
【關(guān)于 GECToR】 那些你不知道的事
作者:楊夕
論文:GECToR–Grammatical Error Correction: Tag, Not Rewrite
會(huì)議:ACL2020
論文下載地址:chrome-extension://ikhdkkncnoglghljlkmcimlnlhkeamad/pdf-viewer/web/viewer.html?file=https%3A%2F%2Farxiv.org%2Fpdf%2F2005.12592.pdf#=&zoom=125
論文代碼:https://github.com/grammarly/gector
本文鏈接:https://github.com/km1994/nlp_paper_study
個(gè)人介紹:大佬們好,我叫楊夕,該項(xiàng)目主要是本人在研讀頂會(huì)論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯(cuò)誤,希望大佬們多多指正。
先介紹一下,自己為什么會(huì)讀這一篇文章,主要原因是自己正好 參加了 科大訊飛 舉辦的 CIEC-CTC 2021 中文文本糾錯(cuò)比賽,然后剛好該比賽的 baseline 就是 ctc_gector,所以就想了讀一下該文章,順便學(xué)習(xí)一下 文本糾錯(cuò)任務(wù)。
【注:手機(jī)閱讀可能圖片打不開!!!】
一、摘要
論文方法:提出了僅使用Transformer編碼器的簡(jiǎn)單有效的GEC序列標(biāo)注器。
論文思路:
首先是錯(cuò)誤的語料庫;
其次是有錯(cuò)誤和無錯(cuò)誤的平行語料庫的組合。
系統(tǒng)在綜合數(shù)據(jù)上進(jìn)行了預(yù)訓(xùn)練;
然后分兩個(gè)階段進(jìn)行了微調(diào):
我們?cè)O(shè)計(jì)了自定義的字符級(jí)別轉(zhuǎn)換,以將輸入字符映射到糾正后的目標(biāo)。
效果:
我們最好的單模型以及聯(lián)合模型GEC標(biāo)注器分別在CoNLL-2014測(cè)試集上F0.5達(dá)到65.3和66.5,在BEA-2019上F0.5達(dá)到72.4和73.6。模型的推理速度是基于Transformer的seq2seq GEC系統(tǒng)的10倍
二、論文背景
2.1 什么是 seq2seq?
背景:由于Seq2Seq在機(jī)器翻譯等領(lǐng)域的成功應(yīng)用,把這種方法用到類似的語法糾錯(cuò)問題上也是非常自然的想法。
seq2seq 的輸入輸出:
機(jī)器翻譯的輸入是源語言(比如英語),輸出是另外一個(gè)目標(biāo)語言(比如法語);
語法糾錯(cuò)的輸入是有語法錯(cuò)誤的句子,輸出是與之對(duì)應(yīng)的語法正確的句子;
區(qū)別:只在于機(jī)器翻譯的輸入輸出是不同的語言而語法糾錯(cuò)的輸入輸出是相同的語言。
2.2 Transformer 后 的 seq2seq ?
隨著 Transformer 在機(jī)器翻譯領(lǐng)域的成功,主流的語法糾錯(cuò)也都使用了 Transformer 來作為 Seq2Seq 模型的 Encoder 和 Decoder。
當(dāng)然隨著 BERT 等 Pretraining 模型的出現(xiàn),機(jī)器翻譯和語法糾錯(cuò)都使用了這些 Pretraining 的 Transformer 模型來作為初始化參數(shù),并且使用領(lǐng)域的數(shù)據(jù)進(jìn)行 Fine-Tuning。由于領(lǐng)域數(shù)據(jù)相對(duì) Pretraining 的無監(jiān)督數(shù)據(jù)量太少,最近合成的(synthetic)數(shù)據(jù)用于 Fine-tuning 變得流行起來。查看一下 nlpprogress 的 GEC 任務(wù) ,排行榜里的方法大多都是使用了BERT 等 Pretraining 的 Seq2Seq 模型。
三、論文動(dòng)機(jī)
3.1 什么是 GEC 系統(tǒng)?
