。骨架中的每個(gè)坐標(biāo)都稱為零件(或關(guān)節(jié)或關(guān)鍵點(diǎn))。兩個(gè)部分之間的有效連接稱為一對(或肢體)。請注意,并非所有零件組合都會(huì)產(chǎn)生有效的配對。下面顯示了一個(gè)示例人體姿勢骨架。
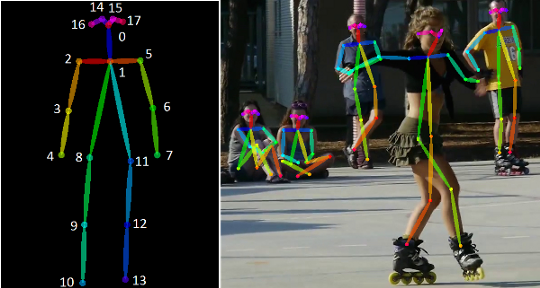
左:人體姿勢骨架的 COCO 關(guān)鍵點(diǎn)格式。右圖:渲染的人體姿勢骨架。?
多年來,人們引入了幾種人體姿勢估計(jì)方法。最早(也是最慢)的方法通常是在只有一個(gè)人的圖像中估計(jì)單個(gè)人的姿勢。這些方法通常首先識(shí)別各個(gè)部分,然后在它們之間形成連接以創(chuàng)建姿勢。
自然,這些方法在許多圖像包含多人的現(xiàn)實(shí)生活場景中并不是特別有用。
多人姿勢估計(jì)
多人姿態(tài)估計(jì)比單人情況更困難,因?yàn)閳D像中的位置和人數(shù)是未知的。通常,我們可以使用以下兩種方法之一來解決上述問題:
簡單的方法是首先結(jié)合一個(gè)人檢測器,然后估計(jì)各個(gè)部分,然后計(jì)算每個(gè)人的姿勢。這種方法被稱為自上而下的方法。
另一種方法是檢測圖像中的所有部分(即每個(gè)人的部分),然后關(guān)聯(lián)/分組屬于不同人的部分。這種方法被稱為自下而上的方法。

頂部:典型的自上而下的方法。底部:典型的自下而上的方法。?
通常,自頂向下方法比自底向上方法更容易實(shí)現(xiàn),因?yàn)樘砑尤藛T檢測器比添加關(guān)聯(lián)/分組算法簡單得多。很難判斷哪種方法具有更好的整體性能,因?yàn)樗鼘?shí)際上歸結(jié)為人員檢測器和關(guān)聯(lián)/分組算法中的哪種更好。
在本文中,我們將重點(diǎn)介紹使用深度學(xué)習(xí)技術(shù)的多人人體姿態(tài)估計(jì)。在下一節(jié)中,我們將回顧一些流行的自上而下和自下而上的方法。
深度學(xué)習(xí)方法
1. OpenPose
OpenPose 是最流行的自下而上的多人人體姿勢估計(jì)方法之一,部分原因是它們有充分記錄的 GitHub 實(shí)現(xiàn)代碼。
與許多自下而上的方法一樣,OpenPose 首先檢測屬于圖像中每個(gè)人的部分(關(guān)鍵點(diǎn)),然后將部分分配給不同的個(gè)人。下面顯示的是 OpenPose 模型的架構(gòu)。
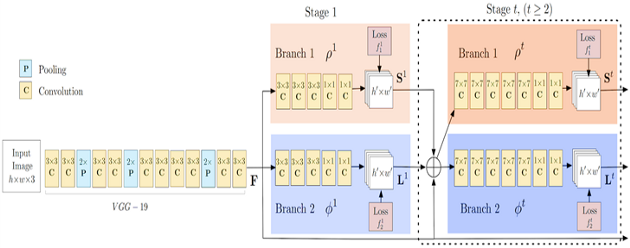
OpenPose 架構(gòu)的流程圖。?
