ECCV 2020 谷歌論文盤點—Poster 篇
點擊上方“小白學(xué)視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
今天盤點Poster中的谷歌論文,總計27篇,從這些論文中可看出,谷歌很重視自動駕駛,多篇論文為自動駕駛領(lǐng)域,目標檢測、NAS、數(shù)據(jù)增廣方法等也是研究的重點。
下載所有ECCV 2020 請點這里:
論文相關(guān)代碼已列出,歡迎感興趣的朋友參考。
弱監(jiān)督、視頻理解
[2].Uncertainty-Aware Weakly Supervised Action Detection from Untrimmed Videos
作者?|?Anurag Arnab,?Chen Sun,?Arsha Nagrani,?Cordelia Schmid
單位 | 谷歌
論文?|?https://arxiv.org/abs/2007.10703
備注 |?ECCV?2020
針對未裁剪的視頻提出一種不確定性感知的弱監(jiān)督動作檢測算法。
[3].Beyond Controlled Environments: 3D Camera Re-Localization in Changing Indoor Scenes
作者?|?Johanna Wald,?Torsten Sattler,?Stuart Golodetz,?Tommaso Cavallari,?Federico Tombari
單位 | 慕尼黑工業(yè)大學(xué);查爾姆斯理工大學(xué);捷克理工大學(xué);Five AI Ltd;谷歌
論文?|?https://arxiv.org/abs/2008.02004
主頁 |?https://waldjohannau.github.io/RIO10/
備注 |?ECCV?2020
該文提出一種超越受控環(huán)境的室內(nèi)場景變化中的3D攝像機重定位方法。
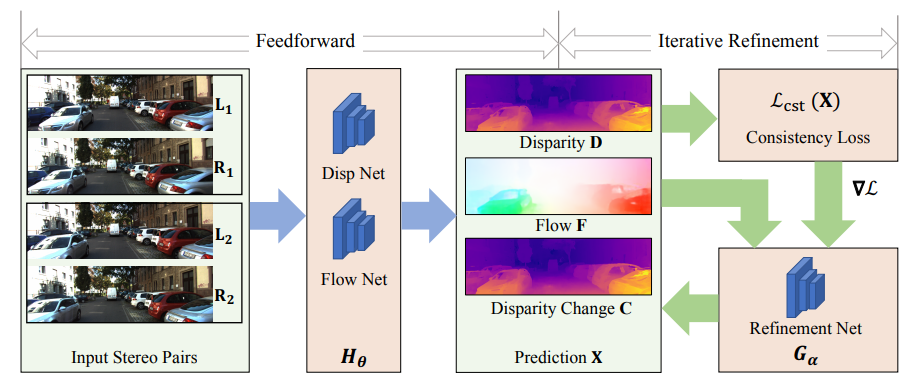
[4].Consistency Guided Scene Flow Estimation
作者?|?Yuhua Chen, Luc Van Gool, Cordelia Schmid, Cristian Sminchisescu
單位 | 谷歌,ETH Zurich
論文?|?https://arxiv.org/abs/2006.11242
備注 |?ECCV?2020
該文提出一種自監(jiān)督學(xué)習(xí)框架,從立體視頻中重建三維場景結(jié)構(gòu)和運動。
[5].Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections
作者?|?Theodora Kontogianni,?Michael Gygli,?Jasper Uijlings,?Vittorio Ferrari
單位 | 谷歌,亞琛工業(yè)大學(xué)
論文?|?https://arxiv.org/abs/1911.12709