3.1.1 基于 encoder-decoder 模型 GEC 系統(tǒng)
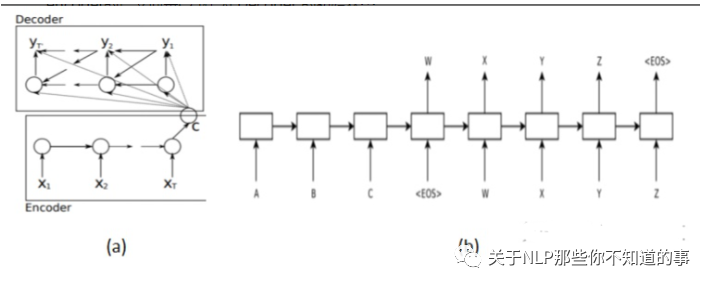
介紹:基于 NMT 自然還是要使用基于encoder-decoder 模型的 Seq2Seq。使用 RNN 作為核心網(wǎng)絡(luò);
結(jié)構(gòu):
用一個(gè) RNN (Encoder)輸入句子F編碼成一個(gè)固定長(zhǎng)度的向量;
用另一個(gè) RNN (Decoder)基于該向量進(jìn)行解碼,輸出糾正后的句子;
3.1.2 基于 attention 機(jī)制 GEC 系統(tǒng)
動(dòng)機(jī):RNN 對(duì)長(zhǎng)距離依賴的不敏感和“輸入的表示”(就是第5個(gè)模型中的壓緊處理), 輸入的表示問題相比于長(zhǎng)距離依賴問題更加嚴(yán)重。
eg:想象有兩個(gè)輸入句子,第一個(gè)僅包含3個(gè)單詞,第二個(gè)包含100個(gè)單詞,而encoder居然無差別地將它們都編碼成相同長(zhǎng)度的向量(比如說50維)。這一做法顯然存在問題,長(zhǎng)度為100的句子中很多信息可能被忽略了。
介紹:加入attention機(jī)制后,如果給 decoder 多提供了一個(gè)輸入“c”,在解碼序列的每一步中都讓“c”參與就可以緩解瓶頸問題。輸入序列中每個(gè)單詞對(duì) decoder 在不同時(shí)刻輸出單詞時(shí)的幫助作用不一樣,所以就需要提前計(jì)算一個(gè) attention score 作為權(quán)重分配給每個(gè)單詞,再將這些單詞對(duì)應(yīng)的 encoder output 帶權(quán)加在一起,就變成了此刻 decoder 的另一個(gè)輸入“c”。
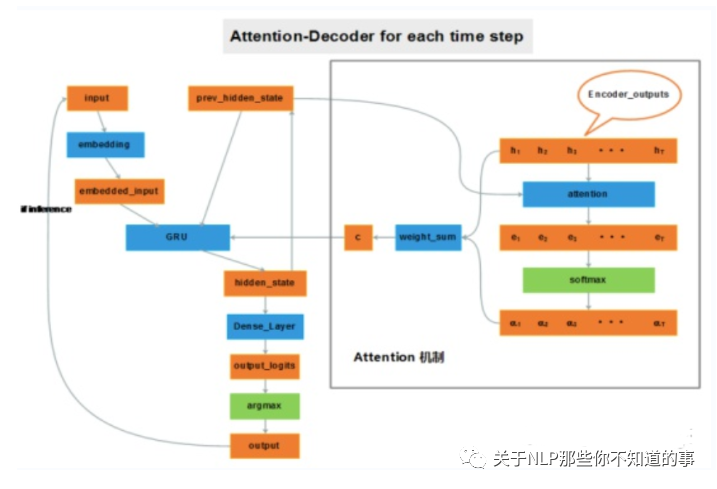
3.1.3 基于 Transformer-NMT 的 GEC 系統(tǒng)
介紹:基于 Transformer-NMT 自然還是要使用基于encoder-decoder 模型的 Seq2Seq。使用 Transformer 作為核心網(wǎng)絡(luò);
3.2 NMT-based GEC系統(tǒng) 存在 什么問題?
由于 NMT-based GEC系統(tǒng) 的 核心是 seq2seq 結(jié)構(gòu),所以在部署的時(shí)候會(huì)遇到以下問題:
緩慢的推理速度;
需要大量的訓(xùn)練數(shù)據(jù);
可解釋性,從而使他們需要其他功能來解釋更正,例如語法錯(cuò)誤類型分類;
四、論文介紹
4.1 論文解決 NMT-based GEC系統(tǒng) 問題的核心是什么?
將GEC任務(wù)從序列生成簡(jiǎn)化到序列標(biāo)注來解決 NMT-based GEC系統(tǒng) 問題
4.2 GEC 的 訓(xùn)練階段?
對(duì)合成數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練;
對(duì)有錯(cuò)誤的平行語料庫進(jìn)行微調(diào);
對(duì)有錯(cuò)誤和無錯(cuò)誤的平行語料庫的組合進(jìn)行微調(diào)。
4.3 NMT-based GEC 系統(tǒng) 與 GEC 在預(yù)測(cè)階段的區(qū)別?
NMT-based GEC 系統(tǒng):保留字符,刪除字符以及在字符之前添加短語;
GEC 系統(tǒng):解碼器是 softmax 層。PIE是一個(gè)迭代序列標(biāo)注 GEC 系統(tǒng),可預(yù)測(cè)字符級(jí)編輯操作。
