
姿態(tài)估計(jì):人體骨骼關(guān)鍵點(diǎn)檢測綜述(2016-2020)
加入極市專業(yè)CV交流群,與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度?等名校名企視覺開發(fā)者互動(dòng)交流!
同時(shí)提供每月大咖直播分享、真實(shí)項(xiàng)目需求對接、干貨資訊匯總,行業(yè)技術(shù)交流。關(guān)注?極市平臺?公眾號?,回復(fù)?加群,立刻申請入群~
目錄
一、前言
二、相關(guān)數(shù)據(jù)集
三、Ground Truth的構(gòu)建
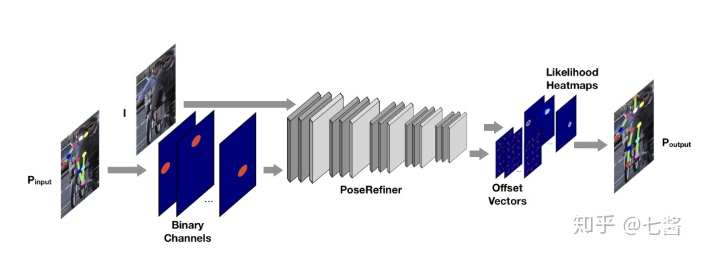
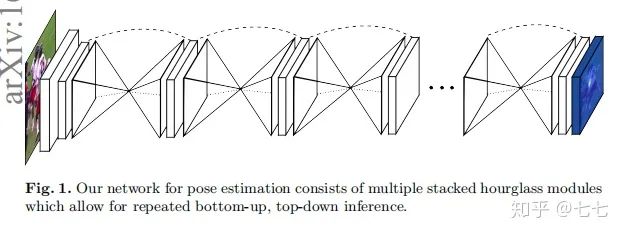
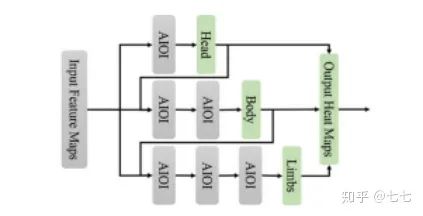
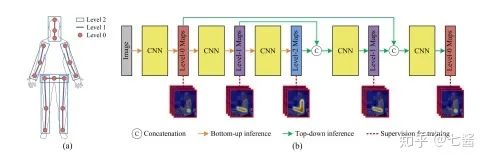
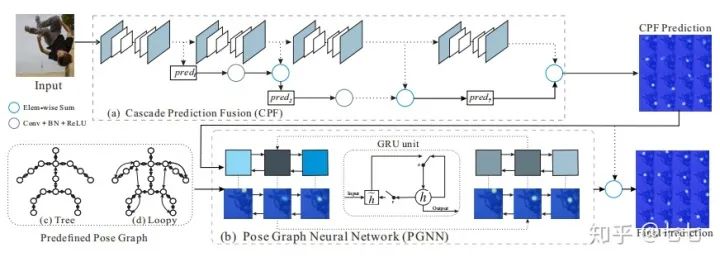
四、單人關(guān)鍵點(diǎn)檢測的發(fā)展(2016-2019)
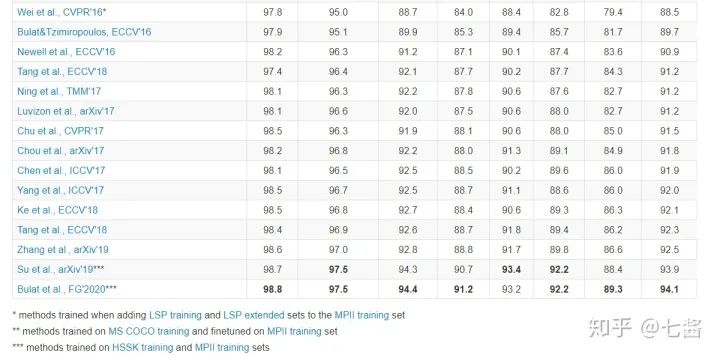
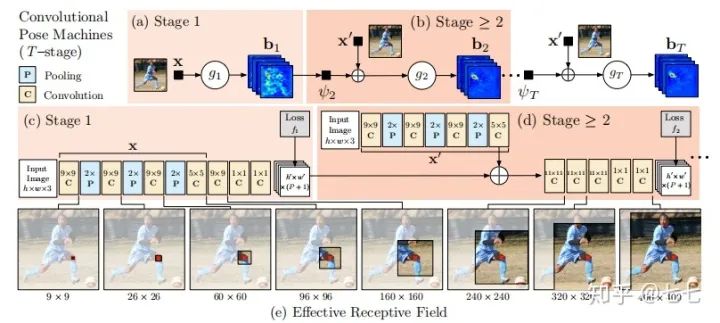
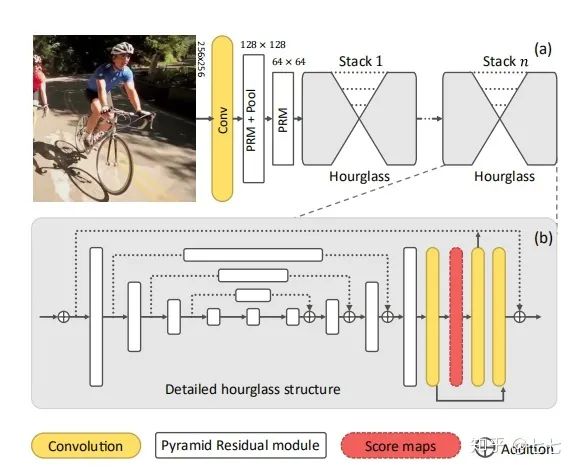

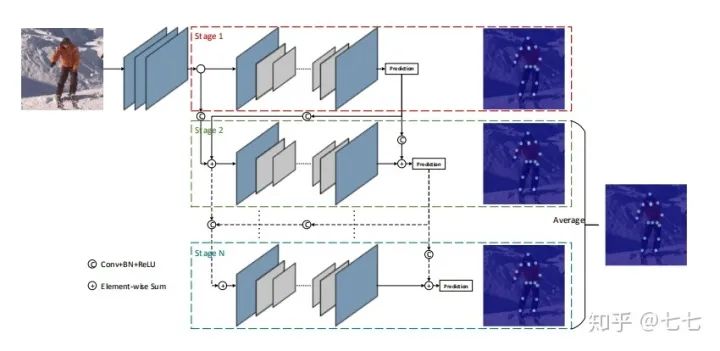
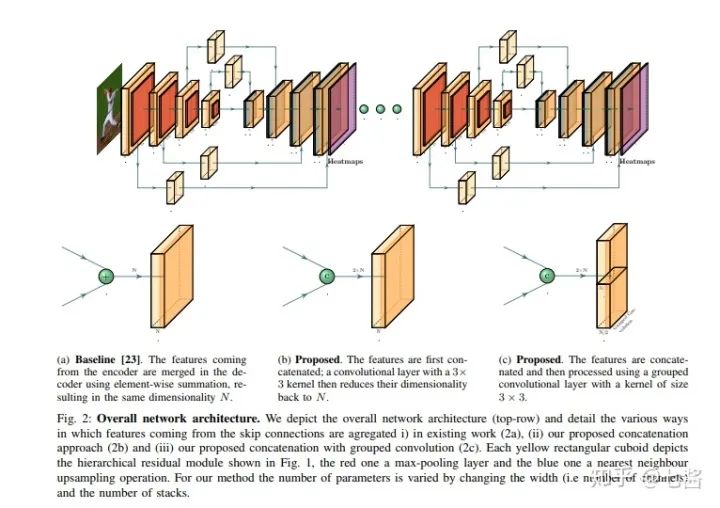
五、多人關(guān)鍵點(diǎn)檢測
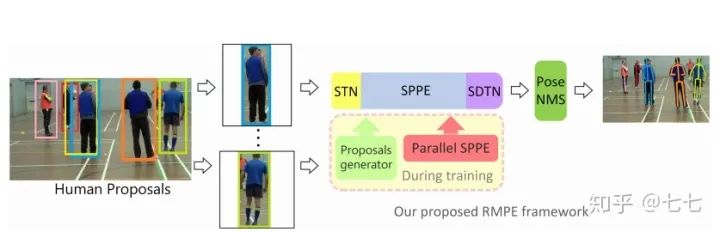
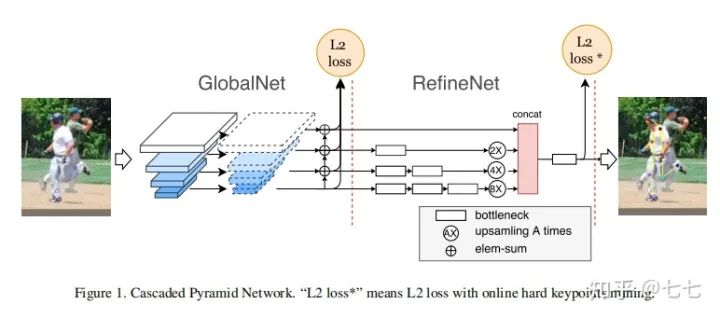