備注 |?ECCV?2020
一種從用戶校正操作中學(xué)習(xí)得到的交互式土體分割方法。
人體姿態(tài)估計
[6].SimPose: Effectively Learning DensePose and Surface Normals of People from Simulated Data
作者?|?Tyler Zhu, Per Karlsson, Christoph Bregler
單位 | 谷歌
論文?|?https://arxiv.org/abs/2007.15506
備注 |?ECCV?2020
對人體進行密集2.5D DensePose 和3D表面法向標注是非常昂貴的,該文提出一種從模擬數(shù)據(jù)經(jīng)域適應(yīng)技術(shù)進行真人密集姿態(tài)估計和表面法向量計算的方法,大幅降低了成本取得了不錯的效果。

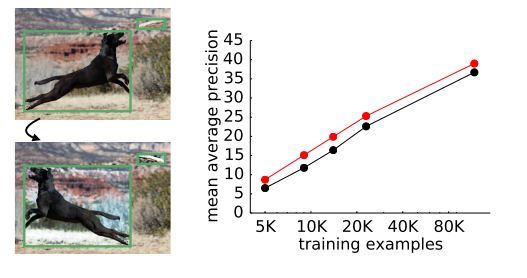
[7].Learning Data Augmentation Strategies for Object Detection
作者?|?Barret Zoph,?Ekin D. Cubuk,?Golnaz Ghiasi,?Tsung-Yi Lin,?Jonathon Shlens,?Quoc V. Le
單位 | 谷歌
論文?|?https://arxiv.org/abs/1906.11172
代碼 |?https://github.com/tensorflow/tpu/tree/master/
models/official/detection
備注 |?ECCV?2020
數(shù)據(jù)增廣是如此重要,已經(jīng)獲得大量研究者的關(guān)注,但作者發(fā)現(xiàn)對于圖像分類有效的增廣策略對目標檢測的提升是有限的,于是作者提出一重可學(xué)習(xí)的用于目標檢測特定任務(wù)的增廣方法,實驗中取得了2.3mAP的提升,而且將這種策略直接用于其他數(shù)據(jù)集,同樣獲得了2.7mAP的提升,證明這種方法推廣性很好。
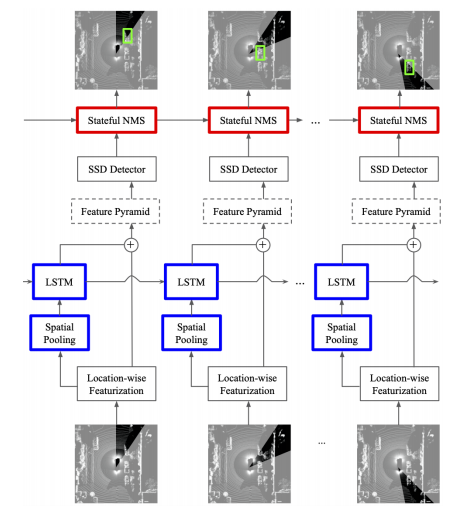
[8].Streaming Object Detection for 3-D Point Clouds
作者?|?Wei Han, Zhengdong Zhang, Benjamin Caine, Brandon Yang, Christoph Sprunk, Ouais Alsharif, Jiquan Ngiam, Vijay Vasudevan, Jonathon Shlens, Zhifeng Chen
單位 | 谷歌,Waymo
論文?|?https://arxiv.org/abs/2005.01864
備注 |?ECCV?2020
不同于RGB成像的相機,需要獲得全部數(shù)據(jù)再進行后一步處理,這在自動駕駛汽車中會造成一定的延遲,該文針對激光雷達信號采集的流式的特點,設(shè)計一種流式目標檢測的算法,降低了系統(tǒng)延遲。
[9].Improving 3D Object Detection through Progressive Population Based Augmentation
作者?|?Shuyang Cheng, Zhaoqi Leng, Ekin Dogus Cubuk, Barret Zoph, Chunyan Bai, Jiquan Ngiam, Yang Song, Benjamin Caine, Vijay Vasudevan, Congcong Li, Quoc V. Le, Jonathon Shlens, Dragomir Anguelov
單位 | Waymo LLC;谷歌
論文?|?https://arxiv.org/abs/2004.00831
備注 |?ECCV?2020
針對點云數(shù)據(jù)的目標檢測的數(shù)據(jù)增廣方法。
3D目標檢測,LSTM,點云
[10].An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds
作者?|?Rui Huang, Wanyue Zhang, Abhijit Kundu, Caroline Pantofaru, David A Ross, Thomas Funkhouser, Alireza Fathi
單位 | 谷歌
論文?|?https://arxiv.org/abs/2007.12392
主頁 |?https://sites.google.com/view/lstm-3d-detection/home
備注 |?ECCV?2020
再點云數(shù)據(jù)中,基于LSTM的時序3D目標檢測方法。
AutoML,NAS
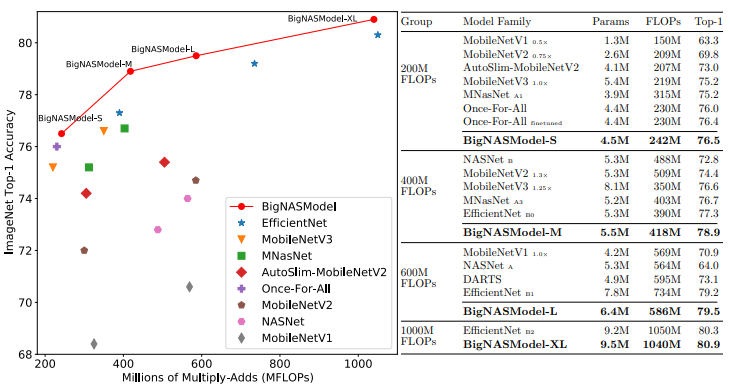
[11].BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
作者?|?Jiahui Yu, Pengchong Jin, Hanxiao Liu, Gabriel Bender, Pieter-Jan Kindermans, Mingxing Tan, Thomas Huang, Xiaodan Song, Ruoming Pang, Quoc Le
單位 | 谷歌,University of Illinois at Urbana-Champaign
論文?|?https://arxiv.org/abs/2003.11142
備注 |?ECCV?2020
在NAS中一次搜索訓(xùn)練,得到多個不需要重訓(xùn)練或后處理的子模型,并且這些子模型精度超越了EfficientNets 和 Once-for-All?網(wǎng)絡(luò)等工作。
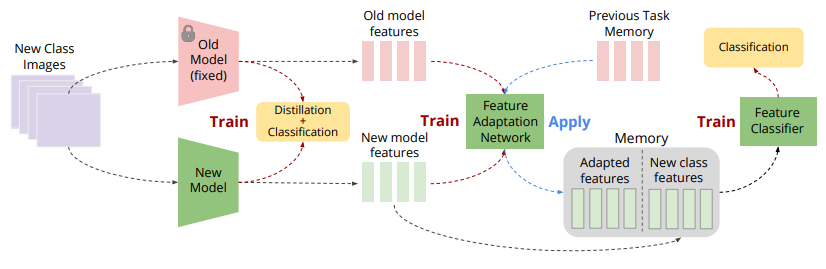
[12].Memory-Efficient Incremental Learning Through Feature Adaptation
作者?|?Ahmet Iscen, Jeffrey Zhang, Svetlana Lazebnik, Cordelia Schmid
單位 | 谷歌
論文?|?https://arxiv.org/abs/2004.00713
備注 |?ECCV?2020
基于特征適應(yīng)的內(nèi)存高效的增量學(xué)習(xí)法方法。
[13].Virtual Multi-view Fusion for 3D Semantic Segmentation
作者?|?Abhijit Kundu, Xiaoqi Yin, Alireza Fathi, David Ross, Brian Brewington, Thomas Funkhouser, Caroline Pantofaru
單位 | 谷歌
論文?|?https://arxiv.org/abs/2007.13138
主頁 |?https://abhijitkundu.info/projects/multiview_segmentation/
備注 |?ECCV?2020
虛擬多視圖融合用于3D語義分割。
目標檢測
[14].Efficient Scale-Permuted Backbone with Learned Resource Distribution
作者?|?Xianzhi Du, Tsung-Yi Lin, Pengchong Jin, Yin Cui Mingxing Tan, Quoc Le, and Xiaodan Song
單位 | 谷歌
論文?|?https://www.ecva.net/papers/eccv_2020/
papers_ECCV/papers/123680562.pdf
備注 |?ECCV?2020
使用NAS搜索得到目標檢測的骨干網(wǎng)絡(luò),在檢測任務(wù)中超越EfficientDet,在分類、語義分割中也取得了不錯效果。
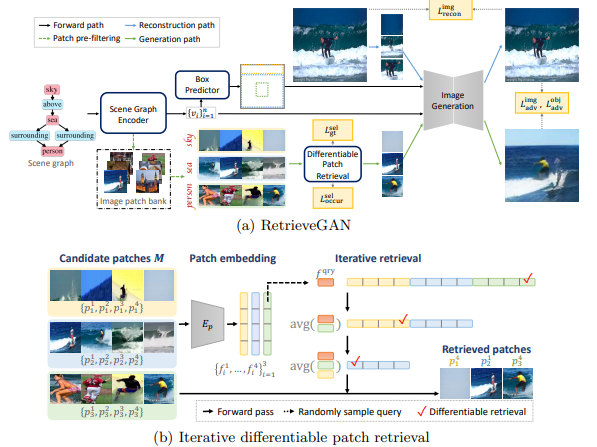
[15].RetrieveGAN: Image Synthesis via Differentiable Patch Retrieval
作者?|?Hung-Yu Tseng, Hsin-Ying Lee, Lu Jiang, Ming-Hsuan Yang, Weilong Yang
單位 | 谷歌,University of California, Merced,Yonsei University
論文?|?https://arxiv.org/abs/2007.08513
備注 |?ECCV?2020
通過可微分的Patch檢索進行圖像合成。
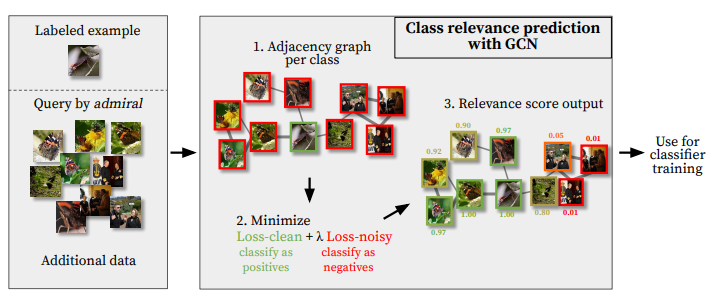
[16].Graph convolutional networks for learning with few clean and many noisy labels
作者?|?Ahmet Iscen, Giorgos Tolias, Yannis Avrithis, Ondrej Chum, Cordelia Schmid
單位 | 谷歌,Czech Technical University in Prague,Univ Rennes
論文?|?https://arxiv.org/abs/1910.00324
備注 |?ECCV?2020
通過圖卷積網(wǎng)絡(luò)在少量干凈和大量含噪聲樣本中進行學(xué)習(xí)。
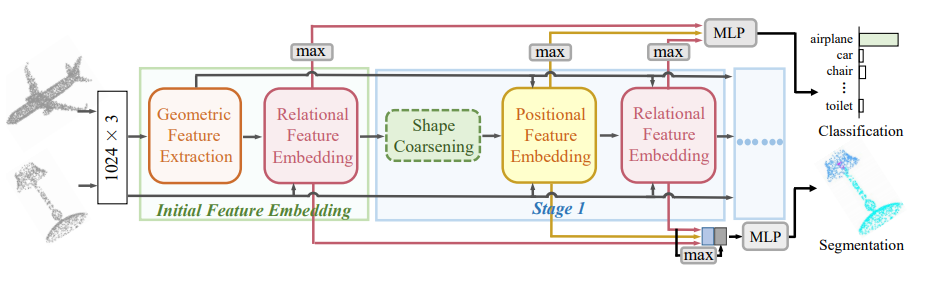
[17].Deep Positional and Relational Feature Learning for Rotation-Invariant Point Cloud Analysis
作者?|?Ruixuan Yu?, Xin Wei, Federico Tombari?, and Jian Sun
單位 | 西安交通大學(xué);慕尼黑工業(yè)大學(xué);谷歌
論文?|?http://www.ecva.net/papers/eccv_2020/
papers_ECCV/papers/123550222.pdf
備注 |?ECCV?2020
旋轉(zhuǎn)不變的點云分析。
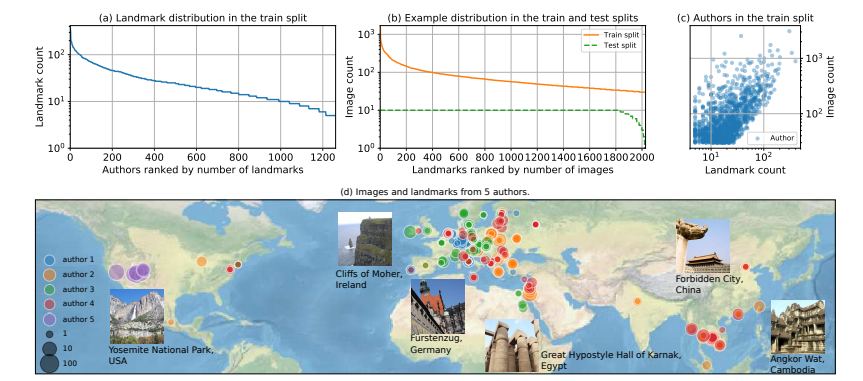
[18].Federated Visual Classification with Real-World Data Distribution
作者?|?Tzu-Ming Harry Hsu, Hang Qi, Matthew Brown
單位 |?麻省理工學(xué)院;谷歌
論文?|?https://arxiv.org/abs/2003.08082
數(shù)據(jù)集 |?https://github.com/google-research/google-research/tree/master/federated_vision_datasets
備注 |?ECCV?2020
保護數(shù)據(jù)隱私的聯(lián)邦學(xué)習(xí)。
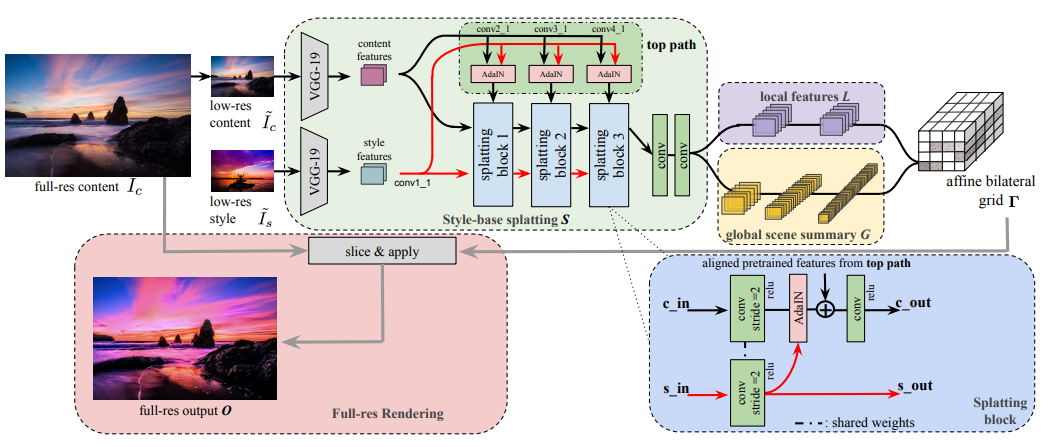
[19].Joint Bilateral Learning for Real-time Universal Photorealistic Style Transfer
作者?|?Xide Xia, Meng Zhang, Tianfan Xue, Zheng Sun, Hui Fang, Brian Kulis, Jiawen Chen
單位 |?波士頓大學(xué);PixelShift.AI;谷歌
論文?|?https://arxiv.org/abs/2004.10955
備注 |?ECCV?2020
聯(lián)合雙邊學(xué)習(xí),用于實時通用逼真的風(fēng)格遷移。

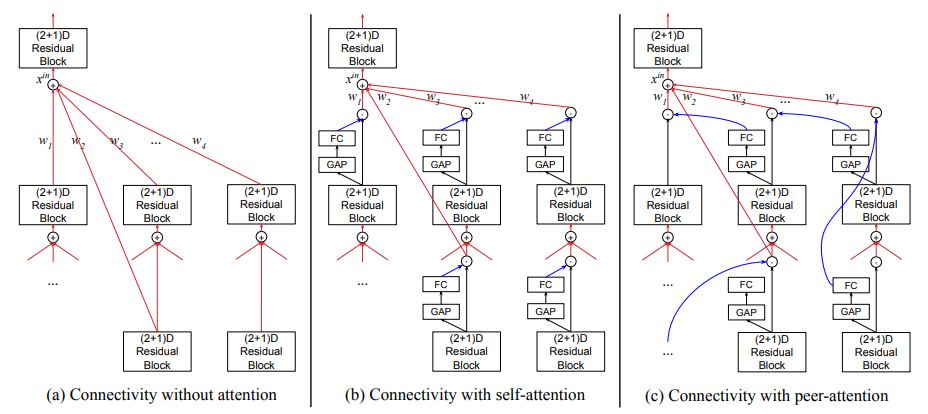
注意力機制,視頻理解,活動識別
[20].AssembleNet++: Assembling Modality Representations via Attention Connections
作者?|?Michael S. Ryoo, AJ Piergiovanni, Juhana Kangaspunta, Anelia Angelova
單位 | 谷歌,Stony Brook University
論文?|?https://arxiv.org/abs/2008.08072
代碼 |?https://github.com/google-research/google-research/tree/master/assemblenet
主頁 |?https://sites.google.com/view/assemblenet/
備注 |?ECCV?2020
半監(jiān)督學(xué)習(xí)+圖像分割
[21].Naive-Student: Leveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation
作者?|?Liang-Chieh Chen, Raphael Gontijo Lopes, Bowen Cheng, Maxwell D. Collins, Ekin D. Cubuk, Barret Zoph, Hartwig Adam, Jonathon Shlens
單位 | 谷歌,UIUC
論文?|?https://arxiv.org/abs/2005.10266
備注 |?ECCV?2020
視頻序列的半監(jiān)督學(xué)習(xí)用于城市場景分割。
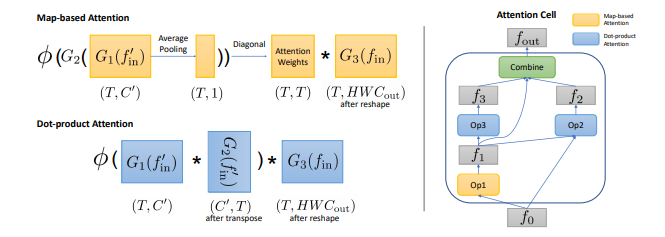
視頻分類
[22].AttentionNAS: Spatiotemporal Attention Cell Search for Video Classification
作者?|?Xiaofang Wang, Xuehan Xiong, Maxim Neumann, AJ Piergiovanni, Michael S. Ryoo, Anelia Angelova, Kris M. Kitani, Wei Hua
單位 | 谷歌;卡內(nèi)基梅隆大學(xué)
論文?|?https://arxiv.org/abs/2007.12034
備注 |?ECCV?2020
將時空注意力與NAS結(jié)合的視頻分類模型。
圖像檢索
[23].Unifying Deep Local and Global Features for Image Search
作者?|?Bingyi Cao, Andre Araujo, Jack Sim
單位 | 谷歌
論文?|?https://arxiv.org/abs/2001.05027
代碼 |?https://github.com/tensorflow/models/
tree/master/research/delf
備注 |?ECCV?2020
統(tǒng)一深度局部和全局特征的圖像搜索。
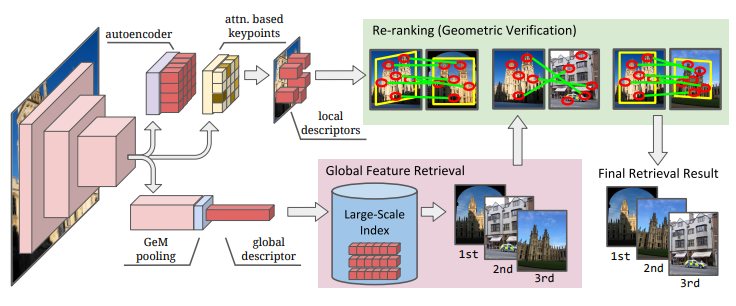
[24].Pillar-based Object Detection for Autonomous Driving
作者?|?Yue Wang, Alireza Fathi, Abhijit Kundu, David Ross, Caroline Pantofaru, Thomas Funkhouser, Justin Solomon
單位 | 麻省理工學(xué)院;谷歌
論文?|?https://arxiv.org/abs/2007.10323
代碼 |?https://github.com/WangYueFt/pillar-od
備注 |?ECCV?2020
自動駕駛目標檢測。
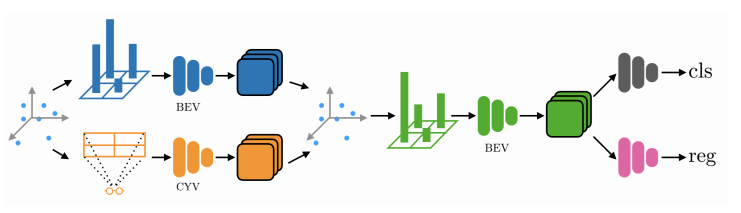
[25].Improving Object Detection with Selective Self-supervised Self-training
作者?|?Yandong Li, Di Huang, Danfeng Qin, Liqiang Wang, Boqing Gong
單位 |?中佛羅里達大學(xué);谷歌
論文?|?https://arxiv.org/abs/2007.09162
備注 |?ECCV?2020
通過可選擇的自監(jiān)督自訓(xùn)練方法改進目標檢測。

[26].Environment-agnostic Multitask Learning for Natural Language Grounded Navigation
作者?|?Xin Eric Wang, Vihan Jain, Eugene Ie, William Yang Wang, Zornitsa Kozareva, Sujith Ravi
單位 |?加利福尼亞大學(xué)圣克魯茲分校;加州大學(xué)圣巴巴拉分校;谷歌;亞馬遜
論文?|?https://arxiv.org/abs/2003.00443
代碼 |?https://github.com/google-research/valan
備注 |?ECCV?2020
面向自然語言的導(dǎo)航的環(huán)境不可知多任務(wù)學(xué)習(xí)。
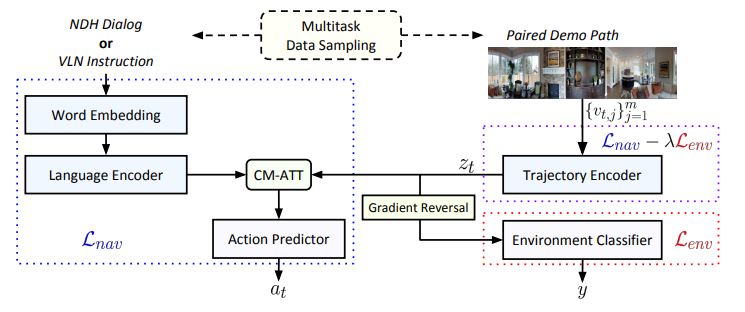
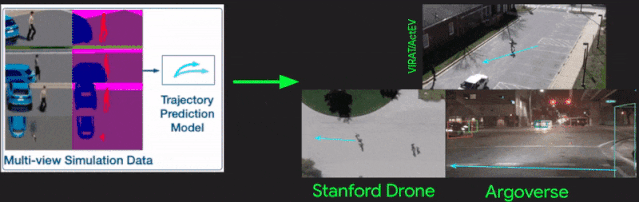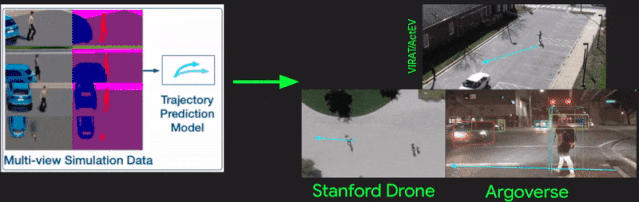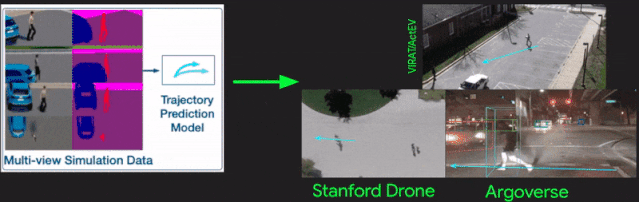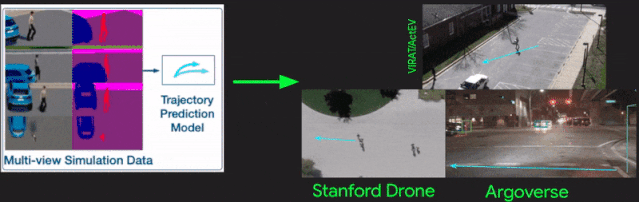
[27].SimAug: Learning Robust Representations from Simulation for Trajectory Prediction
作者?|?Junwei Liang, Lu Jiang, Alexander Hauptmann
單位 | 卡內(nèi)基梅隆大學(xué);谷歌
論文?|?https://arxiv.org/abs/2004.02022
代碼 |?https://github.com/JunweiLiang/Multiverse/tree/master/SimAug
主頁 |?https://next.cs.cmu.edu/simaug/
備注 |?ECCV?2020
從仿真數(shù)據(jù)中學(xué)習(xí)用于軌跡預(yù)測的魯棒表示。