4.4 NMT-based GEC 系統(tǒng) 與 GEC 的區(qū)別是什么?
開發(fā)自定義的 g-transformations:通過字符級(jí)編輯以執(zhí)行語法錯(cuò)誤糾正。預(yù)測(cè) g-transformations 而不是常規(guī)字符可改善 GEC 序列標(biāo)簽系統(tǒng)的通用性。
將微調(diào)階段分為兩個(gè)階段:
對(duì)僅錯(cuò)誤的句子進(jìn)行微調(diào);
然后對(duì)包含有錯(cuò)誤和無錯(cuò)誤句子的小型高質(zhì)量數(shù)據(jù)集進(jìn)行進(jìn)一步的微調(diào)。
通過在我們的GEC序列標(biāo)注系統(tǒng)中加入預(yù)訓(xùn)練的Transformer編碼器,可以實(shí)現(xiàn)卓越的性能。在實(shí)驗(yàn)中,XLNet和RoBERTa的編碼器的性能優(yōu)于其他三個(gè)Transformer編碼器(ALBERT,BERT和GPT-2)。
五、論文思路
5.1 Token-level transformations
包含 Basic transformations 和 g-transformations 兩種方法。
5.1.1 Basic transformations
保持不變、刪除、在目前的 token 后面添加一個(gè) token、將目前的 token 替換為另一個(gè) token
5.1.2 g-transformations
主要是一些具體的任務(wù),比如:改變大小寫、將當(dāng)前的token與下一個(gè)token合并、把目前的token分解為兩個(gè)、單數(shù)轉(zhuǎn)復(fù)數(shù)等等
5.1.3 數(shù)據(jù)預(yù)處理
要將任務(wù)作為序列標(biāo)注問題進(jìn)行處理,我們需要將每個(gè)目標(biāo)句子從訓(xùn)練/評(píng)估集中轉(zhuǎn)換為標(biāo)記序列,其中每個(gè)標(biāo)記都映射到單個(gè)源字符。下面是表3中針對(duì)顏色編碼的句子對(duì)的三步預(yù)處理算法的簡(jiǎn)要說明:
將源句子中的每個(gè)字符映射到目標(biāo)句子中的字符的子序列;
對(duì)于列表中的每個(gè)映射,需要找到將源字符轉(zhuǎn)換為目標(biāo)子序列的字符級(jí)別轉(zhuǎn)換;
每個(gè)源字符僅保留一個(gè)轉(zhuǎn)換
注:迭代序列標(biāo)記方法增加了一個(gè)約束,因?yàn)槲覀冎荒転槊總€(gè)字符使用單個(gè)標(biāo)記。如果有多個(gè)轉(zhuǎn)換,我們將采用第一個(gè)不是$KEEP標(biāo)記的轉(zhuǎn)換。
六、Tagging model architecture
GEC序列標(biāo)注模型是一種編碼器,由預(yù)訓(xùn)練的 BERT 型 transformer 組成,堆疊有兩個(gè)線性層,頂部有 softmax 層。
我們始終使用預(yù)訓(xùn)練 transformer 的 Base 配置。
Tokenization 取決于特定 transformer 的設(shè)計(jì):
BPE被用于RoBERTa;
BERT 使用 WordPiece;
XLNet 則使用 SentencePiece。
為了在字符級(jí)別處理信息,我們從編碼器表示中獲取每個(gè)字符的第一個(gè)子詞,然后將其傳遞到后續(xù)的線性層,這些線性層分別負(fù)責(zé)錯(cuò)誤檢測(cè)和錯(cuò)誤標(biāo)記。
七、Iterative sequence tagging approach
使用GEC sequence tagger標(biāo)注修改過的序列,然后再次糾正,以這樣的方式進(jìn)行迭代,保證盡可能地完全糾正句子。由于模型問題,一次迭代只能執(zhí)行一次編輯,但是很多錯(cuò)誤并不能由一次編輯來糾正,所以多次迭代具有相應(yīng)的科學(xué)性。
八、實(shí)戰(zhàn)
8.1 Requirements
python=3.6
torch==1.3.0
allennlp==0.8.4
python-Levenshtein==0.12.0
transformers==2.2.2
scikit-learn==0.20.0
sentencepiece==0.1.91
overrides==4.1.2
8.2 數(shù)據(jù)介紹
{"ID": "ID14347228", "source": "優(yōu)點(diǎn):反映科目之間的對(duì)應(yīng)關(guān)系,便于了解經(jīng)濟(jì)業(yè)務(wù)概況,辯于檢查和分析經(jīng)問濟(jì)業(yè)務(wù);", "target": "優(yōu)點(diǎn):反映科目之間的對(duì)應(yīng)關(guān)系,便于了解經(jīng)濟(jì)業(yè)務(wù)概況,便于檢查和分析經(jīng)濟(jì)業(yè)務(wù);"}
