
【關于 DSSM】 那些你不知道的事
作者:楊夕
項目地址:https://github.com/km1994/nlp_paper_study
論文:Deep Structured Semantic Model
論文會議:CIKM2013
論文地址:https://posenhuang.github.io/papers/cikm2013_DSSM_fullversion.pdf
代碼學習:https://github.com/km1994/TextMatching/tree/master/dssm
個人介紹:大佬們好,我叫楊夕,該項目主要是本人在研讀頂會論文和復現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯誤,希望大佬們多多指正。
目錄

動機
問題:語義相似度問題
字面匹配體現(xiàn)
召回:在召回時,傳統(tǒng)的文本相似性如 BM25,無法有效發(fā)現(xiàn)語義類 Query-Doc 結果對,如"從北京到上海的機票"與"攜程網(wǎng)"的相似性、"快遞軟件"與"菜鳥裹裹"的相似性
排序:在排序時,一些細微的語言變化往往帶來巨大的語義變化,如"小寶寶生病怎么辦"和"狗寶寶生病怎么辦"、"深度學習"和"學習深度";
使用 LSA 類模型進行語義匹配,但是效果不好
DSSM (Deep Structured Semantic Models) 深度語義匹配模型介紹
思路
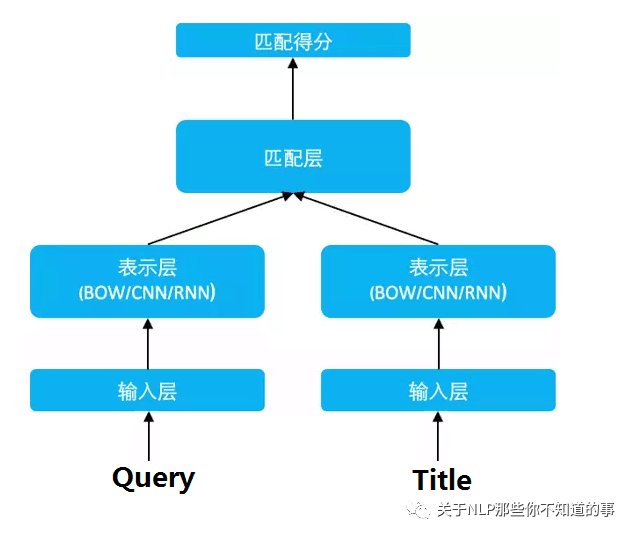
利用 表示層 將 Query 和 Title 表達為低維語義向量;
通過 cosine 距離來計算兩個語義向量的距離,最終訓練出語義相似度模型。
優(yōu)點
該模型既可以用來預測兩個句子的語義相似度,又可以獲得某句子的低維語義向量表達
模型結構介紹
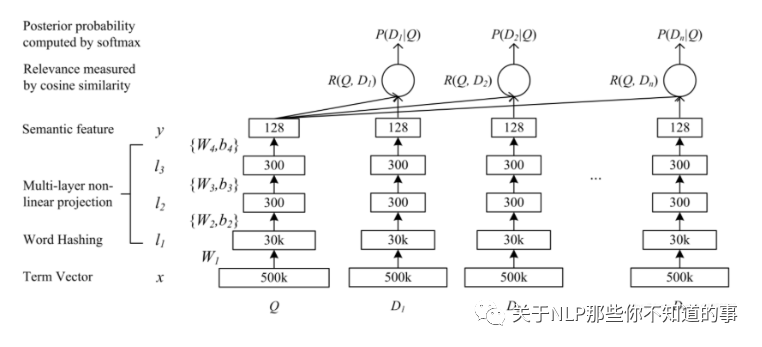
三層:
embedding 層對應圖中的Term Vector,Word Hashing;
特征提取層對應圖中的,Multi-layer,Semantic feature;
匹配層 Cosine similarity, Softmax;
輸入層
(1) 英文

(2)中文
問題:
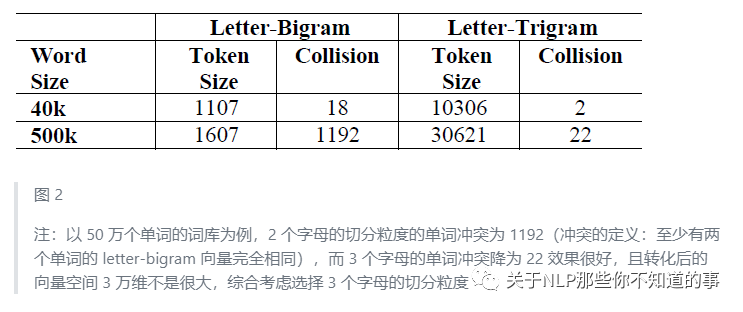
中文的輸入層處理方式與英文有很大不同,首先中文分詞是個讓所有 NLP 從業(yè)者頭疼的事情,即便業(yè)界號稱能做到 95%左右的分詞準確性,但分詞結果極為不可控,往往會在分詞階段引入誤差。所以這里我們不分詞,而是仿照英文的處理方式,對應到中文的最小粒度就是單字了。(曾經(jīng)有人用偏旁部首切的,感興趣的朋友可以試試)
由于常用的單字為 1.5 萬左右,而常用的雙字大約到百萬級別了,所以這里出于向量空間的考慮,采用字向量(one-hot)作為輸入,向量空間約為 1.5 萬維。
特征提取層
三個全連接層,激活函數(shù)采用的是tanh,把維度降低到128
用 Wi 表示第 i 層的權值矩陣,bi 表示第 i 層的 bias 項。則第一隱層向量 l1(300 維),第 i 個隱層向量 li(300 維),輸出向量 y(128 維)可以分別表示為:

匹配層
Query 和 Doc 的語義相似性可以用這兩個語義向量(128 維) 的 cosine 距離(即余弦相似度) 來表示:
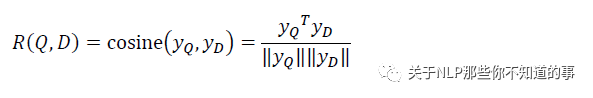
通過 softmax 函數(shù)可以把 Query 與正樣本 Doc 的語義相似性轉(zhuǎn)化為一個后驗概率:
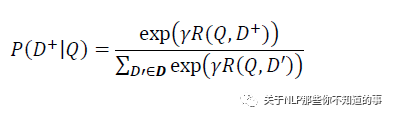
其中 r 為 softmax 的平滑因子,D 為 Query 下的正樣本,D-為 Query 下的負樣本(采取隨機負采樣),D 為 Query 下的整個樣本空間。
在訓練階段,通過極大似然估計,我們最小化損失函數(shù):
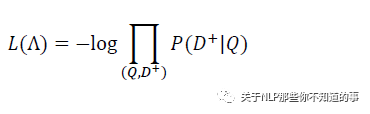
殘差會在表示層的 DNN 中反向傳播,最終通過隨機梯度下降(SGD)使模型收斂,得到各網(wǎng)絡層的參數(shù){Wi,bi}。
評價
優(yōu)點
減少切詞的依賴:解決了LSA、LDA、Autoencoder等方法存在的一個最大的問題,因為在英文單詞中,詞的數(shù)量可能是沒有限制,但是字母 n-gram 的數(shù)量通常是有限的
基于詞的特征表示比較難處理新詞,字母的 n-gram可以有效表示,魯棒性較強;
傳統(tǒng)的輸入層是用 Embedding 的方式(如 Word2Vec 的詞向量)或者主題模型的方式(如 LDA 的主題向量)來直接做詞的映射,再把各個詞的向量累加或者拼接起來,由于 Word2Vec 和 LDA 都是無監(jiān)督的訓練,這樣會給整個模型引入誤差,DSSM 采用統(tǒng)一的有監(jiān)督訓練,不需要在中間過程做無監(jiān)督模型的映射,因此精準度會比較高;
省去了人工的特征工程;
缺點
word hashing可能造成沖突
DSSM采用了詞袋模型,損失了上下文信息
在排序中,搜索引擎的排序由多種因素決定,由于用戶點擊時doc的排名越靠前,點擊的概率就越大,如果僅僅用點擊來判斷是否為正負樣本,噪聲比較大,難以收斂
參考
DSSM論文閱讀與總結
DSSM:深度語義匹配模型
文本匹配、文本相似度模型之DSSM