
【機(jī)器學(xué)習(xí)】Github8.9K,目前最佳模型解釋器-LIME!
模型解釋性--LIME算法

簡(jiǎn)單的模型例如線性回歸,LR等模型非常易于解釋,但在實(shí)際應(yīng)用中的效果卻遠(yuǎn)遠(yuǎn)低于復(fù)雜的梯度提升樹模型以及神經(jīng)網(wǎng)絡(luò)等模型。現(xiàn)在大部分互聯(lián)網(wǎng)公司的建模都是基于梯度提升樹或者神經(jīng)網(wǎng)絡(luò)模型等復(fù)雜模型,遺憾的是,這些模型雖然效果好,但是我們卻較難對(duì)其進(jìn)行很好地解釋,這也是目前一直困擾著大家的一個(gè)重要問題,現(xiàn)在大家也越來越加關(guān)注模型的解釋性。
本文介紹一種解釋機(jī)器學(xué)習(xí)模型輸出的方法LIME。
LIME(Local Interpretable Model-agnostic Explanations)支持的模型包括:
結(jié)構(gòu)化模型的解釋; 文本分類器的解釋; 圖像分類器的解釋;
LIME被用作解釋機(jī)器學(xué)習(xí)模型的解釋,通過LIME我們可以知道為什么模型會(huì)這樣進(jìn)行預(yù)測(cè)。
本文我們就重點(diǎn)觀測(cè)一下LIME是如何對(duì)預(yù)測(cè)結(jié)果進(jìn)行解釋的。
此處我們使用winequality-white數(shù)據(jù)集,并且將quality<=5設(shè)置為0,其它的值轉(zhuǎn)變?yōu)?.
# !pip install lime
import pandas as pd
from xgboost import XGBClassifier
import shap
import numpy as np
from sklearn.model_selection import train_test_split
df = pd.read_csv('./data/winequality-white.csv',sep = ';')
df['quality'] = df['quality'].apply(lambda x: 0 if x <= 5 else 1)
df.head()
| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.0 | 0.27 | 0.36 | 20.7 | 0.045 | 45.0 | 170.0 | 1.0010 | 3.00 | 0.45 | 8.8 | 1 |
| 1 | 6.3 | 0.30 | 0.34 | 1.6 | 0.049 | 14.0 | 132.0 | 0.9940 | 3.30 | 0.49 | 9.5 | 1 |
| 2 | 8.1 | 0.28 | 0.40 | 6.9 | 0.050 | 30.0 | 97.0 | 0.9951 | 3.26 | 0.44 | 10.1 | 1 |
| 3 | 7.2 | 0.23 | 0.32 | 8.5 | 0.058 | 47.0 | 186.0 | 0.9956 | 3.19 | 0.40 | 9.9 | 1 |
| 4 | 7.2 | 0.23 | 0.32 | 8.5 | 0.058 | 47.0 | 186.0 | 0.9956 | 3.19 | 0.40 | 9.9 | 1 |
# 訓(xùn)練集測(cè)試集分割
X = df.drop('quality', axis=1)
y = df['quality']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 模型訓(xùn)練
model = XGBClassifier(n_estimators = 100, random_state=42)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
score
The use of label encoder in XGBClassifier is deprecated and will be removed in a future release.