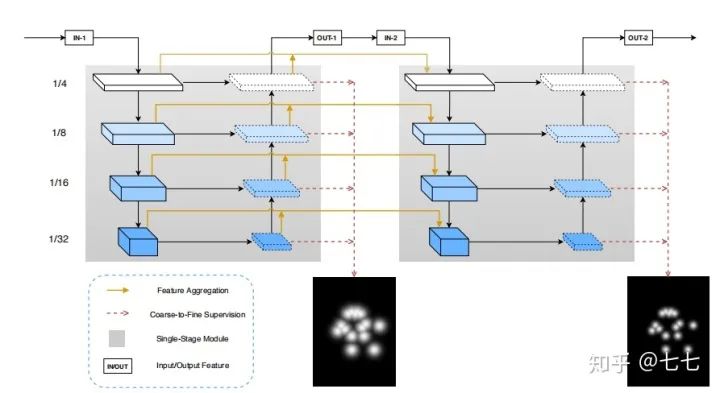
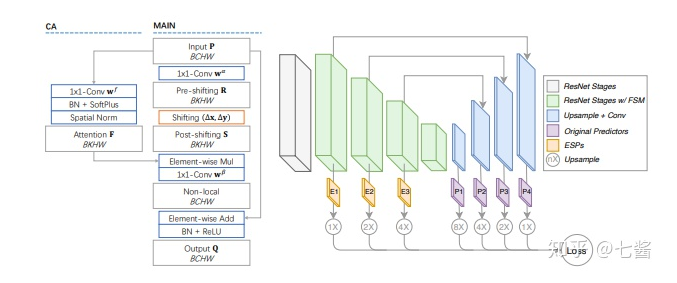
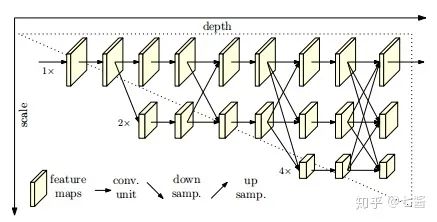
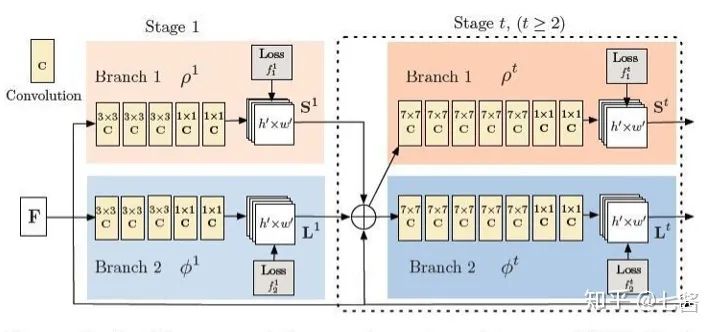
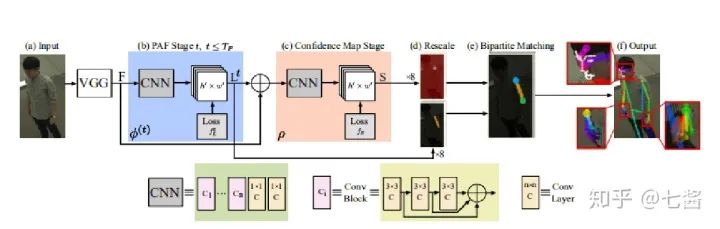
六、3D關(guān)鍵點(diǎn)檢測的算法
七、2020CVPR姿態(tài)估計(jì)相關(guān)文章跟新
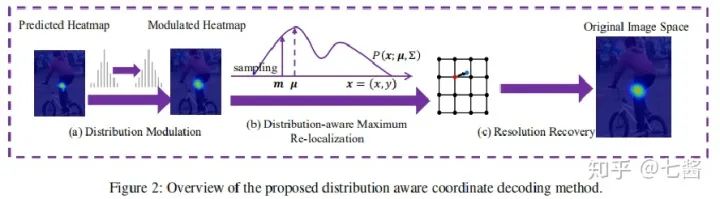
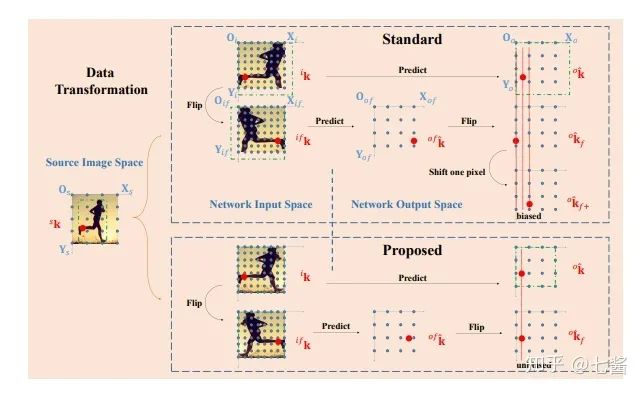
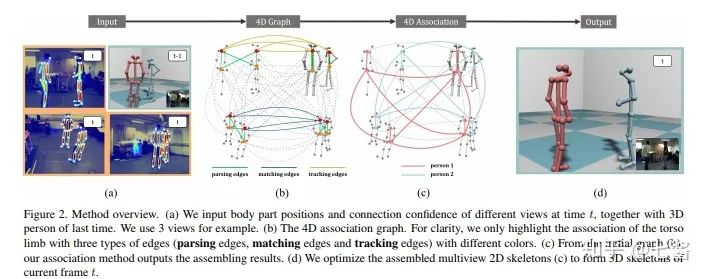

評論
圖片
表情