OpenPose 網(wǎng)絡(luò)首先使用前幾層(上述流程圖中的 VGG-19)從圖像中提取特征。然后將特征輸入到卷積層的兩個(gè)平行分支中。第一個(gè)分支預(yù)測一組 18 個(gè)置信度圖,每個(gè)圖代表人體姿勢骨架的特定部分。第二個(gè)分支預(yù)測一組 38 個(gè)部件親和域 (PAF),它表示部件之間的關(guān)聯(lián)程度。
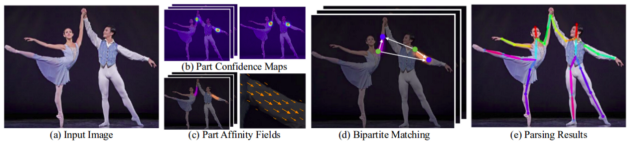
使用 OpenPose 進(jìn)行人體姿態(tài)估計(jì)的步驟。
后續(xù)階段用于細(xì)化每個(gè)分支所做的預(yù)測。使用部件置信度圖,在部件對之間形成二部圖(如上圖所示)。使用 PAF 值,可以修剪二部圖中較弱的鏈接。通過上述步驟,可以估計(jì)人體姿勢骨架并將其分配給圖像中的每個(gè)人。
2. DeepCut
論文:DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation
代碼:http://pose.mpi-inf.mpg.de/
DeepCut 是一種自下而上的多人人體姿態(tài)估計(jì)方法。作者通過定義以下問題來完成這項(xiàng)任務(wù):
產(chǎn)生一組 D 身體部位候選。該集合代表圖像中每個(gè)人身體部位的所有可能位置。從上述候選身體部位集合中選擇身體部位的子集。
使用 C 身體部位類之一標(biāo)記每個(gè)選定的身體部位。身體部位類表示部位的類型,例如“手臂”、“腿”、“軀干”等。
劃分屬于同一個(gè)人的身體部位。

該方法的圖示。?
上述問題通過將其建模為整數(shù)線性規(guī)劃 ( Integer Linear Programming , ILP) 問題來共同解決。它是通過考慮具有域的二元隨機(jī)變量的三元組 (x, y, z) 來建模的,如下圖所示。
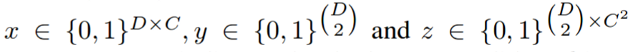
二元隨機(jī)變量的域。?
考慮來自身體部位候選集 D 的兩個(gè)身體部位候選者 d 和 d' 以及來自類別 C 的類別 c 和 c'。身體部位候選者是通過 Faster RCNN 或 Dense CNN 獲得的。現(xiàn)在,我們可以開發(fā)以下語句集。
如果 x(d,c) = 1,則表示候選身體部位 d 屬于類 c。
此外,y(d,d') = 1 表示候選身體部位 d 和 d' 屬于同一個(gè)人。
他們還定義了 z(d,d',c,c') = x(d,c) * x(d',c') * y(d,d')。如果上述值為1,則表示候選身體部位d屬于c類,候選身體部位d'屬于類別c',最后候選身體部位d,d'屬于同一個(gè)人。
最后一個(gè)語句可用于劃分屬于不同人的姿勢。顯然,上述陳述可以用線性方程表示為 (x,y,z) 的函數(shù)。這樣就建立了整數(shù)線性規(guī)劃(?Integer Linear Programming?,?ILP),可以估計(jì)多人的姿態(tài)。對于確切的方程組和更詳細(xì)的分析,請自行查看他們的論文。
3. RMPE (AlphaPose)
論文:RMPE: Regional Multi-person Pose Estimation
代碼:https://github.com/MVIG-SJTU/RMPE
RMPE 是一種流行的自上而下的姿態(tài)估計(jì)方法。作者認(rèn)為自上而下的方法通常取決于人物檢測器的準(zhǔn)確性,因?yàn)樽藙莨烙?jì)是在人物所在的區(qū)域上執(zhí)行的。因此,定位和重復(fù)邊界框預(yù)測中的錯(cuò)誤會(huì)導(dǎo)致姿勢提取算法執(zhí)行欠佳。

重復(fù)預(yù)測(左)和低置信邊界框(右)的影響。
為了解決這個(gè)問題,作者提出使用對稱空間transformer網(wǎng)絡(luò) (Symmetric Spatial Transformer Network, SSTN) 從不準(zhǔn)確的邊界框中提取高質(zhì)量的單人區(qū)域。在這個(gè)提取的區(qū)域中使用單人姿勢估計(jì)器 (SPPE) 來估計(jì)該人的人體姿勢骨架。空間De-Transformer網(wǎng)絡(luò) (SDTN) 用于將估計(jì)的人體姿勢重新映射回原始圖像坐標(biāo)系。最后,使用參數(shù)姿態(tài)非極大抑制 (NMS) 技術(shù)來處理冗余姿態(tài)推演問題。