0.832653061224489
對(duì)單個(gè)樣本進(jìn)行預(yù)測(cè)解釋
下面的圖中表明了單個(gè)樣本的預(yù)測(cè)值中各個(gè)特征的貢獻(xiàn)。
import lime
from lime import lime_tabular
explainer = lime_tabular.LimeTabularExplainer(
training_data=np.array(X_train),
feature_names=X_train.columns,
class_names=['bad', 'good'],
mode='classification'
)
模型有84%的置信度是壞的wine,而其中alcohol,total sulfur dioxide是最重要的。
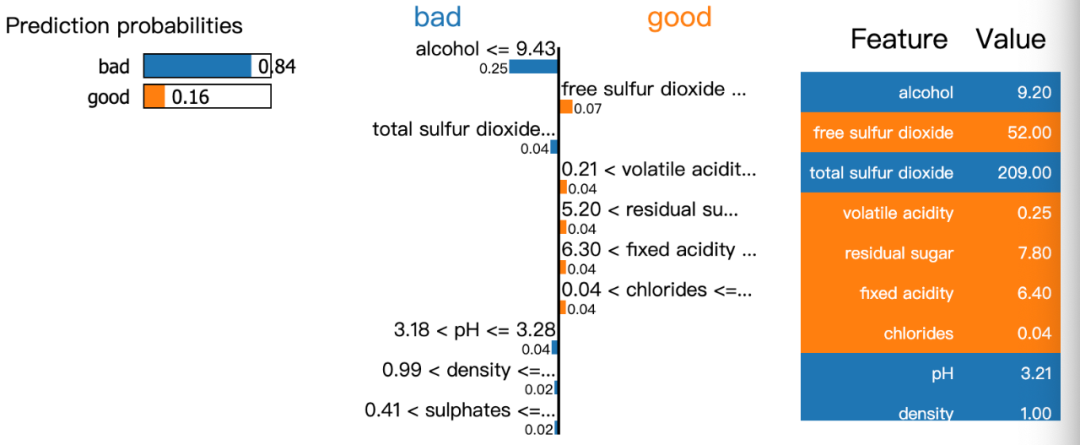
exp = explainer.explain_instance(data_row=X_test.iloc[1], predict_fn=model.predict_proba)
exp.show_in_notebook(show_table=True)
模型有59%的置信度是壞的wine,而其中alcohol,chlorides, density, citric acid是最重要的預(yù)測(cè)參考因素。
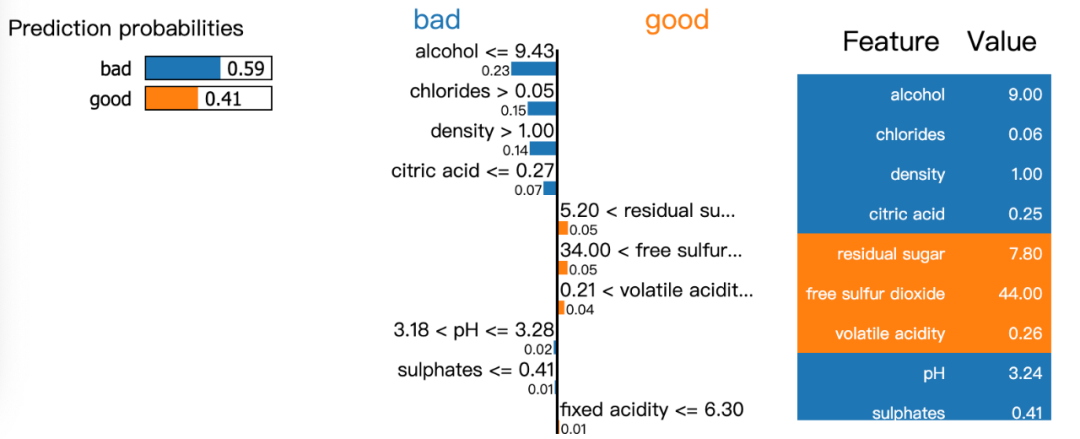
exp = explainer.explain_instance(data_row=X_test.iloc[3], predict_fn=model.predict_proba)
exp.show_in_notebook(show_table=True)LIME可以認(rèn)為是SHARP的升級(jí)版,它通過預(yù)測(cè)結(jié)果解釋機(jī)器學(xué)習(xí)模型很簡(jiǎn)單。它為我們提供了一個(gè)很好的方式來向非技術(shù)人員解釋地下發(fā)生了什么。您不必?fù)?dān)心數(shù)據(jù)可視化,因?yàn)長(zhǎng)IME庫會(huì)為您處理數(shù)據(jù)可視化。
https://www.kaggle.com/piyushagni5/white-wine-quality LIME: How to Interpret Machine Learning Models With Python https://github.com/marcotcr/lime
往期精彩回顧 本站qq群851320808,加入微信群請(qǐng)掃碼: