
【關(guān)于 Sentence-BERT】 那些你不知道的事
作者:楊夕
項目地址:https://github.com/km1994/nlp_paper_study
論文:Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
個人介紹:大佬們好,我叫楊夕,該項目主要是本人在研讀頂會論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯誤,希望大佬們多多指正。
論文地址:chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Farxiv.org%2Fpdf%2F1908.10084.pdf
動機
方法一:BERT使用交叉編碼器:將兩個句子傳遞到變壓器網(wǎng)絡(luò),并預(yù)測目標值;
問題:由于太多可能的組合,此設(shè)置不適用于各種對回歸任務(wù)。在n = 10000個句子的集合中找到相似度最高的對需要BERT n·(n-1)/ 2 = 49 995 000推理計算。在現(xiàn)代V100 GPU上,這大約需要65個小時。類似地,對于一個新問題,找到Quora的超過4,000萬個現(xiàn)有問題中最相似的一個可以建模為與BERT的成對比較,但是,回答單個查詢將需要50多個小時。
方法二:解決聚類和語義搜索的常用方法是將每個句子映射到向量空間,以使語義相似的句子接近。研究人員已開始將單個句子輸入BERT,并得出固定大小的句子嵌入。最常用的方法是平均BERT輸出層(稱為BERT嵌入)或通過使用第一個令牌的輸出([CLS]令牌);
問題:就像我們將要展示的那樣,這種常規(guī)做法產(chǎn)生的句子嵌入效果很差,通常比平均GloVe嵌入效果更差。

解決方法
為了緩解此問題,我們開發(fā)了SBERT。siamese network 體系結(jié)構(gòu)使得可以導(dǎo)出輸入句子的固定大小矢量。使用余弦相似度或Manhatten / Euclidean距離之類的相似度度量,可以找到語義上相似的句子。這些相似性度量可以在現(xiàn)代硬件上非常高效地執(zhí)行,從而允許SBERT用于語義相似性搜索以及聚類。 在10,000個句子的集合中查找最相似的句子對的復(fù)雜性從使用BERT的65小時減少到計算10,000個句子嵌入(使用SBERT約為5秒)和計算余弦相似度(?0.01秒)。通過使用優(yōu)化的索引結(jié)構(gòu),可以將找到最相似的Quora問題從50小時減少到幾毫秒。
方法介紹
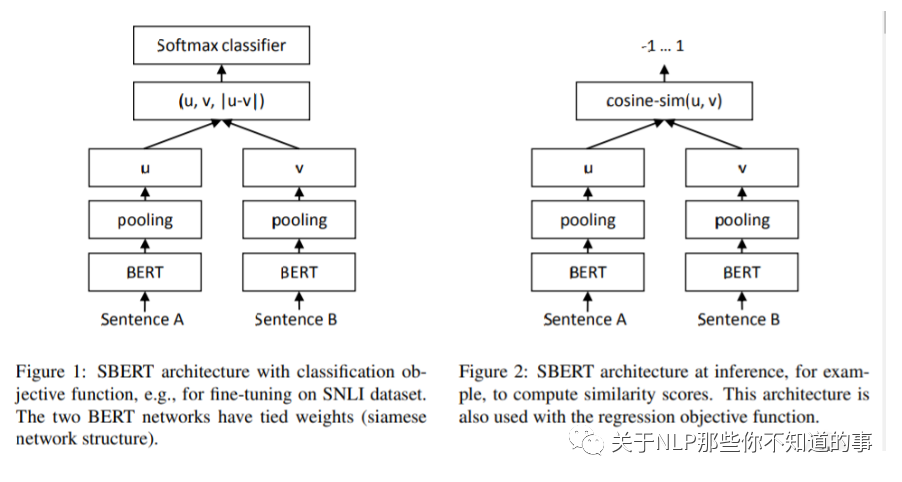
對 BERT 的輸出添加 三種 pooling operation
Using the output of the CLS-token;
computing the mean of all output vectors (MEANstrategy);
computing a max-over-time of theoutput vectors (MAX-strategy)
針對不同的任務(wù),建立三種目標函數(shù)
Classification Objective Function(上圖左)
獲取到 兩句話 的 句子向量 u 和 v;
將 u 、v 和二者按位求差向量 |u-v| 進行拼接;
拼接好的向量乘上一個可訓(xùn)練的權(quán)重 Wt;

Regression Objective Function (上圖右)
目標函數(shù)是MSE-loss,直接對兩句話的句子向量 和 計算余弦相似度,然后計算。
Triplet Objective Function
在這個目標函數(shù)下,將模型框架進行修改,將原來的兩個輸入,變成三個句子輸入。給定一個錨定句 a ,一個肯定句 p和一個否定句 n ,模型通過使 p和a 的距離小于 n和a 的距離,來優(yōu)化模型。使其目標函數(shù)o最小,即:

實驗結(jié)果
模型效果對比實驗
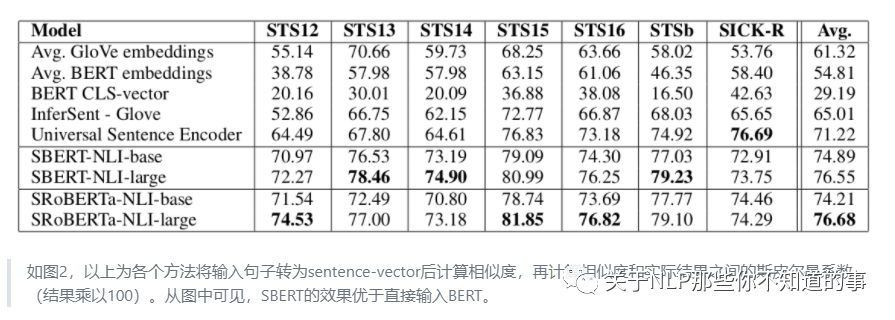
消融實驗
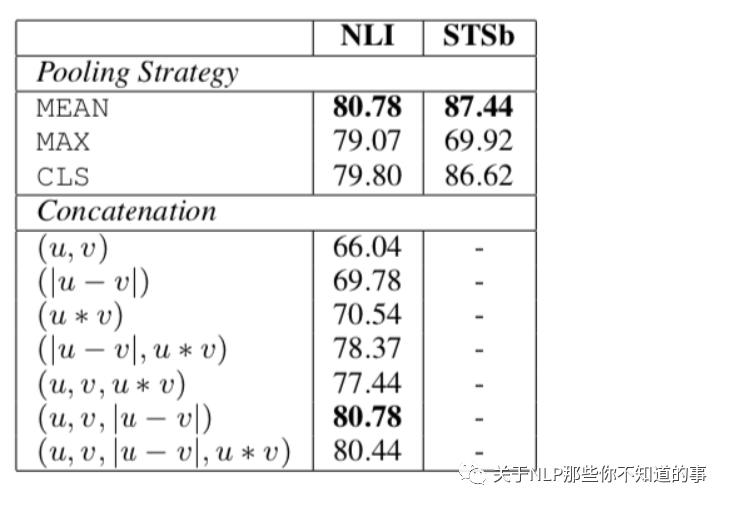
本實驗檢測了不同pooling方法和不同特征concat手段對結(jié)果的影響。最終發(fā)現(xiàn),特征concat方式對結(jié)果有較大的影響,而pooling方法影響不大。特別的是,加上u*v這個特征后,效果反而會有所下降。
計算開銷試驗
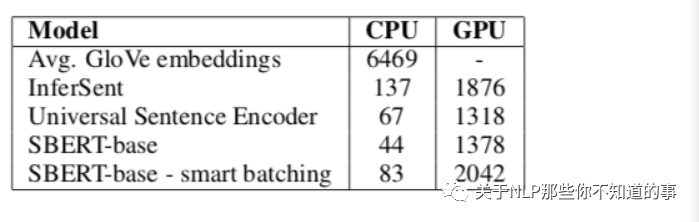
該實驗衡量了不同的句子Embedding生成方法的速度。從圖中可以看出,在CPU上運行時,InferSent的速度比SBERT大約快65%;但切換到可并行的GPU后,transformer可并行的優(yōu)勢就顯現(xiàn)出來,當SBERT采用聰明的batch size時,它的速度比InferSent快~9%。