本文約2200字,建議閱讀5分鐘
本文為你介紹強化學(xué)習(xí)和遺傳算法不同之處,適用于那些情況。
強化學(xué)習(xí)(Reinforcement Learning)和遺傳算法(Genetic Algorithm)都是受自然啟發(fā)的AI方法,它們有何不同?更重要的是,在哪些情況下,其中一種會比另一種更受青睞?”因此,今天我們將嘗試解釋這些原因。
他們是什么... ?
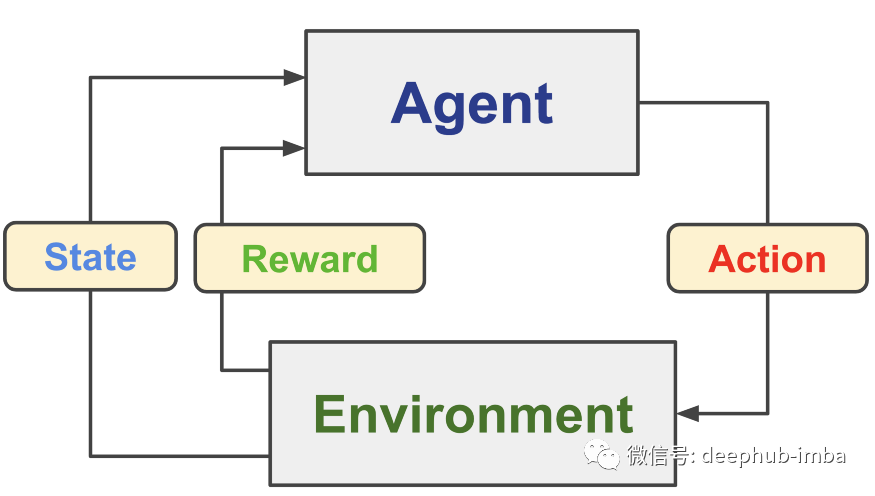
在我們開始比較之前,讓我們更好地理解這些是什么……強化學(xué)習(xí)是訓(xùn)練機器學(xué)習(xí)模型以做出一系列決策。它被構(gòu)造為與環(huán)境交互的代理。
在強化學(xué)習(xí)中,人工智能 (AI) 面臨類似游戲的情況(即模擬)。人工智能通過反復(fù)試驗來提出問題的解決方案。智能體緩慢而穩(wěn)定地學(xué)習(xí)在不確定的、潛在復(fù)雜的環(huán)境中實現(xiàn)目標(biāo),但我們不能指望智能體盲目地偶然發(fā)現(xiàn)完美的解決方案。這是交互發(fā)揮作用的地方,為代理提供了環(huán)境狀態(tài),這成為代理采取行動的輸入/基礎(chǔ)。一個動作首先向代理提供獎勵(注意,根據(jù)問題的適應(yīng)度函數(shù),獎勵可以是正的也可以是負的),基于此獎勵,代理內(nèi)部的策略(ML 模型)適應(yīng)/學(xué)習(xí)其次,它會影響環(huán)境并改變它的狀態(tài),這意味著下一個循環(huán)的輸入會發(fā)生變化。這個循環(huán)一直持續(xù)到創(chuàng)建一個最佳代理。這個循環(huán)試圖復(fù)制我們在自然界中看到的生物體在其生命周期中的學(xué)習(xí)循環(huán)。在大多數(shù)情況下,環(huán)境會在一定數(shù)量的循環(huán)后或有條件地重置。注意,可以同時運行多個代理以更快地獲得解決方案,但所有代理都是獨立運行的。遺傳算法是一種搜索元啟發(fā)式算法,其靈感來自查爾斯達爾文的自然進化理論。該算法反映了自然選擇的過程,即選擇最適合的個體進行繁殖以產(chǎn)生下一代的后代。
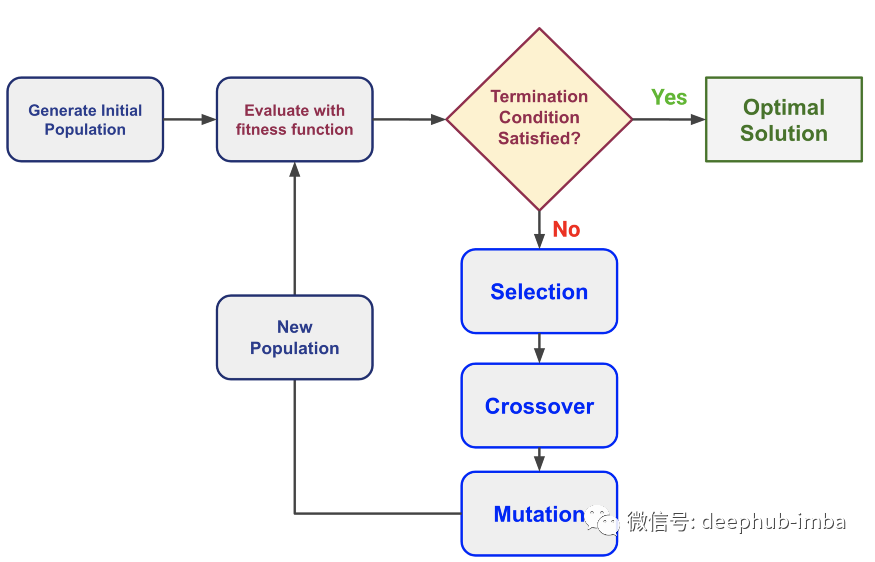
生成初始種群:一組“個體”被稱為群體,其中每個個體的特征是一組以二進制表示的基因(即 0 或 1)。由字符串/序列表示的一組基因稱為染色體。我們開始的人口稱為初始人口。評估:適應(yīng)度函數(shù)是一個系統(tǒng),它確定一個人的健康程度(一個人與其他人競爭的能力)。它為每個人提供了一個適應(yīng)度分數(shù),這有助于量化表現(xiàn)。該函數(shù)在總體表現(xiàn)上執(zhí)行,以量化和比較個體的表現(xiàn)。選擇:挑選“最適合的”(基于評估階段生成的適應(yīng)度分數(shù))個體以產(chǎn)生下一代(即下一個評估和繁殖周期的新種群)的過程。沒有基于適應(yīng)度分數(shù)的嚴格截止,但選擇更多地基于概率(適應(yīng)度分數(shù)越高,被選中的概率越高),并為下一階段選擇一對。交叉:混合選擇的一對個體的基因以產(chǎn)生一對新個體的過程稱為交叉或遺傳操作。這個過程繼續(xù)創(chuàng)造一個新的人口。交叉可以用不同的方法進行,例如:單點交叉、兩點交叉、順序交叉、部分映射交叉 、循環(huán)交叉。突變:在某些新個體中,他們的一些基因可能會以低隨機概率發(fā)生突變。這意味著染色體(位序列)中的某些基因(位)可以改變(翻轉(zhuǎn))。突變有助于保持種群內(nèi)的多樣性并防止過早收斂。終止:當(dāng)種群收斂時,算法終止。這里的收斂表示個體的遺傳結(jié)構(gòu)不再有顯著差異。終止也可能在一定數(shù)量的循環(huán)后發(fā)生,這通常會導(dǎo)致多個收斂點。如何進行比較?
根據(jù)定義,遺傳算法是一種跨生命的算法,這意味著該方法需要個體“死亡”才能前進。RL旨在成為一種生命內(nèi)學(xué)習(xí)算法,最近開發(fā)的許多方法都針對持續(xù)學(xué)習(xí)和“安全RL”的問題。從根本上講,這兩種方法的操作原則是不同的。RL使用馬爾可夫決策過程,而遺傳算法主要基于啟發(fā)式。RL中的值函數(shù)更新是基于梯度的更新,而GAs通常不使用這種梯度。RL是一種機器學(xué)習(xí),它關(guān)注的是一種特定類型的優(yōu)化問題,即尋找最大化回報的策略(策略),代理以時間步驟與環(huán)境進行交互。GAs是一種自學(xué)習(xí)算法,可以應(yīng)用于任何優(yōu)化問題,其中你可以編碼解決方案,定義一個適應(yīng)度函數(shù)來比較解決方案,你可以隨機地改變這些解決方案。從本質(zhì)上講,GAs可以應(yīng)用于幾乎任何優(yōu)化問題。原則上,您可以使用GAs來查找策略,只要您能夠?qū)⑺鼈兣c適應(yīng)度函數(shù)進行比較。這并不意味著GA更好,這只是意味著如果沒有更好的解決方案,GA將是你的選擇。而RL對于需要在環(huán)境中進行順序決策的問題是一個強有力的方案。遺傳算法:需要較少的關(guān)于問題的信息,但設(shè)計適應(yīng)度函數(shù)并獲得正確的表示和操作可能是非常復(fù)雜和困難的。它在計算上也很昂貴。強化學(xué)習(xí):過多的強化學(xué)習(xí)會導(dǎo)致狀態(tài)過載,從而降低結(jié)果。這種算法不適用于簡單問題的求解。該算法需要大量的數(shù)據(jù)和大量的計算。維數(shù)的詛咒限制了對真實物理系統(tǒng)的強化學(xué)習(xí)。怎么使用
正如我們已經(jīng)討論過的,除了根本的區(qū)別之外,這兩種方法都有各自的用途和缺點。雖然GA的用途更廣泛,但是定義一個適合問題的適應(yīng)度函數(shù)以及正確的表示和操作類型是非常困難的。而RL最適合解決需要連續(xù)決策的問題,但需要更多的數(shù)據(jù),當(dāng)問題的維度較高時就不是很好。基于學(xué)習(xí)的早期階段,RL模型也傾向于變得狹隘。由于明顯的原因,當(dāng)沒有其他解決方案適合這種模式時,GA是最受歡迎的;
對于更簡單的問題,大多數(shù)時候,RL是有效的,但通常比遺傳算法更耗時,而且遺傳算法的適應(yīng)度函數(shù)和表示更容易編寫,所以RL或遺傳算法都可以根據(jù)問題工作;
當(dāng)我們有中等程度的復(fù)雜性和高可用數(shù)據(jù)時,RL是首選;
對于具有更高復(fù)雜性的問題,GA和RL都需要花費大量時間,需要復(fù)雜的表示,或者受到需要處理的維數(shù)的限制。
在這種情況下,兩者的結(jié)合比任何單獨的都更可取。
二者結(jié)合
是的,結(jié)合遺傳算法和強化學(xué)習(xí)是可能的,因為這兩種方法不是相互排斥的。就像它們源于自然的兩個原則一樣,這些方法也可以共存。強化學(xué)習(xí)使代理能夠基于獎勵功能做出決策。然而,在學(xué)習(xí)過程中,學(xué)習(xí)算法參數(shù)值的選擇會顯著影響整個學(xué)習(xí)過程。使用遺傳算法找到學(xué)習(xí)算法中使用的參數(shù)值,比如深度確定性策略梯度(Deep Deterministic Policy Gradient, DDPG)結(jié)合后見經(jīng)驗回放(Hindsight Experience Replay, HER),以幫助加快學(xué)習(xí)代理。導(dǎo)致性能更好,比原來的算法更快。另一種方法是采用強化學(xué)習(xí)的部分,如Agent-Environment關(guān)系,并運行多個可以交叉和變異的代理,類似于遺傳算法。