{"ID": "ID00558239", "source": "明武宗時(shí),宦官劉瑾被施刑,據(jù)說割天三夜。", "target": "明武宗時(shí),宦官劉瑾被施以此刑,據(jù)說割了三天三夜。"}
{"ID": "ID13767986", "source": "昌江出版集團(tuán)北京圖書中心總編輯、《狼圖騰》責(zé)任編輯安波舜這樣描述自己眼中的姜戎:67“如果他走在任何地方,沒有任何人會(huì)注意他。”", "target": "長(zhǎng)江出版集團(tuán)北京圖書中心總編輯、《狼圖騰》責(zé)任編輯安波舜這樣描述自己眼中的姜戎:67“如果他走在任何地方,沒有任何人會(huì)注意他。”"}
注:ID 為編號(hào);source 為 錯(cuò)誤句子;target 為 糾錯(cuò)后的句子
eg:source 中的 ”優(yōu)點(diǎn):反映科目之間的對(duì)應(yīng)關(guān)系,便于了解經(jīng)濟(jì)業(yè)務(wù)概況,辯于檢查和分析經(jīng)問濟(jì)業(yè)務(wù);” 加粗的詞是錯(cuò)誤的
target:“優(yōu)點(diǎn):反映科目之間的對(duì)應(yīng)關(guān)系,便于了解經(jīng)濟(jì)業(yè)務(wù)概況,便于檢查和分析經(jīng)濟(jì)業(yè)務(wù);”
8.3 操作
8.3.1 安裝依賴包
pip install -r requirements.txt
8.3.2 模型訓(xùn)練
將訓(xùn)練集train.json中數(shù)據(jù)分成兩個(gè)文件,train.src 和 train.tgt
使用tokenizer.py或其他工具將數(shù)據(jù)進(jìn)行分詞
使用預(yù)處理腳本將數(shù)據(jù)處理成 gecotr 需要的格式
python utils/preprocess_data.py -s SOURCE -t TARGET -o OUTPUT_FILE
使用stage1_bert_ctc2021.sh訓(xùn)練模型
8.3.3 模型推理
sh run_bert_ctc2021.sh
8.4 代碼細(xì)節(jié)學(xué)習(xí)
8.4.1 數(shù)據(jù)分隔
將訓(xùn)練集train.json中數(shù)據(jù)分成兩個(gè)文件,train.src和train.tgt,這里并沒有寫代碼,而是通過一些工具進(jìn)行分隔,所以不做介紹。
分隔后的數(shù)據(jù)
train.src
優(yōu)點(diǎn):反映科目之間的對(duì)應(yīng)關(guān)系,便于了解經(jīng)濟(jì)業(yè)務(wù)概況,辯于檢查和分析經(jīng)問濟(jì)業(yè)務(wù);
明武宗時(shí),宦官劉瑾被施刑,據(jù)說割天三夜。
昌江出版集團(tuán)北京圖書中心總編輯、《狼圖騰》責(zé)任編輯安波舜這樣描述自己眼中的姜戎:67“如果他走在任何地方,沒有任何人會(huì)注意他。”
train.tgt
優(yōu)點(diǎn):反映科目之間的對(duì)應(yīng)關(guān)系,便于了解經(jīng)濟(jì)業(yè)務(wù)概況,便于檢查和分析經(jīng)濟(jì)業(yè)務(wù);
明武宗時(shí),宦官劉瑾被施以此刑,據(jù)說割了三天三夜。
長(zhǎng)江出版集團(tuán)北京圖書中心總編輯、《狼圖騰》責(zé)任編輯安波舜這樣描述自己眼中的姜戎:67“如果他走在任何地方,沒有任何人會(huì)注意他。”
8.4.2 數(shù)據(jù)分詞
使用 Bert 中 tokenizer.py 將數(shù)據(jù)進(jìn)行分詞,調(diào)用 函數(shù):
# 功能:對(duì) 文件中句子 進(jìn)行 分詞
def segment_for_file(inp_file_name,onp_file_name):
with open(inp_file_name, encoding="utf-8",mode="r") as fr, open(onp_file_name, encoding="utf-8",mode="a+") as fw:
lines = fr.readlines()
for line in tqdm(lines):
line = tokenization.convert_to_unicode(line)
if not line:
print()
continue
tokens = tokenizer.tokenize(line)
line = ' '.join(tokens)
fw.write(f"{line}\n")
分詞后的數(shù)據(jù):
2 ##2 歲 的 威 廉 - 卡 瓦 略 已 經(jīng) 為 葡 萄 牙 國(guó) 家 隊(duì) 踢 了 兩 場(chǎng) 比 賽 了 , 他 在 20 ##1 ##3 年 11 月 1 ##9 日 葡 萄 牙 客 戰(zhàn) 瑞 典 的 生 死 戰(zhàn) 中 替 補(bǔ) 出 場(chǎng) 上 演 觸 子 秀 。
co ##ls ##pan = \ " 5 \ " style = \ " back ##ground - color : silver ;
...
8.4.3 Token-level transformations 使用預(yù)處理腳本將數(shù)據(jù)處理成 gecotr 需要的格式(訓(xùn)練數(shù)據(jù)格式)
包含 Basic transformations 和 g-transformations 兩種方法。
8.4.3.1 Basic transformations
保持不變、刪除、在目前的 token 后面添加一個(gè) token、將目前的 token 替換為另一個(gè) token
8.4.3.2 g-transformations
主要是一些具體的任務(wù),比如:改變大小寫、將當(dāng)前的token與下一個(gè)token合并、把目前的token分解為兩個(gè)、單數(shù)轉(zhuǎn)復(fù)數(shù)等等
8.4.3.3 數(shù)據(jù)預(yù)處理
要將任務(wù)作為序列標(biāo)注問題進(jìn)行處理,我們需要將每個(gè)目標(biāo)句子從訓(xùn)練/評(píng)估集中轉(zhuǎn)換為標(biāo)記序列,其中每個(gè)標(biāo)記都映射到單個(gè)源字符。下面是表3中針對(duì)顏色編碼的句子對(duì)的三步預(yù)處理算法的簡(jiǎn)要說明:
將源句子中的每個(gè)字符映射到目標(biāo)句子中的字符的子序列;
對(duì)于列表中的每個(gè)映射,需要找到將源字符轉(zhuǎn)換為目標(biāo)子序列的字符級(jí)別轉(zhuǎn)換;
每個(gè)源字符僅保留一個(gè)轉(zhuǎn)換
注:迭代序列標(biāo)記方法增加了一個(gè)約束,因?yàn)槲覀冎荒転槊總€(gè)字符使用單個(gè)標(biāo)記。如果有多個(gè)轉(zhuǎn)換,我們將采用第一個(gè)不是$KEEP標(biāo)記的轉(zhuǎn)換。
8.4.3.4 操作
$ python utils/preprocess_data.py -s SOURCE -t TARGET -o OUTPUT_FILE --chunk_size 1000000 -m 128
eg:
$ python utils/preprocess_data.py -s train.src -t train.tgt -o train.gecotr --chunk_size 1000000 -m 128
注:
-s:source 文件的位置
-t:target 文件的位置
-o:輸出文件的位置
--chunk_size:Dump each chunk size
-m:序列最大長(zhǎng)度
舉例說明
例子一:
source:'明 武 宗 時(shí) , 宦 官 劉 瑾 被 施 刑 , 據(jù) 說 割 天 三 夜 。'
target:'明 武 宗 時(shí) , 宦 官 劉 瑾 被 施 以 此 刑 , 據(jù) 說 割 了 三 天 三 夜 。'
>>>
編碼:'$STARTSEPL|||SEPR$KEEP 明SEPL|||SEPR$KEEP 武SEPL|||SEPR$KEEP 宗SEPL|||SEPR$KEEP 時(shí)SEPL|||SEPR$KEEP ,SEPL|||SEPR$KEEP 宦SEPL|||SEPR$KEEP 官SEPL|||SEPR$KEEP 劉SEPL|||SEPR$KEEP 瑾SEPL|||SEPR$KEEP 被SEPL|||SEPR$KEEP 施SEPL|||SEPR$APPEND_以SEPL__SEPR$APPEND_此 刑SEPL|||SEPR$KEEP ,SEPL|||SEPR$KEEP 據(jù)SEPL|||SEPR$KEEP 說SEPL|||SEPR$KEEP 割SEPL|||SEPR$APPEND_了SEPL__SEPR$APPEND_三 天SEPL|||SEPR$KEEP 三SEPL|||SEPR$KEEP 夜SEPL|||SEPR$KEEP 。SEPL|||SEPR$KEEP'
例子二:
source:'昌 江 出 版 集 團(tuán) 北 京 圖 書 中 心 總 編 輯 、 《 狼 圖 騰 》 責(zé) 任 編 輯 安 波 舜 這 樣 描 述 自 己 眼 中 的 姜 戎 :67 “ 如 果 他 走 在 任 何 地 方 , 沒 有 任 何 人 會(huì) 注 意 他 。”'
target:'長(zhǎng) 江 出 版 集 團(tuán) 北 京 圖 書 中 心 總 編 輯 、 《 狼 圖 騰 》 責(zé) 任 編 輯 安 波 舜 這 樣 描 述 自 己 眼 中 的 姜 戎 :67 “ 如 果 他 走 在 任 何 地 方 , 沒 有 任 何 人 會(huì) 注 意 他 。”'
>>>
編碼:'$STARTSEPL|||SEPR$KEEP 昌SEPL|||SEPR$REPLACE_長(zhǎng) 江SEPL|||SEPR$KEEP 出SEPL|||SEPR$KEEP 版SEPL|||SEPR$KEEP 集SEPL|||SEPR$KEEP 團(tuán)SEPL|||SEPR$KEEP 北SEPL|||SEPR$KEEP 京SEPL|||SEPR$KEEP 圖SEPL|||SEPR$KEEP 書SEPL|||SEPR$KEEP 中SEPL|||SEPR$KEEP 心SEPL|||SEPR$KEEP 總SEPL|||SEPR$KEEP 編SEPL|||SEPR$KEEP 輯SEPL|||SEPR$KEEP 、SEPL|||SEPR$KEEP 《SEPL|||SEPR$KEEP 狼SEPL|||SEPR$KEEP 圖SEPL|||SEPR$KEEP 騰SEPL|||SEPR$KEEP 》SEPL|||SEPR$KEEP 責(zé)SEPL|||SEPR$KEEP 任SEPL|||SEPR$KEEP 編SEPL|||SEPR$KEEP 輯SEPL|||SEPR$KEEP 安SEPL|||SEPR$KEEP 波SEPL|||SEPR$KEEP 舜SEPL|||SEPR$KEEP 這SEPL|||SEPR$KEEP 樣SEPL|||SEPR$KEEP 描SEPL|||SEPR$KEEP 述SEPL|||SEPR$KEEP 自SEPL|||SEPR$KEEP 己SEPL|||SEPR$KEEP 眼SEPL|||SEPR$KEEP 中SEPL|||SEPR$KEEP 的SEPL|||SEPR$KEEP 姜SEPL|||SEPR$KEEP 戎SEPL|||SEPR$KEEP :SEPL|||SEPR$KEEP 67SEPL|||SEPR$KEEP “SEPL|||SEPR$KEEP 如SEPL|||SEPR$KEEP 果SEPL|||SEPR$KEEP 他SEPL|||SEPR$KEEP 走SEPL|||SEPR$KEEP 在SEPL|||SEPR$KEEP 任SEPL|||SEPR$KEEP 何SEPL|||SEPR$KEEP 地SEPL|||SEPR$KEEP 方SEPL|||SEPR$KEEP ,SEPL|||SEPR$KEEP 沒SEPL|||SEPR$KEEP 有SEPL|||SEPR$KEEP 任SEPL|||SEPR$KEEP 何SEPL|||SEPR$KEEP 人SEPL|||SEPR$KEEP 會(huì)SEPL|||SEPR$KEEP 注SEPL|||SEPR$KEEP 意SEPL|||SEPR$KEEP 他SEPL|||SEPR$KEEP 。SEPL|||SEPR$KEEP ”SEPL|||SEPR$KEEP'
例子三:
source:'此 片 的 電 視 斑 ( 収 僂 迪 士 尼 頻 道 播 版 本 ) 是 從 戲 院 版 剪 接 的 版 本 。'
target:'此 片 的 電 視 版 ( 也 就 是 于 迪 士 尼 頻 道 播 出 的 版 本 ) 是 從 戲 院 版 剪 接 的 版 本 。'
>>>
編碼:'$STARTSEPL|||SEPR$KEEP 此SEPL|||SEPR$KEEP 片SEPL|||SEPR$KEEP 的SEPL|||SEPR$KEEP 電SEPL|||SEPR$KEEP 視SEPL|||SEPR$KEEP 斑SEPL|||SEPR$REPLACE_版 (SEPL|||SEPR$KEEP 収SEPL|||SEPR$REPLACE_也 僂SEPL|||SEPR$REPLACE_就SEPL__SEPR$APPEND_是SEPL__SEPR$APPEND_于 迪SEPL|||SEPR$KEEP 士SEPL|||SEPR$KEEP 尼SEPL|||SEPR$KEEP 頻SEPL|||SEPR$KEEP 道SEPL|||SEPR$KEEP 播SEPL|||SEPR$APPEND_出SEPL__SEPR$APPEND_的 版SEPL|||SEPR$KEEP 本SEPL|||SEPR$KEEP )SEPL|||SEPR$KEEP 是SEPL|||SEPR$KEEP 從SEPL|||SEPR$KEEP 戲SEPL|||SEPR$KEEP 院SEPL|||SEPR$KEEP 版SEPL|||SEPR$KEEP 剪SEPL|||SEPR$KEEP 接SEPL|||SEPR$KEEP 的SEPL|||SEPR$KEEP 版SEPL|||SEPR$KEEP 本SEPL|||SEPR$KEEP 。SEPL|||SEPR$KEEP'
8.4.4 Tagging model architecture
GEC序列標(biāo)注模型是一種編碼器,由預(yù)訓(xùn)練的 BERT 型 transformer 組成,堆疊有兩個(gè)線性層,頂部有 softmax 層。
我們始終使用預(yù)訓(xùn)練 transformer 的 Base 配置。
Tokenization 取決于特定 transformer 的設(shè)計(jì):
BPE被用于RoBERTa;
BERT 使用 WordPiece;
XLNet 則使用 SentencePiece。
為了在字符級(jí)別處理信息,我們從編碼器表示中獲取每個(gè)字符的第一個(gè)子詞,然后將其傳遞到后續(xù)的線性層,這些線性層分別負(fù)責(zé)錯(cuò)誤檢測(cè)和錯(cuò)誤標(biāo)記。
"""Basic model. Predicts tags for every token"""
from typing import Dict, Optional, List, Any
import numpy
import torch
import torch.nn.functional as F
from allennlp.data import Vocabulary
from allennlp.models.model import Model
from allennlp.modules import TimeDistributed, TextFieldEmbedder
from allennlp.nn import InitializerApplicator, RegularizerApplicator
from allennlp.nn.util import get_text_field_mask, sequence_cross_entropy_with_logits
from allennlp.training.metrics import CategoricalAccuracy
from overrides import overrides
from torch.nn.modules.linear import Linear
@Model.register("seq2labels")
class Seq2Labels(Model):
"""
This ``Seq2Labels`` simply encodes a sequence of text with a stacked ``Seq2SeqEncoder``, then
predicts a tag (or couple tags) for each token in the sequence.
Parameters
----------
vocab : ``Vocabulary``, required
A Vocabulary, required in order to compute sizes for input/output projections.
text_field_embedder : ``TextFieldEmbedder``, required
Used to embed the ``tokens`` ``TextField`` we get as input to the model.
encoder : ``Seq2SeqEncoder``
The encoder (with its own internal stacking) that we will use in between embedding tokens
and predicting output tags.
calculate_span_f1 : ``bool``, optional (default=``None``)
Calculate span-level F1 metrics during training. If this is ``True``, then
``label_encoding`` is required. If ``None`` and
label_encoding is specified, this is set to ``True``.
If ``None`` and label_encoding is not specified, it defaults
to ``False``.
label_encoding : ``str``, optional (default=``None``)
Label encoding to use when calculating span f1.
Valid options are "BIO", "BIOUL", "IOB1", "BMES".
Required if ``calculate_span_f1`` is true.
label_namespace : ``str``, optional (default=``labels``)
This is needed to compute the SpanBasedF1Measure metric, if desired.
Unless you did something unusual, the default value should be what you want.
verbose_metrics : ``bool``, optional (default = False)
If true, metrics will be returned per label class in addition
to the overall statistics.
initializer : ``InitializerApplicator``, optional (default=``InitializerApplicator()``)
Used to initialize the model parameters.
regularizer : ``RegularizerApplicator``, optional (default=``None``)
If provided, will be used to calculate the regularization penalty during training.
"""
def __init__(self, vocab: Vocabulary,
text_field_embedder: TextFieldEmbedder,
predictor_dropout=0.0,
labels_namespace: str = "labels",
detect_namespace: str = "d_tags",
verbose_metrics: bool = False,
label_smoothing: float = 0.0,
confidence: float = 0.0,
initializer: InitializerApplicator = InitializerApplicator(),
regularizer: Optional[RegularizerApplicator] = None) -> None:
super(Seq2Labels, self).__init__(vocab, regularizer)
self.label_namespaces = [labels_namespace,
detect_namespace]
self.text_field_embedder = text_field_embedder
self.num_labels_classes = self.vocab.get_vocab_size(labels_namespace)
self.num_detect_classes = self.vocab.get_vocab_size(detect_namespace)
self.label_smoothing = label_smoothing
self.confidence = confidence
self.incorr_index = self.vocab.get_token_index("INCORRECT",
namespace=detect_namespace)
self._verbose_metrics = verbose_metrics
self.predictor_dropout = TimeDistributed(torch.nn.Dropout(predictor_dropout))
self.tag_labels_projection_layer = TimeDistributed(
Linear(text_field_embedder._token_embedders['bert'].get_output_dim(), self.num_labels_classes))
self.tag_detect_projection_layer = TimeDistributed(
Linear(text_field_embedder._token_embedders['bert'].get_output_dim(), self.num_detect_classes))
self.metrics = {"accuracy": CategoricalAccuracy()}
initializer(self)
@overrides
def forward(self, # type: ignore
tokens: Dict[str, torch.LongTensor],
labels: torch.LongTensor = None,
d_tags: torch.LongTensor = None,
metadata: List[Dict[str, Any]] = None) -> Dict[str, torch.Tensor]:
# pylint: disable=arguments-differ
"""
Parameters
----------
tokens : Dict[str, torch.LongTensor], required
The output of ``TextField.as_array()``, which should typically be passed directly to a
``TextFieldEmbedder``. This output is a dictionary mapping keys to ``TokenIndexer``
tensors. At its most basic, using a ``SingleIdTokenIndexer`` this is: ``{"tokens":
Tensor(batch_size, num_tokens)}``. This dictionary will have the same keys as were used
for the ``TokenIndexers`` when you created the ``TextField`` representing your
sequence. The dictionary is designed to be passed directly to a ``TextFieldEmbedder``,
which knows how to combine different word representations into a single vector per
token in your input.
lables : torch.LongTensor, optional (default = None)
A torch tensor representing the sequence of integer gold class labels of shape
``(batch_size, num_tokens)``.
d_tags : torch.LongTensor, optional (default = None)
A torch tensor representing the sequence of integer gold class labels of shape
``(batch_size, num_tokens)``.
metadata : ``List[Dict[str, Any]]``, optional, (default = None)
metadata containing the original words in the sentence to be tagged under a 'words' key.
Returns
-------
An output dictionary consisting of:
logits : torch.FloatTensor
A tensor of shape ``(batch_size, num_tokens, tag_vocab_size)`` representing
unnormalised log probabilities of the tag classes.
class_probabilities : torch.FloatTensor
A tensor of shape ``(batch_size, num_tokens, tag_vocab_size)`` representing
a distribution of the tag classes per word.
loss : torch.FloatTensor, optional
A scalar loss to be optimised.
"""
# 由預(yù)訓(xùn)練的 BERT 型 transformer 組成
encoded_text = self.text_field_embedder(tokens)
batch_size, sequence_length, _ = encoded_text.size()
mask = get_text_field_mask(tokens)
# 堆疊有兩個(gè)線性層
logits_labels = self.tag_labels_projection_layer(self.predictor_dropout(encoded_text))
logits_d = self.tag_detect_projection_layer(encoded_text)
# softmax 層
class_probabilities_labels = F.softmax(logits_labels, dim=-1).view(
[batch_size, sequence_length, self.num_labels_classes])
class_probabilities_d = F.softmax(logits_d, dim=-1).view(
[batch_size, sequence_length, self.num_detect_classes])
error_probs = class_probabilities_d[:, :, self.incorr_index] * mask
incorr_prob = torch.max(error_probs, dim=-1)[0]
#if self.confidence > 0:
# FIXME
probability_change = [self.confidence] + [0] * (self.num_labels_classes - 1)
class_probabilities_labels += torch.cuda.FloatTensor(probability_change).repeat(
(batch_size, sequence_length, 1))
output_dict = {"logits_labels": logits_labels,
"logits_d_tags": logits_d,
"class_probabilities_labels": class_probabilities_labels,
"class_probabilities_d_tags": class_probabilities_d,
"max_error_probability": incorr_prob}
if labels is not None and d_tags is not None:
loss_labels = sequence_cross_entropy_with_logits(logits_labels, labels, mask,
label_smoothing=self.label_smoothing)
loss_d = sequence_cross_entropy_with_logits(logits_d, d_tags, mask)
for metric in self.metrics.values():
metric(logits_labels, labels, mask.float())
metric(logits_d, d_tags, mask.float())
output_dict["loss"] = loss_labels + loss_d
if metadata is not None:
output_dict["words"] = [x["words"] for x in metadata]
return output_dict
@overrides
def decode(self, output_dict: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]:
"""
Does a simple position-wise argmax over each token, converts indices to string labels, and
adds a ``"tags"`` key to the dictionary with the result.
"""
for label_namespace in self.label_namespaces:
all_predictions = output_dict[f'class_probabilities_{label_namespace}']
all_predictions = all_predictions.cpu().data.numpy()
if all_predictions.ndim == 3:
predictions_list = [all_predictions[i] for i in range(all_predictions.shape[0])]
else:
predictions_list = [all_predictions]
all_tags = []
for predictions in predictions_list:
argmax_indices = numpy.argmax(predictions, axis=-1)
tags = [self.vocab.get_token_from_index(x, namespace=label_namespace)
for x in argmax_indices]
all_tags.append(tags)
output_dict[f'{label_namespace}'] = all_tags
return output_dict
@overrides
def get_metrics(self, reset: bool = False) -> Dict[str, float]:
metrics_to_return = {metric_name: metric.get_metric(reset) for
metric_name, metric in self.metrics.items()}
return metrics_to_return
參考
GECToR語法糾錯(cuò)算法
GECToR–Grammatical Error Correction: Tag, Not Rewrite翻譯
《GECToR -- Grammatical Error Correction: Tag, Not Rewrite》論文筆記
基于神經(jīng)機(jī)器翻譯(NMT)的語法糾錯(cuò)