
【關(guān)于 EDA 】那些你不知道的事
作者:楊夕
面筋地址:https://github.com/km1994/NLP-Interview-Notes
個人筆記:https://github.com/km1994/nlp_paper_study
個人介紹:大佬們好,我叫楊夕,該項目主要是本人在研讀頂會論文和復(fù)現(xiàn)經(jīng)典論文過程中,所見、所思、所想、所聞,可能存在一些理解錯誤,希望大佬們多多指正。
【注:手機(jī)閱讀可能圖片打不開!!!】
目錄
一、動機(jī)篇
1.1 什么是 數(shù)據(jù)增強(qiáng)?
數(shù)據(jù)增強(qiáng) 是通過采用一些策略 增加 訓(xùn)練樣本的數(shù)據(jù)量,提高模型的訓(xùn)練效果。
1.2 為什么需要 數(shù)據(jù)增強(qiáng)?
在醫(yī)療、金融、法律等領(lǐng)域,高質(zhì)量的標(biāo)注數(shù)據(jù)十分稀缺、昂貴,我們通常面臨少樣本低資源問題。
二、常見的數(shù)據(jù)增強(qiáng)方法篇
2.1 詞匯替換篇
2.1.1 什么是基于詞典的替換方法?
介紹:基于同義詞替換的方法是從句子中以一定的概率隨機(jī)選取一個單詞,利用一些同義詞數(shù)據(jù)庫(注:英文可以用 WordNet 數(shù)據(jù)庫,中文可以用 synonyms python 同義詞詞典) 將其替換成對應(yīng)的同義詞。
舉例說明:

注:對 句子 “我 喜歡 NLP ” 隨機(jī)選取 其中一個詞 利用 synonyms 包進(jìn)行替換,可以替換為 “我 喜愛 NLP ”。
2.1.2 什么是基于詞向量的替換方法?
介紹:通過利用預(yù)先訓(xùn)練好的詞向量(eg:Word2Vec、GloVe、FastText等),使用嵌入空間中最近的相鄰單詞替換句子中的某些單詞。
思路:
預(yù)先訓(xùn)練好的詞向量(eg:Word2Vec、GloVe、FastText等);
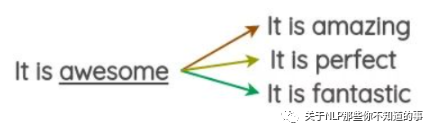
使用嵌入空間中最近的相鄰單詞,如下圖,在嵌入空間中,與詞 “awesome” 最近的相鄰單詞為 amazing、perfect等

隨機(jī)選取三個 與 詞 “awesome” 最相近的單詞替換 詞 “awesome”,如下圖:
實現(xiàn):
import synonyms
# 功能:同義詞替換,替換一個語句中的n個單詞為其同義詞
def synonym_replacement(words, alpha, num_words, stop_words):
n = max(1, int(alpha * num_words))
new_words = words.copy()
random_word_list = list(set([word for word in words if word not in stop_words]))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(synonyms)
new_words = [synonym if word == random_word else word for word in new_words]
num_replaced += 1
if num_replaced >= n:
break
sentence = ' '.join(new_words)
new_words = sentence.split(' ')
return new_words
# 功能:獲取與 word 最相近的同義詞
def get_synonyms(word):
return synonyms.nearby(word)[0]
2.1.3 什么是基于 MLM 的替換方法?
介紹:像BERT、ROBERTA和ALBERT這樣的Transformer模型已經(jīng)接受了大量的文本訓(xùn)練,使用一種稱為“Masked Language Modeling”的預(yù)訓(xùn)練,即模型必須根據(jù)上下文來預(yù)測遮蓋的詞匯。這可以用來擴(kuò)充一些文本。例如,我們可以使用一個預(yù)訓(xùn)練的BERT模型并屏蔽文本的某些部分。然后,我們使用BERT模型來預(yù)測遮蔽掉的token。
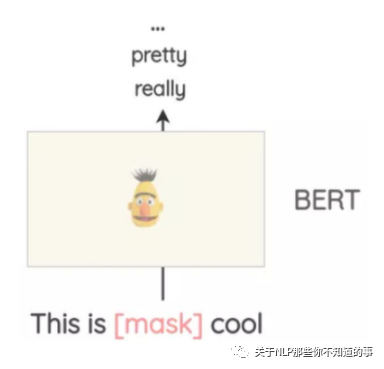
使用mask預(yù)測來生成文本的變體。與之前的方法相比,生成的文本在語法上更加連貫,因為模型在進(jìn)行預(yù)測時考慮了上下文。
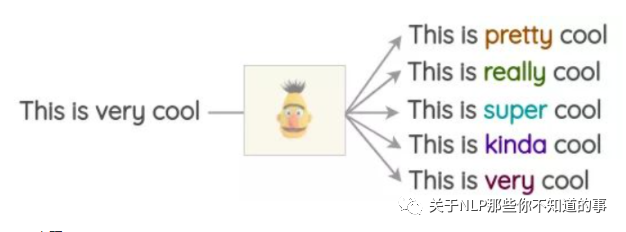
實現(xiàn):
注:使用開源庫這很容易實現(xiàn),如Hugging Face的transformers。你可以將你想要替換的token設(shè)置為并生成預(yù)測。
from transformers import pipeline
nlp = pipeline('fill-mask')
nlp('This is <mask> cool')
[{'score': 0.515411913394928,
'sequence': '<s> This is pretty cool</s>',
'token': 1256},
{'score': 0.1166248694062233,
'sequence': '<s> This is really cool</s>',
'token': 269},
{'score': 0.07387523353099823,
'sequence': '<s> This is super cool</s>',
'token': 2422},
{'score': 0.04272908344864845,
'sequence': '<s> This is kinda cool</s>',
'token': 24282},
{'score': 0.034715913236141205,
'sequence': '<s> This is very cool</s>',
'token': 182}]
注:這種方法的一個問題是,決定要屏蔽文本的哪一部分并不是一件小事。你必須使用啟發(fā)式的方法來決定掩碼,否則生成的文本將不保留原句的含義。
2.1.4 什么是基于 TF-IDF 的詞替換?
動機(jī):對于 query 里面 TF-IDF 值較小的詞語,一般對 query 的貢獻(xiàn)度較少
基本思想:針對 TF-IDF值較低的詞語貢獻(xiàn)度低問題,所以在不影響句子所屬類別的情況下替換,可以達(dá)到數(shù)據(jù)增強(qiáng)的作用。

2.2 詞匯插入篇
2.2.1 什么是隨機(jī)插入法?
方法:通過在 query 里面隨機(jī)插入一個或多個新詞匯、相應(yīng)的拼寫錯誤、符號等噪聲的方式提高 訓(xùn)練模型的健壯性。
代碼實現(xiàn):
import random
import synonyms
# 功能:隨機(jī)插入,隨機(jī)在語句中插入n個詞
def random_insertion(words, alpha, num_words, stop_words):
n = max(1, int(alpha * num_words))
new_words = words.copy()
for _ in range(n):
self.add_word(new_words)
return new_words
# 功能:插入新詞
def add_word(new_words):
synonyms = []
counter = 0
while len(synonyms) < 1:
random_word = new_words[random.randint(0, len(new_words)-1)]
synonyms = get_synonyms(random_word)
counter += 1
if counter >= 10:
return
random_synonym = random.choice(synonyms)
random_idx = random.randint(0, len(new_words)-1)
new_words.insert(random_idx, random_synonym)
# 功能:獲取同義詞
def get_synonyms(word):
return synonyms.nearby(word)[0]
2.3 詞匯交換篇
2.3.1 什么是隨機(jī)交換法?
方法:通過在 query 里面隨機(jī)交換一個或多個詞匯的方式提高 訓(xùn)練模型的健壯性。
代碼實現(xiàn):
import random
# 功能:隨機(jī)交換:隨機(jī)交換句子中的兩個詞
def random_swap(words, alpha, num_words, stop_words):
n = max(1, int(alpha * num_words))
new_words = words.copy()
for _ in range(n):
new_words = swap_word(new_words)
return new_words
# 功能:隨機(jī)交換兩個詞
def swap_word(new_words):
random_idx_1 = random.randint(0, len(new_words)-1)
random_idx_2 = random_idx_1
counter = 0
while random_idx_2 == random_idx_1:
random_idx_2 = random.randint(0, len(new_words)-1)
counter += 1
if counter > 3:
return new_words
new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
return new_words
2.4 詞匯刪除篇
2.4.1 什么是隨機(jī)刪除法?
方法:通過在 query 里面隨機(jī)刪除一個或多個詞匯的方式提高 訓(xùn)練模型的健壯性。
代碼實現(xiàn):
import random
# 功能:隨機(jī)刪除,以概率p刪除語句中的詞
def random_deletion( words, alpha, num_words, stop_words):
if len(words) == 1:
return words
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > alpha:
new_words.append(word)
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return new_words
2.5 回譯篇
2.5.1 什么是回譯法?
方法:利用百度翻譯、谷歌翻譯等在線翻譯器來解釋文本,并重新訓(xùn)練文本;
思路:
將待數(shù)據(jù)增強(qiáng)的句子(如中文句子)翻譯成另外一種語言,如英語、日語等;
然后將翻譯后的句子回譯回中文句子;
檢查新句子是否與原來的句子不同。如果是,那么我們使用這個新句子作為原始文本的數(shù)據(jù)增強(qiáng)。

2.6 交叉增強(qiáng)篇
2.6.1 什么是 交叉增強(qiáng)篇
方法:借鑒遺傳學(xué)中染色體交叉操作的方式進(jìn)行數(shù)據(jù)增強(qiáng)。
思路:將 tweets 切分未為兩部分,兩個具有相同極性的隨機(jī)推文(即正面/負(fù)面)進(jìn)行交換。這個方法的假設(shè)是,即使結(jié)果是不符合語法和語義的,新文本仍將保留情感的極性。
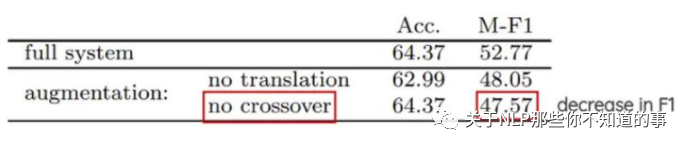
實驗結(jié)果分析:這一技術(shù)對準(zhǔn)確性沒有影響,但有助于論文中極少數(shù)類的F1分?jǐn)?shù),如tweets較少的中性類。
2.7 語法樹篇
2.7.1 什么是語法樹操作?
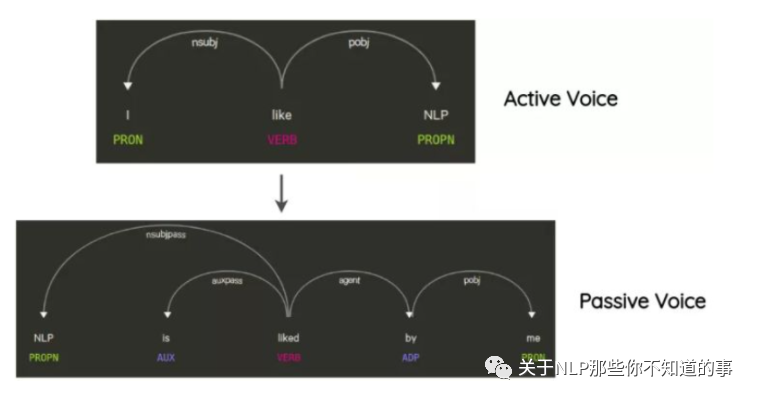
思路:這項技術(shù)已經(jīng)在Coulombe的論文中使用。其思想是解析和生成原始句子的依賴關(guān)系樹,使用規(guī)則對其進(jìn)行轉(zhuǎn)換,并生成改寫后的句子。
舉例說明:在不改變句子的含義的情況下將句子從主動轉(zhuǎn)化為被動語態(tài)的方式,也是一種數(shù)據(jù)增強(qiáng)方式。
實現(xiàn)方式:要使用上述所有方法,可以使用名為nlpaug的python庫:https://github.com/makcedward/nlpaug。它提供了一個簡單且一致的API來應(yīng)用這些技術(shù)。
2.8 對抗增強(qiáng)篇
2.8.1 什么是對抗增強(qiáng)?
方法:NLP中通常在詞向量上添加擾動并進(jìn)行對抗訓(xùn)練,文獻(xiàn)[10]NLP中的對抗訓(xùn)練方法FGM, PGD, FreeAT, YOPO, FreeLB等進(jìn)行了總結(jié)。
參考
NLP中數(shù)據(jù)增強(qiáng)的綜述,快速的生成大量的訓(xùn)練數(shù)據(jù)