此外,作者引入了一個(gè)姿勢引導(dǎo)建議生成器(Pose Guided Proposals Generator)來增加訓(xùn)練樣本,從而更好地幫助訓(xùn)練 SPPE 和 SSTN 網(wǎng)絡(luò)。RMPE 的顯著特點(diǎn)是該技術(shù)可以擴(kuò)展到人員檢測算法和 SPPE 的任意組合。
4. Mask RCNN
論文:Mask RCNN
Mask RCNN 是一種用于執(zhí)行語義和實(shí)例分割的流行架構(gòu)。該模型同時(shí)預(yù)測圖像中各種目標(biāo)的邊界框位置和語義分割目標(biāo)的掩碼。基本架構(gòu)可以很容易地?cái)U(kuò)展到人體姿態(tài)估計(jì)。
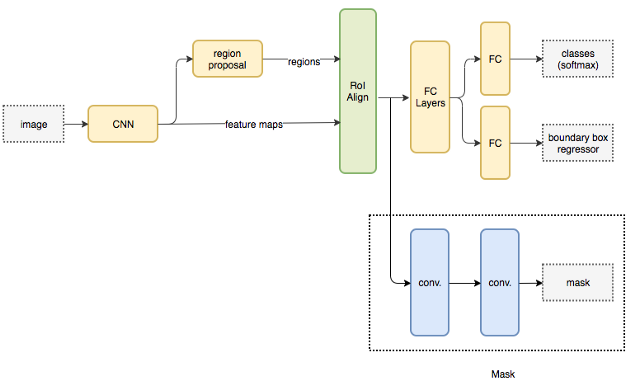
描述 Mask RCNN 架構(gòu)的流程圖。
基本架構(gòu)首先使用 CNN 從圖像中提取特征圖。區(qū)域提議網(wǎng)絡(luò) (Region Proposal Network, RPN) 使用這些特征圖來獲取存在對象的邊界框候選者。邊界框候選從 CNN 提取的特征圖中選擇一個(gè)區(qū)域(區(qū)域)。由于候選邊界框可以有各種大小,因此使用稱為 RoIAlign 的層來減小提取特征的大小,使它們都具有統(tǒng)一的大小。現(xiàn)在,這個(gè)提取的特征被傳遞到 CNN 的并行分支,用于邊界框和分割掩碼的最終預(yù)測。
讓我們專注于執(zhí)行分段的分支。假設(shè)我們圖像中的一個(gè)目標(biāo)可以屬于 K 個(gè)類中的一個(gè)。分割分支輸出 K 個(gè)大小為 m x m 的二進(jìn)制掩碼,其中每個(gè)二進(jìn)制掩碼代表屬于該類的所有目標(biāo)。我們可以通過將每種類型的關(guān)鍵點(diǎn)建模為一個(gè)不同的類并將其視為分割問題來提取屬于圖像中每個(gè)人的關(guān)鍵點(diǎn)。
同時(shí),可以訓(xùn)練目標(biāo)檢測算法來識(shí)別人員的位置。通過結(jié)合人的位置信息以及他們的關(guān)鍵點(diǎn)集,我們獲得了圖像中每個(gè)人的人體姿勢骨架。
這種方法幾乎類似于自頂向下的方法,但人員檢測階段與部件檢測階段并行執(zhí)行。換句話說,關(guān)鍵點(diǎn)檢測階段和人物檢測階段是相互獨(dú)立的。
5. 其他方法
多人人體姿勢估計(jì)是一個(gè)廣闊的領(lǐng)域,有很多方法可以解決這個(gè)問題。為簡潔起見,這里僅解釋了少數(shù)幾種方法。有關(guān)更詳盡的方法列表,可以查看以下鏈接:
1. Awesome Human Pose Estimation:
地址:https://github.com/cbsudux/awesome-human-pose-estimation
2. paperwithcode上關(guān)于多人姿態(tài)估計(jì)的論文列表:
地址:https://paperswithcode.com/sota/multi-person-pose-estimation-on-mpii-multi
應(yīng)用
姿態(tài)估計(jì)在無數(shù)領(lǐng)域都有應(yīng)用,下面列出了其中的一些領(lǐng)域。
1.活動(dòng)識(shí)別
跟蹤一個(gè)人一段時(shí)間內(nèi)姿勢的變化也可用于活動(dòng)、手勢和步態(tài)識(shí)別。有幾個(gè)相同的用例,包括:
用于檢測一個(gè)人是否跌倒或生病的應(yīng)用程序。 可以自主教授正確的鍛煉方式、運(yùn)動(dòng)技巧和舞蹈活動(dòng)的應(yīng)用程序。 可以理解全身手語的應(yīng)用程序。(例如:機(jī)場跑道信號、交警信號等)。 可以增強(qiáng)安全性和監(jiān)視的應(yīng)用程序。
跟蹤人的步態(tài)對于安全和監(jiān)視目的很有用。?
2. 動(dòng)作捕捉和增強(qiáng)現(xiàn)實(shí)
人體姿態(tài)估計(jì)的一個(gè)有趣應(yīng)用是 CGI 應(yīng)用。如果可以估計(jì)人體姿勢,則可以將圖形、樣式、花哨的增強(qiáng)功能、設(shè)備和藝術(shù)品疊加在人身上。通過跟蹤這種人體姿勢的變化,渲染的圖形可以在人物移動(dòng)時(shí)“自然地貼合”他們。

CGI 渲染示例。
通過 Animoji 可以看到一個(gè)很好的視覺示例。盡管上面只跟蹤了人臉的結(jié)構(gòu),但可以推斷出一個(gè)人的關(guān)鍵點(diǎn)。可以利用相同的概念來渲染可以模仿人的運(yùn)動(dòng)的增強(qiáng)現(xiàn)實(shí) (AR) 元素。
3. 訓(xùn)練機(jī)器人
可以讓機(jī)器人跟隨正在執(zhí)行動(dòng)作的人體姿勢骨架的軌跡,而不是手動(dòng)編程機(jī)器人來跟隨軌跡。人類教練可以通過演示來有效地教機(jī)器人某些動(dòng)作。然后機(jī)器人可以計(jì)算如何移動(dòng)其咬合架以執(zhí)行相同的動(dòng)作。
4. 控制臺(tái)的運(yùn)動(dòng)跟蹤
姿勢估計(jì)的一個(gè)有趣應(yīng)用是蹤人類主體在交互式游戲中的運(yùn)動(dòng)。通常,Kinect 使用 3D 姿勢估計(jì)(使用 IR 傳感器數(shù)據(jù))來跟蹤人類玩家的運(yùn)動(dòng)并使用它來渲染虛擬角色的動(dòng)作。
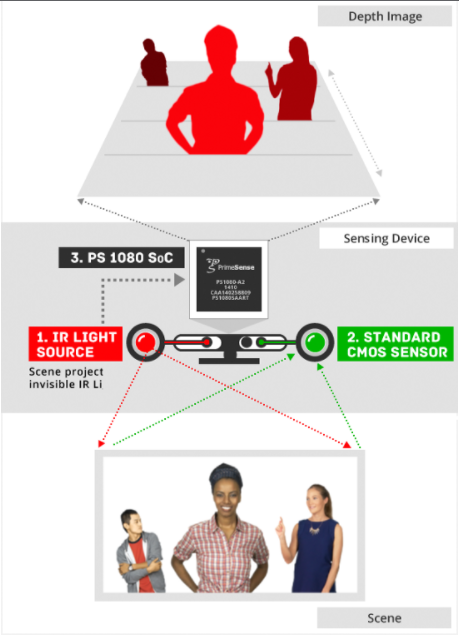
正在運(yùn)行的 Kinect 傳感器。
結(jié)論
人體姿態(tài)估計(jì)領(lǐng)域取得了長足的進(jìn)步,這使我們能夠更好地為可能的無數(shù)應(yīng)用提供服務(wù)。此外,在姿態(tài)跟蹤等相關(guān)領(lǐng)域的研究可以大大提高其在多個(gè)領(lǐng)域的生產(chǎn)利用率。
—版權(quán)聲明—
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
若有侵權(quán),請聯(lián)系微信號:yiyang-sy 刪除或修改!